
Home >Java >javaTutorial >Summarize Java concurrency knowledge points
Summarize Java concurrency knowledge points

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2022-03-25 19:16:263327browse
This article brings you relevant knowledge about java. It mainly introduces the issues related to java concurrency and summarizes some problems. Let’s take a look and see how much it will be. I hope it will be helpful to everyone. .

Recommended study: "java tutorial"
1. What is the difference between parallelism and concurrency?
From the perspective of the operating system, a thread is the smallest unit of CPU allocation.
- Parallelism means that both threads are executing at the same time. This requires two CPUs to execute two threads respectively.
- Concurrency means that there is only one execution at the same time, but within a period of time, both threads are executed. The implementation of concurrency relies on CPU switching threads. Because the switching time is very short, it is basically imperceptible to the user.
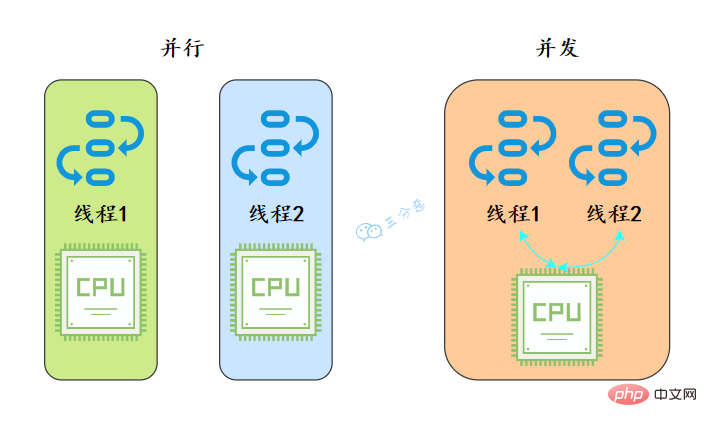
# Just like when we go to the canteen to get food, parallelism means that we line up at multiple windows and several aunties are getting food at the same time; concurrency means that we crowd into one window, The aunt gave this one a spoonful, and then hurriedly gave that one a spoonful.

#2. What are processes and threads?
To talk about threads, we must first talk about processes.
- Process: A process is a running activity of code on a data collection. It is the basic unit of resource allocation and scheduling in the system.
- Thread: A thread is an execution path of a process. There is at least one thread in a process. Multiple threads in the process share the resources of the process.
The operating system allocates resources to processes when allocating resources, but the CPU resource is special. It is allocated to threads, because it is the threads that really occupy the CPU for running, so it is also said that Threads are the basic unit of CPU allocation.
For example, in Java, when we start the main function, we actually start a JVM process, and the thread in which the main function is located is a thread in this process, also called the main thread.
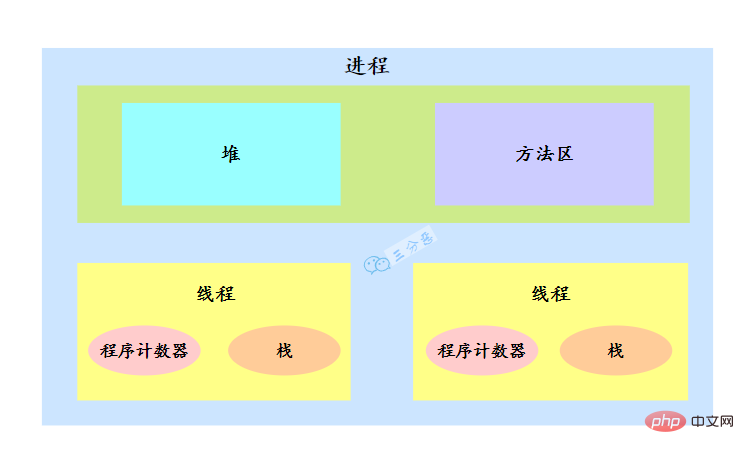
There are multiple threads in a process. Multiple threads share the heap and method area resources of the process, but each thread has its own program counter and stack.
3. How many ways are there to create a thread?
There are three main ways to create threads in Java, namely inheriting the Thread class, implementing the Runnable interface, and implementing the Callable interface.
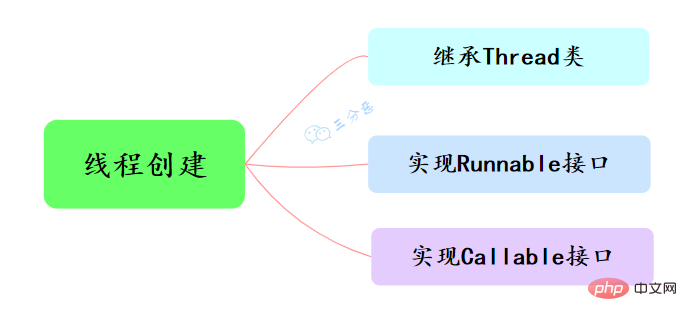
- Inherit the Thread class, override the run() method, and call the start() method to start the thread
public class ThreadTest {
/**
* 继承Thread类
*/
public static class MyThread extends Thread {
@Override
public void run() {
System.out.println("This is child thread");
}
}
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
}}
- Implementation Runnable interface, override the run() method
public class RunnableTask implements Runnable {
public void run() {
System.out.println("Runnable!");
}
public static void main(String[] args) {
RunnableTask task = new RunnableTask();
new Thread(task).start();
}}
The above two have no return value, but what should we do if we need to obtain the execution result of the thread?
- Implement the Callable interface and override the call() method. In this way, the return value of task execution can be obtained through FutureTask
public class CallerTask implements Callable<string> {
public String call() throws Exception {
return "Hello,i am running!";
}
public static void main(String[] args) {
//创建异步任务
FutureTask<string> task=new FutureTask<string>(new CallerTask());
//启动线程
new Thread(task).start();
try {
//等待执行完成,并获取返回结果
String result=task.get();
System.out.println(result);
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}}</string></string></string>
4. Why call the start() method The run() method will be executed, so why not call the run() method directly?
When the JVM executes the start method, it will first create a thread, and the created new thread will execute the thread's run method, which achieves the multi-threading effect.
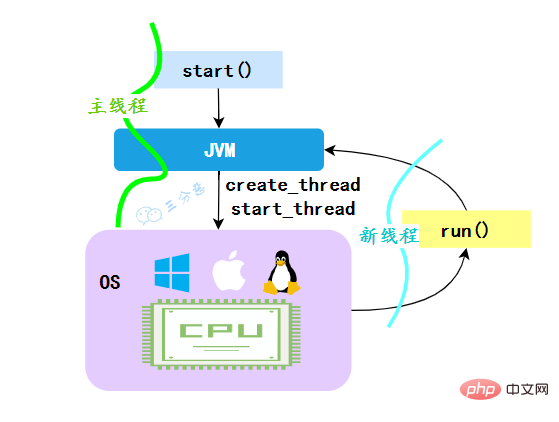
#**Why can’t we call the run() method directly? **It is also clear that if the run() method of Thread is called directly, the run method will still run in the main thread, which is equivalent to sequential execution, and will not achieve the multi-threading effect.
5. What are the commonly used scheduling methods for threads?
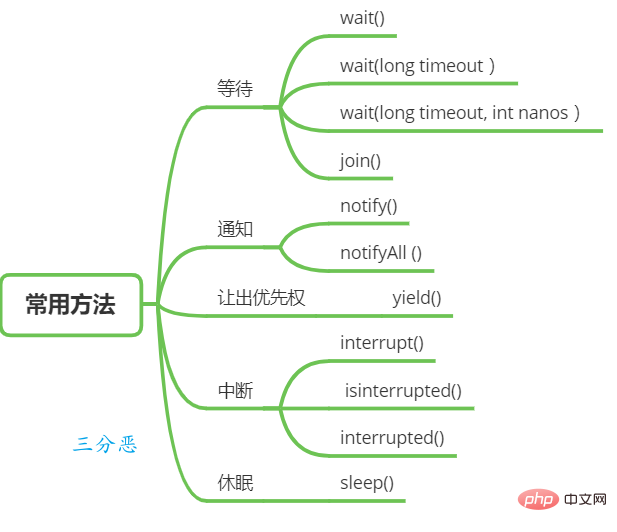
Thread waiting and notification
There are some functions in the Object class that can be used for thread waiting and notification.
-
wait(): When a thread A calls the wait() method of a shared variable, thread A will be blocked and suspended, and will only return when the following situations occur:
(1) Thread A calls the shared object notify() or notifyAll() method;
(2) Other threads call thread A’s interrupt() method, thread A throws InterruptedException and returns.
wait(long timeout): This method has one more timeout parameter than the wait() method. The difference is that if thread A calls shared If the object's wait(long timeout) method is not awakened by other threads within the specified timeout ms, then this method will still return due to timeout.
wait(long timeout, int nanos), which internally calls the wait(long timout) function.
The above are the methods for thread waiting, and there are mainly two methods to wake up the thread:
- notify(): After a thread A calls the notify() method of a shared object, it will wake up a thread that was suspended after calling the wait series of methods on the shared variable. There may be multiple threads waiting on a shared variable, and which waiting thread is awakened is random.
- notifyAll(): Unlike calling the notify() function on a shared variable, which will wake up a thread blocked on the shared variable, the notifyAll() method will wake up all threads blocked on the shared variable due to calling wait. A thread that is suspended due to a series of methods.
The Thread class also provides a method for waiting:
-
join(): If a thread A executes the thread.join() statement , its meaning is: the current thread A waits for the thread thread to terminate before
returns from thread.join().
Thread sleep
- sleep(long millis): Static method in the Thread class, called when an executing thread A After calling Thread's sleep method, Thread A will temporarily give up the execution rights for the specified time, but the monitor resources owned by Thread A, such as locks, are still held and will not be given up. After the specified sleep time is up, the function will return normally, then participate in CPU scheduling, and continue running after obtaining CPU resources.
Give priority
- yield(): a static method in the Thread class. When a thread calls the yield method, it is actually It hints to the thread scheduler that the current thread is requesting to give up its CPU, but the thread scheduler can unconditionally ignore this hint.
Thread interruption
Thread interruption in Java is a cooperation mode between threads. Setting the interruption flag of a thread cannot directly terminate the thread. execution, but the interrupted thread handles it by itself according to the interruption status.
- void interrupt(): Interrupt a thread. For example, when thread A is running, thread B can call the interrupt() method to set the thread's interrupt flag to true and return immediately. Setting the flag is just setting the flag. Thread A is not actually interrupted and will continue to execute.
- boolean isInterrupted() method: Detect whether the current thread is interrupted.
- boolean interrupted() method: Detect whether the current thread is interrupted. Unlike isInterrupted, this method will clear the interrupt flag if it finds that the current thread is interrupted.
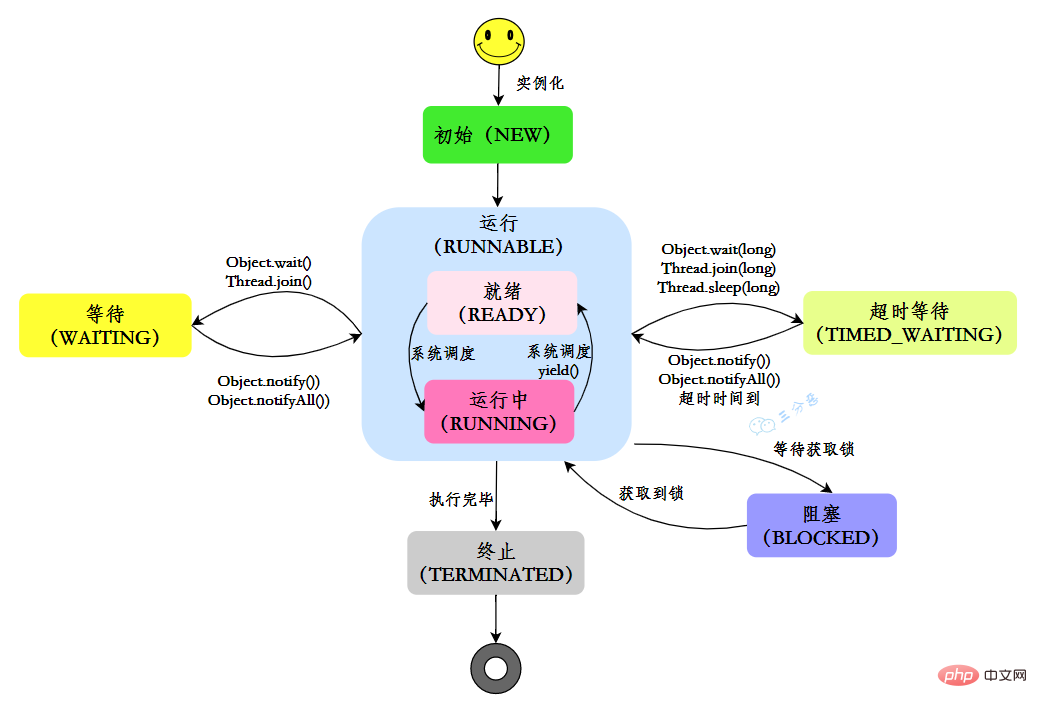
6. How many states does a thread have?
In Java, there are six states of threads:
| State | Description |
|---|---|
| NEW | Initial state: The thread is created, but the start() method has not been called yet |
| RUNNABLE | Running state : Java threads generally refer to the two states of ready and running in the operating system as "running" |
| BLOCKED | Blocking state: Indicates that the thread is blocked in the lock |
| WAITING | Waiting state: Indicates that the thread enters the waiting state. Entering this state means that the current thread needs to wait for other threads to make some specific actions (notifications or interruptions) |
| TIME_WAITING | Timeout waiting status: This status is different from WAITIND, it can return by itself at the specified time |
| TERMINATED | Termination status: Indicates that the current thread has completed execution |
In its own life cycle, a thread is not in a fixed state, but switches between different states as the code is executed. The Java thread state changes as shown in the figure:
7. What is thread context switching?
The purpose of using multi-threading is to make full use of the CPU, but we know that concurrency is actually one CPU to cope with multiple threads.
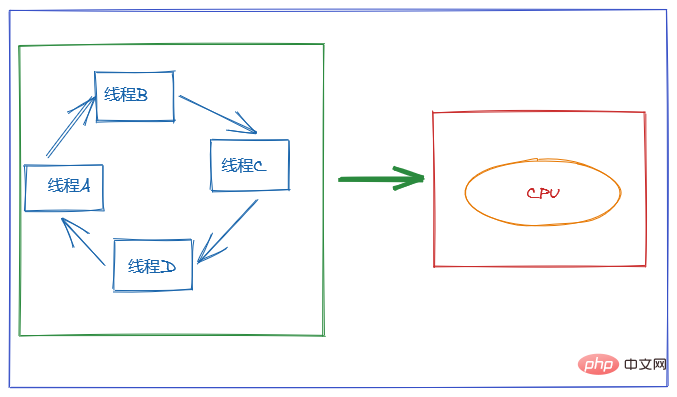
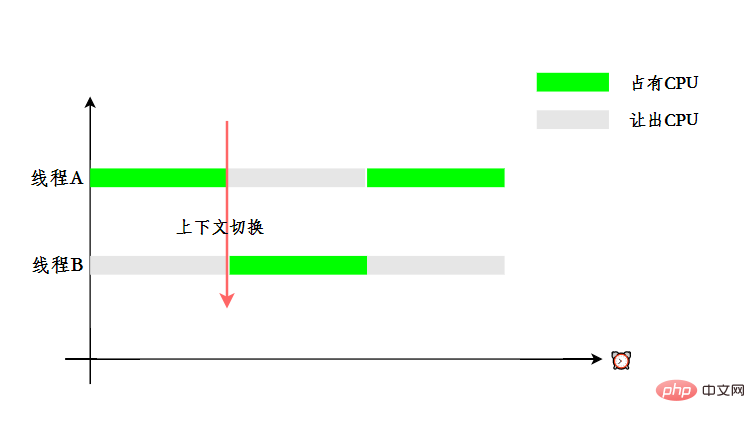
In order to make users feel that multiple threads are executing at the same time, CPU resources are allocated using time slice rotation, that is, each thread is assigned a time slice. The CPU is occupied to perform tasks within the time slice. When a thread uses up its time slice, it will be in a ready state and let other threads take up the CPU. This is a context switch.
8. Do you understand the daemon thread?
Threads in Java are divided into two categories, namely daemon thread (daemon thread) and user thread (user thread).
The main function will be called when the JVM starts. The process where the main function is located is a user thread. In fact, many daemon threads are also started inside the JVM, such as garbage collection threads.
So what is the difference between daemon threads and user threads? One of the differences is that when the last non-daemon thread warps, the JVM will exit normally, regardless of whether there is currently a daemon thread, which means that whether the daemon thread ends does not affect the JVM exit. In other words, as long as one user thread has not ended, the JVM will not exit under normal circumstances.
9. What are the communication methods between threads?
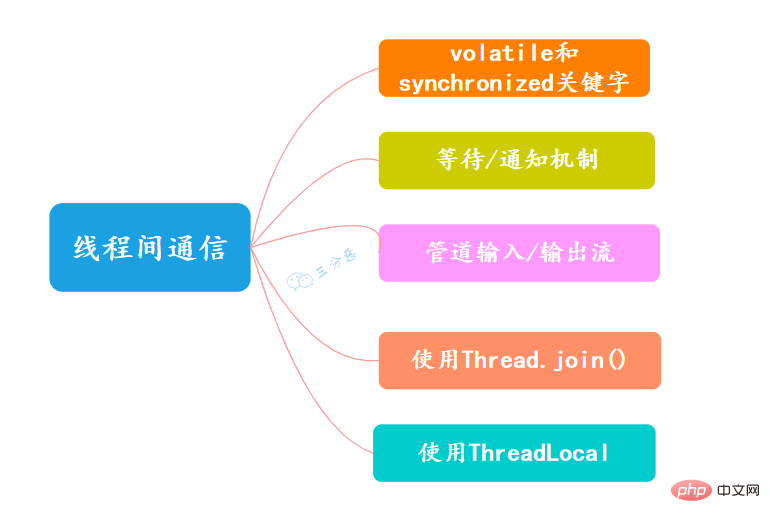
- volatile and synchronized keywords
The keyword volatile can be used to modify fields (member variables) , which is to inform the program that any access to the variable needs to be obtained from the shared memory, and changes to it must be flushed back to the shared memory synchronously. It can ensure the visibility of variable access by all threads.
The keyword synchronized can be used to modify methods or in the form of synchronized blocks. It mainly ensures that multiple threads can only have one thread in a method or synchronized block at the same time. It ensures that threads can Visibility and exclusivity of variable access.
- Waiting/notification mechanism
A thread modification can be implemented through Java’s built-in waiting/notification mechanism (wait()/notify()) The value of an object, and another thread senses the change and then performs the corresponding operation.
- Pipeline input/output stream
Pipeline input/output stream is different from ordinary file input/output stream or network input/output stream The reason is that it is mainly used for data transmission between threads, and the transmission medium is memory.
Pipe input/output streams mainly include the following four specific implementations: PipedOutputStream, PipedInputStream, PipedReader and PipedWriter. The first two are byte-oriented, and the latter two are character-oriented.
- Use Thread.join()
If a thread A executes the thread.join() statement, the meaning is: current thread A Wait for the thread thread to terminate before returning from thread.join(). . In addition to the join() method, thread Thread also provides two methods with timeout characteristics: join(long millis) and join(long millis, int nanos).
- Using ThreadLocal
ThreadLocal, that is, a thread variable, is a storage structure with a ThreadLocal object as a key and any object as a value. This structure is attached to the thread, which means that a thread can query a value bound to this thread based on a ThreadLocal object.
You can set a value through the set(T) method, and then obtain the originally set value through the get() method in the current thread.
Regarding multi-threading, there is a high probability that there will also be some written test questions, such as alternate printing, bank transfers, production and consumption models, etc. Later, Laosan will publish a separate issue to review common questions. Multithreading written test questions.
ThreadLocal
ThreadLocal actually does not have many application scenarios, but it is an interview veteran who has been bombarded thousands of times. It involves multi-threading, data structures, and JVM. You can ask questions. If you have more points, you must win them.
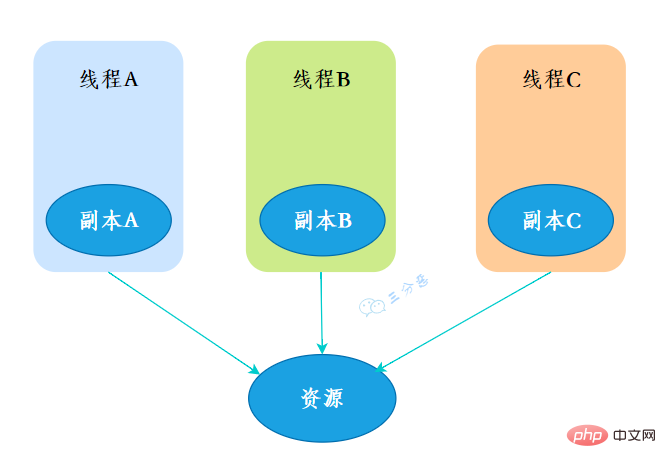
10.What is ThreadLocal?
ThreadLocal, which is a thread local variable. If you create a ThreadLocal variable, then each thread that accesses this variable will have a local copy of this variable. When multiple threads operate this variable, they actually operate the variables in their own local memory, thus achieving thread isolation. function to avoid thread safety issues.
- 创建
创建了一个ThreadLoca变量localVariable,任何一个线程都能并发访问localVariable。
//创建一个ThreadLocal变量public static ThreadLocal<string> localVariable = new ThreadLocal();</string>
- 写入
线程可以在任何地方使用localVariable,写入变量。
localVariable.set("鄙人三某”);
- 读取
线程在任何地方读取的都是它写入的变量。
localVariable.get();
11.你在工作中用到过ThreadLocal吗?
有用到过的,用来做用户信息上下文的存储。
我们的系统应用是一个典型的MVC架构,登录后的用户每次访问接口,都会在请求头中携带一个token,在控制层可以根据这个token,解析出用户的基本信息。那么问题来了,假如在服务层和持久层都要用到用户信息,比如rpc调用、更新用户获取等等,那应该怎么办呢?
一种办法是显式定义用户相关的参数,比如账号、用户名……这样一来,我们可能需要大面积地修改代码,多少有点瓜皮,那该怎么办呢?
这时候我们就可以用到ThreadLocal,在控制层拦截请求把用户信息存入ThreadLocal,这样我们在任何一个地方,都可以取出ThreadLocal中存的用户数据。
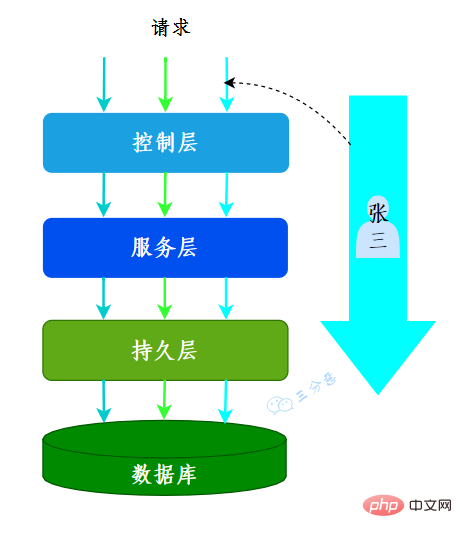
很多其它场景的cookie、session等等数据隔离也都可以通过ThreadLocal去实现。
我们常用的数据库连接池也用到了ThreadLocal:
- 数据库连接池的连接交给ThreadLoca进行管理,保证当前线程的操作都是同一个Connnection。
12.ThreadLocal怎么实现的呢?
我们看一下ThreadLocal的set(T)方法,发现先获取到当前线程,再获取ThreadLocalMap,然后把元素存到这个map中。
public void set(T value) {
//获取当前线程
Thread t = Thread.currentThread();
//获取ThreadLocalMap
ThreadLocalMap map = getMap(t);
//讲当前元素存入map
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocal实现的秘密都在这个ThreadLocalMap了,可以Thread类中定义了一个类型为ThreadLocal.ThreadLocalMap的成员变量threadLocals。
public class Thread implements Runnable {
//ThreadLocal.ThreadLocalMap是Thread的属性
ThreadLocal.ThreadLocalMap threadLocals = null;}
ThreadLocalMap既然被称为Map,那么毫无疑问它是
static class Entry extends WeakReference<threadlocal>> {
/** The value associated with this ThreadLocal. */
Object value;
//节点类
Entry(ThreadLocal> k, Object v) {
//key赋值
super(k);
//value赋值
value = v;
}
}</threadlocal>
这里的节点,key可以简单低视作ThreadLocal,value为代码中放入的值,当然实际上key并不是ThreadLocal本身,而是它的一个弱引用,可以看到Entry的key继承了 WeakReference(弱引用),再来看一下key怎么赋值的:
public WeakReference(T referent) {
super(referent);
}
key的赋值,使用的是WeakReference的赋值。
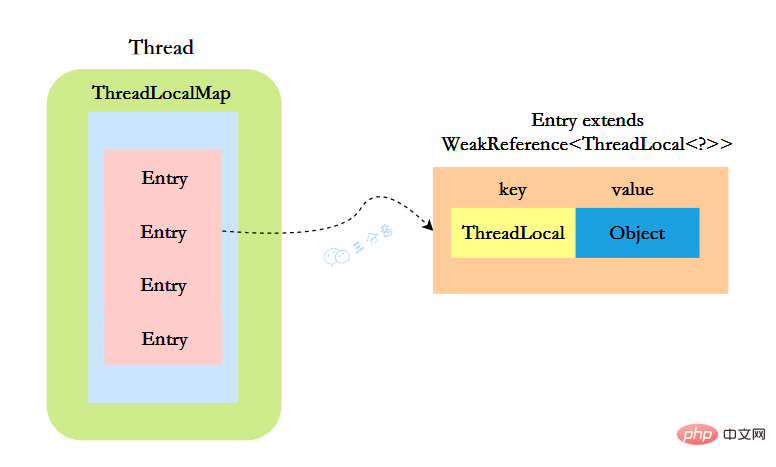
所以,怎么回答ThreadLocal原理?要答出这几个点:
- Thread类有一个类型为ThreadLocal.ThreadLocalMap的实例变量threadLocals,每个线程都有一个属于自己的ThreadLocalMap。
- ThreadLocalMap内部维护着Entry数组,每个Entry代表一个完整的对象,key是ThreadLocal的弱引用,value是ThreadLocal的泛型值。
- 每个线程在往ThreadLocal里设置值的时候,都是往自己的ThreadLocalMap里存,读也是以某个ThreadLocal作为引用,在自己的map里找对应的key,从而实现了线程隔离。
- ThreadLocal本身不存储值,它只是作为一个key来让线程往ThreadLocalMap里存取值。
13.ThreadLocal 内存泄露是怎么回事?
我们先来分析一下使用ThreadLocal时的内存,我们都知道,在JVM中,栈内存线程私有,存储了对象的引用,堆内存线程共享,存储了对象实例。
所以呢,栈中存储了ThreadLocal、Thread的引用,堆中存储了它们的具体实例。
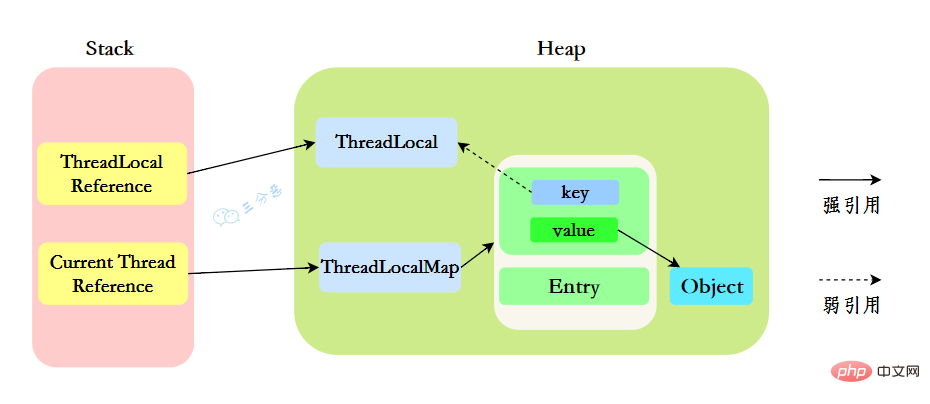
ThreadLocalMap中使用的 key 为 ThreadLocal 的弱引用。
“弱引用:只要垃圾回收机制一运行,不管JVM的内存空间是否充足,都会回收该对象占用的内存。”
那么现在问题就来了,弱引用很容易被回收,如果ThreadLocal(ThreadLocalMap的Key)被垃圾回收器回收了,但是ThreadLocalMap生命周期和Thread是一样的,它这时候如果不被回收,就会出现这种情况:ThreadLocalMap的key没了,value还在,这就会造成了内存泄漏问题。
那怎么解决内存泄漏问题呢?
很简单,使用完ThreadLocal后,及时调用remove()方法释放内存空间。
ThreadLocallocalVariable = new ThreadLocal();try { localVariable.set("鄙人三某”); ……} finally { localVariable.remove();}
那为什么key还要设计成弱引用?
key设计成弱引用同样是为了防止内存泄漏。
假如key被设计成强引用,如果ThreadLocal Reference被销毁,此时它指向ThreadLoca的强引用就没有了,但是此时key还强引用指向ThreadLoca,就会导致ThreadLocal不能被回收,这时候就发生了内存泄漏的问题。
14.ThreadLocalMap的结构了解吗?
ThreadLocalMap虽然被叫做Map,其实它是没有实现Map接口的,但是结构还是和HashMap比较类似的,主要关注的是两个要素:元素数组和散列方法。
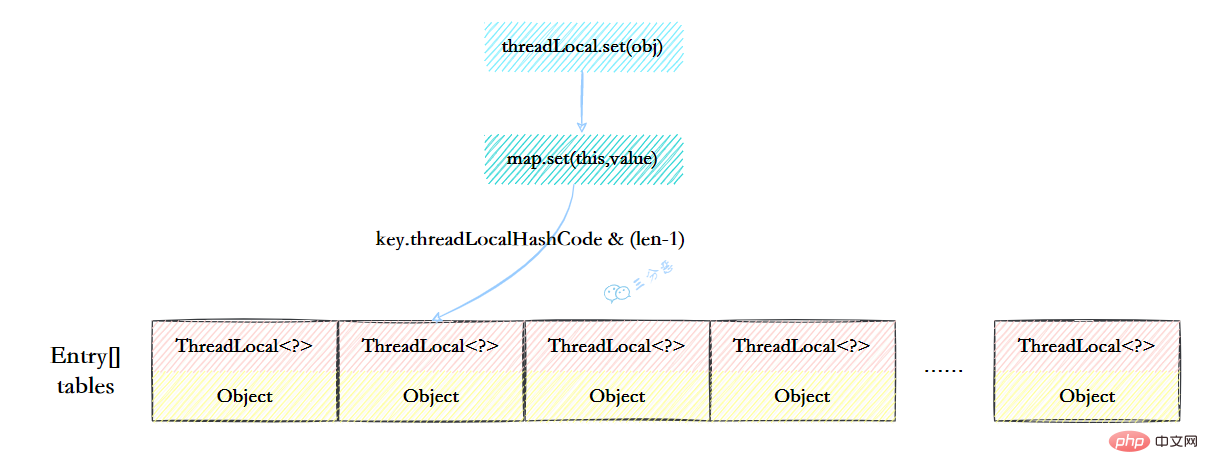
-
元素数组
一个table数组,存储Entry类型的元素,Entry是ThreaLocal弱引用作为key,Object作为value的结构。
private Entry[] table;
-
散列方法
散列方法就是怎么把对应的key映射到table数组的相应下标,ThreadLocalMap用的是哈希取余法,取出key的threadLocalHashCode,然后和table数组长度减一&运算(相当于取余)。
int i = key.threadLocalHashCode & (table.length - 1);
这里的threadLocalHashCode计算有点东西,每创建一个ThreadLocal对象,它就会新增0x61c88647,这个值很特殊,它是斐波那契数 也叫 黄金分割数。hash增量为 这个数字,带来的好处就是 hash 分布非常均匀。
private static final int HASH_INCREMENT = 0x61c88647;
private static int nextHashCode() {
return nextHashCode.getAndAdd(HASH_INCREMENT);
}
15.ThreadLocalMap怎么解决Hash冲突的?
我们可能都知道HashMap使用了链表来解决冲突,也就是所谓的链地址法。
ThreadLocalMap没有使用链表,自然也不是用链地址法来解决冲突了,它用的是另外一种方式——开放定址法。开放定址法是什么意思呢?简单来说,就是这个坑被人占了,那就接着去找空着的坑。
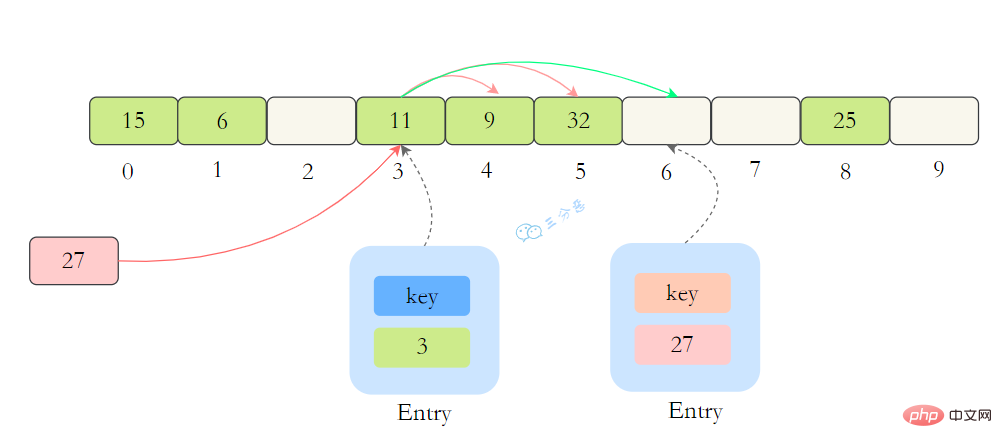
如上图所示,如果我们插入一个value=27的数据,通过 hash计算后应该落入第 4 个槽位中,而槽位 4 已经有了 Entry数据,而且Entry数据的key和当前不相等。此时就会线性向后查找,一直找到 Entry为 null的槽位才会停止查找,把元素放到空的槽中。
在get的时候,也会根据ThreadLocal对象的hash值,定位到table中的位置,然后判断该槽位Entry对象中的key是否和get的key一致,如果不一致,就判断下一个位置。
16.Summarize Java concurrency knowledge points机制了解吗?
在ThreadLocalMap.set()方法的最后,如果执行完启发式清理工作后,未清理到任何数据,且当前散列数组中Entry的数量已经达到了列表的扩容阈值(len*2/3),就开始执行rehash()逻辑:
if (!cleanSomeSlots(i, sz) && sz >= threshold) rehash();
再着看rehash()具体实现:这里会先去清理过期的Entry,然后还要根据条件判断size >= threshold - threshold / 4 也就是size >= threshold* 3/4来决定是否需要扩容。
private void rehash() {
//清理过期Entry
expungeStaleEntries();
//扩容
if (size >= threshold - threshold / 4)
resize();}//清理过期Entryprivate void expungeStaleEntries() {
Entry[] tab = table;
int len = tab.length;
for (int j = 0; j <p>接着看看具体的<code>resize()</code>方法,扩容后的<code>newTab</code>的大小为老数组的两倍,然后遍历老的table数组,散列方法重新计算位置,开放地址解决冲突,然后放到新的<code>newTab</code>,遍历完成之后,<code>oldTab</code>中所有的<code>entry</code>数据都已经放入到<code>newTab</code>中了,然后table引用指向<code>newTab</code></p><p><img src="https://img.php.cn/upload/article/000/000/067/6137d48077cbb320beee2007e8763d69-16.png" alt="Summarize Java concurrency knowledge points"></p><p>具体代码:</p><p><img src="https://img.php.cn/upload/article/000/000/067/85310a4f8d2bb86283cd76fb2542424d-17.png" alt="ThreadLocalMap resize"></p><h2>17.父子线程怎么共享数据?</h2><p>父线程能用ThreadLocal来给子线程传值吗?毫无疑问,不能。那该怎么办?</p><p>这时候可以用到另外一个类——<code>InheritableThreadLocal</code>。</p><p>使用起来很简单,在主线程的InheritableThreadLocal实例设置值,在子线程中就可以拿到了。</p><pre class="brush:php;toolbar:false">public class InheritableThreadLocalTest {
public static void main(String[] args) {
final ThreadLocal threadLocal = new InheritableThreadLocal();
// 主线程
threadLocal.set("不擅技术");
//子线程
Thread t = new Thread() {
@Override
public void run() {
super.run();
System.out.println("鄙人三某 ," + threadLocal.get());
}
};
t.start();
}}那原理是什么呢?
原理很简单,在Thread类里还有另外一个变量:
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
在Thread.init的时候,如果父线程的inheritableThreadLocals不为空,就把它赋给当前线程(子线程)的inheritableThreadLocals。
if (inheritThreadLocals && parent.inheritableThreadLocals != null) this.inheritableThreadLocals = ThreadLocal.createInheritedMap(parent.inheritableThreadLocals)
18.说一下你对Summarize Java concurrency knowledge points(JMM)的理解?
Summarize Java concurrency knowledge points(Java Memory Model,JMM),是一种抽象的模型,被定义出来屏蔽各种硬件和操作系统的内存访问差异。
JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的副本。
Summarize Java concurrency knowledge points的抽象图:
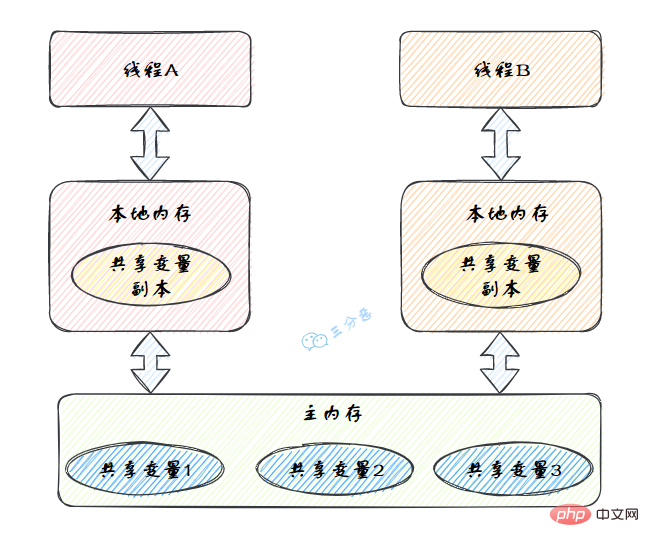
本地内存是JMM的 一个抽象概念,并不真实存在。它其实涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。
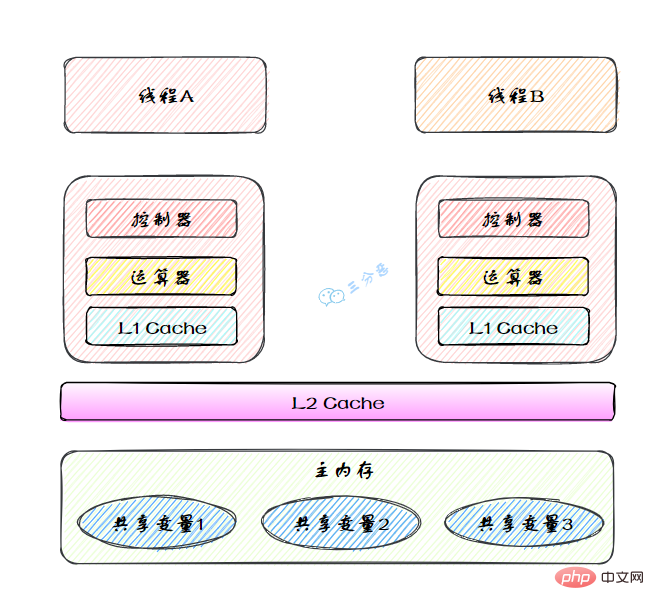
图里面的是一个双核 CPU 系统架构 ,每个核有自己的控制器和运算器,其中控制器包含一组寄存器和操作控制器,运算器执行算术逻辅运算。每个核都有自己的一级缓存,在有些架构里面还有一个所有 CPU 共享的二级缓存。 那么 Java 内存模型里面的工作内存,就对应这里的 Ll 缓存或者 L2 缓存或者 CPU 寄存器。
19.说说你对原子性、可见性、有序性的理解?
原子性、有序性、可见性是并发编程中非常重要的基础概念,JMM的很多技术都是围绕着这三大特性展开。
- 原子性:原子性指的是一个操作是不可分割、不可中断的,要么全部执行并且执行的过程不会被任何因素打断,要么就全不执行。
- 可见性:可见性指的是一个线程修改了某一个共享变量的值时,其它线程能够立即知道这个修改。
- 有序性:有序性指的是对于一个线程的执行代码,从前往后依次执行,单线程下可以认为程序是有序的,但是并发时有可能会发生指令重排。
分析下面几行代码的原子性?
int i = 2;int j = i;i++;i = i + 1;
- 第1句是基本类型赋值,是原子性操作。
- 第2句先读i的值,再赋值到j,两步操作,不能保证原子性。
- 第3和第4句其实是等效的,先读取i的值,再+1,最后赋值到i,三步操作了,不能保证原子性。
原子性、可见性、有序性都应该怎么保证呢?
- 原子性:JMM只能保证基本的原子性,如果要保证一个代码块的原子性,需要使用
synchronized。 - 可见性:Java是利用
volatile关键字来保证可见性的,除此之外,final和synchronized也能保证可见性。 - 有序性:
synchronized或者volatile都可以保证多线程之间操作的有序性。
20.那说说什么是指令重排?
在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。重排序分3种类型。
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术(Instruction-Level Parallelism,ILP)来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应 机器指令的执行顺序。
- 内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
从Java源代码到最终实际执行的指令序列,会分别经历下面3种重排序,如图:

我们比较熟悉的双重校验单例模式就是一个经典的指令重排的例子,Singleton instance=new Singleton();对应的JVM指令分为三步:分配内存空间–>初始化对象—>对象指向分配的内存空间,但是经过了编译器的指令重排序,第二步和第三步就可能会重排序。
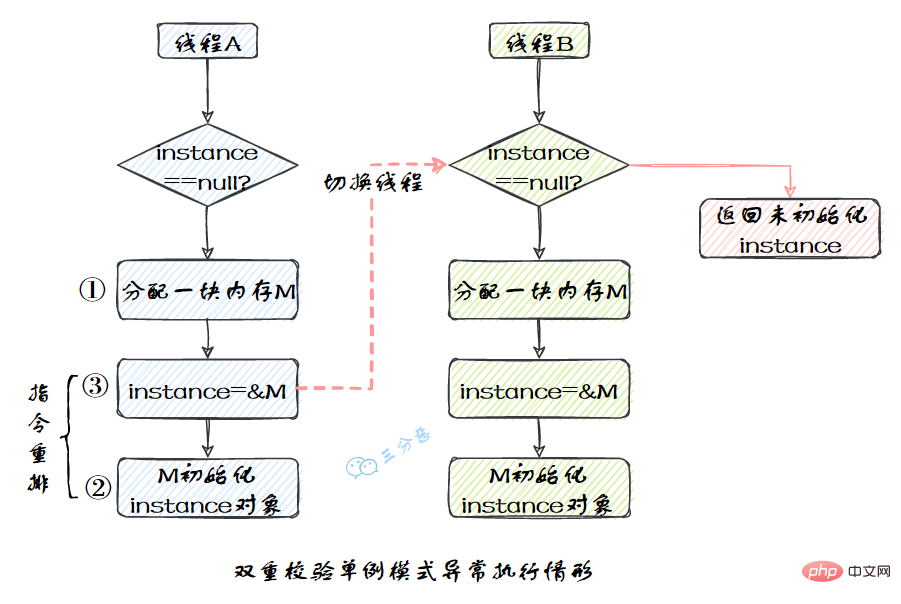
JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
21.指令重排有限制吗?happens-before了解吗?
指令重排也是有一些限制的,有两个规则happens-before和as-if-serial来约束。
happens-before的定义:
- 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。
- 两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照 happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么这种重排序并不非法
happens-before和我们息息相关的有六大规则:
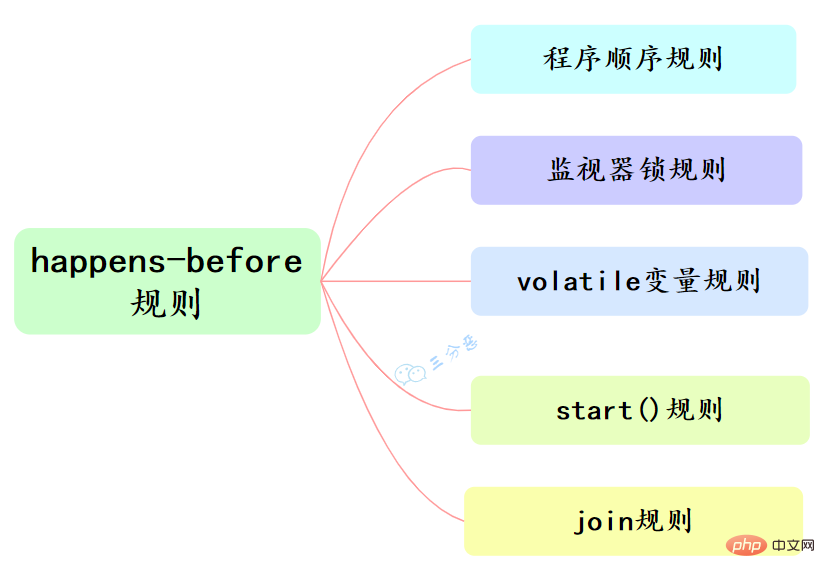
- 程序顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作。
- 监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。
- volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。
- 传递性:如果A happens-before B,且B happens-before C,那么A happens-before C。
- start()规则:如果线程A执行操作ThreadB.start()(启动线程B),那么A线程的 ThreadB.start()操作happens-before于线程B中的任意操作。
- join()规则:如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作 happens-before于线程A从ThreadB.join()操作成功返回。
22.as-if-serial又是什么?单线程的程序一定是顺序的吗?
as-if-serial语义的意思是:不管怎么重排序(编译器和处理器为了提高并行度),单线程程序的执行结果不能被改变。编译器、runtime和处理器都必须遵守as-if-serial语义。
为了遵守as-if-serial语义,编译器和处理器不会对存在数据依赖关系的操作做重排序,因为这种重排序会改变执行结果。但是,如果操作之间不存在数据依赖关系,这些操作就可能被编译器和处理器重排序。为了具体说明,请看下面计算圆面积的代码示例。
double pi = 3.14; // Adouble r = 1.0; // B double area = pi * r * r; // C
上面3个操作的数据依赖关系:
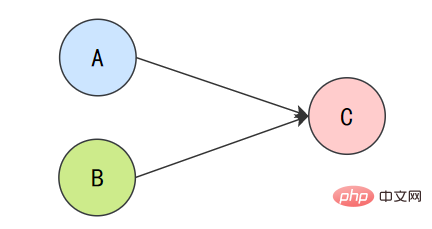
A和C之间存在数据依赖关系,同时B和C之间也存在数据依赖关系。因此在最终执行的指令序列中,C不能被重排序到A和B的前面(C排到A和B的前面,程序的结果将会被改变)。但A和B之间没有数据依赖关系,编译器和处理器可以重排序A和B之间的执行顺序。
所以最终,程序可能会有两种执行顺序:
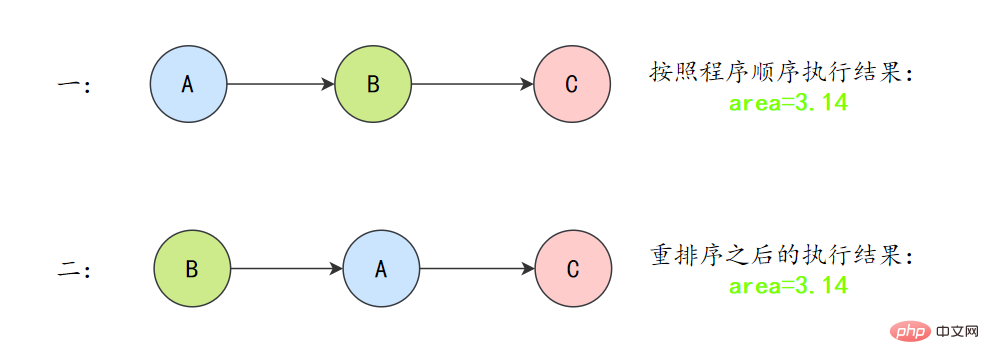
as-if-serial语义把单线程程序保护了起来,遵守as-if-serial语义的编译器、runtime和处理器共同编织了这么一个“楚门的世界”:单线程程序是按程序的“顺序”来执行的。as- if-serial语义使单线程情况下,我们不需要担心重排序的问题,可见性的问题。
23.volatile实现原理了解吗?
volatile有两个作用,保证可见性和有序性。
volatile怎么保证可见性的呢?
相比synchronized的加锁方式来解决共享变量的内存可见性问题,volatile就是更轻量的选择,它没有上下文切换的额外开销成本。
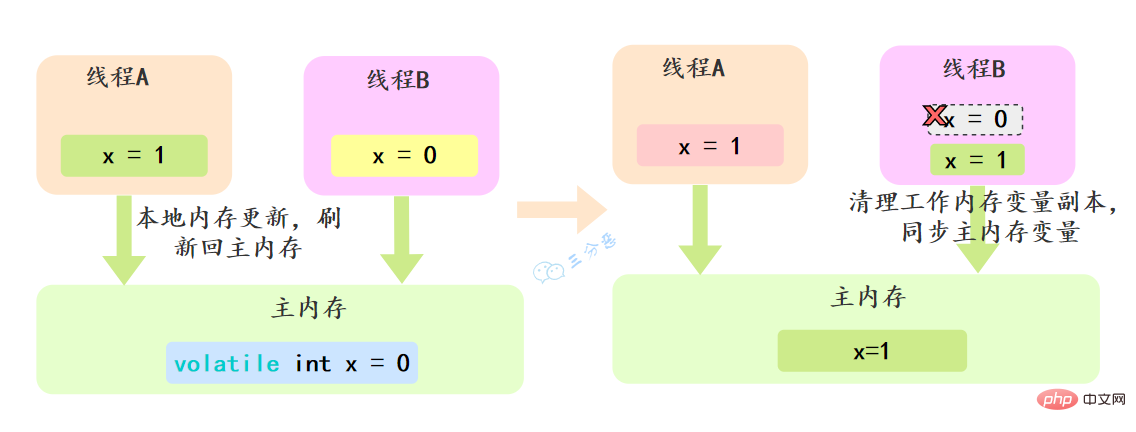
volatile可以确保对某个变量的更新对其他线程马上可见,一个变量被声明为volatile 时,线程在写入变量时不会把值缓存在寄存器或者其他地方,而是会把值刷新回主内存 当其它线程读取该共享变量 ,会从主内存重新获取最新值,而不是使用当前线程的本地内存中的值。
例如,我们声明一个 volatile 变量 volatile int x = 0,线程A修改x=1,修改完之后就会把新的值刷新回主内存,线程B读取x的时候,就会清空本地内存变量,然后再从主内存获取最新值。
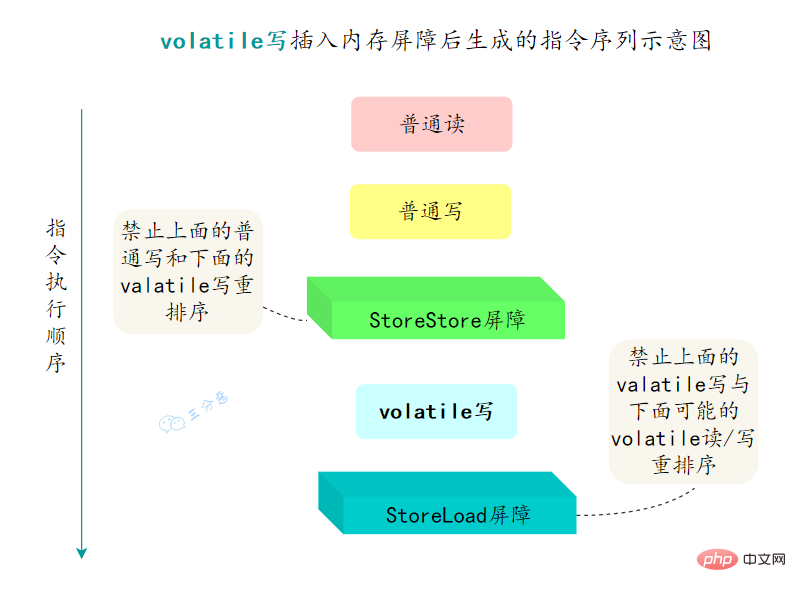
volatile怎么保证有序性的呢?
重排序可以分为编译器重排序和处理器重排序,valatile保证有序性,就是通过分别限制这两种类型的重排序。
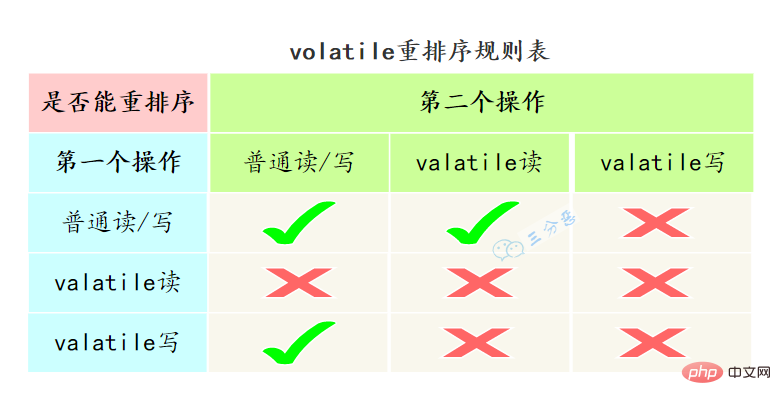
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
- 在每个volatile写操作的前面插入一个
StoreStore屏障 - 在每个volatile写操作的后面插入一个
StoreLoad屏障 - 在每个volatile读操作的后面插入一个
LoadLoad屏障 - 在每个volatile读操作的后面插入一个
LoadStore屏障
24.synchronized用过吗?怎么使用?
synchronized经常用的,用来保证代码的原子性。
synchronized主要有三种用法:
- 修饰实例方法: 作用于当前对象实例加锁,进入同步代码前要获得 当前对象实例的锁
synchronized void method() {
//业务代码}
-
修饰静态方法:也就是给当前类加锁,会作⽤于类的所有对象实例 ,进⼊同步代码前要获得当前 class 的锁。因为静态成员不属于任何⼀个实例对象,是类成员( static 表明这是该类的⼀个静态资源,不管 new 了多少个对象,只有⼀份)。
如果⼀个线程 A 调⽤⼀个实例对象的⾮静态 synchronized ⽅法,⽽线程 B 需要调⽤这个实例对象所属类的静态 synchronized ⽅法,是允许的,不会发⽣互斥现象,因为访问静态 synchronized ⽅法占⽤的锁是当前类的锁,⽽访问⾮静态 synchronized ⽅法占⽤的锁是当前实例对象锁。
synchronized void staic method() {
//业务代码}
- 修饰代码块 :指定加锁对象,对给定对象/类加锁。 synchronized(this|object) 表示进⼊同步代码库前要获得给定对象的锁。 synchronized(类.class) 表示进⼊同步代码前要获得 当前 class 的锁
synchronized(this) {
//业务代码}
25.synchronized的实现原理?
synchronized是怎么加锁的呢?
我们使用synchronized的时候,发现不用自己去lock和unlock,是因为JVM帮我们把这个事情做了。
-
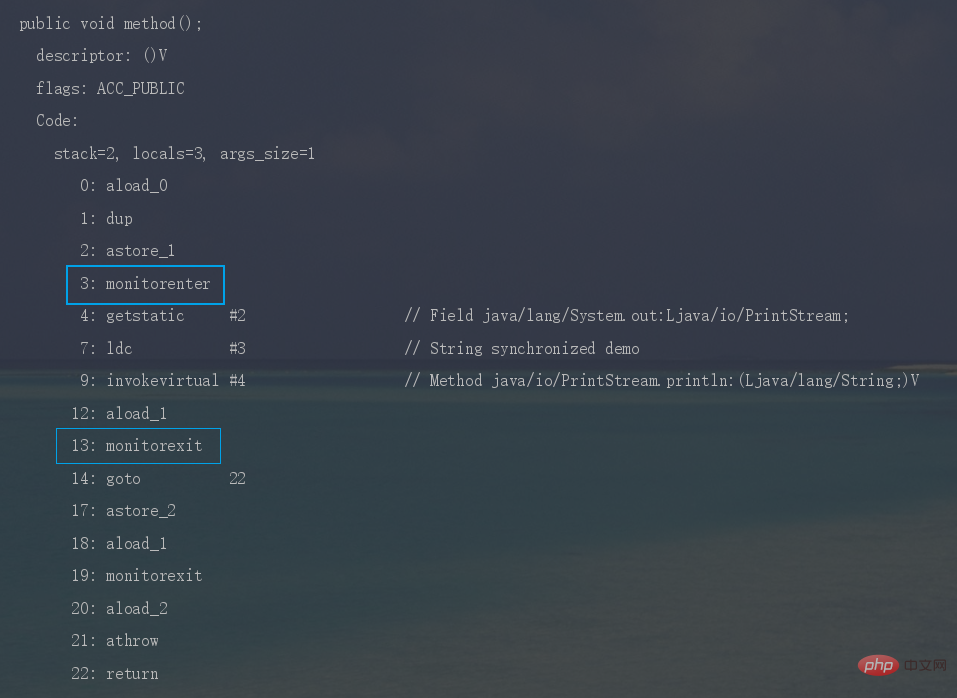
synchronized修饰代码块时,JVM采用
monitorenter、monitorexit两个指令来实现同步,monitorenter指令指向同步代码块的开始位置,monitorexit指令则指向同步代码块的结束位置。反编译一段synchronized修饰代码块代码,
javap -c -s -v -l SynchronizedDemo.class,可以看到相应的字节码指令。
-
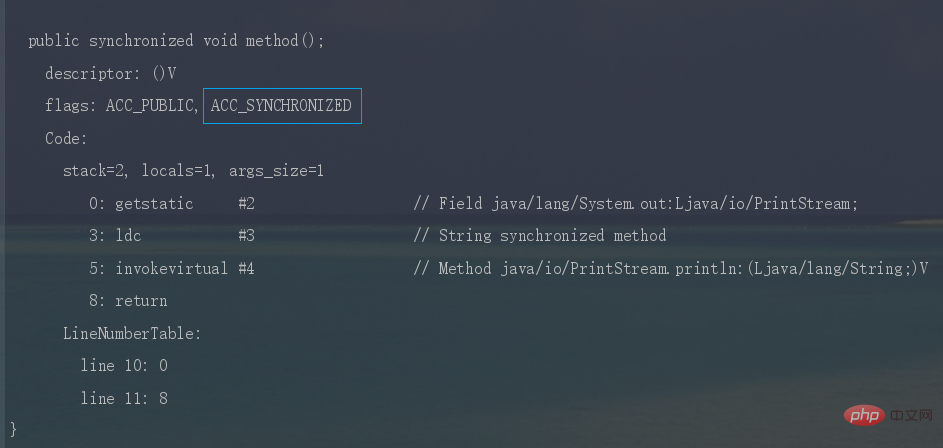
Summarize Java concurrency knowledge points时,JVM采用
ACC_SYNCHRONIZED标记符来实现同步,这个标识指明了该方法是一个同步方法。同样可以写段代码反编译看一下。
synchronized锁住的是什么呢?
monitorenter、monitorexit或者ACC_SYNCHRONIZED都是基于Monitor实现的。
实例对象结构里有对象头,对象头里面有一块结构叫Mark Word,Mark Word指针指向了monitor。
所谓的Monitor其实是一种同步工具,也可以说是一种同步机制。在Java虚拟机(HotSpot)中,Monitor是由ObjectMonitor实现的,可以叫做内部锁,或者Monitor锁。
ObjectMonitor的工作原理:
- ObjectMonitor有两个队列:_WaitSet、_EntryList,用来保存ObjectWaiter 对象列表。
- _owner,获取 Monitor 对象的线程进入 _owner 区时, _count + 1。如果线程调用了 wait() 方法,此时会释放 Monitor 对象, _owner 恢复为空, _count - 1。同时该等待线程进入 _WaitSet 中,等待被唤醒。
ObjectMonitor() {
_header = NULL;
_count = 0; // 记录线程获取锁的次数
_waiters = 0,
_recursions = 0; //锁的重入次数
_object = NULL;
_owner = NULL; // 指向持有ObjectMonitor对象的线程
_WaitSet = NULL; // 处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; // 处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
}
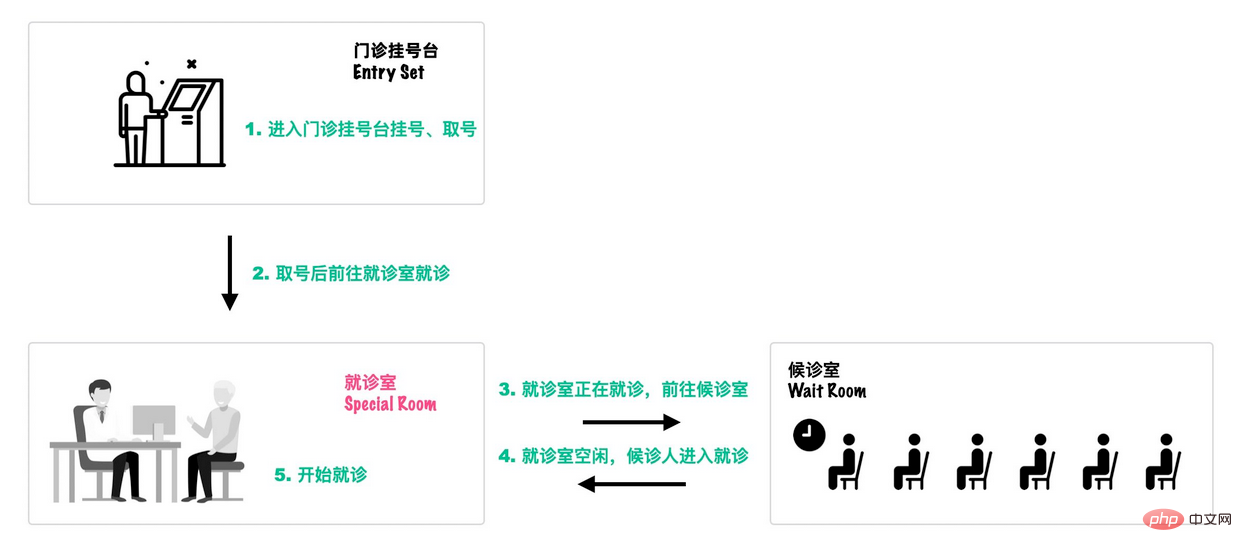
可以类比一个去医院就诊的例子[18]:
首先,患者在门诊大厅前台或自助挂号机进行挂号;
-
随后,挂号结束后患者找到对应的诊室就诊:
- 诊室每次只能有一个患者就诊;
- 如果此时诊室空闲,直接进入就诊;
- 如果此时诊室内有其它患者就诊,那么当前患者进入候诊室,等待叫号;
就诊结束后,走出就诊室,候诊室的下一位候诊患者进入就诊室。
这个过程就和Monitor机制比较相似:
- Outpatient Hall: All threads to be entered must first register at the Entry Set to be eligible;
- Visiting Room: There can only be one thread in the treatment room **_Owner** for treatment. The thread will leave on its own after the treatment.
- Waiting room : When the treatment room is busy, enter to wait. Area (Wait Set) , when the treatment room is free, a new thread will be called from the Waiting Area (Wait Set)
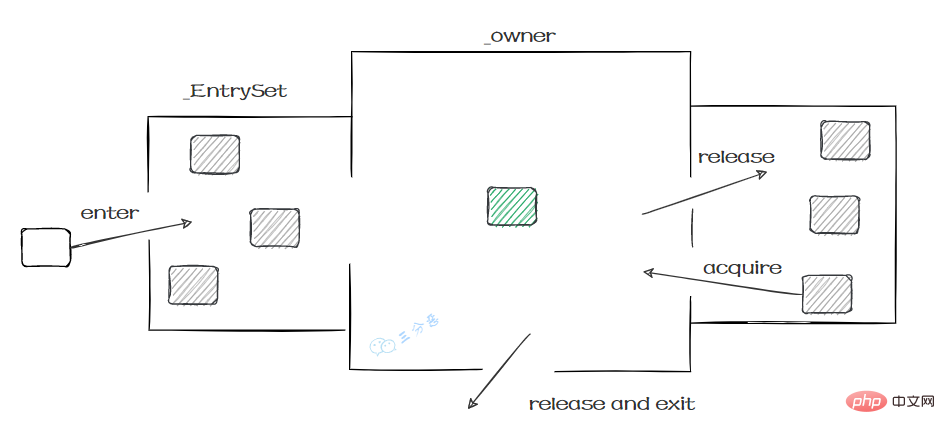
So we You will know what synchronization is locked:
- monitorenter. After judging that it has the synchronization flag ACC_SYNCHRONIZED, the thread that enters this method first will have the owner of the Monitor first. At this time, the counter is 1.
- monitorexit, when exiting after execution, the counter -1, returns to 0 and is obtained by other entering threads.
26. In addition to atomicity, how to achieve synchronized visibility, orderliness, and reentrancy?
How does synchronized ensure visibility?
- Before the thread locks, the value of the shared variable in the working memory will be cleared, so when using the shared variable, you need to re-read the latest value from the main memory.
- After the thread is locked, other threads cannot obtain the shared variables in the main memory.
- Before the thread is unlocked, the latest value of the shared variable must be refreshed to the main memory.
How does synchronized ensure orderliness?
The synchronized code block is exclusive and can only be owned by one thread at a time, so synchronized guarantees that the code is executed by a single thread at the same time.
Because of the existence of as-if-serial semantics, a single-threaded program can ensure that the final result is in order, but there is no guarantee that instructions will not be rearranged.
So the order guaranteed by synchronized is the order of execution results, not the order of preventing instruction reordering.
How does synchronized achieve reentrancy?
synchronized is a reentrant lock, that is, a thread is allowed to request the critical resource of the object lock it holds twice. This situation is called a reentrant lock.
synchronized There is a counter when locking an object. It will record the number of times the thread acquires the lock. After the corresponding code block is executed, the counter will be -1 until the counter is cleared and the lock is released.
The reason is that it is reentrant. This is because the synchronized lock object has a counter, which will count by 1 after the thread acquires the lock, and -1 when the thread completes execution, until it is cleared to release the lock.
27. Lock upgrade? Do you understand synchronized optimization?
In order to unlock and upgrade, you must first know what the status of different locks is. What does this status refer to?
In the Java object header, there is a structure called Mark Word mark field. This structure will change as the lock status changes.
The 64-bit virtual machine Mark Word is 64bit. Let’s take a look at its status changes:
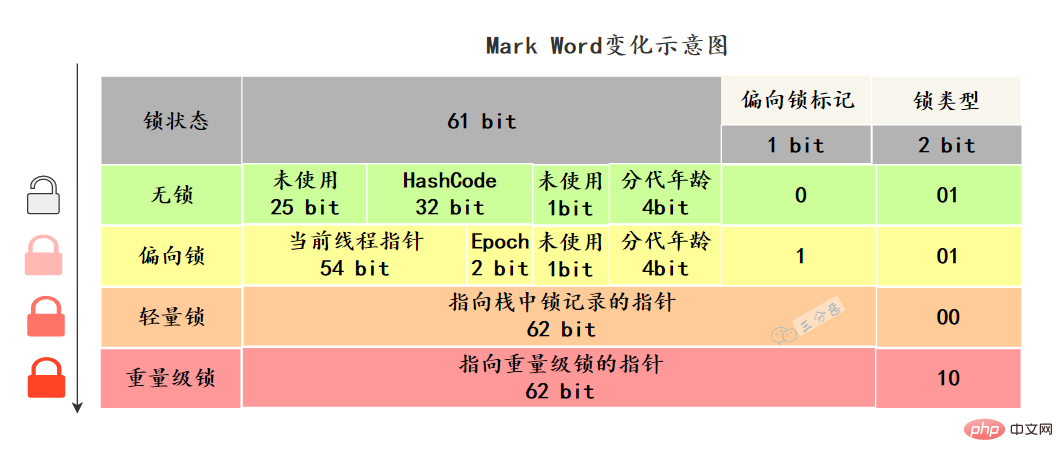
Mark Word stores the running data of the object itself, such asHash code, GC generation age, lock status flag, bias timestamp (Epoch), etc.
What optimizations has synchronized done?
Before JDK1.6, the implementation of synchronized directly called the enter and exit of ObjectMonitor. This kind of lock was called Heavyweight lock. Starting from JDK6, the HotSpot virtual machine development team has optimized locks in Java, such as adding optimization strategies such as adaptive spin, lock elimination, lock coarsening, lightweight locks and biased locks, to improve the performance of synchronized.
Biased lock: In the absence of competition, the current thread pointer is only stored in Mark Word, and no CAS operation is performed.
Lightweight locks: When there is no multi-thread competition, compared to heavyweight locks, the performance consumption caused by operating system mutexes is reduced. However, if there is lock competition, in addition to the overhead of the mutex itself, there is also the additional overhead of the CAS operation.
Spin lock: Reduce unnecessary CPU context switching. When a lightweight lock is upgraded to a heavyweight lock, the spin lock method is used
Lock coarsening: connecting multiple consecutive locking and unlocking operations together , expand into a lock with a larger range.
Lock elimination: When the virtual machine just-in-time compiler is running, it eliminates locks that require synchronization on some codes but are detected as unlikely to have shared data competition.
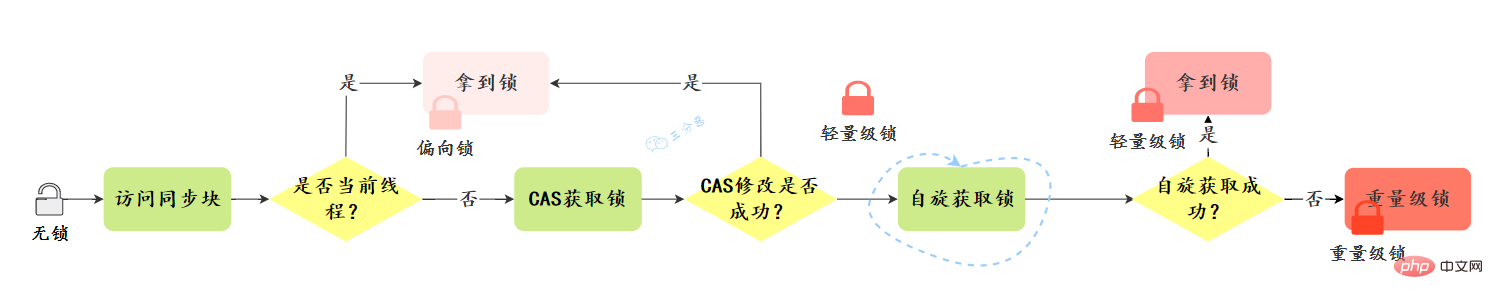
What is the process of lock upgrade?
Lock upgrade direction: No lock –> Bias lock –> Lightweight lock –> Heavyweight lock, this direction is basically irreversible.

Let’s take a look at the upgrade process:
Bias lock:
Acquisition of bias lock:
- Determine whether it is a biasable state – whether the lock flag in MarkWord is '01', whether the biased lock is '1'
- If it is a biasable state, check whether the thread ID is current thread, if so, go to step '5', otherwise go to step '3'
- Compete for the lock through CAS operation, if the competition is successful, set the thread ID in MarkWord to the current thread ID, and then execute '5 ';If the competition fails, execute '4'
- CAS failure to acquire the bias lock indicates competition. When the safepoint is reached, the thread that obtained the biased lock is suspended, The biased lock is upgraded to a lightweight lock, and then the thread blocked at the safepoint continues to execute the synchronization code block
- execution Synchronization code
Revocation of biased lock:
- The biased lock will not be actively released (revoked) and will only be released when other threads compete. To execute the revocation, since the revocation needs to know the stack status of the thread currently holding the biased lock, it must wait until safepoint to execute. At this time, the thread (T) holding the biased lock has two situations: '2' and '3';
- Revocation----The T thread has exited the synchronization code block, or is no longer alive, then the bias lock will be revoked directly and become a lock-free state----If the state reaches the threshold 20, batch re-bias will be executed
- Upgrade----The T thread is still in the synchronization code block, then the biased lock of the T thread is upgraded to a lightweight lock, and the current thread executes the lock in the lightweight lock state Acquisition steps----If the status reaches the threshold 40, perform batch revocation
Lightweight lock:
Acquisition of lightweight lock:
- When performing a locking operation, the jvm will determine whether a heavyweight lock has been obtained. If not, a space will be drawn in the current thread stack frame as the lock record of the lock, and the lock object will be MarkWord is copied to the lock record
- After the copy is successful, jvm uses the CAS operation to update the object header MarkWord to a pointer to the lock record, and points the owner pointer in the lock record to the MarkWord of the object header. If successful, execute '3', otherwise execute '4'
- If the update is successful, the current thread holds the object lock, and the object MarkWord lock flag is set to '00', which means that this object is in a lightweight state. Level lock status
- Update failed, jvm first checks whether the object MarkWord points to the lock record in the current thread stack frame, if so, execute '5', otherwise execute '4'
- Indicates the lock is repeated Enter; then the first part of the lock record (Displaced Mark Word) is added to the current thread stack frame as null and points to the Mark Word lock object, which acts as a reentrancy counter.
- Indicates that the lock object has been preempted by other threads, then spin wait (default 10 times), if the number of waits reaches the threshold and the lock is not acquired, then is upgraded to weight Level lock
Generally simplified upgrade process:
Complete upgrade process:
![synchronized 锁升级过程-来源参考[14]](https://img.php.cn/upload/article/000/000/067/2ef068e2d2216314dc9ad545dda17019-36.png)
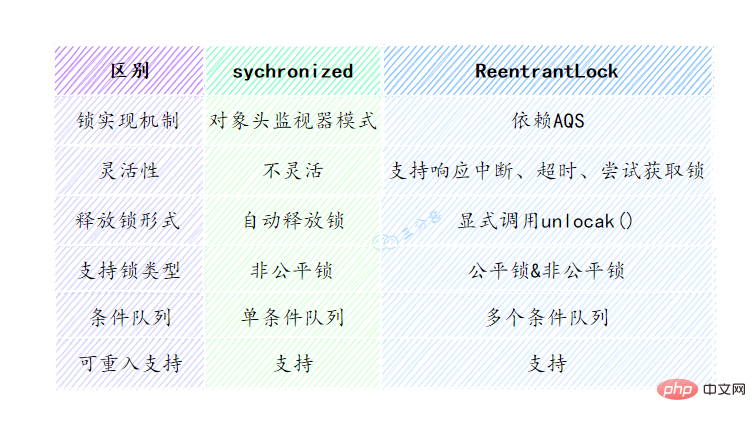
28. Talk about the difference between synchronized and ReentrantLock?
You can answer this question from several dimensions such as lock implementation, functional characteristics, and performance:
- Lock implementation: synchronized is the key to the Java language Word, implemented based on JVM. ReentrantLock is implemented based on the API level of JDK (usually the lock() and unlock() methods are combined with the try/finally statement block.)
- Performance: In JDK1.6 lock Before optimization, the performance of synchronized was much worse than ReenTrantLock. However, since JDK6, adaptive spin, lock elimination, etc. have been added, and the performance of the two is almost the same.
-
Functional features: ReentrantLock adds some advanced features than synchronized, such as interruptible waiting, fair locking, and selective notification.
- ReentrantLock provides a mechanism that can interrupt threads waiting for locks. This mechanism is implemented through lock.lockInterruptibly()
- ReentrantLock can specify whether it is a fair lock or an unfair lock. And synchronized can only be an unfair lock. The so-called fair lock means that the thread waiting first obtains the lock first.
- synchronized is combined with the wait() and notify()/notifyAll() methods to implement the waiting/notification mechanism. The ReentrantLock class is implemented with the help of the Condition interface and the newCondition() method.
- ReentrantLock needs to be declared manually to lock and release the lock, usually in conjunction with finally to release the lock. Synchronized does not need to manually release the lock.
The following table lists the differences between the two locks:
29. How much do you know about AQS ?
AbstractQueuedSynchronizer Abstract Synchronization Queue, referred to as AQS, is the foundation of the Java concurrent package. The locks in the concurrent package are implemented based on AQS.
- AQS是基于一个FIFO的双向队列,其内部定义了一个节点类Node,Node 节点内部的 SHARED 用来标记该线程是获取共享资源时被阻挂起后放入AQS 队列的, EXCLUSIVE 用来标记线程是 取独占资源时被挂起后放入AQS 队列
- AQS 使用一个 volatile 修饰的 int 类型的成员变量 state 来表示同步状态,修改同步状态成功即为获得锁,volatile 保证了变量在多线程之间的可见性,修改 State 值时通过 CAS 机制来保证修改的原子性
- 获取state的方式分为两种,独占方式和共享方式,一个线程使用独占方式获取了资源,其它线程就会在获取失败后被阻塞。一个线程使用共享方式获取了资源,另外一个线程还可以通过CAS的方式进行获取。
- 如果共享资源被占用,需要一定的阻塞等待唤醒机制来保证锁的分配,AQS 中会将竞争共享资源失败的线程添加到一个变体的 CLH 队列中。
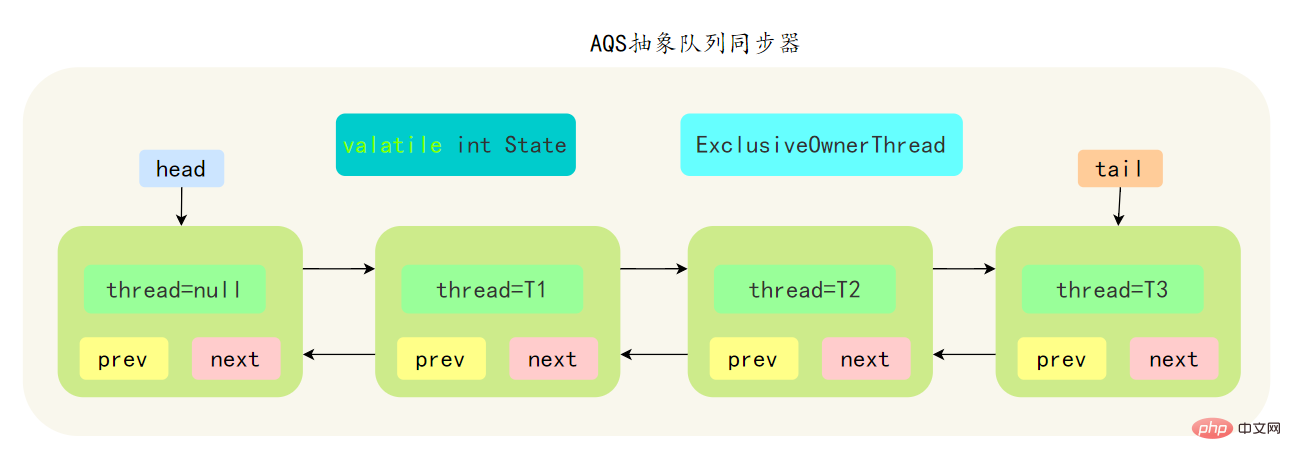 先简单了解一下CLH:Craig、Landin and Hagersten 队列,是 单向链表实现的队列。申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现 前驱节点释放了锁就结束自旋
先简单了解一下CLH:Craig、Landin and Hagersten 队列,是 单向链表实现的队列。申请线程只在本地变量上自旋,它不断轮询前驱的状态,如果发现 前驱节点释放了锁就结束自旋
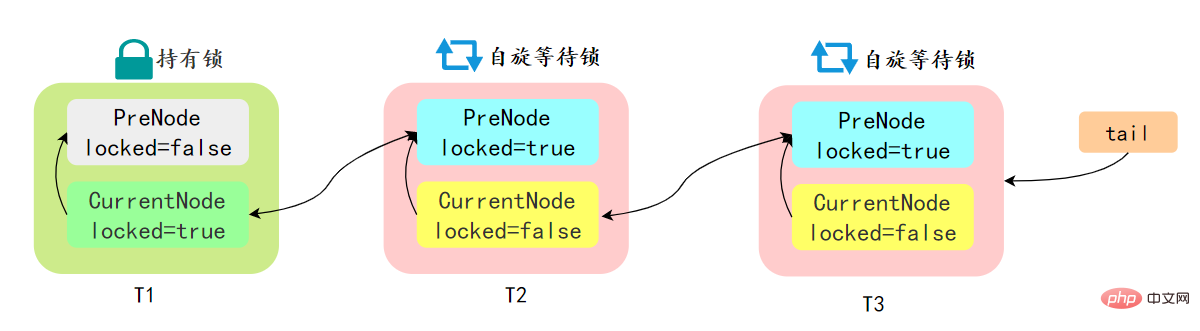
AQS 中的队列是 CLH 变体的虚拟双向队列,通过将每条请求共享资源的线程封装成一个节点来实现锁的分配:
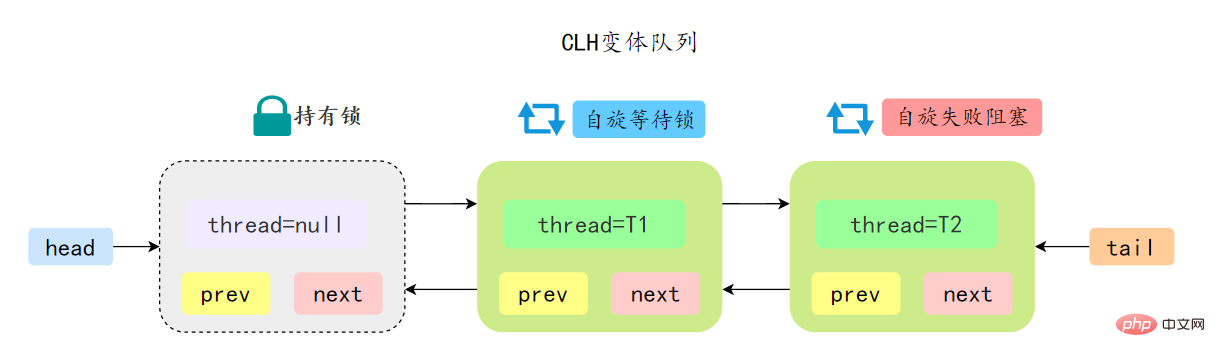
AQS 中的 CLH 变体等待队列拥有以下特性:
- AQS 中队列是个双向链表,也是 FIFO 先进先出的特性
- 通过 Head、Tail 头尾两个节点来组成队列结构,通过 volatile 修饰保证可见性
- Head 指向节点为已获得锁的节点,是一个虚拟节点,节点本身不持有具体线程
- 获取不到同步状态,会将节点进行自旋获取锁,自旋一定次数失败后会将线程阻塞,相对于 CLH 队列性能较好
ps:AQS源码里面有很多细节可问,建议有时间好好看看AQS源码。
30.ReentrantLock实现原理?
ReentrantLock 是可重入的独占锁,只能有一个线程可以获取该锁,其它获取该锁的线程会被阻塞而被放入该锁的阻塞队列里面。
看看ReentrantLock的加锁操作:
// 创建非公平锁
ReentrantLock lock = new ReentrantLock();
// 获取锁操作
lock.lock();
try {
// 执行代码逻辑
} catch (Exception ex) {
// ...
} finally {
// 解锁操作
lock.unlock();
}
new ReentrantLock()构造函数默认创建的是非公平锁 NonfairSync。
公平锁 FairSync
- 公平锁是指多个线程按照申请锁的顺序来获取锁,线程直接进入队列中排队,队列中的第一个线程才能获得锁
- 公平锁的优点是等待锁的线程不会饿死。缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU 唤醒阻塞线程的开销比非公平锁大
非公平锁 NonfairSync
- 非公平锁是多个线程加锁时直接尝试获取锁,获取不到才会到等待队列的队尾等待。但如果此时锁刚好可用,那么这个线程可以无需阻塞直接获取到锁
- 非公平锁的优点是可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获得锁,CPU 不必唤醒所有线程。缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁
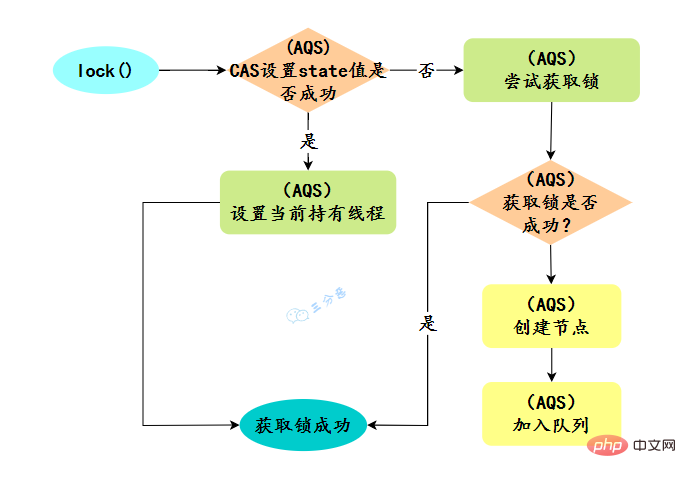
默认创建的对象lock()的时候:
- 如果锁当前没有被其它线程占用,并且当前线程之前没有获取过该锁,则当前线程会获取到该锁,然后设置当前锁的拥有者为当前线程,并设置 AQS 的状态值为1 ,然后直接返回。如果当前线程之前己经获取过该锁,则这次只是简单地把 AQS 的状态值加1后返回。
- 如果该锁己经被其他线程持有,非公平锁会尝试去获取锁,获取失败的话,则调用该方法线程会被放入 AQS 队列阻塞挂起。
31.ReentrantLock怎么实现公平锁的?
new ReentrantLock()构造函数默认创建的是非公平锁 NonfairSync
public ReentrantLock() {
sync = new NonfairSync();}
同时也可以在创建锁构造函数中传入具体参数创建公平锁 FairSync
ReentrantLock lock = new ReentrantLock(true);--- ReentrantLock// true 代表公平锁,false 代表非公平锁public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();}
FairSync、NonfairSync 代表公平锁和非公平锁,两者都是 ReentrantLock 静态内部类,只不过实现不同锁语义。
非公平锁和公平锁的两处不同:
- After calling lock for an unfair lock, CAS will first be called to grab the lock. If the lock happens to be not occupied at this time, the lock will be obtained directly and returned.
- After the CAS fails, the unfair lock will enter the tryAcquire method like the fair lock. In the tryAcquire method, if the lock is found to be released at this time (state == 0), the unfair lock will directly CAS Grab the lock, but the fair lock will determine whether there is a thread in the waiting queue in the waiting state. If there is, it will not grab the lock and will be queued to the back.
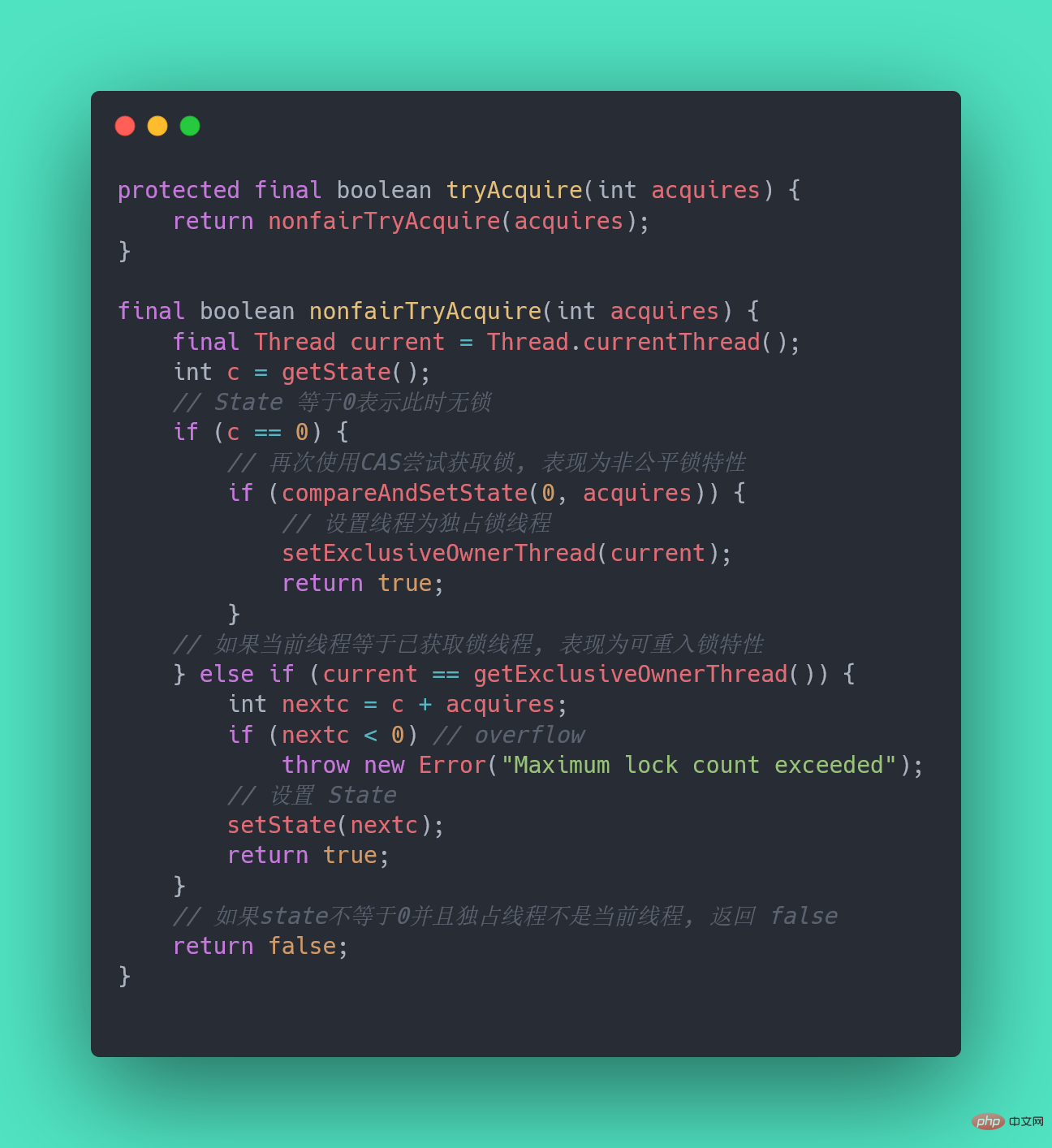
# Relatively speaking, unfair lock will have better performance because its throughput is relatively large. Of course, unfair locks make the time to acquire the lock more uncertain, which may cause threads in the blocking queue to be starved for a long time.
32.What about CAS? What does CAS know?
CAS is called CompareAndSwap, which compares and swaps. It mainly uses processor instructions to ensure the atomicity of the operation.
The CAS instruction contains 3 parameters: the memory address A of the shared variable, the expected value B, and the new value C of the shared variable.
Only when the value at address A in memory is equal to B, the value at address A in memory can be updated to the new value C. As a CPU instruction, the CAS instruction itself can guarantee atomicity.
33.What’s wrong with CAS? How to solve?
The three classic problems of CAS:
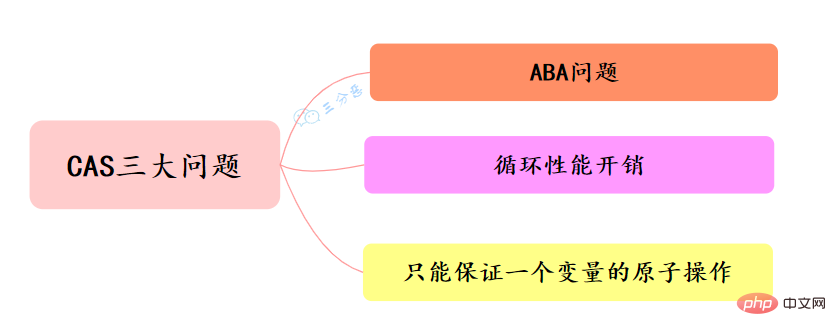
ABA problem
In a concurrent environment, assuming that the initial condition is A, when modifying the data , if it is found to be A, the modification will be performed. But although what you see is A, A may have changed into B, and B changed back to A again. At this time, A is no longer the other A. Even if the data is successfully modified, there may be problems.
How to solve the ABA problem?
- Add version number
Every time a variable is modified, 1 is added to the version number of the variable. In this way, just A->B-> ;A, although the value of A has not changed, its version number has changed. If you judge the version number again, you will find that A has been changed at this time. Referring to the version number of optimistic locking, this approach can bring a practical test to the data.
Java provides the AtomicStampReference class. Its compareAndSet method first checks whether the current object reference value is equal to the expected reference, and whether the current stamp (Stamp) flag is equal to the expected flag. If all are equal, atomically The reference value and stamp value are updated to the given update value.
Loop performance overhead
Spin CAS, if it is executed in a loop without success, it will bring very large execution overhead to the CPU.
How to solve the loop performance overhead problem?
In Java, many places where spin CAS is used will have a limit on the number of spins. If it exceeds a certain number, the spin will stop.
Can only guarantee the atomic operation of one variable
CAS guarantees the atomicity of the operation on a variable. If multiple variables are operated on, CAS currently cannot directly guarantee the atomicity of the operation. of.
How to solve the problem of atomic operation that can only guarantee one variable?
- You can consider using locks to ensure the atomicity of operations
- You can consider merging multiple variables, encapsulating multiple variables into an object, and ensuring atomicity through AtomicReference sex.
34.What are the methods to ensure atomicity in Java? How to ensure that the i result is correct under multi-threading?
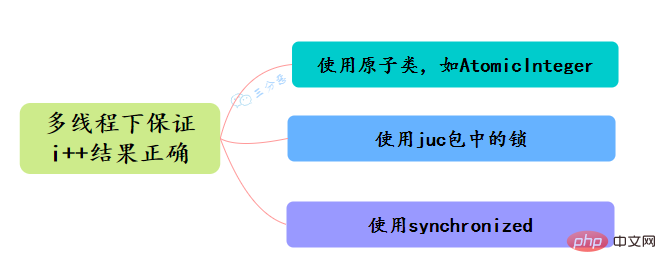
- Use cyclic atomic classes, such as AtomicInteger, to implement i atomic operations
- Use locks under the juc package, such as ReentrantLock, to add i operations Lock lock.lock() to achieve atomicity
- Use synchronized to lock the i operation
35. How much do you know about the atomic operation class?
When the program updates a variable, if multiple threads update the variable at the same time, unexpected values may be obtained. For example, variable i=1, thread A updates i 1, and thread B also updates i 1. After two After a thread operation, i may not be equal to 3, but equal to 2. Because threads A and B get i both as 1 when updating variable i, this is a thread-unsafe update operation. Generally, we will use synchronized to solve this problem. Synchronized will ensure that multiple threads will not update variable i at the same time.
In fact, in addition to this, there are more lightweight options. Java has provided the java.util.concurrent.atomic package since JDK 1.5. The atomic operation class in this package provides a simple usage , a performance-efficient, thread-safe way to update a variable.
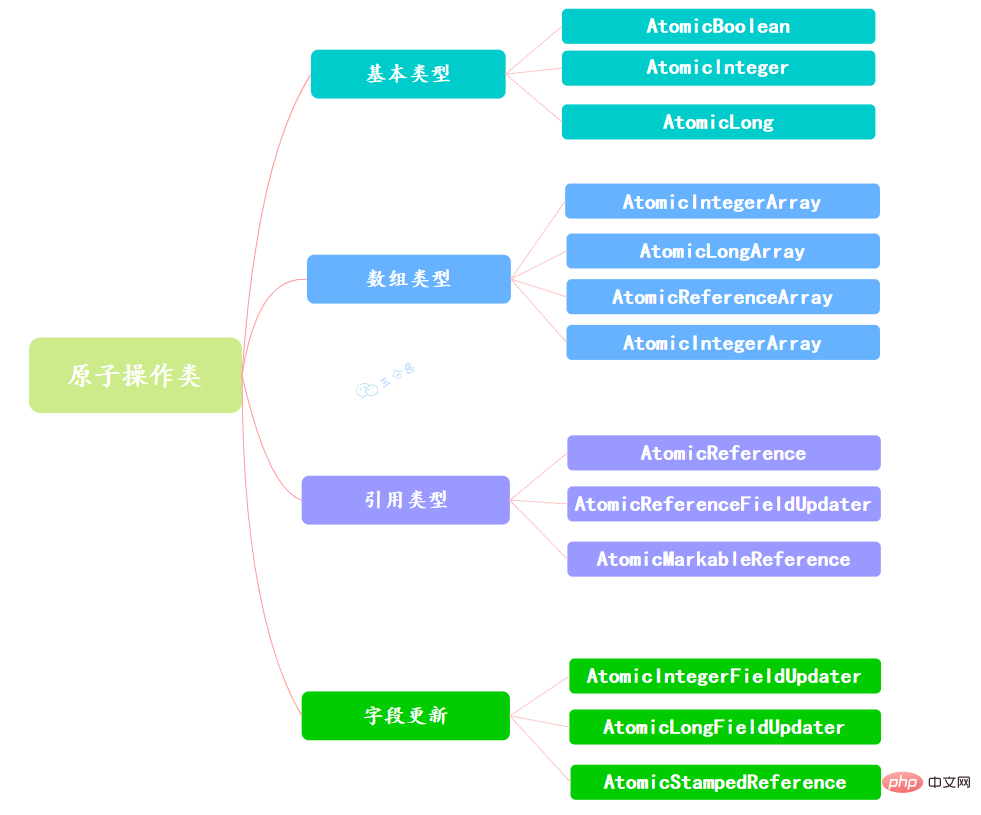
Because there are many types of variables, a total of 13 classes are provided in the Atomic package, which belong to 4 types of atomic update methods, namely atomic update basic type, atomic update array, atomic update reference and Atomic update of properties (fields).
#The classes in the Atomic package are basically wrapper classes implemented using Unsafe.
使用原子的方式更新基本类型,Atomic包提供了以下3个类:
AtomicBoolean:原子更新布尔类型。
AtomicInteger:原子更新整型。
AtomicLong:原子更新长整型。
通过原子的方式更新数组里的某个元素,Atomic包提供了以下4个类:
AtomicIntegerArray:原子更新整型数组里的元素。
AtomicLongArray:原子更新长整型数组里的元素。
AtomicReferenceArray:原子更新引用类型数组里的元素。
AtomicIntegerArray类主要是提供原子的方式更新数组里的整型
原子更新基本类型的AtomicInteger,只能更新一个变量,如果要原子更新多个变量,就需要使用这个原子更新引用类型提供的类。Atomic包提供了以下3个类:
AtomicReference:原子更新引用类型。
AtomicReferenceFieldUpdater:原子更新引用类型里的字段。
AtomicMarkableReference:原子更新带有标记位的引用类型。可以原子更新一个布尔类型的标记位和引用类型。构造方法是AtomicMarkableReference(V initialRef,boolean initialMark)。
如果需原子地更新某个类里的某个字段时,就需要使用原子更新字段类,Atomic包提供了以下3个类进行原子字段更新:
- AtomicIntegerFieldUpdater:原子更新整型的字段的更新器。
- AtomicLongFieldUpdater:原子更新长整型字段的更新器。
- AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于原子的更新数据和数据的版本号,可以解决使用CAS进行原子更新时可能出现的 ABA问题。
36.AtomicInteger 的原理?
一句话概括:使用CAS实现。
以AtomicInteger的添加方法为例:
public final int getAndIncrement() {
return unsafe.getAndAddInt(this, valueOffset, 1);
}
通过Unsafe类的实例来进行添加操作,来看看具体的CAS操作:
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
compareAndSwapInt 是一个native方法,基于CAS来操作int类型变量。其它的Summarize Java concurrency knowledge points基本都是大同小异。
37.线程死锁了解吗?该如何避免?
死锁是指两个或两个以上的线程在执行过程中,因争夺资源而造成的互相等待的现象,在无外力作用的情况下,这些线程会一直相互等待而无法继续运行下去。
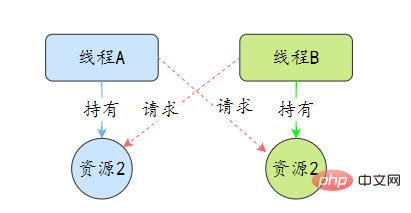
那么为什么会产生死锁呢? 死锁的产生必须具备以下四个条件:
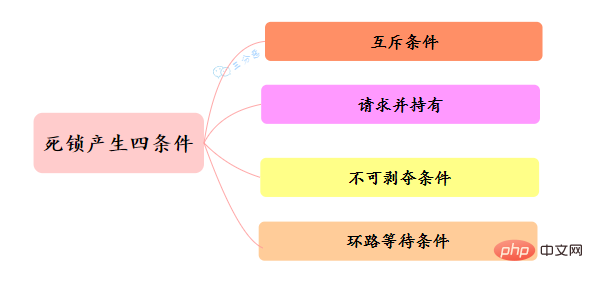
- 互斥条件:指线程对己经获取到的资源进行它性使用,即该资源同时只由一个线程占用。如果此时还有其它线程请求获取获取该资源,则请求者只能等待,直至占有资源的线程释放该资源。
- 请求并持有条件:指一个 线程己经持有了至少一个资源,但又提出了新的资源请求,而新资源己被其它线程占有,所以当前线程会被阻塞,但阻塞 的同时并不释放自己已经获取的资源。
- 不可剥夺条件:指线程获取到的资源在自己使用完之前不能被其它线程抢占,只有在自己使用完毕后才由自己释放该资源。
- 环路等待条件:指在发生死锁时,必然存在一个线程——资源的环形链,即线程集合 {T0,T1,T2,…… ,Tn} 中 T0 正在等待一 T1 占用的资源,Tl1正在等待 T2用的资源,…… Tn 在等待己被 T0占用的资源。
该如何避免死锁呢?答案是至少破坏死锁发生的一个条件。
其中,互斥这个条件我们没有办法破坏,因为用锁为的就是互斥。不过其他三个条件都是有办法破坏掉的,到底如何做呢?
对于“请求并持有”这个条件,可以一次性请求所有的资源。
对于“不可剥夺”这个条件,占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源,这样不可抢占这个条件就破坏掉了。
对于“环路等待”这个条件,可以靠按序申请资源来预防。所谓按序申请,是指资源是有线性顺序的,申请的时候可以先申请资源序号小的,再申请资源序号大的,这样线性化后就不存在环路了。
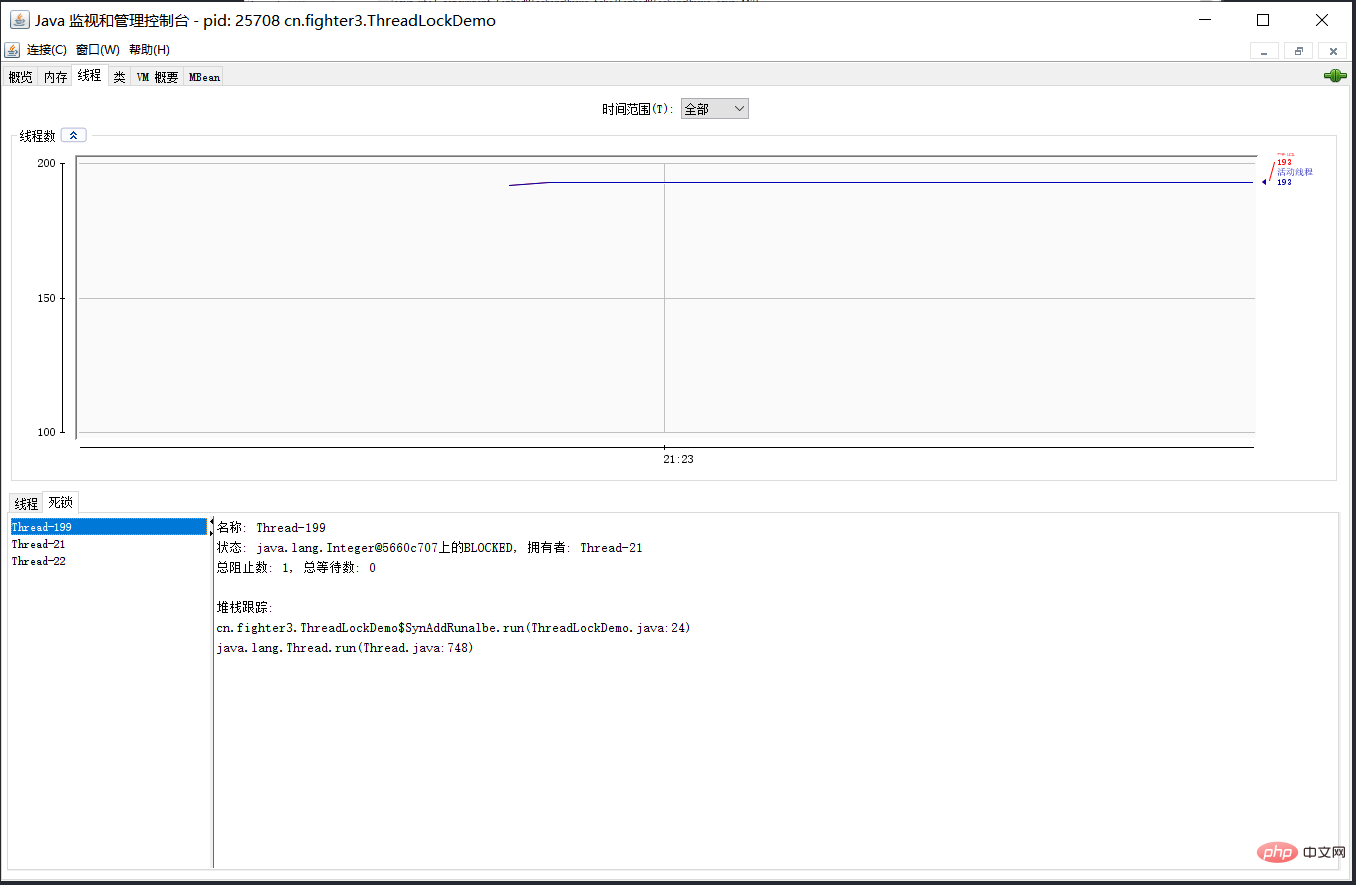
38.那死锁问题怎么排查呢?
可以使用jdk自带的命令行工具排查:
- 使用jps查找运行的Java进程:jps -l
- 使用jstack查看线程堆栈信息:jstack -l 进程id
基本就可以看到死锁的信息。
还可以利用图形化工具,比如JConsole。出现线程死锁以后,点击JConsole线程面板的检测到死锁按钮,将会看到线程的死锁信息。
39.CountDownLatch(倒计数器)了解吗?
CountDownLatch,倒计数器,有两个常见的应用场景[18]:
场景1:协调子线程结束动作:等待所有子线程运行结束
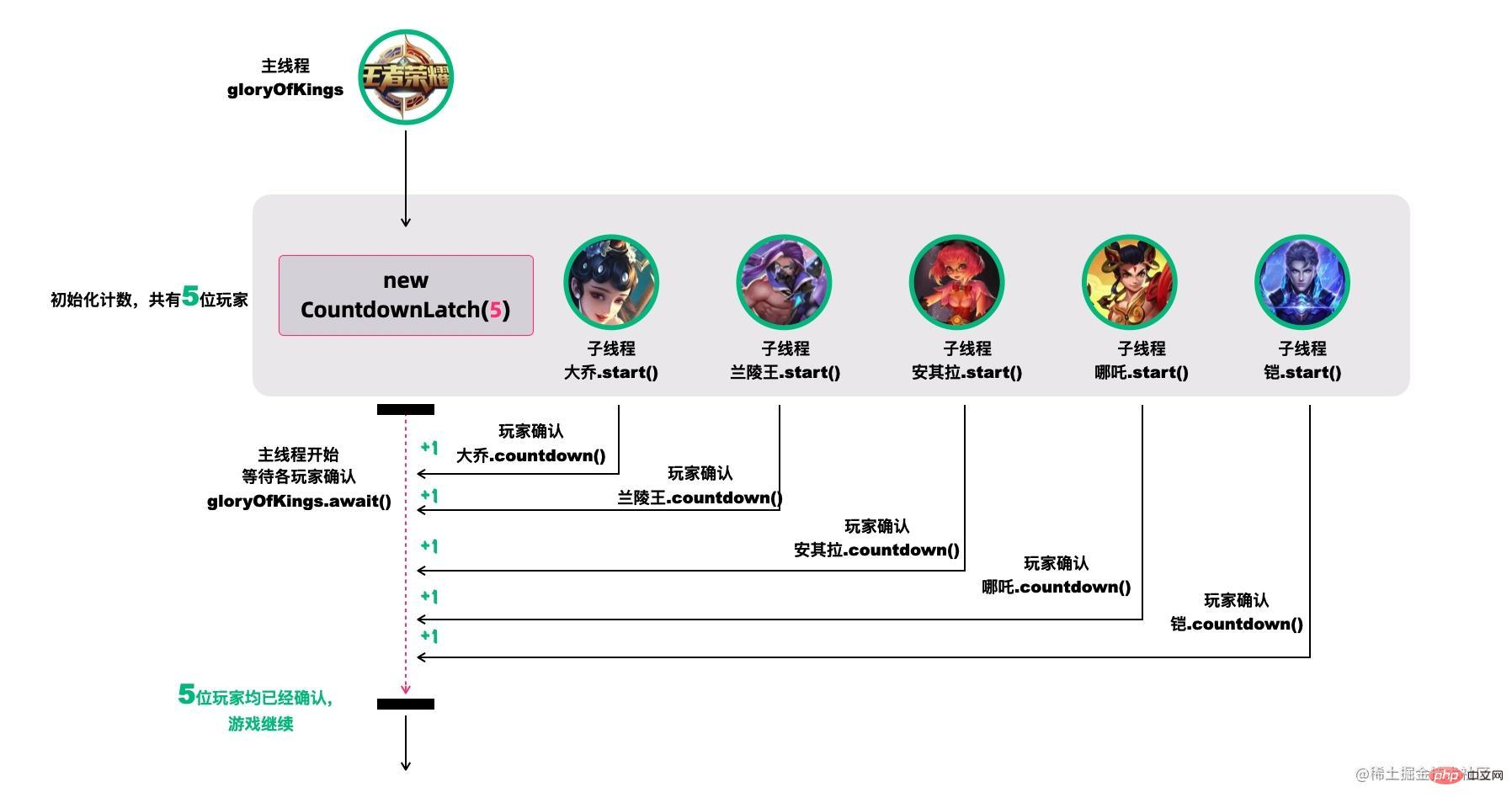
CountDownLatch允许一个或多个线程等待其他线程完成操作。
例如,我们很多人喜欢玩的王者荣耀,开黑的时候,得等所有人都上线之后,才能开打。
CountDownLatch模仿这个场景(参考[18]):
创建大乔、兰陵王、安其拉、哪吒和铠等五个玩家,主线程必须在他们都完成确认后,才可以继续运行。
在这段代码中,new CountDownLatch(5)用户创建初始的latch数量,各玩家通过countDownLatch.countDown()完成状态确认,主线程通过countDownLatch.await()等待。
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(5);
Thread 大乔 = new Thread(countDownLatch::countDown);
Thread 兰陵王 = new Thread(countDownLatch::countDown);
Thread 安其拉 = new Thread(countDownLatch::countDown);
Thread 哪吒 = new Thread(countDownLatch::countDown);
Thread 铠 = new Thread(() -> {
try {
// 稍等,上个卫生间,马上到...
Thread.sleep(1500);
countDownLatch.countDown();
} catch (InterruptedException ignored) {}
});
大乔.start();
兰陵王.start();
安其拉.start();
哪吒.start();
铠.start();
countDownLatch.await();
System.out.println("所有玩家已经就位!");
}
场景2. 协调子线程开始动作:统一各线程动作开始的时机
王者游戏中也有类似的场景,游戏开始时,各玩家的初始状态必须一致。不能有的玩家都出完装了,有的才降生。
所以大家得一块出生,在

在这个场景中,仍然用五个线程代表大乔、兰陵王、安其拉、哪吒和铠等五个玩家。需要注意的是,各玩家虽然都调用了start()线程,但是它们在运行时都在等待countDownLatch的信号,在信号未收到前,它们不会往下执行。
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(1);
Thread 大乔 = new Thread(() -> waitToFight(countDownLatch));
Thread 兰陵王 = new Thread(() -> waitToFight(countDownLatch));
Thread 安其拉 = new Thread(() -> waitToFight(countDownLatch));
Thread 哪吒 = new Thread(() -> waitToFight(countDownLatch));
Thread 铠 = new Thread(() -> waitToFight(countDownLatch));
大乔.start();
兰陵王.start();
安其拉.start();
哪吒.start();
铠.start();
Thread.sleep(1000);
countDownLatch.countDown();
System.out.println("敌方还有5秒达到战场,全军出击!");
}
private static void waitToFight(CountDownLatch countDownLatch) {
try {
countDownLatch.await(); // 在此等待信号再继续
System.out.println("收到,发起进攻!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
CountDownLatch的核心方法也不多:
-
await():等待latch降为0; -
boolean await(long timeout, TimeUnit unit):等待latch降为0,但是可以设置超时时间。比如有玩家超时未确认,那就重新匹配,总不能为了某个玩家等到天荒地老。 -
countDown():latch数量减1; -
getCount():获取当前的latch数量。
40.CyclicBarrier(同步屏障)了解吗?
CyclicBarrier的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一 组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
它和CountDownLatch类似,都可以协调多线程的结束动作,在它们结束后都可以执行特定动作,但是为什么要有CyclicBarrier,自然是它有和CountDownLatch不同的地方。
不知道你听没听过一个新人UP主小约翰可汗,小约翰生平有两大恨——“Summarize Java concurrency knowledge points”我们来还原一下事情的经过:小约翰在亲政后认识了新垣结衣,于是决定第一次选妃,向结衣表白,等待回应。然而新垣结衣回应嫁给了星野源,小约翰伤心欲绝,发誓生平不娶,突然发现了铃木爱理,于是小约翰决定第二次选妃,求爱理搭理,等待回应。

我们拿代码模拟这一场景,发现CountDownLatch无能为力了,因为CountDownLatch的使用是一次性的,无法重复利用,而这里等待了两次。此时,我们用CyclicBarrier就可以实现,因为它可以重复利用。
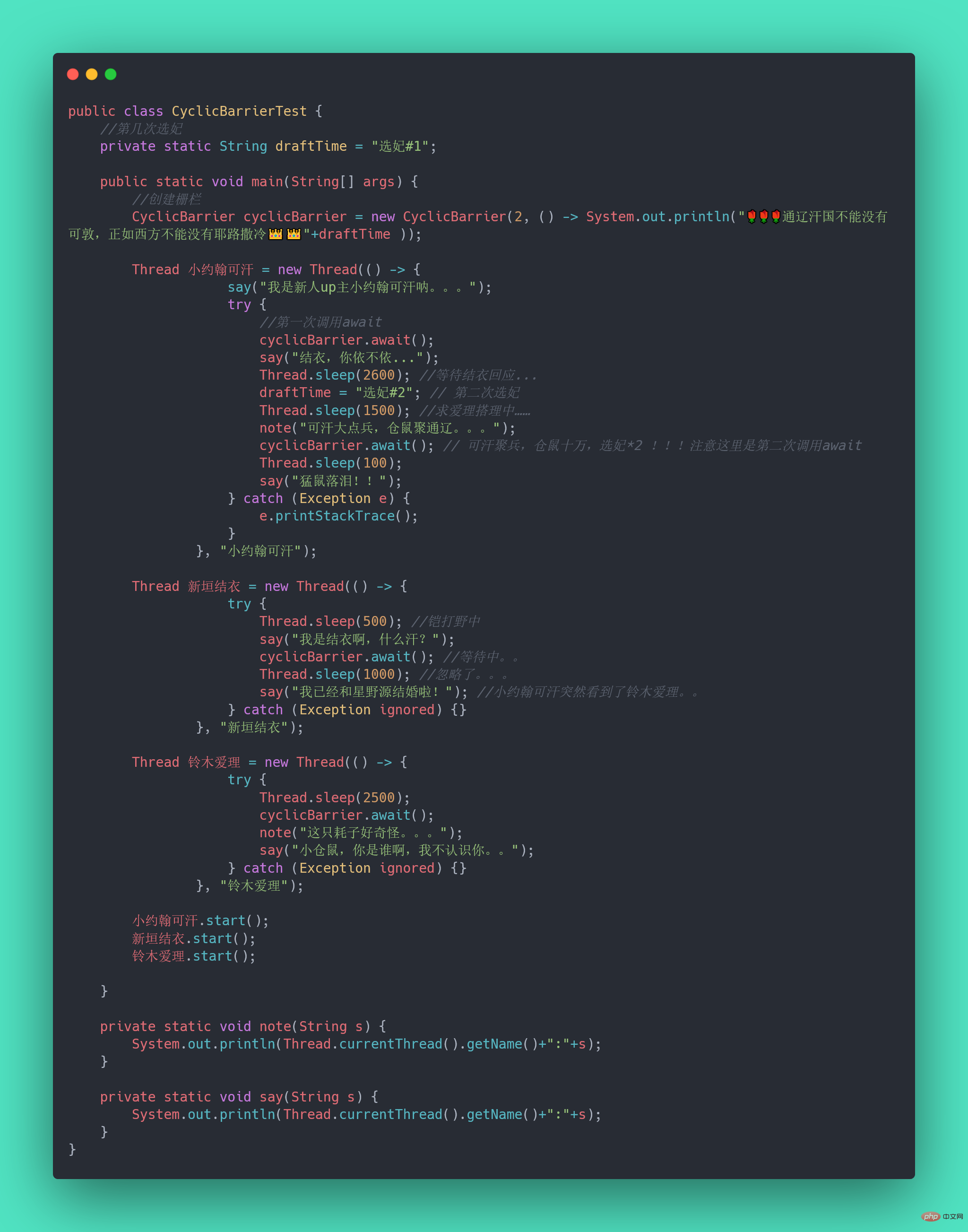
Summarize Java concurrency knowledge points:

CyclicBarrier最最核心的方法,仍然是await():
- 如果当前线程不是第一个到达屏障的话,它将会进入等待,直到其他线程都到达,除非发生被中断、屏障被拆除、屏障被重设等情况;
上面的例子抽象一下,本质上它的流程就是这样就是这样:
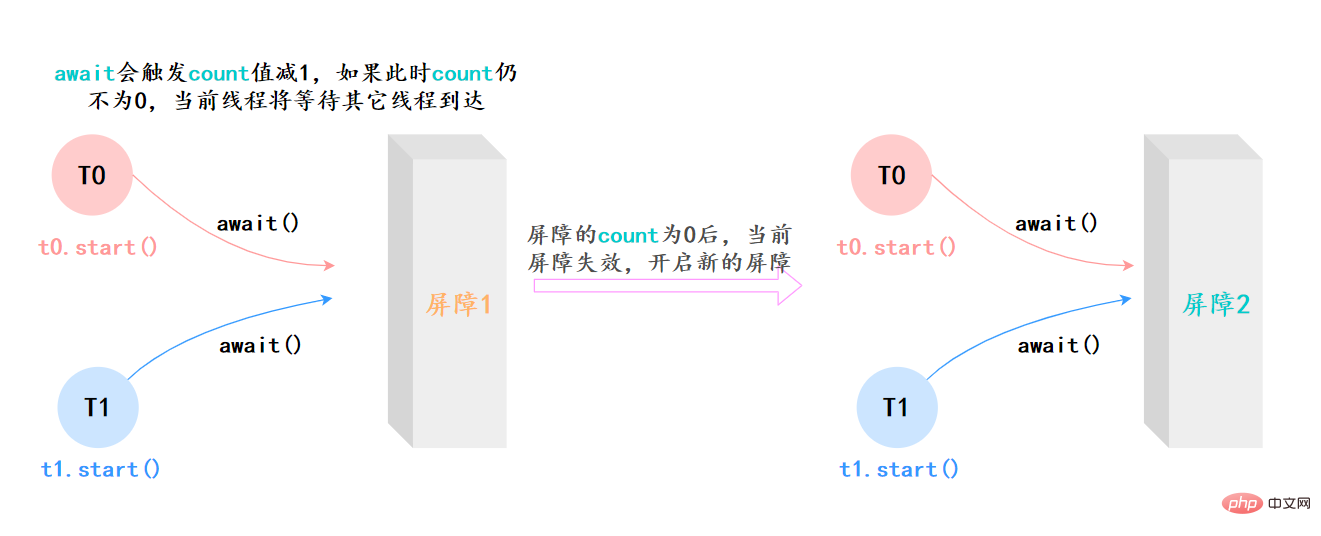
41.CyclicBarrier和CountDownLatch有什么区别?
两者最核心的区别[18]:
- CountDownLatch is a one-time use, while CyclicBarrier can set the barrier multiple times for reuse;
- Each sub-thread in CountDownLatch cannot wait for other threads and can only complete its own tasks; Each thread in CyclicBarrier can wait for other threads
Their differences are organized in a table:
| CyclicBarrier | CountDownLatch |
|---|---|
| CyclicBarrier is reusable, and the threads in it will wait for all threads to complete their tasks. At that time, the barrier will be removed and some specific actions can be selectively performed. | CountDownLatch is one-time, different threads work on the same counter until the counter is 0. |
| CyclicBarrier is oriented to the number of threads | CountDownLatch is oriented to the number of tasks |
| When using CyclicBarrier, you must specify the number of threads participating in the collaboration in the construction, and these threads must call the await() method | When using CountDownLatch, you must specify the number of tasks. It does not matter which threads complete these tasks. |
| CyclicBarrier can be reused after all threads are released | CountDownLatch When the counter is 0, it can no longer be used. |
| In CyclicBarrier, if a thread encounters an interruption, timeout, etc., the thread in await will have problems | In CountDownLatch, if a problem occurs in one thread, other threads will not be affected |
42.Semaphore(信号量)了解吗?
Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。
听起来似乎很抽象,现在汽车多了,开车出门在外的一个老大难问题就是停车 。停车场的车位是有限的,只能允许若干车辆停泊,如果停车场还有空位,那么显示牌显示的就是绿灯和剩余的车位,车辆就可以驶入;如果停车场没位了,那么显示牌显示的就是绿灯和数字0,车辆就得等待。如果满了的停车场有车离开,那么显示牌就又变绿,显示空车位数量,等待的车辆就能进停车场。

我们把这个例子类比一下,车辆就是线程,进入停车场就是线程在执行,离开停车场就是线程执行完毕,看见红灯就表示线程被阻塞,不能执行,Semaphore的本质就是协调多个线程对共享资源的获取。
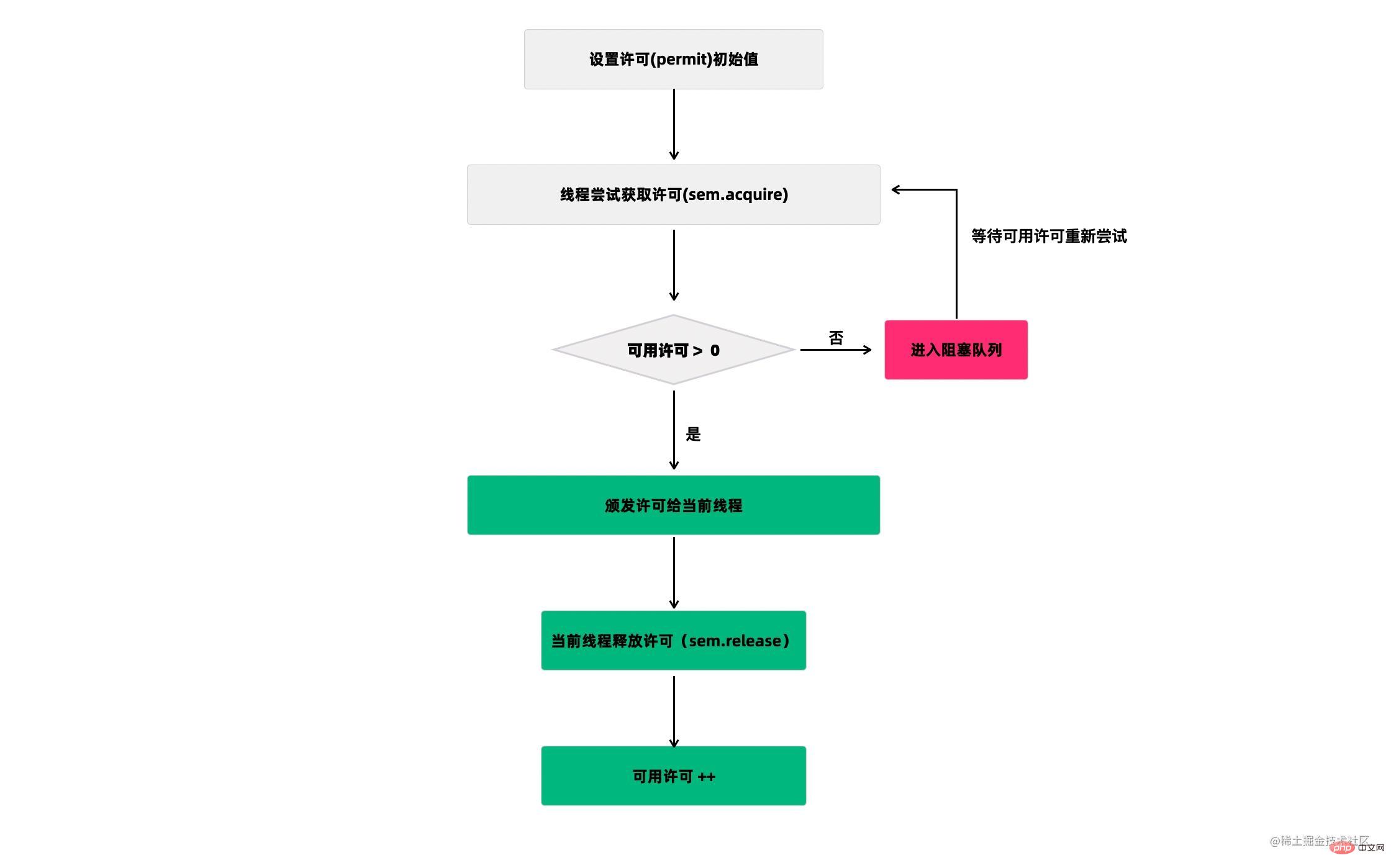
我们再来看一个Semaphore的用途:它可以用于做流量控制,特别是公用资源有限的应用场景,比如数据库连接。
假如有一个需求,要读取几万个文件的数据,因为都是IO密集型任务,我们可以启动几十个线程并发地读取,但是如果读到内存后,还需要存储到数据库中,而数据库的连接数只有10个,这时我们必须控制只有10个线程同时获取数据库连接保存数据,否则会报错无法获取数据库连接。这个时候,就可以使用Semaphore来做流量控制,如下:
public class SemaphoreTest {
private static final int THREAD_COUNT = 30;
private static ExecutorService threadPool = Executors.newSummarize Java concurrency knowledge points(THREAD_COUNT);
private static Semaphore s = new Semaphore(10);
public static void main(String[] args) {
for (int i = 0; i <p>在代码中,虽然有30个线程在执行,但是只允许10个并发执行。Semaphore的构造方法<code>Semaphore(int permits</code>)接受一个整型的数字,表示可用的许可证数量。<code>Semaphore(10)</code>表示允许10个线程获取许可证,也就是最大并发数是10。Semaphore的用法也很简单,首先线程使用 Semaphore的acquire()方法获取一个许可证,使用完之后调用release()方法归还许可证。还可以用tryAcquire()方法尝试获取许可证。</p><h2>43.Exchanger 了解吗?</h2><p>Exchanger(交换者)是一个用于线程间协作的工具类。Exchanger用于进行线程间的数据交换。它提供一个同步点,在这个同步点,两个线程可以交换彼此的数据。</p><p><img src="https://img.php.cn/upload/article/000/000/067/a99f1f171b5f8c414e2981e6a7d5189a-57.png" alt="Summarize Java concurrency knowledge points"></p><p>这两个线程通过 exchange方法交换数据,如果第一个线程先执行exchange()方法,它会一直等待第二个线程也执行exchange方法,当两个线程都到达同步点时,这两个线程就可以交换数据,将本线程生产出来的数据传递给对方。</p><p>Exchanger可以用于遗传算法,遗传算法里需要选出两个人作为交配对象,这时候会交换两人的数据,并使用交叉规则得出2个交配结果。Exchanger也可以用于校对工作,比如我们需要将纸制银行流水通过人工的方式录入成电子银行流水,为了避免错误,采用AB岗两人进行录入,录入到Excel之后,系统需要加载这两个Excel,并对两个Excel数据进行校对,看看是否录入一致。</p><pre class="brush:php;toolbar:false">public class ExchangerTest {
private static final Exchanger<string> exgr = new Exchanger<string>();
private static ExecutorService threadPool = Executors.newSummarize Java concurrency knowledge points(2);
public static void main(String[] args) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
String A = "银行流水A"; // A录入银行流水数据
exgr.exchange(A);
} catch (InterruptedException e) {
}
}
});
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
String B = "银行流水B"; // B录入银行流水数据
String A = exgr.exchange("B");
System.out.println("A和B数据是否一致:" + A.equals(B) + ",A录入的是:"
+ A + ",B录入是:" + B);
} catch (InterruptedException e) {
}
}
});
threadPool.shutdown();
}}</string></string>假如两个线程有一个没有执行exchange()方法,则会一直等待,如果担心有特殊情况发生,避免一直等待,可以使用exchange(V x, long timeOut, TimeUnit unit)设置最大等待时长
44.什么是线程池?
线程池: 简单理解,它就是一个Summarize Java concurrency knowledge points。
- 它帮我们管理线程,避免增加创建线程和销毁线程的资源损耗。因为线程其实也是一个对象,创建一个对象,需要经过类加载过程,销毁一个对象,需要走GC垃圾回收流程,都是需要资源开销的。
- 提高响应速度。 如果任务到达了,相对于从线程池拿线程,重新去创建一条线程执行,速度肯定慢很多。
- 重复利用。 线程用完,再放回池子,可以达到重复利用的效果,节省资源。
45.能说说工作中线程池的应用吗?
之前我们有一个和第三方对接的需求,需要向第三方推送数据,引入了多线程来提升数据推送的效率,其中用到了线程池来管理线程。
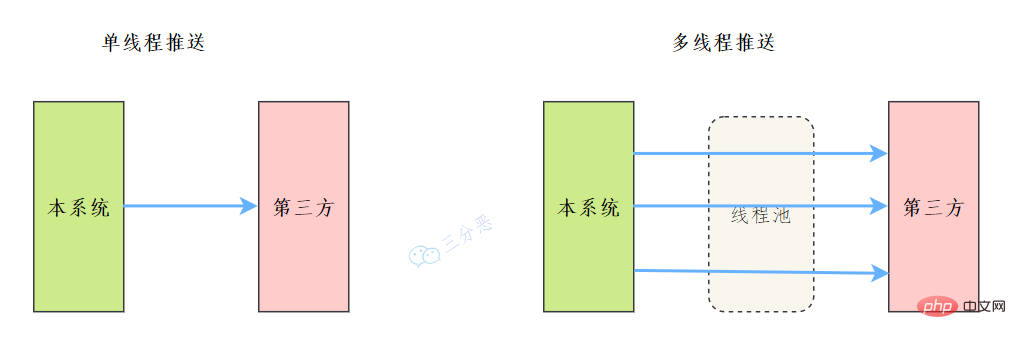
Summarize Java concurrency knowledge points如下:
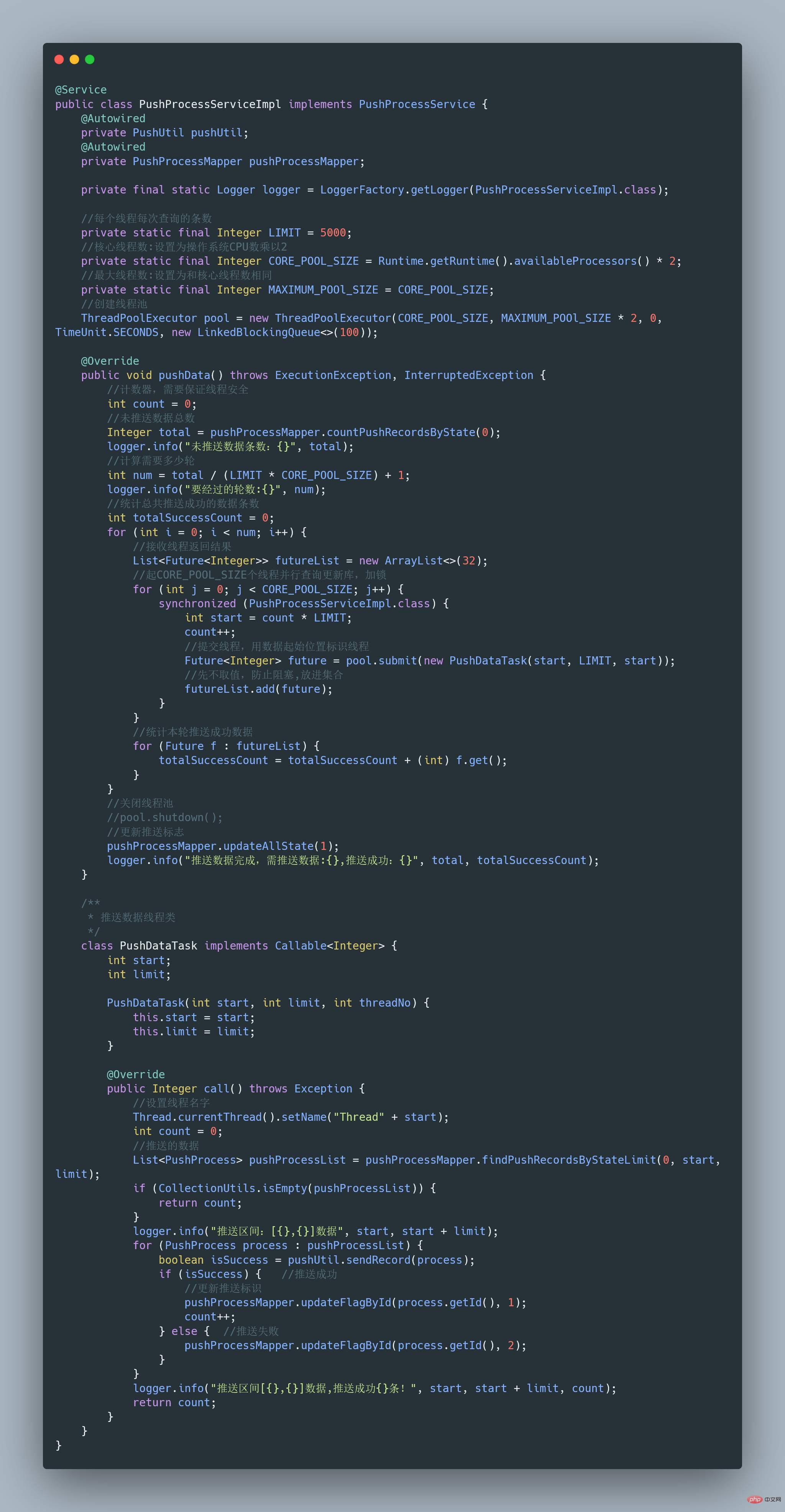
完整可运行代码地址:https://gitee.com/fighter3/thread-demo.git
线程池的参数如下:
corePoolSize:线程核心参数选择了CPU数×2
maximumPoolSize:最大线程数选择了和核心线程数相同
keepAliveTime:非核心闲置线程存活时间直接置为0
unit:非核心线程保持存活的时间选择了 TimeUnit.SECONDS 秒
workQueue:线程池等待队列,使用 LinkedBlockingQueue阻塞队列
同时还用了synchronized 来加锁,保证数据不会被重复推送:
synchronized (PushProcessServiceImpl.class) {}
ps:这个例子只是简单地进行了数据推送,实际上还可以结合其他的业务,像什么数据清洗啊、数据统计啊,都可以套用。
46.能简单说一下线程池的工作流程吗?
用一个通俗的比喻:
有一个营业厅,总共有六个窗口,现在开放了三个窗口,现在有三个窗口坐着三个营业员小姐姐在营业。
老三去办业务,可能会遇到什么情况呢?
- 老三发现有空间的在营业的窗口,直接去找小姐姐办理业务。

- 老三发现没有空闲的窗口,就在排队区排队等。
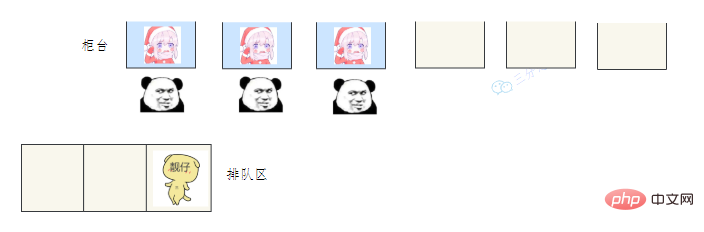
- 老三发现没有空闲的窗口,等待区也满了,蚌埠住了,经理一看,就让休息的小姐姐赶紧回来上班,等待区号靠前的赶紧去新窗口办,老三去排队区排队。小姐姐比较辛苦,假如一段时间发现他们可以不用接着营业,经理就让她们接着休息。
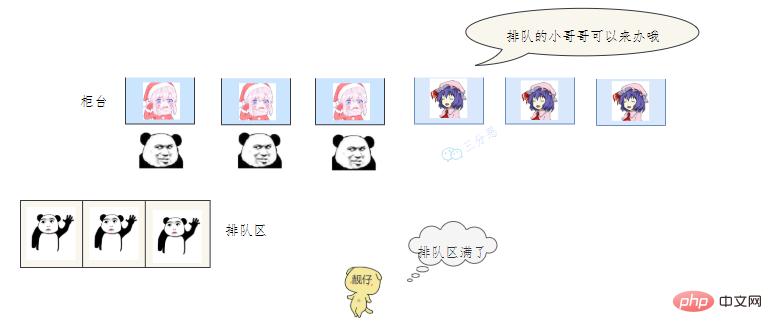
- 老三一看,六个窗口都满了,等待区也没位置了。老三急了,要闹,经理赶紧出来了,经理该怎么办呢?
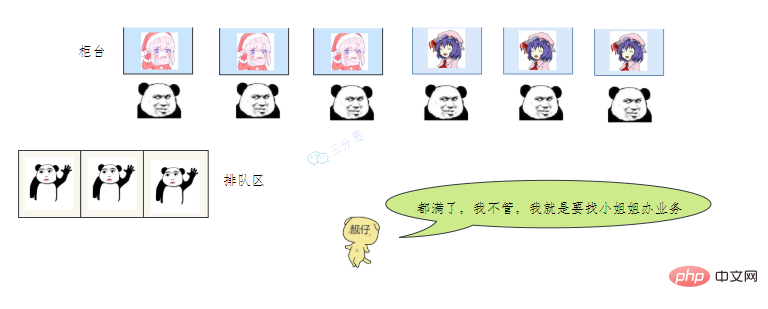
我们银行系统已经瘫痪
谁叫你来办的你找谁去
看你比较急,去队里加个塞
今天没办法,不行你看改一天
上面的这个流程几乎就跟 JDK 线程池的大致流程类似,
- 营业中的 3个窗口对应核心线程池数:corePoolSize
- 总的营业窗口数6对应:maximumPoolSize
- 打开的临时窗口在多少时间内无人办理则关闭对应:unit
- 排队区就是等待队列:workQueue
- 无法办理的时候银行给出的解决方法对应:RejectedExecutionHandler
- threadFactory 该参数在 JDK 中是 线程工厂,用来创建线程对象,一般不会动。
所以我们线程池的工作流程也比较好理解了:
- 线程池刚创建时,里面没有一个线程。任务队列是作为参数传进来的。不过,就算队列里面有任务,线程池也不会马上执行它们。
- 当调用 execute() 方法添加一个任务时,线程池会做如下判断:
- 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
- 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列;
- 如果这时候队列满了,而且正在运行的线程数量小于 maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
- 如果队列满了,而且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会根据拒绝策略来对应处理。
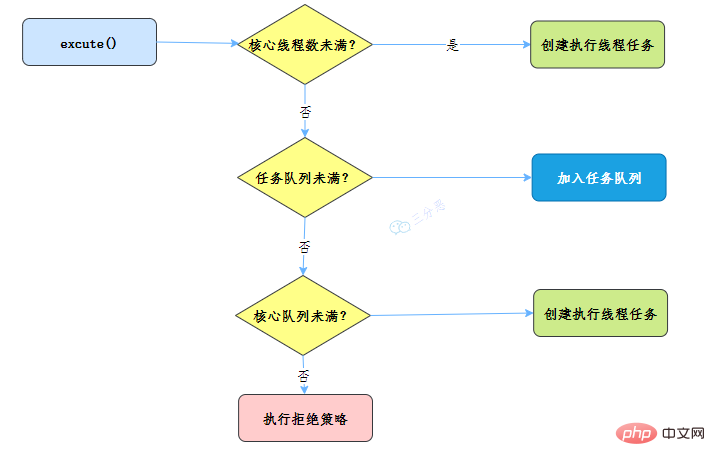
当一个线程完成任务时,它会从队列中取下一个任务来执行。
当一个线程无事可做,超过一定的时间(keepAliveTime)时,线程池会判断,如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
47.线程池主要参数有哪些?
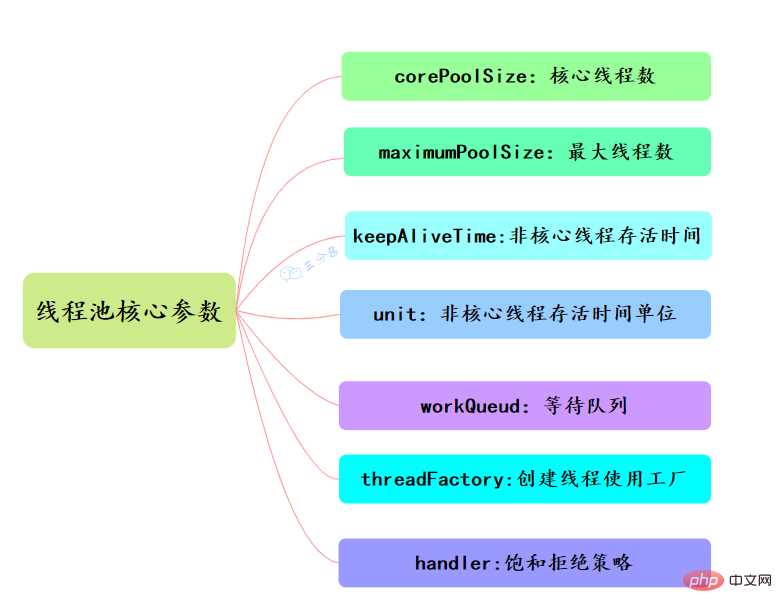
线程池有七大参数,需要重点关注corePoolSize、maximumPoolSize、workQueue、handler这四个。
- corePoolSize
此值是用来初始化线程池中核心线程数,当线程池中线程池数corePoolSize时,系统默认是添加一个任务才创建一个线程池。当线程数 = corePoolSize时,新任务会追加到workQueue中。
- maximumPoolSize
maximumPoolSize表示允许的最大线程数 = (非核心线程数+核心线程数),当BlockingQueue也满了,但线程池中总线程数 maximumPoolSize时候就会再次创建新的线程。
- keepAliveTime
非核心线程 =(maximumPoolSize - corePoolSize ) ,非核心线程闲置下来不干活最多存活时间。
- unit
线程池中非核心线程保持存活的时间的单位
- TimeUnit.DAYS; 天
- TimeUnit.HOURS; 小时
- TimeUnit.MINUTES; 分钟
- TimeUnit.SECONDS; 秒
- TimeUnit.MILLISECONDS; 毫秒
- TimeUnit.MICROSECONDS; 微秒
- TimeUnit.NANOSECONDS; 纳秒
- workQueue
线程池等待队列,维护着等待执行的Runnable对象。当运行当线程数= corePoolSize时,新的任务会被添加到workQueue中,如果workQueue也满了则尝试用非核心线程执行任务,等待队列应该尽量用有界的。
- threadFactory
创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等。
- handler
corePoolSize、workQueue、maximumPoolSize都不可用的时候执行的饱和策略。
48.线程池的拒绝策略有哪些?
类比前面的例子,无法办理业务时的处理方式,帮助记忆:
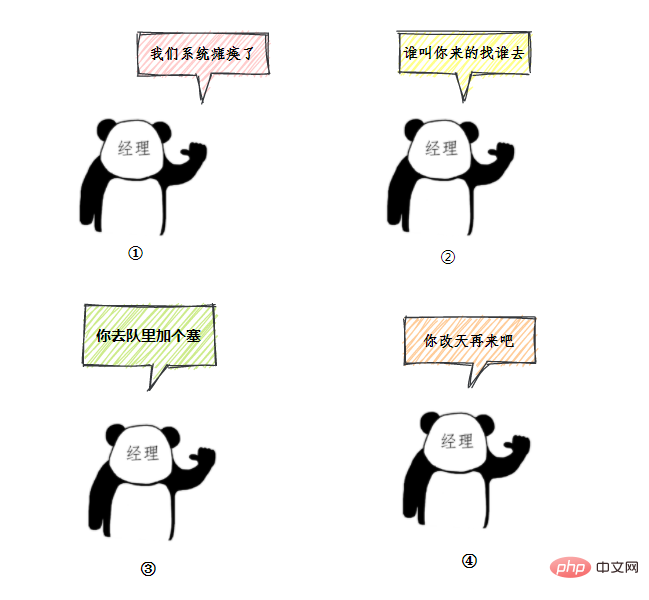
- AbortPolicy :直接抛出异常,默认使用此策略
- CallerRunsPolicy:用调用者所在的线程来执行任务
- DiscardOldestPolicy:丢弃阻塞队列里最老的任务,也就是队列里靠前的任务
- DiscardPolicy :当前任务直接丢弃
想实现自己的拒绝策略,实现RejectedExecutionHandler接口即可。
49.线程池有哪几种工作队列?
常用的阻塞队列主要有以下几种:
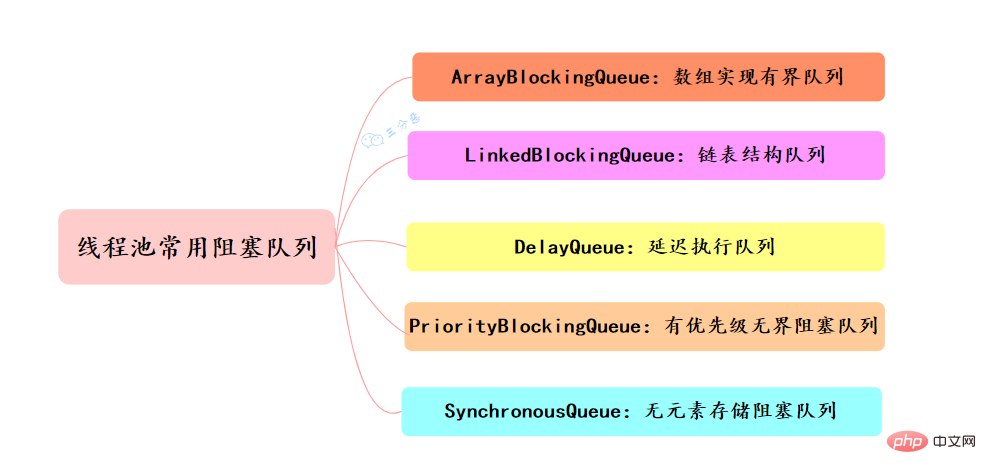
- ArrayBlockingQueue:ArrayBlockingQueue(有界队列)是一个用数组实现的有界阻塞队列,按FIFO排序量。
- LinkedBlockingQueue:LinkedBlockingQueue(可设置容量队列)是基于链表结构的阻塞队列,按FIFO排序任务,容量可以选择进行设置,不设置的话,将是一个无边界的阻塞队列,最大长度为Integer.MAX_VALUE,吞吐量通常要高于ArrayBlockingQuene;newSummarize Java concurrency knowledge points线程池使用了这个队列
- DelayQueue:DelayQueue(延迟队列)是一个任务定时周期的延迟执行的队列。根据指定的执行时间从小到大排序,否则根据插入到队列的先后排序。newScheduledThreadPool线程池使用了这个队列。
- PriorityBlockingQueue:PriorityBlockingQueue(优先级队列)是具有优先级的无界阻塞队列
- SynchronousQueue:SynchronousQueue(同步队列)是一个不存储元素的阻塞队列,每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQuene,newCachedThreadPool线程池使用了这个队列。
50.线程池提交execute和submit有什么区别?
- execute 用于提交不需要返回值的任务
threadsPool.execute(new Runnable() {
@Override public void run() {
// TODO Auto-generated method stub }
});
- submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个 future对象可以判断任务是否执行成功,并且可以通过future的get()方法来获取返回值
Future<object> future = executor.submit(harReturnValuetask); try { Object s = future.get(); } catch (InterruptedException e) {
// 处理中断异常 } catch (ExecutionException e) {
// 处理无法执行任务异常 } finally {
// 关闭线程池 executor.shutdown();}</object>
51.线程池怎么关闭知道吗?
可以通过调用线程池的shutdown或shutdownNow方法来关闭线程池。它们的原理是遍历线程池中的工作线程,然后逐个调用线程的interrupt方法来中断线程,所以无法响应中断的任务可能永远无法终止。
shutdown() 将线程池状态置为shutdown,并不会立即停止:
- 停止接收外部submit的任务
- 内部正在跑的任务和队列里等待的任务,会执行完
- 等到第二步完成后,才真正停止
shutdownNow() 将线程池状态置为stop。一般会立即停止,事实上不一定:
- 和shutdown()一样,先停止接收外部提交的任务
- 忽略队列里等待的任务
- 尝试将正在跑的任务interrupt中断
- 返回未执行的任务列表
shutdown 和shutdownnow简单来说区别如下:
- shutdownNow()能立即停止线程池,正在跑的和正在等待的任务都停下了。这样做立即生效,但是风险也比较大。
- shutdown()只是关闭了提交通道,用submit()是无效的;而内部的任务该怎么跑还是怎么跑,跑完再彻底停止线程池。
52.线程池的线程数应该怎么配置?
线程在Java中属于稀缺资源,线程池不是越大越好也不是越小越好。任务分为计算密集型、IO密集型、混合型。
- 计算密集型:大部分都在用CPU跟内存,加密,逻辑操作业务处理等。
- IO密集型:数据库链接,网络通讯传输等。

一般的经验,不同类型线程池的参数配置:
- 计算密集型一般推荐线程池不要过大,一般是CPU数 + 1,+1是因为可能存在页缺失(就是可能存在有些数据在硬盘中需要多来一个线程将数据读入内存)。如果线程池数太大,可能会频繁的 进行线程上下文切换跟任务调度。获得当前CPU核心数代码如下:
Runtime.getRuntime().availableProcessors();
- IO密集型:线程数适当大一点,机器的Cpu核心数*2。
- 混合型:可以考虑根绝情况将它拆分成CPU密集型和IO密集型任务,如果执行时间相差不大,拆分可以提升吞吐量,反之没有必要。
当然,实际应用中没有固定的公式,需要结合测试和监控来进行调整。
53.有哪几种常见的线程池?
面试常问,主要有四种,都是通过工具类Excutors创建出来的,需要注意,阿里巴巴《Java开发手册》里禁止使用这种方式来创建线程池。
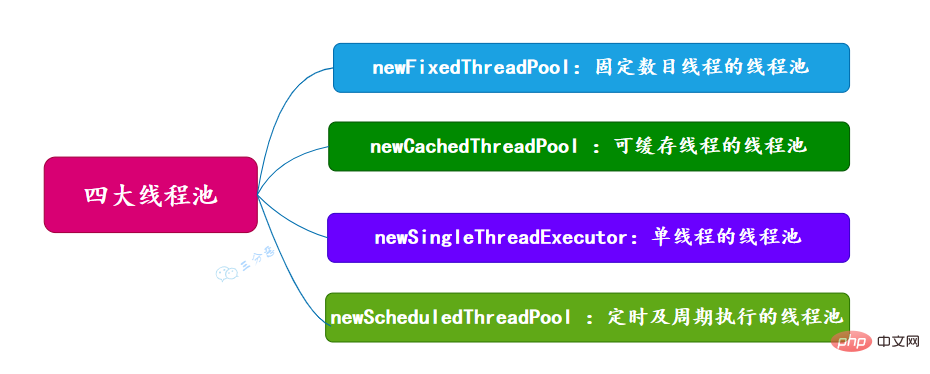
newSummarize Java concurrency knowledge points (固定数目线程的线程池)
newCachedThreadPool (可缓存线程的线程池)
newSingleThreadExecutor (单线程的线程池)
newScheduledThreadPool (定时及周期执行的线程池)
54.能说一下四种常见线程池的原理吗?
前三种线程池的构造直接调用ThreadPoolExecutor的构造方法。
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<runnable>(),
threadFactory));
}</runnable>
线程池特点
- 核心线程数为1
- 最大线程数也为1
- 阻塞队列是无界队列LinkedBlockingQueue,可能会导致OOM
- keepAliveTime为0
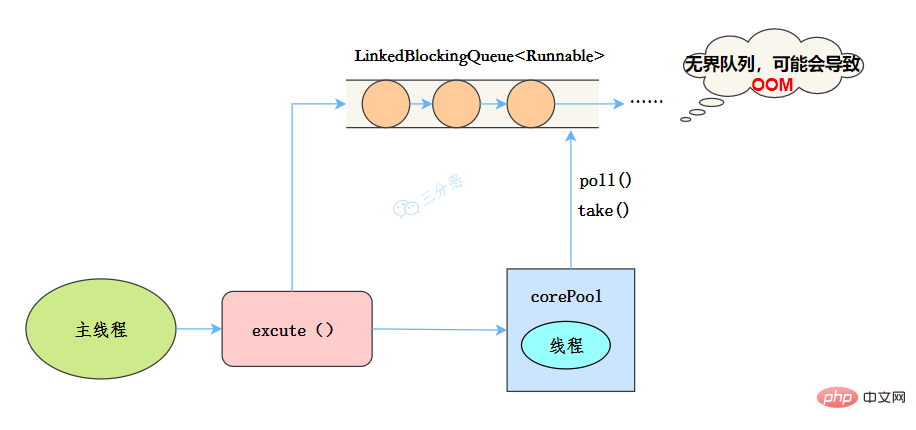
工作流程:
- 提交任务
- 线程池是否有一条线程在,如果没有,新建线程执行任务
- 如果有,将任务加到阻塞队列
- 当前的唯一线程,从队列取任务,执行完一个,再继续取,一个线程执行任务。
适用场景
适用于串行执行任务的场景,一个任务一个任务地执行。
newSummarize Java concurrency knowledge points
public static ExecutorService newSummarize Java concurrency knowledge points(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<runnable>(),
threadFactory);
}</runnable>
线程池特点:
- 核心线程数和最大线程数大小一样
- 没有所谓的非空闲时间,即keepAliveTime为0
- 阻塞队列为无界队列LinkedBlockingQueue,可能会导致OOM
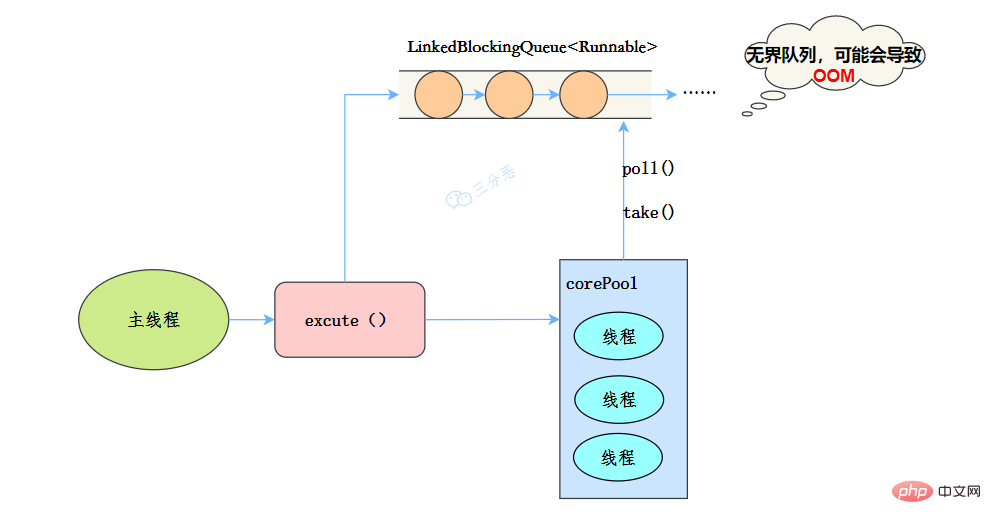
工作流程:
- 提交任务
- 如果线程数少于核心线程,创建核心线程执行任务
- 如果线程数等于核心线程,把任务添加到LinkedBlockingQueue阻塞队列
- 如果线程执行完任务,去阻塞队列取任务,继续执行。
使用场景
Summarize Java concurrency knowledge points 适用于处理CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务。
newCachedThreadPool
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<runnable>(),
threadFactory);
}</runnable>
线程池特点:
- 核心线程数为0
- 最大线程数为Integer.MAX_VALUE,即无限大,可能会因为无限创建线程,导致OOM
- 阻塞队列是SynchronousQueue
- 非核心线程空闲存活时间为60秒
当提交任务的速度大于处理任务的速度时,每次提交一个任务,就必然会创建一个线程。极端情况下会创建过多的线程,耗尽 CPU 和内存资源。由于空闲 60 秒的线程会被终止,长时间保持空闲的 CachedThreadPool 不会占用任何资源。
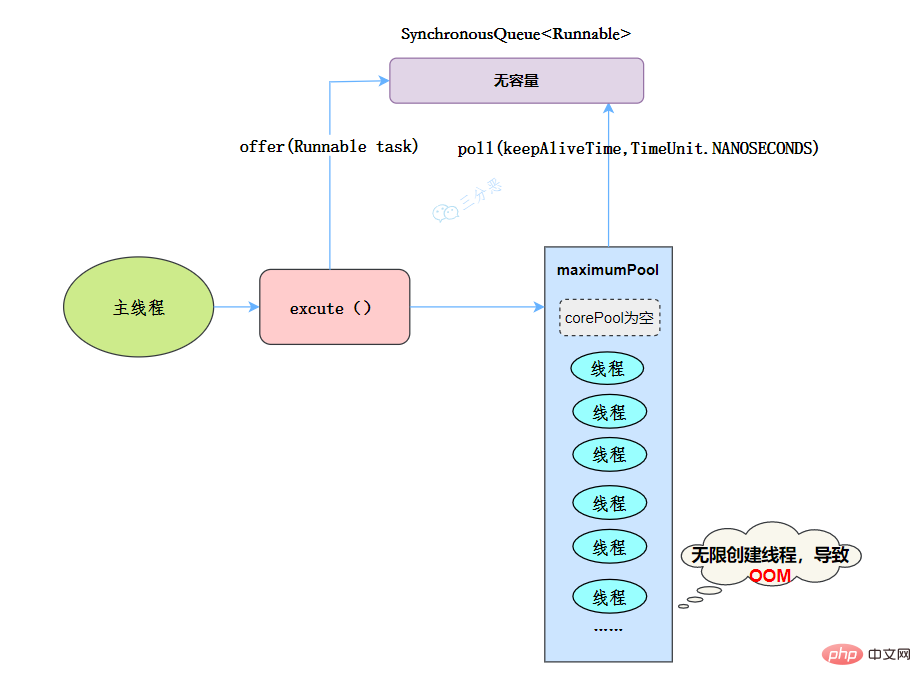
工作流程:
- 提交任务
- 因为没有核心线程,所以任务直接加到SynchronousQueue队列。
- 判断是否有空闲线程,如果有,就去取出任务执行。
- 如果没有空闲线程,就新建一个线程执行。
- 执行完任务的线程,还可以存活60秒,如果在这期间,接到任务,可以继续活下去;否则,被销毁。
适用场景
用于并发执行大量短期的小任务。
newScheduledThreadPool
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
线程池特点
- 最大线程数为Integer.MAX_VALUE,也有OOM的风险
- 阻塞队列是DelayedWorkQueue
- keepAliveTime为0
- scheduleAtFixedRate() :按某种速率周期执行
- scheduleWithFixedDelay():在某个延迟后执行
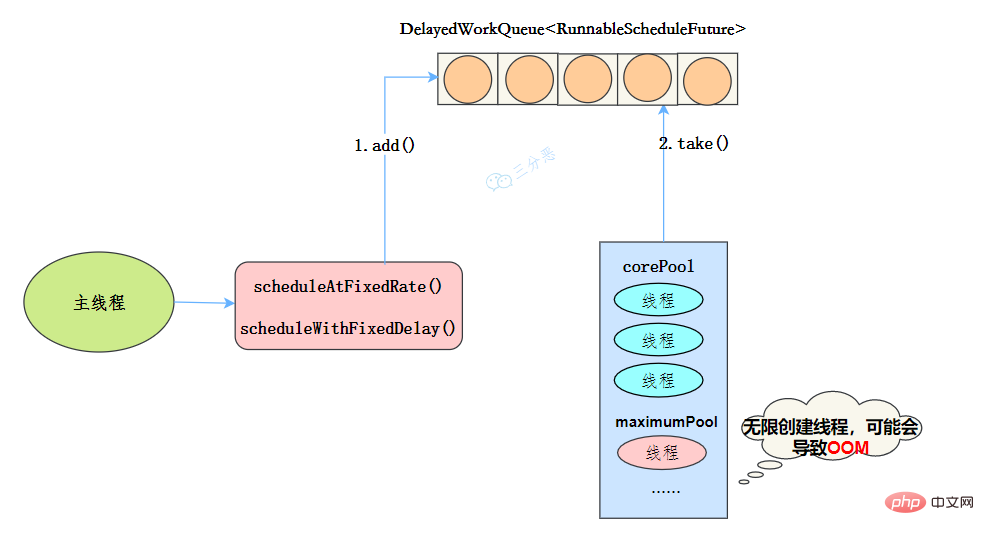
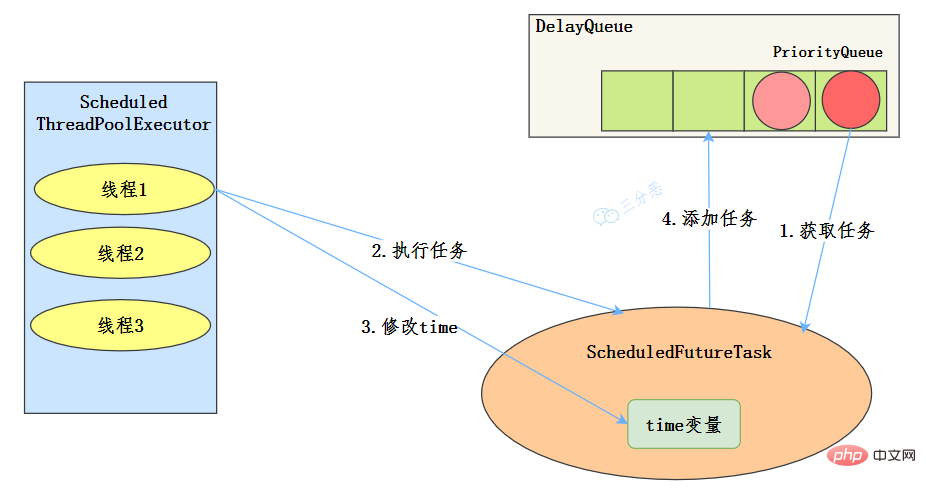
工作机制
- 线程从DelayQueue中获取已到期的ScheduledFutureTask(DelayQueue.take())。到期任务是指ScheduledFutureTask的time大于等于当前时间。
- 线程执行这个ScheduledFutureTask。
- 线程修改ScheduledFutureTask的time变量为下次将要被执行的时间。
- 线程把这个修改time之后的ScheduledFutureTask放回DelayQueue中(DelayQueue.add())。
使用场景
周期性执行任务的场景,需要限制线程数量的场景
使用无界队列的线程池会导致什么问题吗?
例如newSummarize Java concurrency knowledge points使用了无界的阻塞队列LinkedBlockingQueue,如果线程获取一个任务后,任务的执行时间比较长,会导致队列的任务越积越多,导致机器内存使用不停飙升,最终导致OOM。
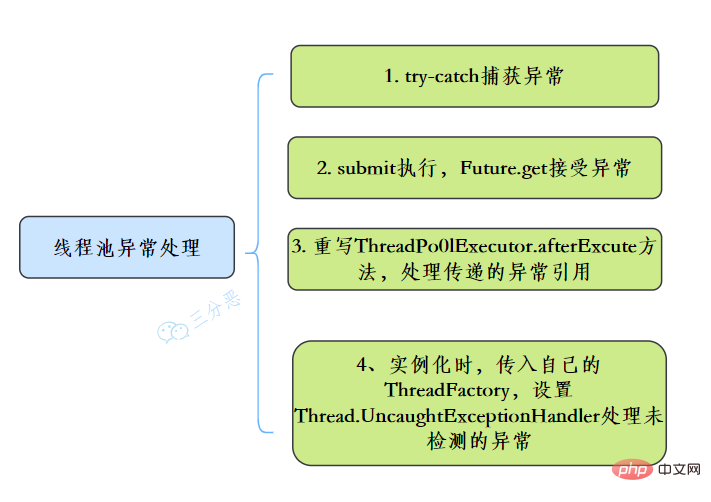
55.线程池异常怎么处理知道吗?
在使用线程池处理任务的时候,任务代码可能抛出RuntimeException,抛出异常后,线程池可能捕获它,也可能创建一个新的线程来代替异常的线程,我们可能无法感知任务出现了异常,因此我们需要考虑线程池异常情况。
常见的异常处理方式:
56.能说一下线程池有几种状态吗?
线程池有这几个状态:RUNNING,SHUTDOWN,STOP,TIDYING,TERMINATED。
//线程池状态 private static final int RUNNING = -1 <p>线程池各个状态切换图:</p><p><img src="https://img.php.cn/upload/article/000/000/067/47690a2c7799a7bd0d10ed5490da3a7b-77.png" alt="Summarize Java concurrency knowledge points"></p><p><strong>RUNNING</strong></p>
- 该状态的线程池会接收新任务,并处理阻塞队列中的任务;
- 调用线程池的shutdown()方法,可以切换到SHUTDOWN状态;
- 调用线程池的shutdownNow()方法,可以切换到STOP状态;
SHUTDOWN
- 该状态的线程池不会接收新任务,但会处理阻塞队列中的任务;
- 队列为空,并且线程池中执行的任务也为空,进入TIDYING状态;
STOP
- 该状态的线程不会接收新任务,也不会处理阻塞队列中的任务,而且会中断正在运行的任务;
- 线程池中执行的任务为空,进入TIDYING状态;
TIDYING
- 该状态表明所有的任务已经运行终止,记录的任务数量为0。
- terminated()执行完毕,进入TERMINATED状态
TERMINATED
- 该状态表示线程池彻底终止
57.线程池如何实现参数的动态修改?
线程池提供了几个 setter方法来设置线程池的参数。
![JDK Summarize Java concurrency knowledge points设置接口来源参考[7]](https://img.php.cn/upload/article/000/000/067/6094178ce7a357b1c3eb573fc35e4d09-78.png)
这里主要有两个思路:
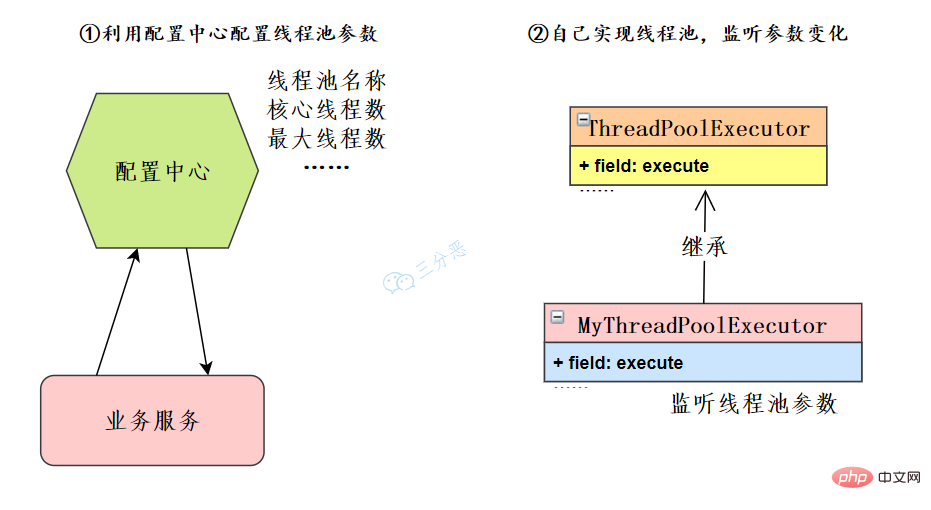
#Under our microservice architecture, you can use configuration centers such as Nacos, Apollo, etc., or you can develop your own configuration center. The business service reads the thread pool configuration and obtains the corresponding thread pool instance to modify the thread pool parameters.
If the use of the configuration center is restricted, you can also extend ThreadPoolExecutor yourself, rewrite methods, monitor changes in thread pool parameters, and dynamically modify thread pool parameters.
Do you know about thread pool tuning?
There is no fixed formula for thread pool configuration. Usually, the thread pool will be evaluated to a certain extent beforehand. The common evaluation scheme is as follows:
![线程池评估方案 来源参考[7]](https://img.php.cn/upload/article/000/000/067/b8171ba02ccd61fc1cad003f65eae9c1-80.png)
Also before going online Fully test and establish a complete thread pool monitoring mechanism after going online.
Combine the monitoring and alarm mechanism during the process to analyze the thread pool problems, or optimize the points and adjust the configuration in conjunction with the thread pool dynamic parameter configuration mechanism.
Please observe carefully afterwards and make adjustments at any time.
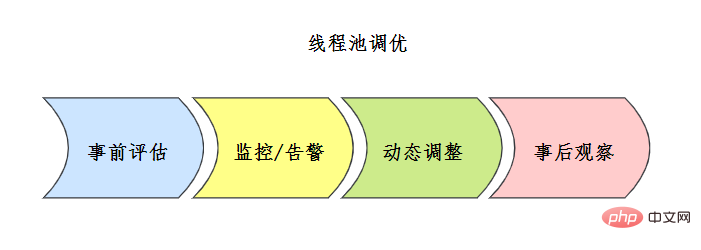
#For specific tuning cases, please refer to [7] Meituan Technology Blog.
58. Can you design and implement a thread pool?
This question appears frequently in Alibaba interviews
You can view the thread pool implementation principle. If someone talked about thread pools like this before, I should have understood it long ago! , Of course, we implement it ourselves, we only need to grasp the core process of the thread pool - reference [6]:
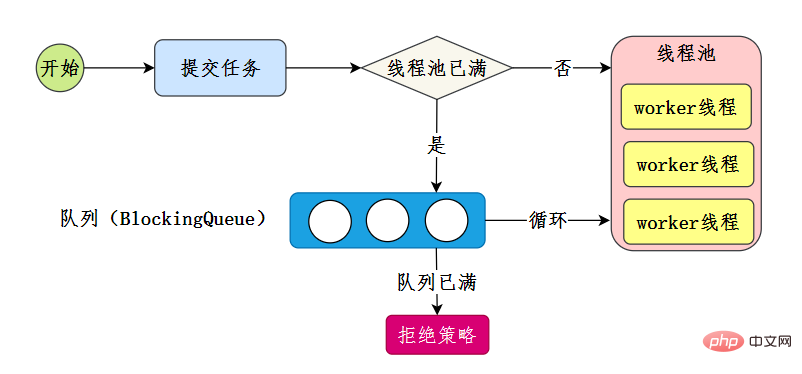
Our own implementation is to complete this core process:
- There are N worker threads in the thread pool
- Submit the task to the thread pool for running
- If the thread pool is full, put the task into the queue
- Finally, when there is free time, get the tasks in the queue to execute
Implementation code [6]:
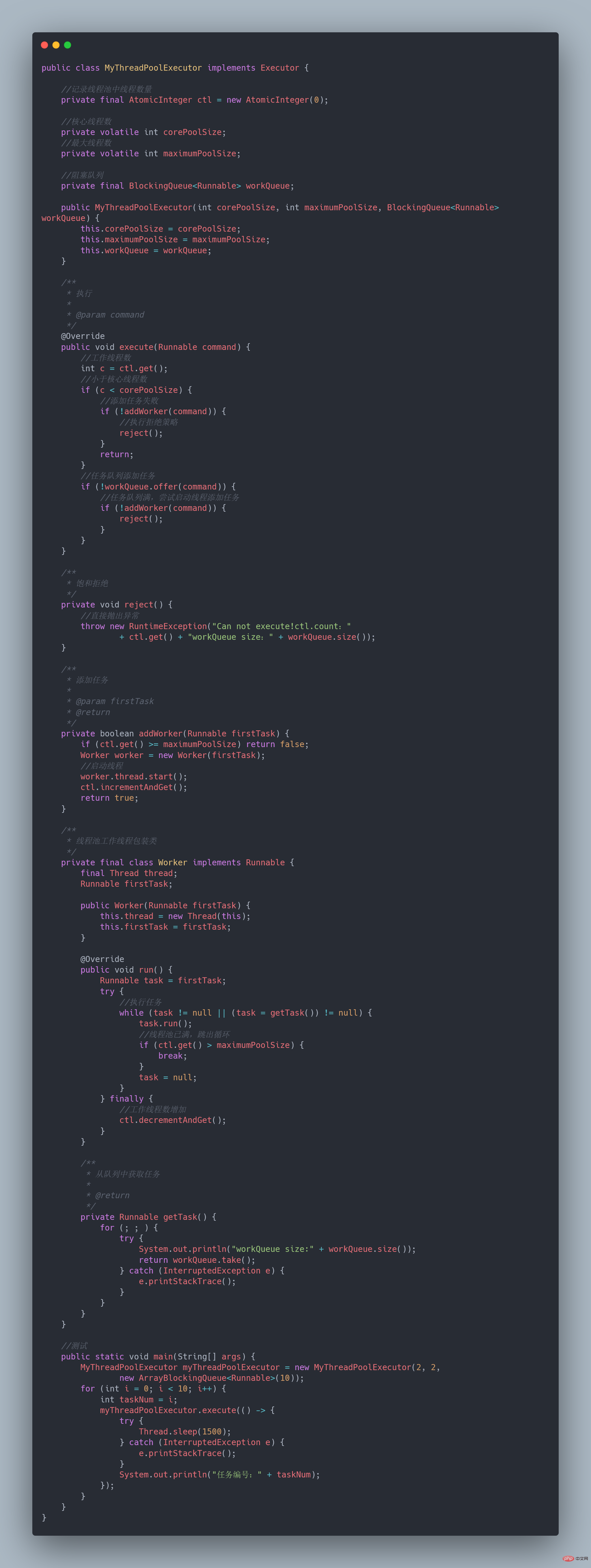
In this way, one realizes the main thread pool The process class is completed.
59. What should I do if the single-machine thread pool execution is powered off?
We can do transaction management for tasks that are being processed and blocked in the queue or persist tasks in the blocked queue, and when there is a power outage or system crash and the operation cannot continue, we can use the traceback log Method to undo the processing operation that has been executed successfully. Then re-execute the entire blocking queue.
In other words, the blocking queue is persisted; task transaction control is being processed; the rollback of the task is being processed after a power outage, and the operation is restored through the log; the data in the blocking queue is reloaded after the server is restarted.
Concurrent Containers and Frameworks
For some concurrent containers, you can check out the Counterattack: Java Collection of Thirty Questions, which contains CopyOnWriteList and ConcurrentHashMapQuestions and answers about these two thread-safe container classes. .
60.Do you understand the Fork/Join framework?
The Fork/Join framework is a framework provided by Java7 for executing tasks in parallel. It is a framework that divides large tasks into several small tasks, and finally summarizes the results of each small task to obtain the results of the large task.
To master the Fork/Join framework, you first need to understand two points, Divide and Conquer and Work Stealing Algorithm.
Divide and Conquer
The definition of the Fork/Join framework actually embodies the idea of divide and conquer: decompose a problem of size N into K smaller ones. These sub-problems are independent of each other and have the same nature as the original problem. By finding the solution to the subproblem, you can get the solution to the original problem.
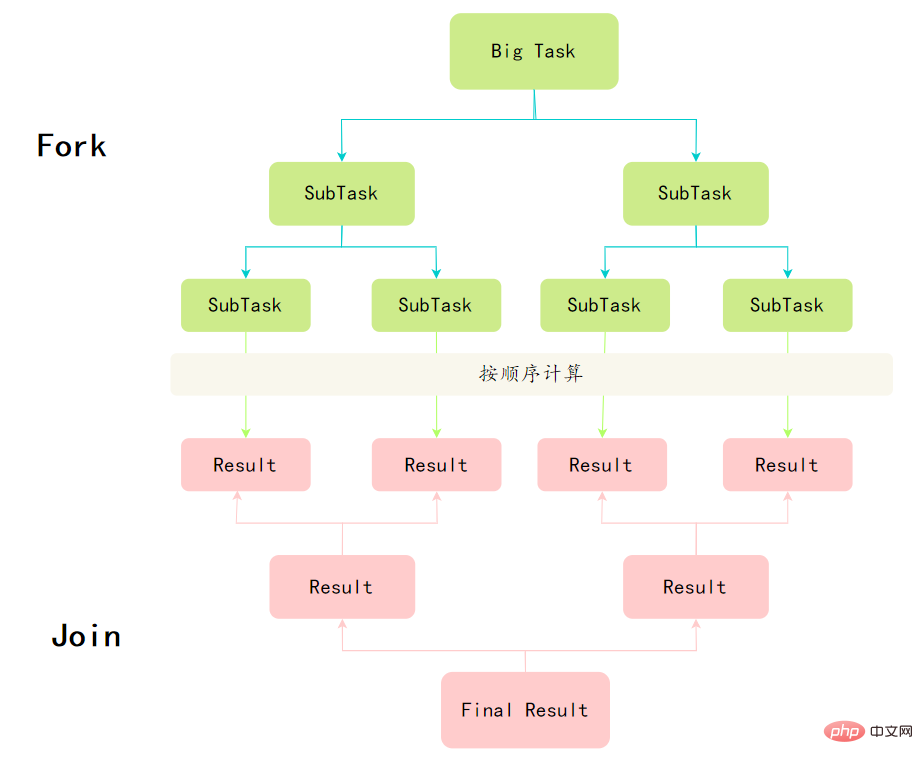
Work stealing algorithm
Split a large task into several small tasks and put these small tasks into different queues , each creates a separate thread to execute the tasks in the queue.
Then the problem comes, some threads work hard, and some threads work slowly. The thread that has finished its work cannot be left idle; it must be allowed to work for the thread that has not finished its work. It steals a task from the queue of other threads for execution. This is the so-called work stealing.
When work stealing occurs, they will access the same queue. In order to reduce the competition between the stealing task thread and the stolen task thread, the task usually uses a double-ended queue, and the stolen task thread always starts from both ends. The task is taken from the head of the queue, and the thread that steals the task always takes the task from the tail of the double-ended queue for execution.
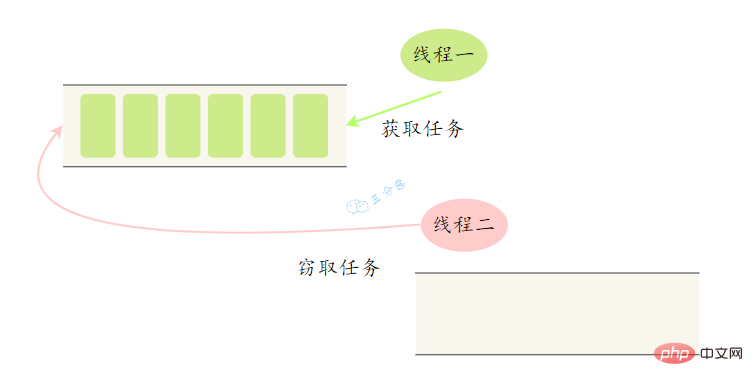
Look at an example of Fork/Join framework application, calculate the sum between 1~n: 1 2 3 … n
- 设置一个分割阈值,任务大于阈值就拆分任务
- 任务有结果,所以需要继承RecursiveTask
public class CountTask extends RecursiveTask<integer> {
private static final int THRESHOLD = 16; // 阈值
private int start;
private int end;
public CountTask(int start, int end) {
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
// 如果任务足够小就计算任务
boolean canCompute = (end - start) result = forkJoinPool.submit(task);
try {
System.out.println(result.get());
} catch (InterruptedException e) {
} catch (ExecutionException e) {
}
}
}</integer>
ForkJoinTask与一般Task的主要区别在于它需要实现compute方法,在这个方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果比较大,就必须分割成两个子任务,每个子任务在调用fork方法时,又会进compute方法,看看当前子任务是否需要继续分割成子任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会等待子任务执行完并得到其结果。
推荐学习:《java教程》
The above is the detailed content of Summarize Java concurrency knowledge points. For more information, please follow other related articles on the PHP Chinese website!