
Home >Web Front-end >JS Tutorial >Learn more about the event loop mechanism in Nodejs
Learn more about the event loop mechanism in Nodejs

- 青灯夜游forward
- 2021-01-05 17:40:042503browse
This article will take you to understand the nodejs event loop mechanism. It has certain reference value. Friends in need can refer to it. I hope it will be helpful to everyone.

Related recommendations: "nodejs Tutorial"
Node.js uses event-driven and asynchronous I/O to achieve A single-threaded, high-concurrency JavaScript runtime environment, and single-threading means that only one thing can be done at the same time. So how does Node.js achieve high concurrency and asynchronous I/O through single-threading? This article will focus on this issue to discuss the single-threaded model of Node.js.
High concurrency strategy
Generally speaking, the solution to high concurrency is to provide a multi-threading model. The server allocates a thread for each client request and uses synchronization I /O, the system uses thread switching to make up for the time overhead of synchronous I/O calls. For example, Apache has this strategy. Since I/O is generally a time-consuming operation, this strategy is difficult to achieve high performance, but it is very simple and can implement complex interaction logic.
In fact, the server side of most websites does not do too much calculation. After receiving the request, they hand over the request to other services for processing (such as reading the database), and then wait for the result. Return, and finally send the result to the client. Therefore, Node.js adopts a single-threaded model to deal with this fact. It does not allocate a thread for each access request. Instead, it uses a main thread to process all requests, and then processes the I/O operations asynchronously. , avoiding the overhead and complexity required to create, destroy, and switch between threads.
Event loop
Node.js maintains an event queue in the main thread. When a request is received, the request is treated as An event is placed into this queue and continues to receive other requests. When the main thread is idle (when there is no request for access), it starts to circulate the event queue and check whether there are events to be processed in the queue. There are two situations: if it is a non-I/O task, handle it personally and call it back. The function returns to the upper layer call; if it is an I/O task, take out a thread from the thread pool to handle the event, specify the callback function, and then continue to cycle other events in the queue.
When the I/O task in the thread is completed, the specified callback function is executed, and the completed event is placed at the end of the event queue, waiting for the event loop. When the main thread loops to the event again, It is processed directly and returned to the upper layer call. This process is called Event Loop (Event Loop), and its operating principle is shown in the following figure:
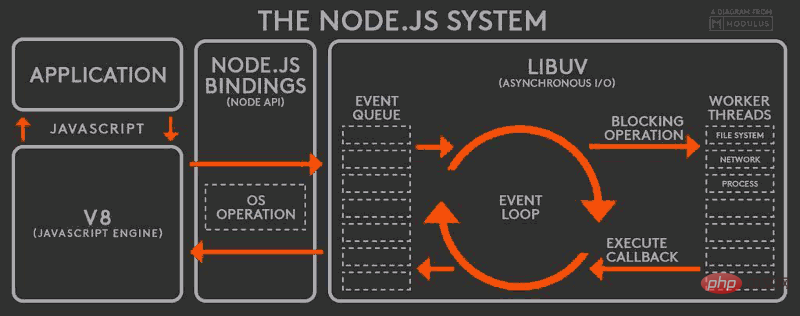
This figure is the operating principle of the entire Node.js , from left to right, from top to bottom, Node.js is divided into four layers, namely Application layer, V8 engine layer, Node API layer and LIBUV layer.
Application layer: That is, the JavaScript interaction layer. The most common ones are Node.js modules, such as http, fs
V8 engine layer: That is, using the V8 engine to parse JavaScript syntax, and then interact with the lower API
NodeAPI layer: Provides system calls for the upper module, usually implemented in C language, to interact with the operating system.
LIBUV layer: It is a cross-platform bottom-level encapsulation that implements event loops, file operations, etc., and is the core of Node.js's asynchronous implementation.
Whether it is a Linux platform or a Windows platform, Node.js internally completes asynchronous I/O operations through thread pool , and LIBUV is implemented differently for different platforms unified call. Therefore, the single thread of Node.js only means that JavaScript runs in a single thread, not that Node.js is single threaded.
Working Principle
The core of Node.js’ asynchronous implementation is events, that is to say, it treats each task as an event , and then processes it through Event Loop simulates the asynchronous effect. In order to understand and accept this fact more specifically and clearly, let's use pseudo code to describe its working principle.
[1] Define event queue
Since it is a queue, it is a first-in-first-out (FIFO) data structure. We use a JS array to describe it, as follows:
/** * 定义事件队列 * 入队:push() * 出队:shift() * 空队列:length == 0 */ globalEventQueue: []
We use arrays to simulate the queue structure: the first element of the array is the head of the queue, the last element of the array is the tail of the queue, push() is to insert an element at the tail of the queue, shift( ) is to pop an element from the head of the queue. This implements a simple event queue.
【2】DefinitionReceive request entry
Each request will be intercepted and entered into the processing function, as shown below:
/**
* 接收用户请求
* 每一个请求都会进入到该函数
* 传递参数request和response
*/
processHttpRequest:function(request,response){
// 定义一个事件对象
var event = createEvent({
params:request.params, // 传递请求参数
result:null, // 存放请求结果
callback:function(){} // 指定回调函数
});
// 在队列的尾部添加该事件
globalEventQueue.push(event);
}这个函数很简单,就是把用户的请求包装成事件,放到队列里,然后继续接收其他请求。
【3】定义 Event Loop
当主线程处于空闲时就开始循环事件队列,所以我们还要定义一个函数来循环事件队列:
/**
* 事件循环主体,主线程择机执行
* 循环遍历事件队列
* 处理非IO任务
* 处理IO任务
* 执行回调,返回给上层
*/
eventLoop:function(){
// 如果队列不为空,就继续循环
while(this.globalEventQueue.length > 0){
// 从队列的头部拿出一个事件
var event = this.globalEventQueue.shift();
// 如果是耗时任务
if(isIOTask(event)){
// 从线程池里拿出一个线程
var thread = getThreadFromThreadPool();
// 交给线程处理
thread.handleIOTask(event)
}else {
// 非耗时任务处理后,直接返回结果
var result = handleEvent(event);
// 最终通过回调函数返回给V8,再由V8返回给应用程序
event.callback.call(null,result);
}
}
}主线程不停的检测事件队列,对于 I/O 任务,就交给线程池来处理,非 I/O 任务就自己处理并返回。
【4】处理 I/O 任务
线程池接到任务以后,直接处理IO操作,比如读取数据库:
/**
* 处理IO任务
* 完成后将事件添加到队列尾部
* 释放线程
*/
handleIOTask:function(event){
//当前线程
var curThread = this;
// 操作数据库
var optDatabase = function(params,callback){
var result = readDataFromDb(params);
callback.call(null,result)
};
// 执行IO任务
optDatabase(event.params,function(result){
// 返回结果存入事件对象中
event.result = result;
// IO完成后,将不再是耗时任务
event.isIOTask = false;
// 将该事件重新添加到队列的尾部
this.globalEventQueue.push(event);
// 释放当前线程
releaseThread(curThread)
})
}当 I/O 任务完成以后就执行回调,把请求结果存入事件中,并将该事件重新放入队列中,等待循环,最后释放当前线程,当主线程再次循环到该事件时,就直接处理了。
总结以上过程我们发现,Node.js 只用了一个主线程来接收请求,但它接收请求以后并没有直接做处理,而是放到了事件队列中,然后又去接收其他请求了,空闲的时候,再通过 Event Loop 来处理这些事件,从而实现了异步效果,当然对于IO类任务还需要依赖于系统层面的线程池来处理。
因此,我们可以简单的理解为:Node.js 本身是一个多线程平台,而它对 JavaScript 层面的任务处理是单线程的。
CPU密集型是短板
至此,对于 Node.js 的单线程模型,我们应该有了一个简单而又清晰的认识,它通过事件驱动模型实现了高并发和异步 I/O,然而也有 Node.js 不擅长做的事情:
上面提到,如果是 I/O 任务,Node.js 就把任务交给线程池来异步处理,高效简单,因此 Node.js 适合处理I/O密集型任务。但不是所有的任务都是 I/O 密集型任务,当碰到CPU密集型任务时,即只用CPU计算的操作,比如要对数据加解密(node.bcrypt.js),数据压缩和解压(node-tar),这时 Node.js 就会亲自处理,一个一个的计算,前面的任务没有执行完,后面的任务就只能干等着 。如下图所示:
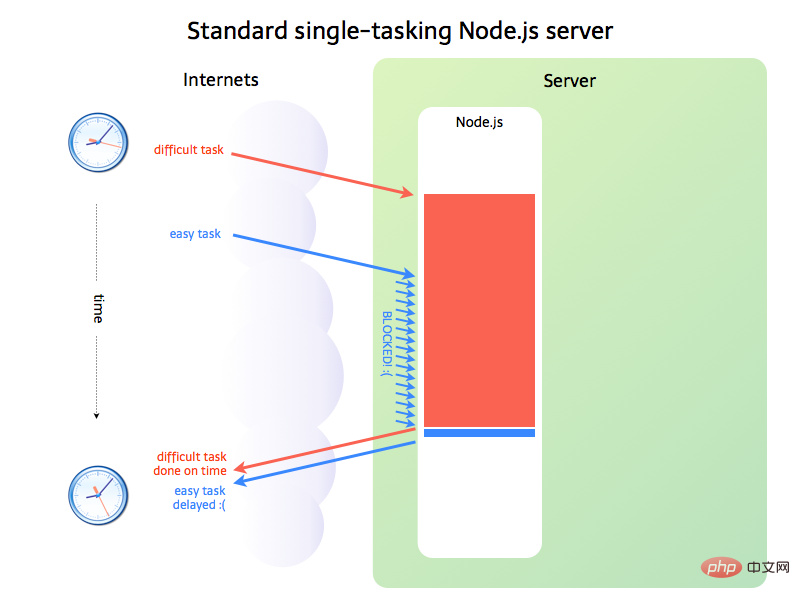
在事件队列中,如果前面的 CPU 计算任务没有完成,后面的任务就会被阻塞,出现响应缓慢的情况,如果操作系统本身就是单核,那也就算了,但现在大部分服务器都是多 CPU 或多核的,而 Node.js 只有一个 EventLoop,也就是只占用一个 CPU 内核,当 Node.js 被CPU 密集型任务占用,导致其他任务被阻塞时,却还有 CPU 内核处于闲置状态,造成资源浪费。
因此,Node.js 并不适合 CPU 密集型任务。
适用场景
RESTful API - 请求和响应只需少量文本,并且不需要大量逻辑处理, 因此可以并发处理数万条连接。
聊天服务 - 轻量级、高流量,没有复杂的计算逻辑。
更多编程相关知识,请访问:编程教学!!
The above is the detailed content of Learn more about the event loop mechanism in Nodejs. For more information, please follow other related articles on the PHP Chinese website!