
Home >Database >Mysql Tutorial >What are MySQL architectural components
What are MySQL architectural components

- 醉折花枝作酒筹forward
- 2021-05-17 09:41:592075browse
This article will introduce you to the MySQL architecture components. It has certain reference value. Friends in need can refer to it. I hope it will be helpful to everyone.

Overall architecture
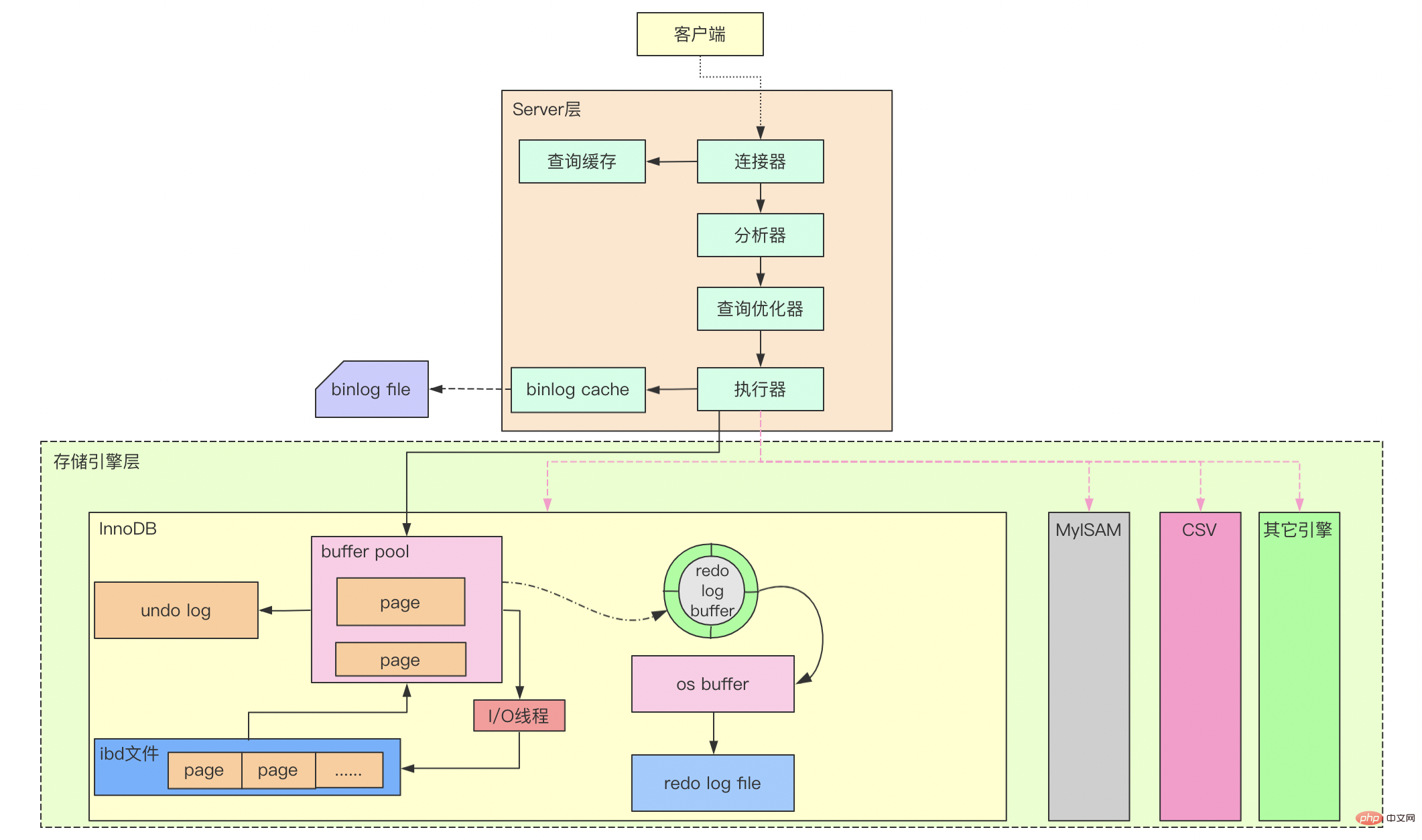
1. Connector
The connector is mainly responsible for establishing the connection with the client. For connections, permission verification and management connections, you can use the command show processlist to view connection information. When a user connection is successfully created, the permission information has been read into the memory. If the user's permissions are modified later, it will not take effect if it is not refreshed.
For a connection, if no instructions are received for a long time (it is in an idle state), the connector will disconnect the link after a certain period of time. This time is controlled by the parameter wait_timeout, which defaults to 8 hours.
The connections in the connector are divided into long connections and short connections:
Long connections: After the connection is successful, the client requests to use the same connection
- Short connection: The connection will be disconnected after each request is executed, and the connection will be re-established if there is another request.
Because in normal times, we generally want to avoid the overhead of frequently repeatedly creating connections. The long connection used means that a connection is maintained for a long time without being disconnected. However, it should be noted that a connection manages some memory occupied by it during use, and will be released along with the connection when the connection is disconnected. If the connection is not disconnected and continues to accumulate without processing for a long time, it may cause excessive memory usage and be forcibly killed by the system. There are generally two solutions:
Disconnect long connections regularly, and disconnect after a period of time or after executing a query that takes up a lot of memory, thereby freeing up memory when a query is needed. When the time comes, re-create the connection
Versions after 5.7 can use mysql_reset_connection to reinitialize the connection resources without reconnection and permission verification, and restore the connection to the state when it was created. At the same time, there will also be some other effects, such as releasing table locks, clearing temporary tables, resetting variables set in the session, etc.
2. Query cache
Note: Query cache was abolished after version 8.0
After the connection is successfully created, the SQL statement can be executed. However, if the query cache is turned on, the query will be queried from the cache before the SQL is actually analyzed. If the cache hits, it will be returned directly. . The query cache is a Key-Value structure, where Key is the SQL statement and Value is the corresponding query result. If the cache misses, subsequent query operations will continue. After the query is completed, the results will be stored in the query cache.
Why is the query cache deleted? Because query caching usually does more harm than good. If a table is updated, the query cache corresponding to the table will be cleared. For frequently updated tables, the query cache will be invalidated very frequently, basically ineffective, and there is also the overhead of updating the cache. For data tables that will basically remain unchanged, you can choose to use query caching, such as system configuration tables. The cache hit rate of such tables will be higher, and the advantages may outweigh the disadvantages. However, for this configuration, We can also use external caching.
The query cache can be configured through the parameter query_cache_type. This parameter has 3 optional values, which are:
- # 0: Turn off the query cache
- 1: Turn on query cache
- 2: Use query cache when there is SQL_CACHE keyword in SQL, such as select SQL_CACHE * from t where xxx;
- 3. Analyzer
If the query cache does not hit, then the SQL needs to be actually executed, and the SQL needs to be parsed before execution. This parsing is mainly divided into lexical analysis and syntax analysis. Two steps.
- Lexical analysis: Extract keywords from SQL, such as select, from, table name, field name, etc.
- Grammatical analysis: According to The results of lexical analysis and some grammar rules defined by MySQL check whether the SQL grammar is legal, and eventually an abstract syntax tree (AST) will be generated
- 4. Optimizer
The optimizer takes the AST generated by the analyzer as input, optimizes the SQL, generates what the optimizer considers to be the optimal execution plan, and hands it to the executor for execution. The optimization process includes logical transformation of SQL and cost calculation.
Logical conversion is similar to Java's static compile-time optimization, which will "simplify" SQL to ensure consistent execution results before and after SQL conversion. For example, where 1=1 and a.id = 2 can be equivalent to where a.id = 2.
The main purpose of cost calculation is to choose the way to execute SQL, including whether to use indexes, which index to use, what order to use for multi-table connections, etc. The cost is divided into service layer cost and engine layer cost. The service layer cost is mainly related to CPU, and the engine layer cost is mainly related to disk I/O. MySQL 5.7 introduces two system tables mysql.server_cost and mysql.engine_cost to configure these two costs. What is configured in the table is the cost corresponding to various operations, such as temporary table creation, sorting, page reading, etc.
The optimizer will calculate the final cost of a query plan based on the generated query plan and the above two cost configurations, and select the one with the smallest cost among multiple query plans to the executor for execution. However, it should be noted that the smallest cost sometimes does not necessarily mean the shortest execution time.
5. Executor
The executor will execute SQL according to the query plan selected by the optimizer. Before execution, it will also verify whether the requesting user has the corresponding query permissions, and finally call the MySQL engine layer Provides an interface to execute SQL statements and return results. If query caching is enabled, the results will also be stored in the query cache.
Related recommendations: "mysql tutorial"
The above is the detailed content of What are MySQL architectural components. For more information, please follow other related articles on the PHP Chinese website!