
Home >Backend Development >Python Tutorial >Take you to interpret Python multi-threading
Take you to interpret Python multi-threading

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2022-03-02 17:35:482625browse
This article brings you relevant knowledge about python, which mainly introduces the relevant knowledge about multi-threading. Multi-threading is similar to executing multiple different programs at the same time and has many advantages. , let’s take a look below, I hope it will be helpful to everyone.

Recommended study: python tutorial
Threading explanation
Multithreading is similar to executing multiple different programs at the same time , multi-threaded operation has the following advantages:
- Using threads can put long-term program tasks into the background for processing.
- The user interface can be more attractive, so that if the user clicks a button to trigger the processing of certain events, a progress bar can pop up to show the progress of the processing.
- The program may run faster.
- Threads are more useful in the implementation of some waiting tasks such as user input, file reading and writing, and network sending and receiving data. In this case we can release some precious resources such as memory usage and so on.
Threads are still different from processes during execution. Each independent thread has an entry point for program execution, a sequential execution sequence, and an exit point for the program. However, threads cannot execute independently and must exist in the application program, and the application program provides multiple thread execution control.
Each thread has its own set of CPU registers, called the thread's context, which reflects the state of the CPU registers the thread last ran.
- Instruction pointer and Stack pointer register are the two most important registers in the thread context. The thread always runs in the context of the process. These addresses are used to mark ownership Memory in the thread's process address space. Threads can be preempted (interrupted).
Threads can be put on hold (also called sleeping) while other threads are running - this is called thread backing off.
Threads can be divided into:
- Kernel threads: created and revoked by the operating system kernel.
- User thread: A thread implemented in the user program without kernel support.
- _thread
- threading (recommended)
Functional: Call the start_new_thread() function in the _thread module to generate a new thread. The syntax is as follows:
_thread.start_new_thread ( function, args[, kwargs] )- Parameter description:
- function - thread function.
- args - the parameters passed to the thread function, it must be a tuple type.
- kwargs - Optional parameters.
#!/usr/bin/python3 import _thread import time # 为线程定义一个函数 def print_time( threadName, delay): count = 0 while count The output of executing the above program is as follows: <p><br><img src="/static/imghwm/default1.png" data-src="https://img.php.cn/upload/article/000/000/067/9e54370fdafb34f8739135c680e1aa53-0.png" class="lazy" alt="Take you to interpret Python multi-threading"></p>Threading module<h2></h2> Python3 passes two standards The libraries _thread and threading provide support for threads. <p></p>
- _thread provides low-level, primitive threads and a simple lock. Its functions are relatively limited compared to the threading module.
- In addition to all the methods in the _thread module, the threading module also provides other methods:
- threading.currentThread(): Returns the current thread variable.
- threading.enumerate():
- Returns a list containing running threads. Running refers to after the thread starts and before it ends, excluding threads before starting and after termination.
threading.activeCount(): - Returns the number of running threads, which has the same result as len(threading.enumerate()).
- run(): to represent thread activity Methods.
- start(): Start thread activity.
- join([time]): Wait until the thread terminates. This blocks the calling thread until the thread's join()
- method is aborted - exiting normally or throwing an unhandled exception - or an optional timeout occurs.
isAlive(): Returns whether the thread is active. - getName(): Returns the thread name.
- setName(): Set the thread name.
#!/usr/bin/python3
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开始线程:" + self.name)
print_time(self.name, self.counter, 5)
print ("退出线程:" + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("退出主线程") The execution results of the above program are as follows: 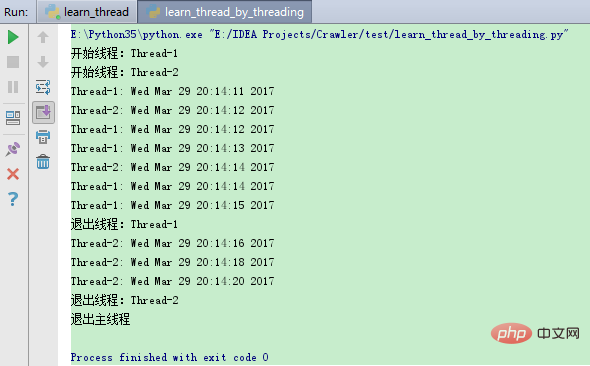
线程同步
如果多个线程共同对某个数据修改,则可能出现不可预料的结果,为了保证数据的正确性,需要对多个线程进行同步。
使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。如下:
多线程的优势在于可以同时运行多个任务(至少感觉起来是这样)。但是当线程需要共享数据时,可能存在数据不同步的问题。
考虑这样一种情况:一个列表里所有元素都是0,线程"set"从后向前把所有元素改成1,而线程"print"负责从前往后读取列表并打印。
那么,可能线程"set"开始改的时候,线程"print"便来打印列表了,输出就成了一半0一半1,这就是数据的不同步。为了避免这种情况,引入了锁的概念。
锁有两种状态——锁定和未锁定。每当一个线程比如"set"要访问共享数据时,必须先获得锁定;如果已经有别的线程比如"print"获得锁定了,那么就让线程"set"暂停,也就是同步阻塞;等到线程"print"访问完毕,释放锁以后,再让线程"set"继续。
经过这样的处理,打印列表时要么全部输出0,要么全部输出1,不会再出现一半0一半1的尴尬场面。
实例:
#!/usr/bin/python3
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, counter):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
def run(self):
print ("开启线程: " + self.name)
# 获取锁,用于线程同步
threadLock.acquire()
print_time(self.name, self.counter, 3)
# 释放锁,开启下一个线程
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
threadLock = threading.Lock()
threads = []
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
# 添加线程到线程列表
threads.append(thread1)
threads.append(thread2)
# 等待所有线程完成
for t in threads:
t.join()
print ("退出主线程")
执行以上程序,输出结果为: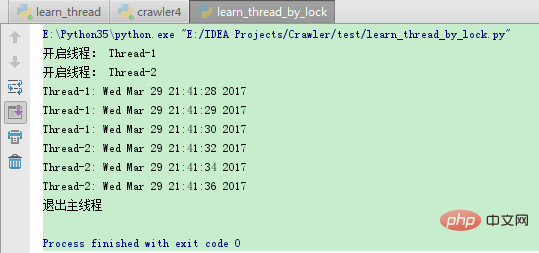
线程优先级队列(Queue)
Python 的 Queue 模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列 PriorityQueue。
这些队列都实现了锁原语,能够在多线程中直接使用,可以使用队列来实现线程间的同步。
Queue 模块中的常用方法:
- Queue.qsize() 返回队列的大小
- Queue.empty() 如果队列为空,返回True,反之False
- Queue.full() 如果队列满了,返回True,反之False
- Queue.full 与 maxsize 大小对应
- Queue.get([block[, timeout]])获取队列,timeout等待时间
- Queue.get_nowait() 相当Queue.get(False)
- Queue.put(item) 写入队列,timeout等待时间
- Queue.put_nowait(item) 相当Queue.put(item, False)
- Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
- Queue.join() 实际上意味着等到队列为空,再执行别的操作
实例:
#!/usr/bin/python3
import queue
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
print ("开启线程:" + self.name)
process_data(self.name, self.q)
print ("退出线程:" + self.name)
def process_data(threadName, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get()
queueLock.release()
print ("%s processing %s" % (threadName, data))
else:
queueLock.release()
time.sleep(1)
threadList = ["Thread-1", "Thread-2", "Thread-3"]
nameList = ["One", "Two", "Three", "Four", "Five"]
queueLock = threading.Lock()
workQueue = queue.Queue(10)
threads = []
threadID = 1
# 创建新线程
for tName in threadList:
thread = myThread(threadID, tName, workQueue)
thread.start()
threads.append(thread)
threadID += 1
# 填充队列
queueLock.acquire()
for word in nameList:
workQueue.put(word)
queueLock.release()
# 等待队列清空
while not workQueue.empty():
pass
# 通知线程是时候退出
exitFlag = 1
# 等待所有线程完成
for t in threads:
t.join()
print ("退出主线程")
以上程序执行结果: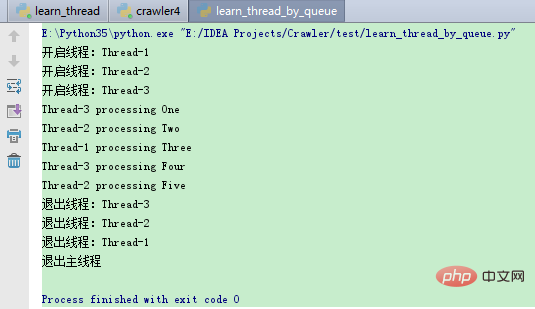
推荐学习:python学习教程
The above is the detailed content of Take you to interpret Python multi-threading. For more information, please follow other related articles on the PHP Chinese website!