
Home >Database >Mysql Tutorial >In-depth understanding of locks in MySQL (global locks, table-level locks, row locks)
In-depth understanding of locks in MySQL (global locks, table-level locks, row locks)

- 青灯夜游forward
- 2021-08-31 10:43:552255browse
This article will take you to understand the locks in MySQL and introduce the global locks, table-level locks and row locks of MySQL. I hope it will be helpful to you!

According to the scope of locking, the locks in MySQL can be roughly divided into three categories: global locks, table-level locks and row locks
1. Global lock
Global lock is to lock the entire database instance. MySQL provides a method to add a global read lock. The command is Flush tables with read lock. When you need to make the entire library in a read-only state, you can use this command. After that, the following statements of other threads will be blocked: data update statements (add, delete, and modify data), data definition statements (including creating tables, modifying table structures, etc.) and update transaction commit statements. [Related recommendations: mysql tutorial (video)]
The typical usage scenario of global lock is to make a logical backup of the entire database. That is to say, select every table in the entire database and save it as text
But if you make the entire database read-only, the following problems may occur:
- If you back up on the main database, then Updates cannot be performed during the backup period, and the business basically has to stop.
- If the backup is performed on the slave database, then the slave database cannot execute the binlog synchronized from the master database during the backup period, which will cause master-slave delay
Opening a transaction under the repeatable read isolation level can obtain the consistency view
The official logical backup tool is mysqldump. When mysqldump uses the parameter --single-transaction, a transaction will be started before importing data to ensure that a consistent view is obtained. Due to the support of MVCC, the data can be updated normally during this process. Single-transaction only applies to all tables using transaction engine libraries
1. Since the whole library is read-only, why not use set global readonly=true?
- In some systems, the value of readonly will be used for other logic, such as determining whether a library is the main library or the standby library. Therefore, the way of modifying global variables has a greater impact
- There are differences in the exception handling mechanism. If the client disconnects abnormally after executing the Flush tables with read lock command, MySQL will automatically release the global lock and the entire library will return to a state where it can be updated normally. After setting the entire library to readonly, if an exception occurs on the client, the database will remain in the readonly state, which will cause the entire library to be unwritable for a long time and the risk is high
2. Table-level locks
There are two types of table-level locks in MySQL: one is table lock and the other is meta data lock (MDL)
The syntax of table lock is lock tables...read/write. You can use unlock tables to actively release the lock, or you can release it automatically when the client disconnects. In addition to restricting the reading and writing of other threads, the lock tables syntax also limits the next operation objects of this thread
If executed in a certain thread Alock tables t1 read,t2 wirte;With this statement, other threads' statements writing t1 and reading and writing t2 will be blocked. At the same time, thread A can only perform the operations of reading t1 and reading and writing t2 before executing unlock tables. Even writing to t1 is not allowed
Another type of table-level lock is MDL. MDL does not need to be used explicitly, it will be added automatically when accessing a table. The function of MDL is to ensure the correctness of reading and writing. If a query is traversing the data in a table, and another thread makes changes to the table structure during execution and deletes a column, then the results obtained by the query thread do not match the table structure, and it will definitely not work
In the MySQL version 5.5, MDL was introduced. When adding, deleting, modifying, and querying a table, add MDL read locks; when making structural changes to the table, add MDL write locks
- Read locks are not mutually exclusive, so multiple threads can add, delete, modify and query a table at the same time
- Read and write locks, Write locks are mutually exclusive and are used to ensure the safety of operations that change the table structure. Therefore, if there are two threads that want to add fields to a table at the same time, one of them has to wait for the other to finish executing before it can start executing.
Add fields to a table, or modify fields, or add Index needs to scan the data of the entire table. When operating large tables, you need to be particularly careful to avoid affecting online services
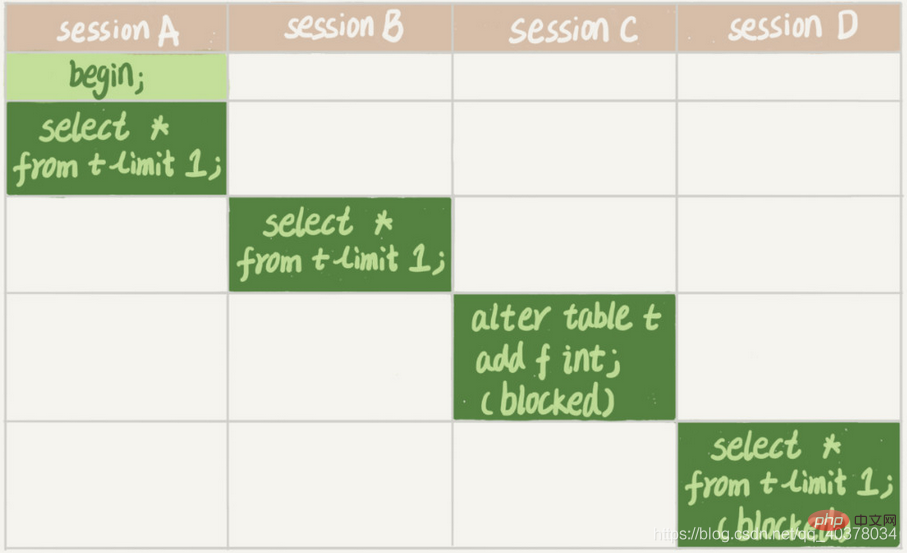
session A is started first, and an MDL read lock will be added to table t at this time. Since session B also requires the MDL read lock, it can be executed normally. Later, session C will be blocked because the MDL read lock of session A has not been released, and session C needs the MDL write lock, so it can only be blocked. It doesn't matter if only session C itself is blocked, but all future requests to apply for MDL read locks on table t will also be blocked by session C. All add, delete, modify and query operations on the table need to apply for the MDL read lock first, and then they are all locked, which means that the table is now completely unreadable and writable
The MDL lock in the transaction is applied for at the beginning of the statement execution, but it will not be released immediately after the statement ends, but will be released after the entire transaction is committed
1. If Safely add fields to small tables?
First of all, long transactions must be resolved. If the transaction is not submitted, the DML lock will always be occupied. In the innodb_trx table of MySQL's information_schema library, the currently executed transaction can be found. If the table to be changed by DDL happens to have a long transaction being executed, consider pausing the DDL first or killing the long transaction
2. If the table to be changed is a hotspot table, although the amount of data is not large, But the above requests are very frequent, and I have to add a field. What should I do?
Set the waiting time in the alter table statement. It is best if you can get the MDL write lock within the specified waiting time. If you can't get it, don't block subsequent business statements and give up first. Then repeat the process by retrying the command
3. Row lock
MySQL's row lock is implemented by each engine at the engine layer. But not all engines support row locks. For example, the MyISAM engine does not support row locks
Row locks are locks for row records in the data table. For example, if transaction A updates a row, and transaction B also wants to update the same row at this time, the update must wait until the operation of transaction A is completed.
1. Two-phase lock protocol

The row locks of the two records held by transaction A are not released until commit. The update statement of transaction B will be blocked until transaction A executes commit. Continue execution
In an InnoDB transaction, row locks are added when needed, but they are not released immediately when they are no longer needed, but are released until the end of the transaction. This is the two-phase lock protocol
If multiple rows need to be locked in a transaction, the locks that are most likely to cause lock conflicts and most likely to affect concurrency should be placed as far back as possible
Suppose you want to implement an online transaction of movie tickets, and customer A wants to buy movie tickets at theater B. The business needs to involve the following operations:
1. Deduct the movie ticket price from the account balance of customer A
2. Add the movie ticket price to the account balance of theater B
3. Record a transaction log
In order to ensure the atomicity of the transaction, these three operations must be placed in one transaction. How to arrange the order of these three statements in the transaction?
If there is another customer C who wants to buy tickets at theater B at the same time, then the conflict between the two transactions is statement 2. Because they want to update the balance of the same theater account, they need to modify the same row of data. According to the two-phase locking protocol, all row locks required for operations are released when the transaction is committed. Therefore, if statement 2 is arranged at the end, for example in the order of 3, 1, 2, then the lock time for the theater account balance line will be the least. This minimizes lock waiting between transactions and improves concurrency
2. Deadlock and deadlock detection
In concurrent systems Circular resource dependencies occur in different threads. When the threads involved are waiting for other threads to release resources, these threads will enter an infinite waiting state, which is called deadlock
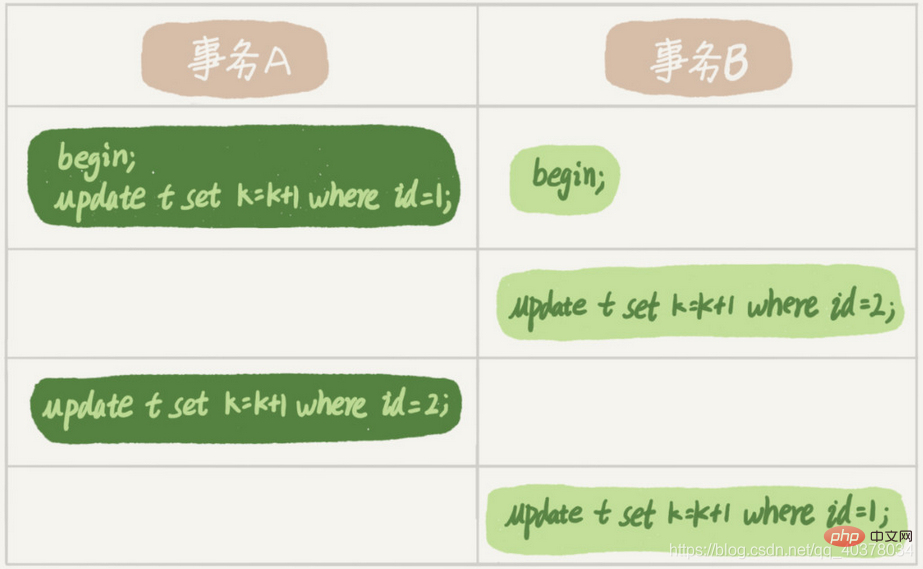
Transaction A is waiting for transaction B to release the row lock with id=2, and transaction B is waiting for transaction A to release the row lock with id=1. Transaction A and transaction B are waiting for each other's resources to be released, which means they have entered a deadlock state. When a deadlock occurs, there are two strategies:
- One strategy is to wait directly until timeout. This timeout can be set through the parameter innodb_lock_wait_timeout
- Another strategy is to initiate deadlock detection. After a deadlock is found, proactively roll back a transaction in the deadlock chain so that other transactions can continue to execute. Set the parameter innodb_deadlock_detect to on, which means turning on this logic
In InnoDB, the default value of innodb_lock_wait_timeout is 50s, which means that if the first strategy is adopted, when a deadlock occurs, the first one is The locked thread will time out and exit after 50 seconds, and then other threads may continue to execute. For online services, this waiting time is often unacceptable
Under normal circumstances, an active deadlock checking strategy must be adopted, and the default value of innodb_deadlock_detect itself is on. Active deadlock monitoring can quickly detect and handle deadlocks when they occur, but it has additional burdens. Whenever a transaction is locked, it is necessary to check whether the thread it depends on is locked by others, and so on, and finally determine whether there is a circular wait, that is, a deadlock
If all transactions are locked To update the same row, each newly blocked thread must determine whether it will cause a deadlock due to its own addition. This is an operation with a time complexity of O(n)
How to solve the performance problems caused by such hot row updates?
1. If you ensure that this business will not deadlock, you can temporarily turn off deadlock detection
2. Control concurrency
3. Change one line into multiple logical lines to reduce lock conflicts. Taking the theater account as an example, you can consider placing it on multiple records, such as 10 records. The total amount of the theater's account is equal to the sum of the values of these 10 records. In this way, every time you want to add money to the theater account, you can randomly select one of the records to add. In this way, the probability of each conflict becomes 1/10 of the original member, which can reduce the number of lock waits and reduce the CPU consumption of deadlock detection.
4. Why do I only check one line of statements? Execution so slow?
Construct a table with two fields id and c, and insert 100,000 rows of records into it
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
CREATE DEFINER=`root`@`%` PROCEDURE `idata`()
BEGIN
declare i int;
set i=1;
while(i<=100000) do
insert into t values(i,i);
set i=i+1;
end while;
END1. Category 1: long query The time is not returned
select * from t3 where id=1;
The query result is not returned for a long time. Use the show processlist command to check the status of the current statement
1), wait for the MDL lock
As shown in the figure below, use the show processlist; command to view the diagram of Waiting for table metadata lock

This status indicates that there is now a The thread is requesting or holding an MDL write lock on table t, blocking the select statement
Scenario recurrence:

sessionA holds the MDL write lock on table t through the lock table command, and sessionB's query needs to acquire the MDL read lock. Therefore, sessionB enters the waiting state
The way to deal with this kind of problem is to find out who holds the MDL write lock and then kill it. However, in the result of show processlist, the Command column of sessionA is Sleep, which makes it inconvenient to search. You can directly find out the process id causing the blocking by querying the sys.schema_table_lock_waits table, and disconnect the connection with the kill command ( You need to set performance_schema=on when starting MySQL. Compared with setting it to off, there will be about 10% performance loss)
select blocking_pid from sys.schema_table_lock_waits;
2), wait for flush
in the table Execute the following SQL statement on t:
select * from information_schema.processlist where id=1;
It is found that the status of a certain thread is Waiting for table flush
This status indicates that there is currently a thread that performs operations on table t. flush operation. There are generally two ways to perform flush operations on tables in MySQL:
flush tables t with read lock;flush tables with read lock;
These two flush statements, if table t is specified, mean that only table t is closed; if no specific table name is specified, , means closing all open tables in MySQL
But under normal circumstances, these two statements execute very quickly, unless they are blocked by other threads
So, Waiting for appears The possible situation of table flush status is: a flush tables command is blocked by other statements, and then it blocks the select statement
Scenario recurrence:

In sessionA, sleep(1) is called once for each row, so this statement will be executed for 100,000 seconds by default. During this period, table t has been opened by sessionA. Then, when sessionB flushes tables t and then closes table t, it needs to wait for sessionA's query to end. In this way, if sessionC wants to query again, it will be blocked by the flush command
3), waiting for row lock
select * from t where id=1 lock in share mode;
Because the access id= 1 A read lock must be added to this record. If there is already a transaction holding a write lock on this record at this time, the select statement will be blocked
Scenario recurrence:


SessionA started the transaction, occupied the write lock, and did not submit it. This is the reason why sessionB was blocked.
2. Category 2 : Query is slow

sessionA first uses the start transaction with consistent snapshot command to open a transaction and establish consistent reading of the transaction (also called snapshot reading. The MVCC mechanism is used to read Get the submitted data in the undo log. So its reading is non-blocking), and then sessionB executes the update statement
After sessionB executes 1 million update statements, it generates 1 million rollback logs
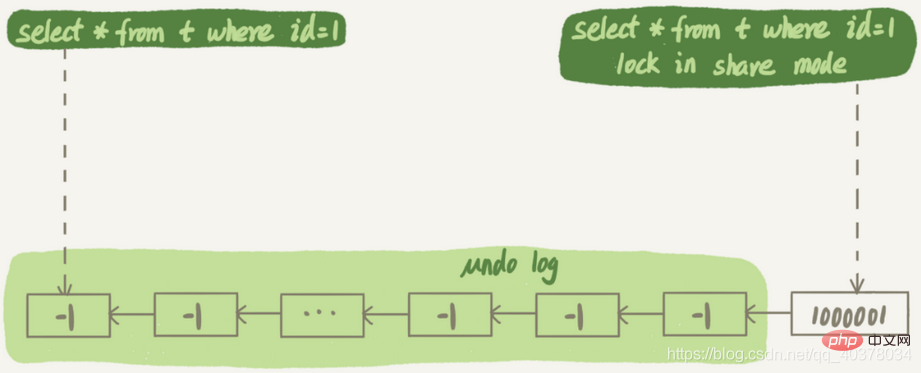
带lock in share mode的语句是当前读,因此会直接读到1000001这个结果,速度很快;而select * from t where id=1这个语句是一致性读,因此需要从1000001开始,依次执行undo log,执行了100万次以后,才将1这个结果返回
五、间隙锁
建表和初始化语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
这个表除了主键id外,还有一个索引c
为了解决幻读问题,InnoDB引入了间隙锁,锁的就是两个值之间的空隙
当执行select * from t where d=5 for update的时候,就不止是给数据库中已有的6个记录加上了行锁,还同时加了7个间隙锁。这样就确保了无法再插入新的记录
行锁分成读锁和写锁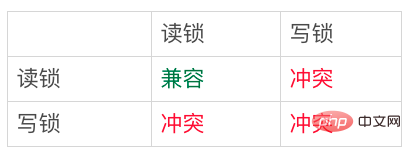
跟间隙锁存在冲突关系的是往这个间隙中插入一个记录这个操作。间隙锁之间不存在冲突关系
这里sessionB并不会被堵住。因为表t里面并没有c=7会这个记录,因此sessionA加的是间隙锁(5,10)。而sessionB也是在这个间隙加的间隙锁。它们用共同的目标,保护这个间隙,不允许插入值。但它们之间是不冲突的
间隙锁和行锁合称next-key lock,每个next-key lock是前开后闭区间。表t初始化以后,如果用select * from t for update要把整个表所有记录锁起来,就形成了7个next-key lock,分别是(-∞,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, +supremum]。因为+∞是开区间,在实现上,InnoDB给每个索引加了一个不存在的最大值supremum,这样才符合都是前开后闭区间
间隙锁和next-key lock的引入,解决了幻读的问题,但同时也带来了一些困扰
间隙锁导致的死锁:
1.sessionA执行select … for update语句,由于id=9这一行并不存在,因此会加上间隙锁(5,10)
2.sessionB执行select … for update语句,同样会加上间隙锁(5,10),间隙锁之间不会冲突
3.sessionB试图插入一行(9,9,9),被sessionA的间隙锁挡住了,只好进入等待
4.sessionA试图插入一行(9,9,9),被sessionB的间隙锁挡住了
两个session进入互相等待状态,形成了死锁
间隙锁的引入可能会导致同样的语句锁住更大的范围,这其实是影响并发度的
在读提交隔离级别下,不存在间隙锁
六、next-key lock
表t的建表语句和初始化语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
1、next-key lock加锁规则
- 原则1:加锁的基本单位是next-key lock,next-key lock是前开后闭区间
- 原则2:查找过程中访问到的对象才会加锁
- 优化1:索引上的等值查询,给唯一索引加锁的时候,next-key lock退化为行锁
- 优化2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock退化为间隙锁
- 一个bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止
这个规则只限于MySQL5.x系列
2、案例一:等值查询间隙锁

1.由于表t中没有id=7的记录,根据原则1,加锁单位是next-key lock,sessionA加锁范围就是(5,10]
2.根据优化2,这是一个等值查询(id=7),而id=10不满足查询条件,next-key lock退化成间隙锁,因此最终加锁的范围是(5,10)
所以,sessionB要往这个间隙里面插入id=8的记录会被锁住,但是sessionC修改id=10这行是可以的
3、案例二:非唯一索引等值锁
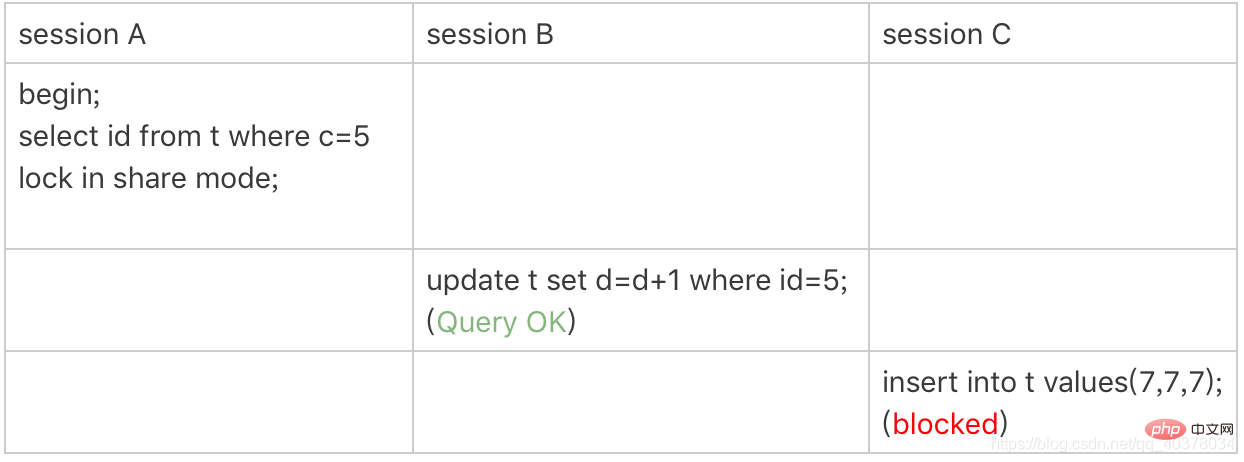
1.根据原则1,加锁单位是next-key lock,因此会给(0,5]加上next-key lock
2.c是普通索引,因此访问c=5这一条记录是不能马上停下来的,需要向右遍历,查到c=10才放弃。根据原则2,访问到的都要加锁,因此要给(5,10]加next-key lock
3.根据优化2,等值判断,向右遍历,最后一个值不满足c=5这个等值条件,因此退化成间隙锁(5,10)
4.根据原则2,只有访问到的对象才会加锁,这个查询使用覆盖索引,并不需要访问主键索引,所以主键索引上没有任何锁,这就是为什么sessionB的update语句可以执行完成
锁是加在索引上的,在这个例子中,lock in share mode只锁覆盖索引,但是如果是for update,系统会认为你接下来要更新数据,因此会顺便给主键索引上满足条件的行加上行锁,这样的话sessionB的update语句会被阻塞住。如果你要用 lock in share mode 来给行加读锁避免数据被更新的话,就必须得绕过覆盖索引的优化,在查询字段中加入索引中不存在的字段
4、案例三:主键索引范围锁

1.开始执行的时候,要找到第一个id=10的行,因此本该是next-key lock(5,10]。根据优化1,主键id上的等值条件,退化成行锁,只加了id=10这一行的行锁
2.范围查询就往后继续找,找到id=15这一行停下来,因此需要加next-key lock(10,15]
所以,sessionA这时候锁的范围就是主键索引上,行锁id=10和next-key lock(10,15]
5、案例四:非唯一索引范围锁
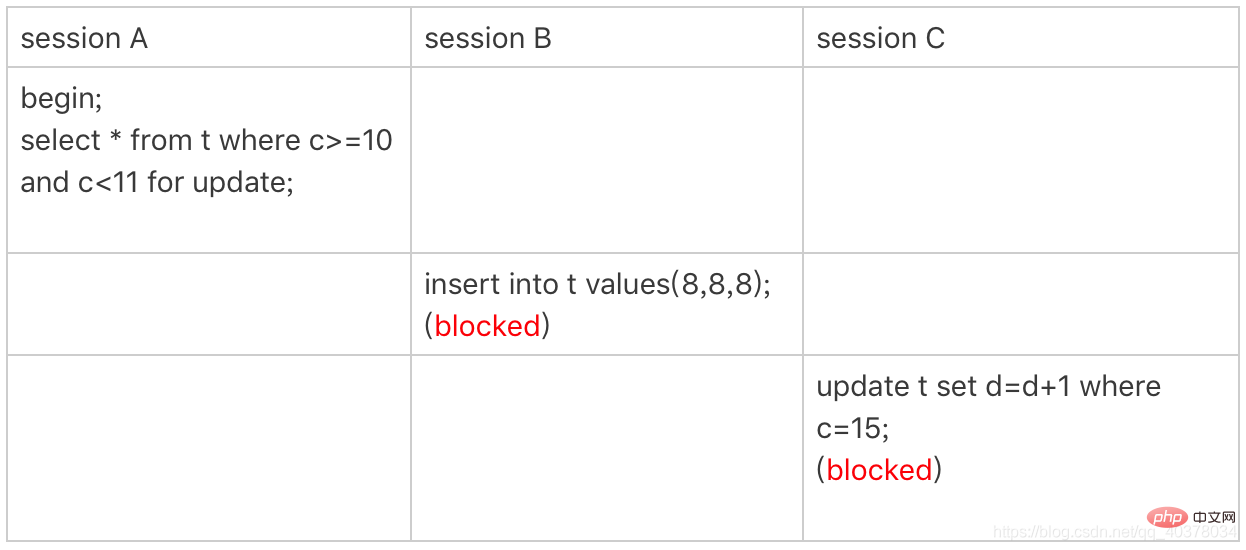
这次sessionA用字段c来判断,加锁规则跟案例三唯一的不同是:在第一次用c=10定位记录的时候,索引c上加上(5,10]这个next-key lock后,由于索引c是非唯一索引,没有优化规则,因此最终sessionA加的锁是索引c上的(5,10]和(10,15]这两个next-key lock
6、案例五:唯一索引范围锁bug
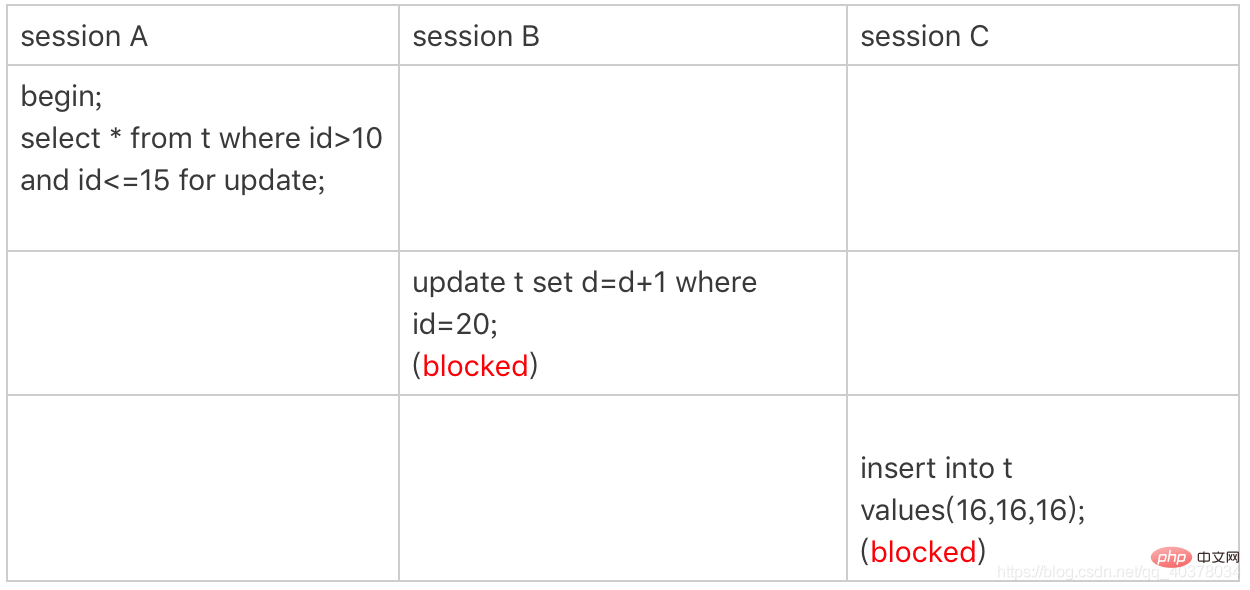
sessionA是一个范围查询,按照原则1的话,应该是索引id上只加(10,15]这个next-key lock,并且因为id是唯一键,所以循环判断到id=15这一行就应该停止了
但是实现上,InnoDB会扫描到第一个不满足条件的行为止,也就是id=20。而且由于这是个范围扫描,因此索引id上的(15,20]这个next-key lock也会被锁上
所以,sessionB要更新id=20这一行是会被锁住的。同样地,sessionC要插入id=16的一行,也会被锁住
7、案例六:非唯一索引上存在等值的例子
insert into t values(30,10,30);
新插入的这一行c=10,现在表里有两个c=10的行。虽然有两个c=10,但是它们的主键值id是不同的,因此这两个c=10的记录之间也是有间隙的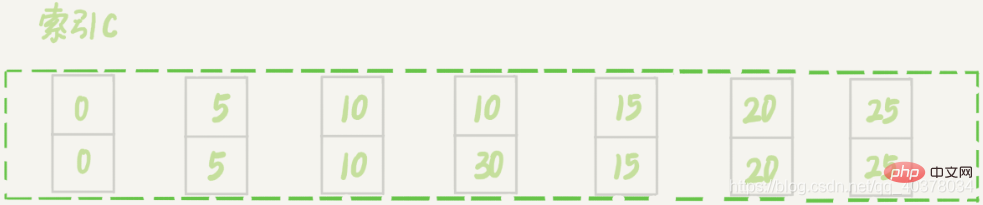
sessionA在遍历的时候,先访问第一个c=10的记录。根据原则1,这里加的是(c=5,id=5)到(c=10,id=10)这个next-key lock。然后sessionA向右查找,直到碰到(c=15,id=15)这一行,循环才结束。根据优化2,这是一个等值查询,向右查找到了不满足条件的行,所以会退化成(c=10,id=10)到(c=15,id=15)的间隙锁
也就是说,这个delete语句在索引c上的加锁范围,就是下图中蓝色区域覆盖的部分,这个蓝色区域左右两边都是虚线,表示开区间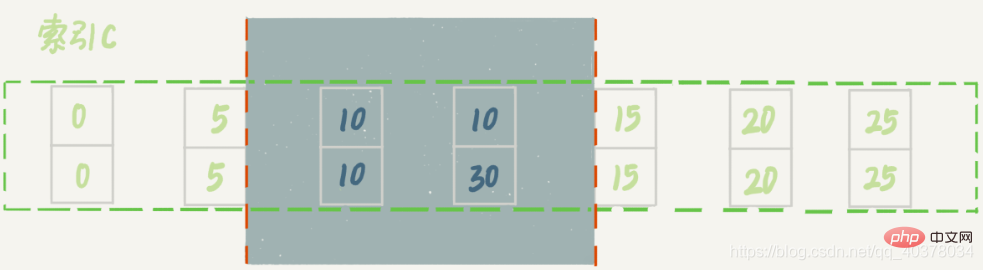
8、案例七:limit语句加锁

加了limit 2的限制,因此在遍历到(c=10,id=30)这一行之后,满足条件的语句已经有两条,循环就结束了。因此,索引c上的加锁范围就变成了从(c=5,id=5)到(c=10,id=30)这个前开后闭区间,如下图所示:
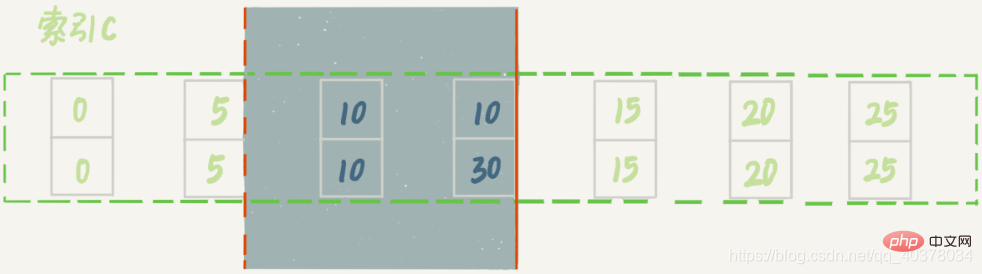
再删除数据的时候尽量加limit,这样不仅可以控制删除数据的条数,让操作更安全,还可以减小加锁的范围
9、案例八:一个死锁的例子

1.sessionA启动事务后执行查询语句加lock in share mode,在索引c上加了next-key lock(5,10]和间隙锁(10,15)
2.sessionB的update语句也要在索引c上加next-key lock(5,10],进入锁等待
3.然后sessionA要再插入(8,8,8)这一行,被sessionB的间隙锁锁住。由于出现了死锁,InnoDB让sessionB回滚
sessionB的加next-key lock(5,10]操作,实际上分成了两步,先是加(5,10)间隙锁,加锁成功;然后加c=10的行锁,这时候才被锁住的
七、用动态的观点看加锁
表t的建表语句和初始化语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(0,0,0),(5,5,5), (10,10,10),(15,15,15),(20,20,20),(25,25,25);
1、不等号条件里的等值查询
begin; select * from t where id>9 and id<12 order by id desc for update;
利用上面的加锁规则,这个语句的加锁范围是主键索引上的(0,5]、(5,10]和(10,15)。加锁单位是next-key lock,这里用到了优化2,即索引上的等值查询,向右遍历的时候id=15不满足条件,所以next-key lock退化为了间隙锁(10,15)

1.首先这个查询语句的语义是order by id desc,要拿到满足条件的所有行,优化器必须先找到第一个id
2.这个过程是通过索引树的搜索过程得到的,在引擎内部,其实是要找到id=12的这个值,只是最终没找到,但找到了(10,15)这个间隙
3.然后根据order by id desc,再向左遍历,在遍历过程中,就不是等值查询了,会扫描到id=5这一行,所以会加一个next-key lock (0,5]
在执行过程中,通过树搜索的方式定位记录的时候,用的是等值查询的方法
2、等值查询的过程
begin; select id from t where c in(5,20,10) lock in share mode;

这条in语句使用了索引c并且rows=3,说明这三个值都是通过B+树搜索定位的
在查找c=5的时候,先锁住了(0,5]。但是因为c不是唯一索引,为了确认还有没有别的记录c=5,就要向右遍历,找到c=10确认没有了,这个过程满足优化2,所以加了间隙锁(5,10)。执行c=10会这个逻辑的时候,加锁的范围是(5,10]和(10,15),执行c=20这个逻辑的时候,加锁的范围是(15,20]和(20,25)
这条语句在索引c上加的三个记录锁的顺序是:先加c=5的记录锁,再加c=10的记录锁,最后加c=20的记录锁
select id from t where c in(5,20,10) order by c desc for update;
由于语句里面是order by c desc,这三个记录锁的加锁顺序是先锁c=20,然后c=10,最后是c=5。这两条语句要加锁相同的资源,但是加锁顺序相反。当这两条语句并发执行的时候,就可能出现死锁
八、insert语句的锁为什么这么多?
1、insert … select语句
表t和t2的表结构、初始化数据语句如下:
CREATE TABLE `t` ( `id` int(11) NOT NULL AUTO_INCREMENT, `c` int(11) DEFAULT NULL, `d` int(11) DEFAULT NULL, PRIMARY KEY (`id`), UNIQUE KEY `c` (`c`) ) ENGINE=InnoDB; insert into t values(null, 1,1); insert into t values(null, 2,2); insert into t values(null, 3,3); insert into t values(null, 4,4); create table t2 like t;
在可重复读隔离级别下,binlog_format=statement时执行下面这个语句时,需要对表t的所有行和间隙加锁
insert into t2(c,d) select c,d from t;
2、insert循环写入
要往表t2中插入一行数据,这一行的c值是表t中c值的最大值加1,SQL语句如下:
insert into t2(c,d) (select c+1, d from t force index(c) order by c desc limit 1);
这个语句的加锁范围,就是表t索引c上的(3,4]和(4,supermum]这两个next-key lock,以及主键索引上id=4这一行
执行流程是从表t中按照索引c倒序吗,扫描第一行,拿到结果写入到表t2中,因此整条语句的扫描行数是1
但如果要把这一行的数据插入到表t中的话:
insert into t(c,d) (select c+1, d from t force index(c) order by c desc limit 1);

explain结果中的Extra字段中Using temporary字段,表示这个语句用到了临时表
执行流程如下:
1.创建临时表,表里有两个字段c和d
2.按照索引c扫描表t,依次取c=4、3、2、1,然后回表,读到c和d的值写入临时表
3.由于语义里面有limit 1,所以只取了临时表的第一行,再插入到表t中
这个语句会导致在表t上做全表扫描,并且会给索引c上的所有间隙都加上共享的next-key lock。所以,这个语句执行期间,其他事务不能在这个表上插入数据
需要临时表是因为这类一边遍历数据,一边更新数据的情况,如果读出来的数据直接写回原表,就可能在遍历过程中,读到刚刚插入的记录,新插入的记录如果参与计算逻辑,就跟语义不符
3、insert唯一键冲突

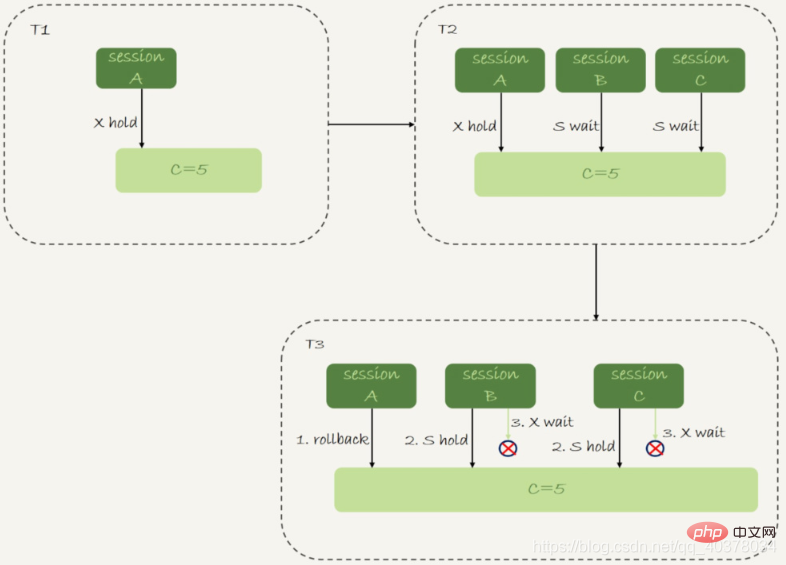
sessionA执行的insert语句,发生唯一键冲突的时候,并不只是简单地报错返回,还在冲突的索引上加了锁,sessionA持有索引c上的(5,10]共享next-key lock(读锁)

在sessionA执行rollback语句回滚的时候,sessionC几乎同时发现死锁并返回
1.在T1时刻,启动sessionA,并执行insert语句,此时在索引c的c=5上加了记录锁。这个索引是唯一索引,因此退化为记录锁
2.在T2时刻,sessionA回滚。这时候,sessionB和sessionC都试图继续执行插入操作,都要加上写锁。两个session都要等待对方的行锁,所以就出现了死锁
4、insert into … on duplicate key update
上面这个例子是主键冲突后直接报错,如果改写成
insert into t values(11,10,10) on duplicate key update d=100;
就会给索引c上(5,10]加一个排他的next-key lock(写锁)
insert into … on duplicate key update的语义逻辑是,插入一行数据,如果碰到唯一键约束,就继续执行后面的更新语句。如果有多个列违反了唯一性索引,就会按照索引的顺序,修改跟第一个索引冲突的行
表t里面已经有了(1,1,1)和(2,2,2)这两行,执行这个语句效果如下:
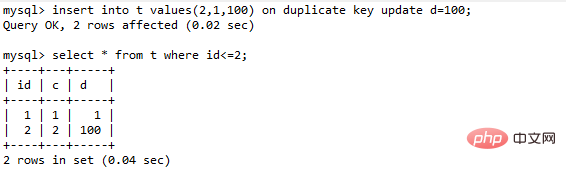
主键id是先判断的,MySQL认为这个语句跟id=2这一行冲突,所以修改的是id=2的行
思考题:
1、如果要删除一个表里面的前10000行数据,有以下三种方法可以做到:
- 第一种,直接执行
delete from T limit 10000; - 第二种,在一个连接中循环执行20次
delete from T limit 500; - 第三种,在20个连接中同时执行
delete from T limit 500;
选择哪一种方式比较好?
参考答案:
第一种方式,单个语句占用时间长,锁的时间也比较长,而且大事务还会导致主从延迟
第三种方式,会人为造成锁冲突
第二种方式相对较好
更多编程相关知识,请访问:编程入门!!
The above is the detailed content of In-depth understanding of locks in MySQL (global locks, table-level locks, row locks). For more information, please follow other related articles on the PHP Chinese website!