
Home >Database >Mysql Tutorial >In-depth understanding of MySQL principles: Buffer pool (detailed graphic and text explanation)
In-depth understanding of MySQL principles: Buffer pool (detailed graphic and text explanation)

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBforward
- 2022-01-18 16:52:203643browse
This article brings you relevant knowledge about Buffer pool in MySQL, including data pages, cache page free linked lists, flush linked lists, LRU linked list Chunks, etc. I hope it will be helpful to everyone.

The importance of caching
Through the previous chatter, we know that for tables using InnoDB as the storage engine, Whether it is the index used to store user data (including clustered indexes and secondary indexes) or various system data, they are all stored in the table space in the form of pages , and the so-called table space is just InnoDB an abstraction of one or several actual files on the file system, which means that our data is still stored on the disk after all. But everyone also knows that the speed of a disk is as slow as a tortoise. How can it be worthy of a CPU that is "fast as the wind and as fast as lightning"? So InnoDB When the storage engine processes the client's request, when it needs to access the data of a certain page, it will load all the data of the complete page into the memory. That is to say, even if we only need to access one For a record of a page, the data of the entire page needs to be loaded into memory first. After loading the entire page into memory, you can perform read and write access. After completing the read and write access, you are not in a hurry to release the memory space corresponding to the page, but cache it, so When there is a request to access the page again in the future, the overhead of disk IO can be saved.
InnoDB's Buffer Pool
What is a Buffer Pool
The uncle who designed InnoDB, in order to cache the pages in the disk, MySQLWhen the server started, it applied for a piece of continuous memory from the operating system. They gave this memory a name, called Buffer Pool (the Chinese name is buffer pool ). So how big is it? This actually depends on the configuration of our machine. If you are rich and you have 512G memory, you can allocate a few hundred G as Buffer Pool. Of course, if you are not that rich , it’s okay to set it smaller~ By default, Buffer Pool is only 128M in size. Of course, if you dislike this 128M being too big or too small, you can configure the value of the innodb_buffer_pool_size parameter when starting the server, which represents the size of the Buffer Pool. Like this:
[server] innodb_buffer_pool_size = 268435456
Among them, the unit of 268435456 is bytes, that is, I specified the size of Buffer Pool to be 256M. It should be noted that Buffer Pool cannot be too small. The minimum value is 5M (when it is less than this value, it will be automatically set to 5M).
The internal composition of Buffer Pool
The default cache page size in Buffer Pool is the same as the default page size on disk, both are 16KB. In order to better manage these cache pages in Buffer Pool, the uncle who designed InnoDB created some so-called control information for each cache page. This control information includes the table space number, page number, cache page address in Buffer Pool to which the page belongs, linked list node information, some lock information and LSN information (lock and LSNWe will talk about it in detail later, you can ignore it for now), of course there are some other control information, we will not talk about them all here, just pick the important ones~
Every The memory size occupied by the control information corresponding to each cache page is the same. Let's call the memory occupied by the control information corresponding to each page a control block. The control block and the cache page are one by one. Correspondingly, they are all stored in the Buffer Pool, where the control block is stored in front of the Buffer Pool, and the cache page is stored in the back of the Buffer Pool, so the entire Buffer Pool corresponding memory space looks like this of:
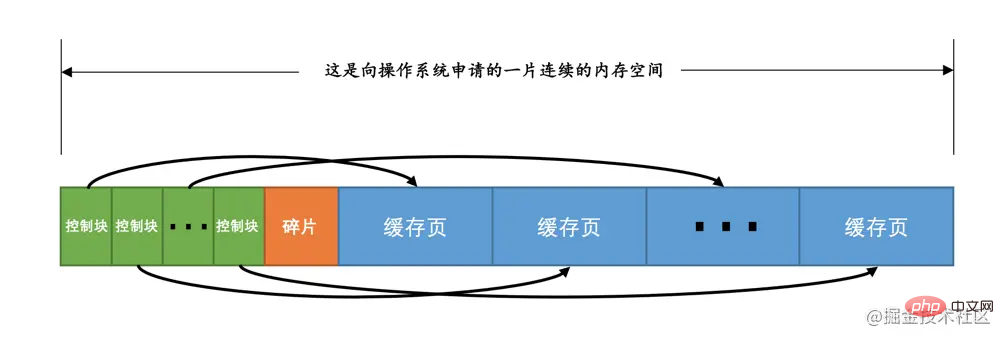
Eh? What is that fragment between the control block and the cache page? Think about it, each control block corresponds to a cache page. After allocating enough control blocks and cache pages, the remaining space may not be enough for a pair of control blocks and cache pages, so naturally it will not be used. Here, the little bit of memory space that is not used is called fragment. Of course, if you set the size of Buffer Pool just right, fragments~
Tips: Each control block occupies approximately 5% of the cache page size. In the version of MySQL 5.7.21, the size of each control block is 808 bytes. The innodb_buffer_pool_size we set does not include the memory space occupied by this part of the control block. That is to say, when InnoDB applies for continuous memory space from the operating system for the Buffer Pool, this continuous memory space will generally be 5 larger than the value of innodb_buffer_pool_size. %about.
Management of free linked lists
When we initially start the MySQL server, we need to complete the Buffer Pool## The initialization process of # is to first apply to the operating system for the memory space of Buffer Pool, and then divide it into several pairs of control blocks and cache pages. However, no real disk pages are cached in Buffer Pool at this time (because they have not been used yet). Later, as the program runs, pages on the disk will continue to be cached in In Buffer Pool. So the question is, when reading a page from the disk into Buffer Pool, where should it be placed in the cache page? Or how to distinguish which cache pages in Buffer Pool are free and which ones have been used? We'd better record which cache pages in the Buffer Pool are available somewhere. At this time, the control block corresponding to the cache page comes in handy. We can put all the free cache pages corresponding to The control block is placed as a node in a linked list. This linked list can also be called free linked list (or free linked list). All cache pages in the Buffer Pool that have just been initialized are free, so the control block corresponding to each cache page will be added to the free linked list, assuming that The number of cache pages that can be accommodated in Buffer Pool is n, so the effect of adding free linked list is like this:
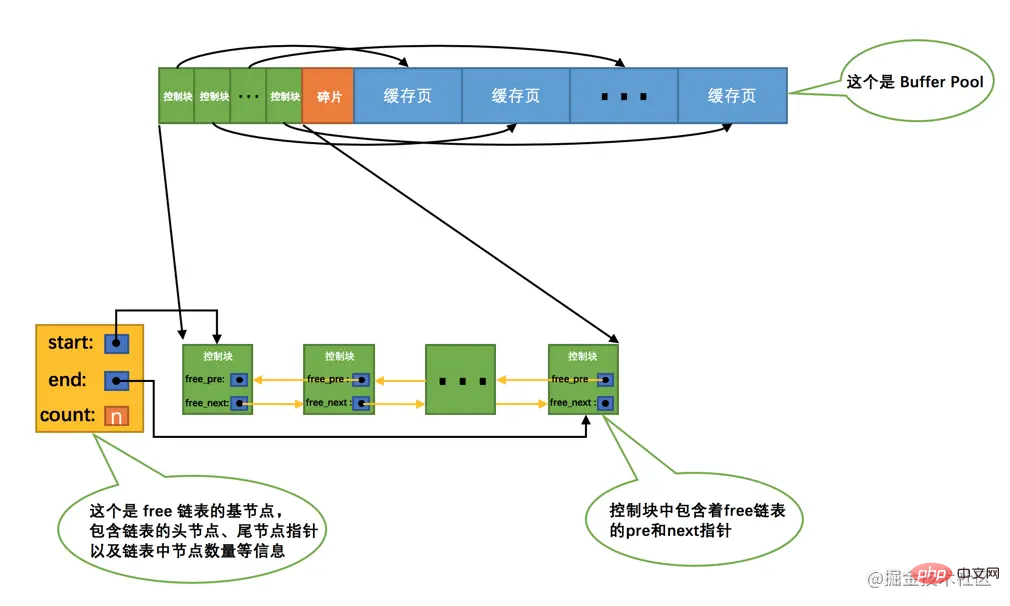
free linked list, we specially defined a base node for this linked list, which contains the address of the head node of the linked list. , the tail node address, and the number of nodes in the current linked list and other information. What needs to be noted here is that the memory space occupied by the base node of the linked list is not included in the large contiguous memory space applied for Buffer Pool, but is a separate piece of memory space applied for.
Tips: The memory space occupied by the base node of the linked list is not large. In the version of MySQL5.7.21, each base node only occupies 40 bytes. We will introduce many different linked lists later. The memory allocation methods of their base nodes and the base nodes of free linked lists are the same. They are all separately applied for a 40-byte memory space, which is not included in the application for Buffer Pool. within a large contiguous memory space.With this
free linked list, things will be easier to handle. Whenever you need to load a page from the disk into Buffer Pool, just Take a free cache page from the free linked list, and fill in the control block information corresponding to the cache page (that is, the table space where the page is located, page number, etc. information), and then remove the free linked list node corresponding to the cache page from the linked list, indicating that the cache page has been used~
Hash processing of the cache page
We said before that when we need to access the data in a certain page, the page will be loaded from the disk to theBuffer Pool. If the page is already in Buffer Pool can be used directly. Then the question arises, how do we know whether the page is in Buffer Pool? Is it necessary to traverse each cache page in Buffer Pool in sequence? Wouldn't it be exhausting to traverse so many cache pages in a Buffer Pool?
table space number page number, which is equivalent to table space number page number being a key, cache page is the corresponding value, how to quickly find a value through a key? Haha, that must be a hash table~
Tips: What? Don't tell me you don't know what a hash table is? Our article is not about hash tables. If you don’t know how to do it, then go read this book on data structures~ What? Can’t you read the books outside? Don't worry, wait for me~So we can use
table space number page number as key, cache page as valueCreate a hash table. When you need to access the data of a certain page, first check whether there is a corresponding cache page in the hash table according to the table space number page number. If so, , just use the cache page directly. If not, select a free cache page from the free linked list, and then load the corresponding page from the disk to the location of the cache page.
Management of flush linked lists
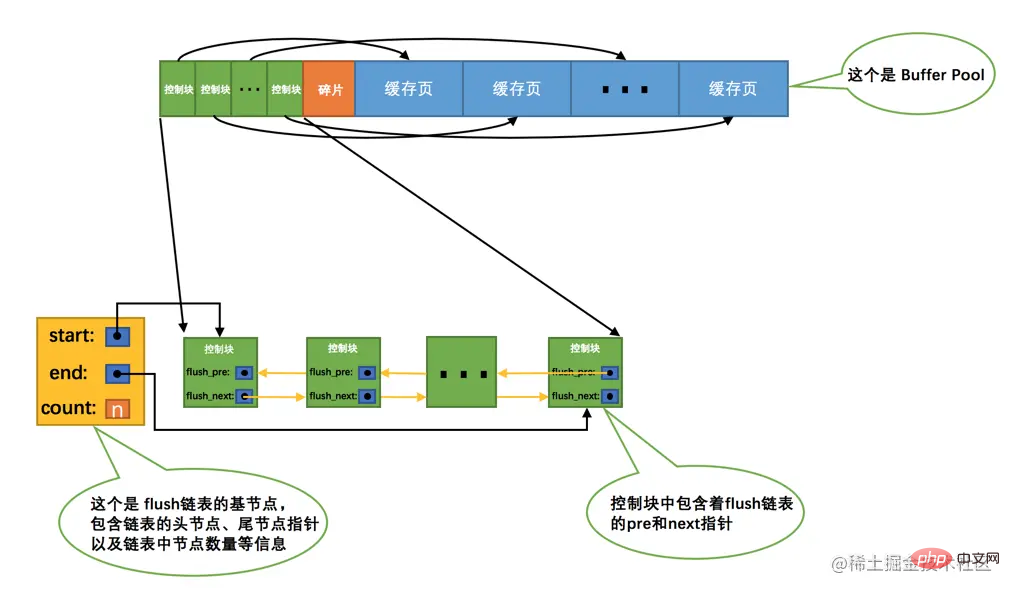
If we modify the data of a cache page in Buffer Pool, then it will be inconsistent with the page on the disk. Such cache pages are also called dirty pages (English name: dirty page). Of course, the simplest way is to synchronize it to the corresponding page on the disk immediately every time a modification occurs, but frequently writing data to the disk will seriously affect the performance of the program (after all, the disk is as slow as a turtle). So every time we modify the cache page, we are not in a hurry to synchronize the modification to the disk immediately, but synchronize it at a certain point in the future. As for this synchronization time, we will explain it later, so don’t worry about it now. Ha~
But if it is not synchronized to the disk immediately, how will we know which pages in the Buffer Pool are dirty pages and which pages have never been synchronized? Hasn't it been modified? You can't synchronize all cache pages to the disk. If Buffer Pool is set to a large size, such as 300G, wouldn't it be slower to synchronize so much data at once? die! Therefore, we have to create another linked list to store dirty pages. The control blocks corresponding to the modified cache pages will be added to a linked list as a node, because the cache pages corresponding to the linked list nodes need to be refreshed to the disk. , so it is also called flush linked list. The structure of the linked list is similar to the free linked list. Assume that the number of dirty pages in Buffer Pool at a certain point in time is n, then the corresponding flush linked listIt looks like this:
LRU linked list management
The dilemma of insufficient cache
Buffer PoolCorrespondence After all, the memory size is limited. If the memory size occupied by the pages that need to be cached exceeds the Buffer Pool size, that is, there are no extra free cache pages in the free linked list. Isn't it embarrassing? What should I do if something like this happens? Of course, some old cache pages are removed from Buffer Pool, and then new pages are put in~ So the question is, which cache pages should be removed?
In order to answer this question, we need to go back to the original intention of setting up Buffer Pool. We just want to reduce the IO interaction with the disk. It is best to do it every time When a page is accessed, it has been cached in Buffer Pool. Assuming that we have visited a total of n times, then the number of times the visited page has been in the cache divided by n is the so-called cache hit rate, our The expectation is to make the cache hit rate the higher the better~ From this perspective, think back to our WeChat chat list. The ones at the top are those that have been used frequently recently, and the ones at the back are naturally those that have been used frequently recently. For rarely used contacts, if the list can only accommodate a limited number of contacts, will you keep the ones you have used frequently recently or the ones you have rarely used recently? Nonsense, of course I’m leaving the ones that have been used frequently recently~
Simple LRU linked list
ManagementBuffer Pool’s cache page actually has the same principle, when When there are no more free cache pages in Buffer Pool, some cache pages that have been rarely used recently need to be eliminated. However, how do we know which cached pages have been used frequently recently and which ones have been used rarely? Haha, the magical linked list comes in handy again. We can create another linked list. Since this linked list is toeliminate cache pages according to the principle of least recently used, so this linked list can be calledLRU linked list (The full English name of LRU: Least Recently Used). When we need to access a page, we can handle the LRU linked list like this:
If the page is not in the
Buffer Pool, put the When the page is loaded from the disk to the cache page inBuffer Pool, thecontrol blockcorresponding to the cache page is inserted into the head of the linked list as a node.If the page has been cached in the
Buffer Pool, directly move thecontrol blockcorresponding to the page to theLRU linked list's head.
That is to say: as long as we use a certain cache page, we will adjust the cache page to the head of the LRU linked list, so thatLRU linked list The tail is the least recently used cache page~ So when the free cache pages in Buffer Pool are used up, go to the tail of LRU linked list to find some cache pages to eliminate. La, it’s so simple, tsk tsk...
LRU linked list for dividing areas
I’m so happy, the above simpleLRU linked list didn’t take long It took time to discover the problem, because there are two embarrassing situations:
-
Situation 1:
InnoDBprovides a seemingly considerate service -read ahead(English name:read ahead). The so-calledpre-readingmeans thatInnoDBbelieves that certain pages may be read after executing the current request, so it loads them intoBuffer Poolin advance. Depending on the triggering method,Pre-readingcan be subdivided into the following two types:-
Linear pre-reading
Design
InnoDB’s uncle provides a system variableinnodb_read_ahead_threshold. If the pages sequentially accessed in a certain area (extent) exceed the value of this system variable, anasynchronous event will be triggered.Request to read all pages in the next area toBuffer Pool, note thatAsynchronousreading means that loading these pre-read pages from disk will not affect to the normal execution of the current worker thread. The value of thisinnodb_read_ahead_thresholdsystem variable defaults to56. We can directly adjust the value of this system variable through startup parameters when the server starts or during server operation, but it is a global variable. , please use theSET GLOBALcommand to modify it.Tips: How does InnoDB implement asynchronous reading? On Windows or Linux platforms, it may be possible to directly call the AIO interface provided by the operating system kernel. In other Unix-like operating systems, a method of simulating the AIO interface is used to achieve asynchronous reading. In fact, it is to let other threads read Get the page that needs to be read in advance. If you don't understand the above paragraph, then there is no need to understand it. It has nothing to do with our topic. You only need to know that asynchronous reading will not affect the normal execution of the current working thread. In fact, this process involves how the operating system handles IO and multi-threading issues. Find a book on the operating system and read it. What? Is the writing of the operating system difficult to understand? It doesn't matter, wait for me~
-
Random pre-reading
If 13 consecutive buffers of a certain area have been cached in
Buffer PoolPages, regardless of whether these pages are read sequentially, will trigger aasynchronousrequest to read all other pages in this area toBuffer Pool. The uncle who designedInnoDBalso provided theinnodb_random_read_aheadsystem variable. Its default value isOFF, which means thatInnoDBdoes not The random read-ahead function is enabled by default. If we want to enable this function, we can set the value of this variable toONby modifying the startup parameters or directly using theSET GLOBALcommand.
Pre-readingis originally a good thing. If the page in the pre-readingBuffer Poolis successfully used, it can be extremely useful. Greatly improve the efficiency of statement execution. But what if it’s not used? These pre-read pages will be placed at the head of theLRUlinked list, but if the capacity ofBuffer Poolis not too large at this time and many pre-read pages are not used, this This will cause some cache pages at the end of theLRU linked listto be quickly eliminated, which is the so-calledbad coins drive out good coins, which will greatly reduce the cache hit rate. -
-
Situation 2: Some friends may write some query statements that need to scan the entire table (such as queries that do not create appropriate indexes or do not have a WHERE clause at all).
What does it mean to scan the entire table? This means that all pages where the table is located will be accessed! Assuming that there are very many records in this table, the table will occupy a particularly large number of
pages. When these pages need to be accessed, they will all be loaded into theBuffer Pool. This will This means that all the pages inBuffer Poolhave been replaced once, and other query statements have to be loaded from disk toBuffer Poolwhen they are executed. . The execution frequency of this kind of full table scan statement is not high. Every time it is executed, the cache page inBuffer Poolmust be replaced, which seriously affects the use of other queries inBuffer Pool The use ofgreatly reduces the cache hit rate.
Summarize the two situations mentioned above that may reduce Buffer Pool:
Load into
Buffer Pages in Poolmay not be used.If many pages with low usage frequency are loaded into
Buffer Poolat the same time, those pages with very high usage frequency may be removed fromEliminated from Buffer Pool.
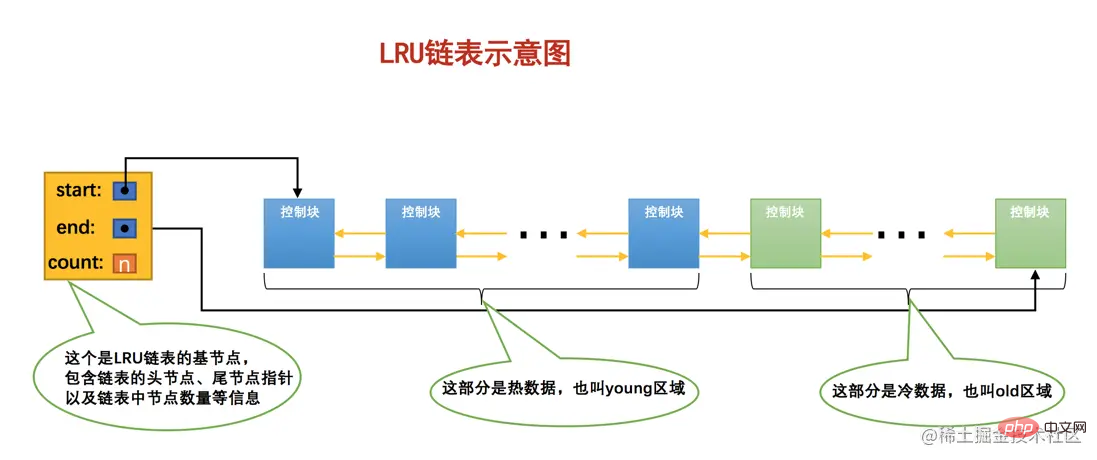
Because these two situations exist, the uncle who designed InnoDB divided this LRU linked list into two parts according to a certain proportion, respectively. Yes:
Part of the cache page stores very frequently used cache pages, so this part of the linked list is also called
hot data, oryoung area.The other part stores cache pages that are not used very frequently, so this part of the linked list is also called
cold data, orold area.
In order to facilitate everyone’s understanding, we have simplified the schematic diagram, so you can understand the spirit:
大家要特别注意一个事儿:我们是按照某个比例将LRU链表分成两半的,不是某些节点固定是young区域的,某些节点固定是old区域的,随着程序的运行,某个节点所属的区域也可能发生变化。那这个划分成两截的比例怎么确定呢?对于InnoDB存储引擎来说,我们可以通过查看系统变量innodb_old_blocks_pct的值来确定old区域在LRU链表中所占的比例,比方说这样:
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_pct'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | innodb_old_blocks_pct | 37 | +-----------------------+-------+ 1 row in set (0.01 sec)
从结果可以看出来,默认情况下,old区域在LRU链表中所占的比例是37%,也就是说old区域大约占LRU链表的3/8。这个比例我们是可以设置的,我们可以在启动时修改innodb_old_blocks_pct参数来控制old区域在LRU链表中所占的比例,比方说这样修改配置文件:
[server] innodb_old_blocks_pct = 40
这样我们在启动服务器后,old区域占LRU链表的比例就是40%。当然,如果在服务器运行期间,我们也可以修改这个系统变量的值,不过需要注意的是,这个系统变量属于全局变量,一经修改,会对所有客户端生效,所以我们只能这样修改:
SET GLOBAL innodb_old_blocks_pct = 40;
有了这个被划分成young和old区域的LRU链表之后,设计InnoDB的大叔就可以针对我们上边提到的两种可能降低缓存命中率的情况进行优化了:
-
针对预读的页面可能不进行后续访问情况的优化
设计
InnoDB的大叔规定,当磁盘上的某个页面在初次加载到Buffer Pool中的某个缓存页时,该缓存页对应的控制块会被放到old区域的头部。这样针对预读到Buffer Pool却不进行后续访问的页面就会被逐渐从old区域逐出,而不会影响young区域中被使用比较频繁的缓存页。 -
针对全表扫描时,短时间内访问大量使用频率非常低的页面情况的优化
在进行全表扫描时,虽然首次被加载到
Buffer Pool的页被放到了old区域的头部,但是后续会被马上访问到,每次进行访问的时候又会把该页放到young区域的头部,这样仍然会把那些使用频率比较高的页面给顶下去。有同学会想:可不可以在第一次访问该页面时不将其从old区域移动到young区域的头部,后续访问时再将其移动到young区域的头部。回答是:行不通!因为设计InnoDB的大叔规定每次去页面中读取一条记录时,都算是访问一次页面,而一个页面中可能会包含很多条记录,也就是说读取完某个页面的记录就相当于访问了这个页面好多次。咋办?全表扫描有一个特点,那就是它的执行频率非常低,谁也不会没事儿老在那写全表扫描的语句玩,而且在执行全表扫描的过程中,即使某个页面中有很多条记录,也就是去多次访问这个页面所花费的时间也是非常少的。所以我们只需要规定,在对某个处在
old区域的缓存页进行第一次访问时就在它对应的控制块中记录下来这个访问时间,如果后续的访问时间与第一次访问的时间在某个时间间隔内,那么该页面就不会被从old区域移动到young区域的头部,否则将它移动到young区域的头部。上述的这个间隔时间是由系统变量innodb_old_blocks_time控制的,你看:
mysql> SHOW VARIABLES LIKE 'innodb_old_blocks_time'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | innodb_old_blocks_time | 1000 | +------------------------+-------+ 1 row in set (0.01 sec)
这个innodb_old_blocks_time的默认值是1000,它的单位是毫秒,也就意味着对于从磁盘上被加载到LRU链表的old区域的某个页来说,如果第一次和最后一次访问该页面的时间间隔小于1s(很明显在一次全表扫描的过程中,多次访问一个页面中的时间不会超过1s),那么该页是不会被加入到young区域的~ 当然,像innodb_old_blocks_pct一样,我们也可以在服务器启动或运行时设置innodb_old_blocks_time的值,这里就不赘述了,你自己试试吧~ 这里需要注意的是,如果我们把innodb_old_blocks_time的值设置为0,那么每次我们访问一个页面时就会把该页面放到young区域的头部。
In summary, it is precisely because the LRU linked list is divided into two parts: young and old areas, and innodb_old_blocks_time is added This system variable curbs the problem of reduced cache hit rate caused by the read-ahead mechanism and full table scan, because unused pre-read pages and full table scan pages will only be placed in old area without affecting cached pages in the young area.
Further optimize the LRU linked list
LRU linked listIs this all? No, it’s early~ For the cache page in the young area, every time we access a cache page, we have to move it to the head of the LRU linked list. Isn’t this too expensive? Well, after all, the cached pages in the young area are hot data, that is, they may be frequently accessed. Isn't it bad to frequently move nodes to the LRU linked list like this? ah? Yes, in order to solve this problem, we can actually propose some optimization strategies. For example, only the accessed cache page located behind 1/4 in the young area will be moved to LRU linked list header, so that the frequency of adjusting the LRU linked list can be reduced, thereby improving performance (that is, if the node corresponding to a cache page is young In area 1/4, when the cache page is accessed again, it will not be moved to the head of the LRU linked list).
Tips: When we introduced random pre-reading before, we said that if there are 13 consecutive pages in a certain area in the Buffer Pool, random pre-reading will be triggered. This is actually not rigorous. (Unfortunately, this is what the MySQL documentation says [show hands]). In fact, these 13 pages are also required to be very hot pages. The so-called very hot refers to these pages being in the first 1/4 of the entire young area.
Are there any other optimization measures for LRU linked list? Of course there is. If you study hard, it won't be a problem to write a paper or a book. But after all, this is an article that introduces the basic knowledge of MySQL. If it is too long, it will be unbearable and it will affect everyone. reading experience, so enough is enough. If you want to know more optimization knowledge, go to the source code yourself or learn more about LRU linked lists~ But no matter how we optimize, don’t forget our original intention: try our best Efficiently improve the cache hit rate of Buffer Pool.
Some other linked lists
In order to better manage the cache pages in Buffer Pool, in addition to some of the measures we mentioned above, we designed InnoDB’s uncles also introduced some other linked lists, such as unzip LRU linked list for managing decompressed pages, zip clean linked list for managing undecompressed pages Compressed pages, each element in zip free array represents a linked list, they form the so-called partner system to provide memory space for compressed pages, etc., anyway, for better management This Buffer Pool introduces various linked lists or other data structures. The specific usage methods will not be tedious. If you are interested in learning more, you can find some more in-depth books or read the source code directly. You can also directly Come to me~
Tips: We have not talked about the compression pages in InnoDB in depth at all. The above linked lists are just mentioned by the way for completeness. If you don’t read Understand and don’t be depressed, because I have no intention of introducing them to you at all.
Refresh dirty pages to disk
There is a special thread in the background that is responsible for refreshing dirty pages to disk every once in a while, so that it does not affect the user thread's processing of normal requests. There are two main refresh paths:
-
Refresh a part of the pages from the cold data of the
LRU linked listto the disk.The background thread will periodically scan some pages starting from the end of the
LRU linked list. The number of pages scanned can be specified by the system variableinnodb_lru_scan_depth. If dirty pages are found inside , will flush them to disk. This method of refreshing the page is calledBUF_FLUSH_LRU. -
Refresh a portion of pages from the
flush linked listto disk.The background thread will also periodically refresh some pages from the
flush linked listto the disk. The refresh rate depends on whether the system is very busy at the time. This method of refreshing the page is calledBUF_FLUSH_LIST.
Sometimes the background thread refreshes dirty pages slowly, causing the user thread to have no available cache page when preparing to load a disk page to Buffer Pool. This causes will try to see if there are unmodified pages at the end of the LRU linked list that can be directly released. If not, a dirty page at the end of the LRU linked list will have to be flushed to the disk synchronously. (Interacting with the disk is very slow, which will slow down the processing of user requests). This flush method of flushing a single page to disk is called BUF_FLUSH_SINGLE_PAGE.
当然,有时候系统特别繁忙时,也可能出现用户线程批量的从flush链表中刷新脏页的情况,很显然在处理用户请求过程中去刷新脏页是一种严重降低处理速度的行为(毕竟磁盘的速度慢的要死),这属于一种迫不得已的情况,不过这得放在后边唠叨redo日志的checkpoint时说了。
多个Buffer Pool实例
我们上边说过,Buffer Pool本质是InnoDB向操作系统申请的一块连续的内存空间,在多线程环境下,访问Buffer Pool中的各种链表都需要加锁处理啥的,在Buffer Pool特别大而且多线程并发访问特别高的情况下,单一的Buffer Pool可能会影响请求的处理速度。所以在Buffer Pool特别大的时候,我们可以把它们拆分成若干个小的Buffer Pool,每个Buffer Pool都称为一个实例,它们都是独立的,独立的去申请内存空间,独立的管理各种链表,独立的吧啦吧啦,所以在多线程并发访问时并不会相互影响,从而提高并发处理能力。我们可以在服务器启动的时候通过设置innodb_buffer_pool_instances的值来修改Buffer Pool实例的个数,比方说这样:
[server] innodb_buffer_pool_instances = 2
这样就表明我们要创建2个Buffer Pool实例,示意图就是这样:
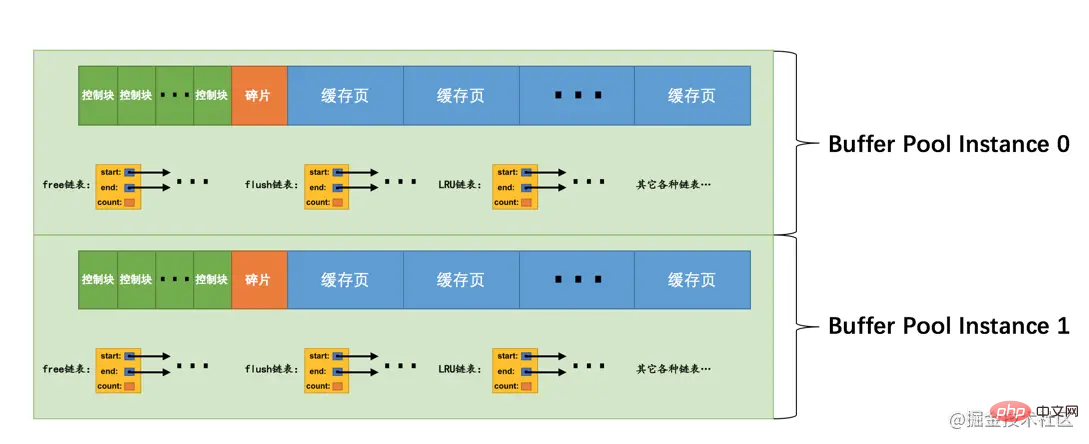
小贴士: 为了简便,我只把各个链表的基节点画出来了,大家应该心里清楚这些链表的节点其实就是每个缓存页对应的控制块!
那每个Buffer Pool实例实际占多少内存空间呢?其实使用这个公式算出来的:
innodb_buffer_pool_size/innodb_buffer_pool_instances
也就是总共的大小除以实例的个数,结果就是每个Buffer Pool实例占用的大小。
不过也不是说Buffer Pool实例创建的越多越好,分别管理各个Buffer Pool也是需要性能开销的,设计InnoDB的大叔们规定:当innodb_buffer_pool_size的值小于1G的时候设置多个实例是无效的,InnoDB会默认把innodb_buffer_pool_instances 的值修改为1。而我们鼓励在Buffer Pool大于或等于1G的时候设置多个Buffer Pool实例。
innodb_buffer_pool_chunk_size
在MySQL 5.7.5之前,Buffer Pool的大小只能在服务器启动时通过配置innodb_buffer_pool_size启动参数来调整大小,在服务器运行过程中是不允许调整该值的。不过设计MySQL的大叔在5.7.5以及之后的版本中支持了在服务器运行过程中调整Buffer Pool大小的功能,但是有一个问题,就是每次当我们要重新调整Buffer Pool大小时,都需要重新向操作系统申请一块连续的内存空间,然后将旧的Buffer Pool中的内容复制到这一块新空间,这是极其耗时的。所以设计MySQL的大叔们决定不再一次性为某个Buffer Pool实例向操作系统申请一大片连续的内存空间,而是以一个所谓的chunk为单位向操作系统申请空间。也就是说一个Buffer Pool实例其实是由若干个chunk组成的,一个chunk就代表一片连续的内存空间,里边儿包含了若干缓存页与其对应的控制块,画个图表示就是这样:
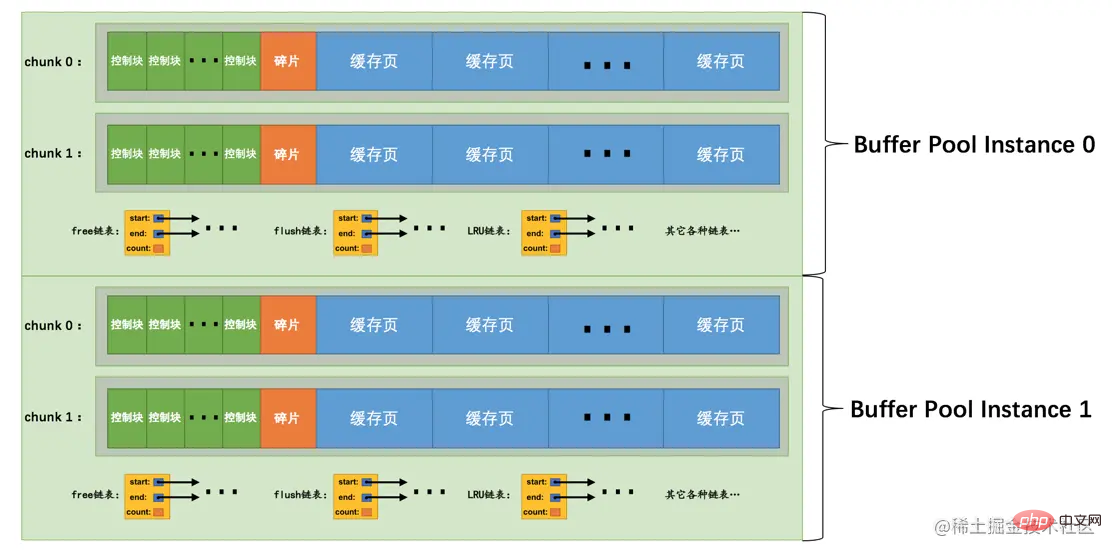
上图代表的Buffer Pool就是由2个实例组成的,每个实例中又包含2个chunk。
正是因为发明了这个chunk的概念,我们在服务器运行期间调整Buffer Pool的大小时就是以chunk为单位增加或者删除内存空间,而不需要重新向操作系统申请一片大的内存,然后进行缓存页的复制。这个所谓的chunk的大小是我们在启动操作MySQL服务器时通过innodb_buffer_pool_chunk_size启动参数指定的,它的默认值是134217728,也就是128M。不过需要注意的是,innodb_buffer_pool_chunk_size的值只能在服务器启动时指定,在服务器运行过程中是不可以修改的。
小贴士: 为什么不允许在服务器运行过程中修改innodb_buffer_pool_chunk_size的值?还不是因为innodb_buffer_pool_chunk_size的值代表InnoDB向操作系统申请的一片连续的内存空间的大小,如果你在服务器运行过程中修改了该值,就意味着要重新向操作系统申请连续的内存空间并且将原先的缓存页和它们对应的控制块复制到这个新的内存空间中,这是十分耗时的操作! 另外,这个innodb_buffer_pool_chunk_size的值并不包含缓存页对应的控制块的内存空间大小,所以实际上InnoDB向操作系统申请连续内存空间时,每个chunk的大小要比innodb_buffer_pool_chunk_size的值大一些,约5%。
配置Buffer Pool时的注意事项
-
innodb_buffer_pool_size必须是innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances的倍数(这主要是想保证每一个Buffer Pool实例中包含的chunk数量相同)。假设我们指定的
innodb_buffer_pool_chunk_size的值是128M,innodb_buffer_pool_instances的值是16,那么这两个值的乘积就是2G,也就是说innodb_buffer_pool_size的值必须是2G或者2G的整数倍。比方说我们在启动MySQL服务器是这样指定启动参数的:mysqld --innodb-buffer-pool-size=8G --innodb-buffer-pool-instances=16
默认的
innodb_buffer_pool_chunk_size值是128M,指定的innodb_buffer_pool_instances的值是16,所以innodb_buffer_pool_size的值必须是2G或者2G的整数倍,上边例子中指定的innodb_buffer_pool_size的值是8G,符合规定,所以在服务器启动完成之后我们查看一下该变量的值就是我们指定的8G(8589934592字节):mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+------------+ | Variable_name | Value | +-------------------------+------------+ | innodb_buffer_pool_size | 8589934592 | +-------------------------+------------+ 1 row in set (0.00 sec)
如果我们指定的
innodb_buffer_pool_size大于2G并且不是2G的整数倍,那么服务器会自动的把innodb_buffer_pool_size的值调整为2G的整数倍,比方说我们在启动服务器时指定的innodb_buffer_pool_size的值是9G:mysqld --innodb-buffer-pool-size=9G --innodb-buffer-pool-instances=16
那么服务器会自动把
innodb_buffer_pool_size的值调整为10G(10737418240字节),不信你看:mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+-------------+ | Variable_name | Value | +-------------------------+-------------+ | innodb_buffer_pool_size | 10737418240 | +-------------------------+-------------+ 1 row in set (0.01 sec)
-
如果在服务器启动时,
innodb_buffer_pool_chunk_size × innodb_buffer_pool_instances的值已经大于innodb_buffer_pool_size的值,那么innodb_buffer_pool_chunk_size的值会被服务器自动设置为innodb_buffer_pool_size/innodb_buffer_pool_instances的值。比方说我们在启动服务器时指定的
innodb_buffer_pool_size的值为2G,innodb_buffer_pool_instances的值为16,innodb_buffer_pool_chunk_size的值为256M:mysqld --innodb-buffer-pool-size=2G --innodb-buffer-pool-instances=16 --innodb-buffer-pool-chunk-size=256M
由于
256M × 16 = 4G,而4G > 2G,所以innodb_buffer_pool_chunk_size值会被服务器改写为innodb_buffer_pool_size/innodb_buffer_pool_instances的值,也就是:2G/16 = 128M(134217728字节),不信你看:mysql> show variables like 'innodb_buffer_pool_size'; +-------------------------+------------+ | Variable_name | Value | +-------------------------+------------+ | innodb_buffer_pool_size | 2147483648 | +-------------------------+------------+ 1 row in set (0.01 sec) mysql> show variables like 'innodb_buffer_pool_chunk_size'; +-------------------------------+-----------+ | Variable_name | Value | +-------------------------------+-----------+ | innodb_buffer_pool_chunk_size | 134217728 | +-------------------------------+-----------+ 1 row in set (0.00 sec)
Buffer Pool中存储的其它信息
Buffer Pool的缓存页除了用来缓存磁盘上的页面以外,还可以存储锁信息、自适应哈希索引等信息,这些内容等我们之后遇到了再详细讨论哈~
查看Buffer Pool的状态信息
设计MySQL的大叔贴心的给我们提供了SHOW ENGINE INNODB STATUS语句来查看关于InnoDB存储引擎运行过程中的一些状态信息,其中就包括Buffer Pool的一些信息,我们看一下(为了突出重点,我们只把输出中关于Buffer Pool的部分提取了出来):
mysql> SHOW ENGINE INNODB STATUS\G (...省略前边的许多状态) ---------------------- BUFFER POOL AND MEMORY ---------------------- Total memory allocated 13218349056; Dictionary memory allocated 4014231 Buffer pool size 786432 Free buffers 8174 Database pages 710576 Old database pages 262143 Modified db pages 124941 Pending reads 0 Pending writes: LRU 0, flush list 0, single page 0 Pages made young 6195930012, not young 78247510485 108.18 youngs/s, 226.15 non-youngs/s Pages read 2748866728, created 29217873, written 4845680877 160.77 reads/s, 3.80 creates/s, 190.16 writes/s Buffer pool hit rate 956 / 1000, young-making rate 30 / 1000 not 605 / 1000 Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s LRU len: 710576, unzip_LRU len: 118 I/O sum[134264]:cur[144], unzip sum[16]:cur[0] -------------- (...省略后边的许多状态) mysql>
我们来详细看一下这里边的每个值都代表什么意思:
Total memory allocated:代表Buffer Pool向操作系统申请的连续内存空间大小,包括全部控制块、缓存页、以及碎片的大小。Dictionary memory allocated:为数据字典信息分配的内存空间大小,注意这个内存空间和Buffer Pool没啥关系,不包括在Total memory allocated中。Buffer pool size:代表该Buffer Pool可以容纳多少缓存页,注意,单位是页!Free buffers:代表当前Buffer Pool还有多少空闲缓存页,也就是free链表中还有多少个节点。Database pages: represents the number of pages in theLRUlinked list, includingyoungandoldThe number of nodes in a region.Old database pages: represents the number of nodes in theLRUlinked listoldarea.Modified db pages: represents the number of dirty pages, which is the number of nodes in theflush linked list.-
Pending reads: The number of pages that are waiting to be loaded from disk intoBuffer Pool.When preparing to load a page from disk, a cache page and its corresponding control block will be allocated for this page in
Buffer Pool, and then this control block will be added to The header of theoldarea of LRU, but the real disk page has not been loaded at this time, and the value ofPending readswill be increased by 1. Pending writes LRU: The number of pages that will be flushed from theLRUlinked list to disk.Pending writes flush list: The number of pages that will be flushed to disk from theflushlinked list.Pending writes single page: The number of pages that will be flushed to disk as a single page.-
Pages made young: Represents that theLRUlinked list has moved from theoldarea toyoungThe number of nodes at the head of the region.It should be noted here that a node will
Pages made youngonly when it moves from theoldarea to the head of theyoungarea. The value is increased by 1, that is to say, if the node is originally in theyoungarea, because it meets the requirement of being behind 1/4 of theyoungarea, it will also be changed the next time you visit this page. It moves to the head of theyoungarea, but this process does not cause the value ofPages made youngto be increased by 1. -
It should be noted here that for a node in thePage made not young: Wheninnodb_old_blocks_timeis set to a value greater than 0, the first visit or subsequent visit to a location is ## When a node in the #oldarea cannot be moved to the head of theyoungarea because it does not meet the time interval limit, the value ofPage made not youngwill be increased by 1.young
area, if it is not moved to ## because it is 1/4 of theyoungarea #youngarea header, such access will not increase the value ofPage made not youngby 1. - youngs/s
: represents the number of nodes moved from the
oldarea to the head of theyoungarea per second . - non-youngs/s
: represents every second that cannot be moved from the
oldarea toyoung# because the time limit is not met. ##The number of nodes at the head of the region.Pages read - ,
created
,written: represents the number of pages read, created, and written. Followed by the rate of reading, creating, and writing.Buffer pool hit rate - : Indicates how many times the page has been cached in the
Buffer Pool for an average of 1,000 page visits in the past period.
.young-making rate - : Indicates that in a certain period of time in the past, the page was visited an average of 1,000 times, and how many visits moved the page to
young
area counted here does not only include moving from theThe head of the area.One thing that everyone needs to pay attention to is that the number of headers that move the page to theyoungold
area toyoung The number of times thearea head also includes the number of times it has moved from theyoungarea to theyoungarea head (visiting a node in ayoungarea, as long as If the node is 1/4 behind theyoungarea, it will be moved to the head of theyoungarea).not (young-making rate) - : Indicates that in a certain period of time in the past, the page was visited an average of 1,000 times, and how many visits did not move the page to
young
area counted here is not only caused by the setting of theThe head of the area.One thing that everyone needs to pay attention to is that the number of header times that the page is not moved to theyounginnodb_old_blocks_time
system variable The number of times nodes in theoldarea were visited without moving them to theyoungarea, including because the node was in the first 1/4 of theyoungarea The number of times it was not moved to the head of theyoungarea.LRU len - : represents the number of nodes in the
LRU linked list
.unzip_LRU - : represents the number of nodes in the
unzip_LRU linked list
(since we have not talked about this linked list specifically, its value can be ignored now ).I/O sum - : The total number of disk pages read in the last 50 seconds.
- : The number of disk pages currently being read.
- : The number of pages decompressed in the last 50 seconds.
- : The number of pages being decompressed.
总结
磁盘太慢,用内存作为缓存很有必要。
Buffer Pool本质上是InnoDB向操作系统申请的一段连续的内存空间,可以通过innodb_buffer_pool_size来调整它的大小。Buffer Pool向操作系统申请的连续内存由控制块和缓存页组成,每个控制块和缓存页都是一一对应的,在填充足够多的控制块和缓存页的组合后,Buffer Pool剩余的空间可能产生不够填充一组控制块和缓存页,这部分空间不能被使用,也被称为碎片。InnoDB使用了许多链表来管理Buffer Pool。free链表中每一个节点都代表一个空闲的缓存页,在将磁盘中的页加载到Buffer Pool时,会从free链表中寻找空闲的缓存页。为了快速定位某个页是否被加载到
Buffer Pool,使用表空间号 + 页号作为key,缓存页作为value,建立哈希表。在
Buffer Pool中被修改的页称为脏页,脏页并不是立即刷新,而是被加入到flush链表中,待之后的某个时刻同步到磁盘上。LRU链表分为young和old两个区域,可以通过innodb_old_blocks_pct来调节old区域所占的比例。首次从磁盘上加载到Buffer Pool的页会被放到old区域的头部,在innodb_old_blocks_time间隔时间内访问该页不会把它移动到young区域头部。在Buffer Pool没有可用的空闲缓存页时,会首先淘汰掉old区域的一些页。我们可以通过指定
innodb_buffer_pool_instances来控制Buffer Pool实例的个数,每个Buffer Pool实例中都有各自独立的链表,互不干扰。自
MySQL 5.7.5版本之后,可以在服务器运行过程中调整Buffer Pool大小。每个Buffer Pool实例由若干个chunk组成,每个chunk的大小可以在服务器启动时通过启动参数调整。-
可以用下边的命令查看
Buffer Pool的状态信息:SHOW ENGINE INNODB STATUS\G
推荐学习:mysql视频教程
The above is the detailed content of In-depth understanding of MySQL principles: Buffer pool (detailed graphic and text explanation). For more information, please follow other related articles on the PHP Chinese website!