
Home >Database >Mysql Tutorial >MySQL knowledge points: row-level locks in InnoDB
MySQL knowledge points: row-level locks in InnoDB

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2022-05-12 18:48:152217browse
This article brings you relevant knowledge about mysql, which mainly introduces the relevant knowledge about row-level locks in InnoDB. Row locks, also called record locks, as the name implies, are Let’s take a look at the locks added to the record. I hope it will be helpful to everyone.

Recommended learning: mysql video tutorial
Row lock, also known as record lock, as the name suggests is a lock added to the record . But please note that this record refers to locking the index entry on the index. This row lock implementation feature of InnoDB means that InnoDB uses row-level locks only when data is retrieved through index conditions. Otherwise, InnoDB will use table locks.
Whether you use a primary key index, a unique index, or a normal index, InnoDB will use row locks to lock data.
Row locks can only be used if the execution plan actually uses the index: even if the index field is used in the condition, whether to use the index to retrieve data is determined by MySQL by judging the cost of different execution plans. If MySQL believes that full table scans are more efficient. For example, for some very small tables, it will not use indexes. In this case, InnoDB will use table locks instead of row locks.
At the same time, when we use range conditions instead of equality conditions to retrieve data and request a lock, InnoDB will lock the index items of existing data records that meet the conditions.
But even row locks are divided into various types in InnoDB. In other words, even if a row lock is added to the same record, if the type is different, the effect will be different.
Here we still use the previous teacher table, add an index, and insert a few records.
mysql> desc teacher; +--------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------+--------------+------+-----+---------+-------+ | number | int(11) | NO | PRI | NULL | | | name | varchar(100) | YES | MUL | NULL | | | domain | varchar(100) | YES | | NULL | | +--------+--------------+------+-----+---------+-------+ 3 rows in set (0.00 sec) mysql> select * from teacher; +--------+------+--------+ | number | name | domain | +--------+------+--------+ | 1 | T | Java | | 3 | M | Redis | | 9 | X | MQ | | 15 | O | Python | | 21 | A | Golang | +--------+------+--------+ 5 rows in set (0.00 sec)
Let’s take a look at the commonly used row lock types.
Record Locks
Also called record lock, it means to lock only one record. The official type name is: LOCK_REC_NOT_GAP. For example, the schematic diagram of adding a record lock to the record with a number value of 9 is as follows:
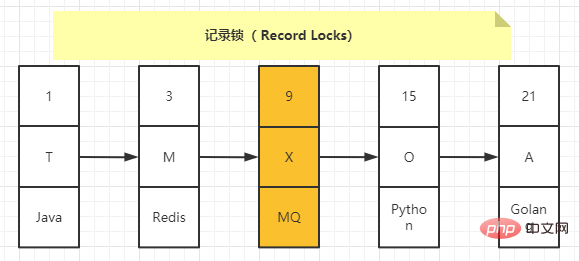
Record locks are divided into S locks and X locks. When a After a transaction acquires the S-type record lock of a record, other transactions can continue to acquire the S-type record lock of the record, but they cannot continue to acquire the X-type record lock; when a transaction acquires the X-type record lock of a record, Other transactions can neither continue to acquire the S-type record lock nor the X-type record lock for this record.
| T1 | T2 |
|---|---|
| ##select * from teacher where number=9 for update; # Blocking |
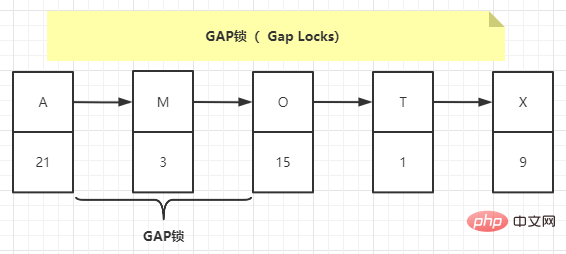
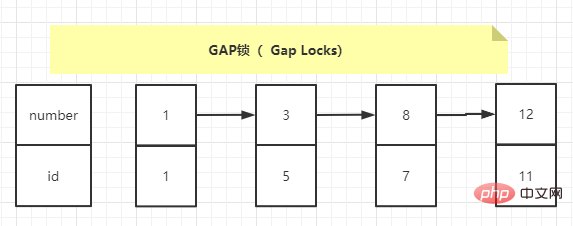
MySQL is allowed under the REPEATABLE READ isolation level There are two solutions to partially solve the phantom reading problem. It can be solved by using the MVCC solution or the locking solution. However, there is a problem when using the locking solution, that is, when the transaction performs the read operation for the first time, those phantom records do not yet exist, and we cannot add record locks to these phantom records. InnoDB proposes a type of lock called Gap Locks. The official type name is: LOCK_GAP. We can also call it gap lock for short.
Gap lock essentially locks the gap before and after the index, but does not lock the index itself.
| T2 | |
|---|---|
The above is the detailed content of MySQL knowledge points: row-level locks in InnoDB. For more information, please follow other related articles on the PHP Chinese website!