
Home >Database >Mysql Tutorial >Summary of database transactions and MySQL transactions
Summary of database transactions and MySQL transactions

- coldplay.xixiforward
- 2020-12-30 16:33:522630browse
mysql tutorialSummary of database transactions and MySQL transactions

Recommended (free): mysql tutorial
Transaction features: ACID
From a business perspective, for A set of database operations is required to maintain 4 characteristics:
- Atomicity: A transaction must be regarded as an indivisible minimum unit of work, and all operations in the entire transaction must be submitted successfully. , or all fail and roll back. For a transaction, it is impossible to perform only part of the operations.
- Consistency: The database always transitions from one consistency state to another. The following bank examples will be mentioned.
- Isolation: Generally speaking, modifications made by one transaction are not visible to other transactions before they are finally committed. Note the "generally speaking" here, which will be discussed later in the transaction isolation level.
- Durability: Once a transaction is committed, its modifications will be permanently saved in the database. Even if the system crashes at this time, the modified data will not be lost. (There is also a certain relationship between persistence security and refresh log level. Different levels correspond to different data security levels.)
In order to better understand ACID, take bank account transfer as an example:
START TRANSACTION;SELECT balance FROM checking WHERE customer_id = 10233276;UPDATE checking SET balance = balance - 200.00 WHERE customer_id = 10233276;UPDATE savings SET balance = balance + 200.00 WHERE customer_id = 10233276;COMMIT;
- Atomicity: Either fully commit (the checking balance of 10233276 is reduced by 200, and the balance of savings is increased by 200), or completely rolled back (the balances of both tables do not change)
- Consistency: The consistency of this example is reflected in the fact that the 200 yuan will not disappear because the database system crashes after running to the 3rd line and before the 4th line, because the transaction has not yet been committed.
- Isolation: Allow operation statements in one transaction to be isolated from statements in other transactions. For example, transaction A runs after line 3 and before line 4, and transaction B queries the checking balance at this time. , it can still see the 200 yuan that was subtracted in transaction A (the account money remains unchanged), because transactions A and B are isolated from each other. Before transaction A commits, transaction B cannot observe the data changes.
- Persistence: This is easy to understand.
- The isolation of transactions is achieved through locks, MVCC, etc. (MySQL lock summary)
- The atomicity, consistency and durability of transactions are achieved through transaction logs (see below)
Transaction isolation level
Problems caused by concurrent transactions
- Lost Update: When two or more transactions select the same row and then update the row based on the originally selected value, since each transaction is not aware of the existence of the other transactions, an error occurs. A lost update problem occurs - the last update overwrites updates made by other transactions. For example, two editors make electronic copies of the same document. Each editor independently changes their copy and then saves the changed copy, overwriting the original document. The editor who last saved a copy of his or her changes overwrites the changes made by another editor. This problem can be avoided if one editor cannot access the same file until another editor completes and commits the transaction.
- Dirty Reads: A transaction is modifying a record. Before the transaction is completed and committed, the data of this record is in an inconsistent state; at this time, another transaction also reads it. If the same record is not controlled and a second transaction reads the "dirty" data and performs further processing based on it, uncommitted data dependencies will occur. This phenomenon is vividly called "dirty reading".
- Non-Repeatable Reads: A transaction reads the previously read data again at some time after reading some data, only to find that the data it read has changed. , or some records have been deleted! This phenomenon is called "non-repeatable reading".
- Phantom Reads: A transaction re-reads previously retrieved data according to the same query conditions, only to find that other transactions have inserted new data that satisfies its query conditions. This phenomenon is called " Phantom reading".
The difference between phantom reading and non-repeatable reading:
- The focus of non-repeatable reading is modification: in the same transaction, under the same conditions, the data read for the first time is different from the data read for the second time. (Because other transactions submitted modifications in the middle)
- The focus of phantom reading is to add or delete: in the same transaction, under the same conditions, the number of records read out for the first and second times is different. . (Because there are other transactions committing insertion/deletion in the middle)
Solutions to problems caused by concurrent transaction processing:
"Lost updates" are generally something that should be avoided altogether. However, preventing update loss cannot be solved by the database transaction controller alone. The application needs to add necessary locks to the data to be updated. Therefore, preventing update loss should be the responsibility of the application.
"Dirty read", "non-repeatable read" and "phantom read" are actually database read consistency problems, which must be solved by the database providing a certain transaction isolation mechanism:
One is locking: lock the data before reading it to prevent other transactions from modifying the data.
The other is data multi-version concurrency control (MultiVersion Concurrency Control, referred to as MVCC or MCC), also known as multi-version database: without adding any locks, a data is generated through a certain mechanism Request a consistent data snapshot (Snapshot) at a point in time, and use this snapshot to provide a certain level (statement level or transaction level) of consistent reads. From the user's perspective, it seems that the database can provide multiple versions of the same data.
The SQL standard defines four types of isolation levels. Each level specifies the modifications made in a transaction, which ones are visible within and between transactions, and which ones are not. visible. Lower isolation levels generally support higher concurrency and have lower system overhead.
Level 1: Read Uncommitted(read uncommitted content)
- All transactions can see other uncommitted transactions Execution results
- This isolation level is rarely used in actual applications because its performance is not much better than other levels
- The problem caused by this level is - Dirty Read: Uncommitted data was read
Level 2: Read Committed
This is the default isolation level for most database systems (but not the MySQL default)
It meets the simple definition of isolation: a transaction can only see what has been committed by the transaction The problem with changing
this isolation level is - Nonrepeatable Read: Nonrepeatable Read means that when we execute the exact same select statement in the same transaction, it is possible See different results. The possible reasons for this situation are:
There is a cross transaction with a new commit, which leads to data changes;
a When the database is operated by multiple instances, other instances of the same transaction may have new commits during the processing of the instance
##Level 3: Repeatable Read (rereadable)
- This is MySQL's default transaction isolation level
- It ensures that multiple instances of the same transaction will see the same message when reading data concurrently. Data rows
- Possible problems at this level - Phantom Read: When the user reads a certain range of data rows, another transaction inserts a new row in the range. When When users read data rows in this range, they will find new "phantom" rows
- InnoDB and Falcon storage engines solve the phantom reading problem through the multi-version concurrency control (MVCC, Multiversion Concurrency Control) mechanism; InnoDB The phantom read problem is also solved through gap locks
##Multi-version concurrency control:Most transactional storage engine implementations of Mysql Not a simple row-level lock. Based on the consideration of improving concurrency, multi-version concurrency control (MVCC) is generally implemented at the same time, including Oracle and PostgreSQL. However implementations vary.
MVCC is implemented by saving a snapshot of data at a certain point in time. In other words, no matter how long it takes to implement, the data seen by each thing is consistent.
It is divided into optimistic concurrency control and pessimistic concurrency control.
How MVCC works: InnoDB's MVCC is implemented by saving two hidden columns behind each row of records. One of these two columns stores the creation time of the row, and the other stores the expiration time (deletion time) of the row. Of course, what is stored is not the real time but the system version number. Every time a new transaction is started, the system version number will be automatically added. The system version number at the start of the transaction will be used as the version number of the transaction, which is used to query the version number of each row of records for comparison.
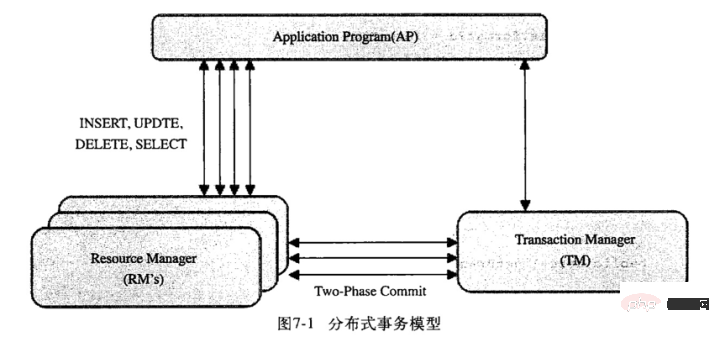
How MVCC works under the REPEATABLE READ isolation level:#InnoDB will check each row of records according to the following conditions: Only those that meet the above two conditions will be queried InnoDB saves the current system version number as the row version number for each newly inserted row InnoDB saves the current system version number as the row deletion for each deleted row Identification InnoDB saves the current system version number as the row version number for a new row inserted, and also saves the current system version number to the original row as the deletion identifier. Save these two version numbers so that most operations do not require locking. It makes data operations simple, performs well, and ensures that only rows required by complex requirements are read. The disadvantages are that each row of records requires additional storage space, more row checking and some additional maintenance work. MVCC only works under two isolation levels: COMMITTED READ (read submission) and REPEATABLE READ (repeatable read). It can be considered that MVCC is a variant of row-level locking, but it avoids locking operations in many cases and has lower overhead. Although the implementation mechanisms of different databases are different, most of them implement non-blocking read operations (no locking is required for reading, and non-repeatable reads and phantom reads can be avoided), and write operations only lock necessary rows (writing must be locked) , otherwise concurrent writing by different transactions will lead to data inconsistency). Level 4: Serializable Isolation level comparison Each specific database may not fully implement the above four isolation levels. For example: Oracle only provides two standards: Read committed and Serializable Isolation level, in addition to providing self-defined Read only isolation level; In addition to supporting the above four isolation levels defined by ISO/ANSI SQL92, SQL Server also supports one called "snapshot" isolation level, but strictly speaking it is a Serializable isolation level implemented using MVCC. MySQL supports all 4 isolation levels, but in specific implementation, there are some characteristics. For example, in some isolation levels, MVCC consistent reading is used, but in some cases it is not. . Mysql can set the isolation level by executing the set transaction isolation level command. The new isolation level will take effect when the next transaction starts. For example: set session transaction isolation level read committed; Transaction log Transaction log can help improve transaction efficiency: Currently, most storage engines are implemented in this way. We usually call it write-ahead logging (Write-Ahead Logging). Modifying data requires writing to the disk twice. Transaction implementation principle in Mysql The implementation of transactions is based on the storage engine of the database. Different storage engines have different levels of support for transactions. The storage engines that support transactions in mysql include innoDB and NDB. innoDB is the default storage engine of mysql. The default isolation level is RR (Repeatable Read), and it goes one step further under the isolation level of RR, through multi-version Concurrency control (MVCC, Multiversion Concurrency Control) solves the non-repeatable read problem, and gap lock (that is, concurrency control) solves the phantom read problem. Therefore, innoDB's RR isolation level actually achieves the effect of serialization level and retains relatively good concurrency performance. 事务的隔离性是通过锁实现,而事务的原子性、一致性和持久性则是通过事务日志实现。说到事务日志,不得不说的就是redo和undo。 1.redo log 在innoDB的存储引擎中,事务日志通过重做(redo)日志和innoDB存储引擎的日志缓冲(InnoDB Log Buffer)实现。事务开启时,事务中的操作,都会先写入存储引擎的日志缓冲中,在事务提交之前,这些缓冲的日志都需要提前刷新到磁盘上持久化,这就是DBA们口中常说的“日志先行”(Write-Ahead Logging)。当事务提交之后,在Buffer Pool中映射的数据文件才会慢慢刷新到磁盘。此时如果数据库崩溃或者宕机,那么当系统重启进行恢复时,就可以根据redo log中记录的日志,把数据库恢复到崩溃前的一个状态。未完成的事务,可以继续提交,也可以选择回滚,这基于恢复的策略而定。 在系统启动的时候,就已经为redo log分配了一块连续的存储空间,以顺序追加的方式记录Redo Log,通过顺序IO来改善性能。所有的事务共享redo log的存储空间,它们的Redo Log按语句的执行顺序,依次交替的记录在一起。如下一个简单示例: 记录1: 记录2: 记录3: 记录4: 记录5: 2.undo log undo log主要为事务的回滚服务。在事务执行的过程中,除了记录redo log,还会记录一定量的undo log。undo log记录了数据在每个操作前的状态,如果事务执行过程中需要回滚,就可以根据undo log进行回滚操作。单个事务的回滚,只会回滚当前事务做的操作,并不会影响到其他的事务做的操作。 以下是undo+redo事务的简化过程 假设有2个数值,分别为A和B,值为1,2 1. start transaction; 2. 记录 A=1 到undo log; 3. update A = 3; 4. 记录 A=3 到redo log; 5. 记录 B=2 到undo log; 6. update B = 4; 7. 记录B = 4 到redo log; 8. 将redo log刷新到磁盘 9. commit 在1-8的任意一步系统宕机,事务未提交,该事务就不会对磁盘上的数据做任何影响。如果在8-9之间宕机,恢复之后可以选择回滚,也可以选择继续完成事务提交,因为此时redo log已经持久化。若在9之后系统宕机,内存映射中变更的数据还来不及刷回磁盘,那么系统恢复之后,可以根据redo log把数据刷回磁盘。 所以,redo log其实保障的是事务的持久性和一致性,而undo log则保障了事务的原子性。 Mysql中的事务使用 MySQL的服务层不管理事务,而是由下层的存储引擎实现。比如InnoDB。 MySQL支持本地事务的语句: 事务使用注意点: 自动提交(autocommit): InnoDB在事务执行过程中,使用两阶段锁协议: 随时都可以执行锁定,InnoDB会根据隔离级别在需要的时候自动加锁; 锁只有在执行commit或者rollback的时候才会释放,并且所有的锁都是在同一时刻被释放。 InnoDB也支持通过特定的语句进行显示锁定(存储引擎层): MySQL Server层的显示锁定: (更多阅读:MySQL锁总结) MySQL对分布式事务的支持 分布式事务的实现方式有很多,既可以采用innoDB提供的原生的事务支持,也可以采用消息队列来实现分布式事务的最终一致性。这里我们主要聊一下innoDB对分布式事务的支持。 MySQL 从 5.0.3 开始支持分布式事务,当前分布式事务只支持 InnoDB 存储引擎。一个分布式事务会涉及多个行动,这些行动本身是事务性的。所有行动都必须一起成功完成,或者一起被回滚。 如图,mysql的分布式事务模型。模型中分三块:应用程序(AP)、资源管理器(RM)、事务管理器(TM): 分布式事务采用两段式提交(two-phase commit)的方式: 分布式事务(XA 事务)的 SQL 语法主要包括: 虽然 MySQL 支持分布式事务,但是在测试过程中,还是发现存在一些问题: 如果分支事务在执行到 prepare 状态时,数据库异常,且不能再正常启动,需要使用备份和 binlog 来恢复数据,那么那些在 prepare 状态的分支事务因为并没有记录到 binlog,所以不能通过 binlog 进行恢复,在数据库恢复后,将丢失这部分的数据。 如果分支事务的客户端连接异常中止,那么数据库会自动回滚未完成的分支事务,如果此时分支事务已经执行到 prepare 状态, 那么这个分布式事务的其他分支可能已经成功提交,如果这个分支回滚,可能导致分布式事务的不完整,丢失部分分支事务的内容。

START TRANSACTION | BEGIN [WORK] COMMIT [WORK] [AND [NO] CHAIN] [[NO] RELEASE] ROLLBACK [WORK] [AND [NO] CHAIN] [[NO] RELEASE] SET AUTOCOMMIT = {0 | 1}
tables 被执行。
务类型的表进行特别的处理,因为 COMMIT、ROLLBACK 只能对事务类型的表进行提交和回滚。
不同的 SAVEPOINT。需要注意的是,如果定义了相同名字的 SAVEPOINT,则后面定义的SAVEPOINT 会覆盖之前的定义。对于不再需要使用的 SAVEPOINT,可以通过 RELEASE SAVEPOINT 命令删除 SAVEPOINT, 删除后的 SAVEPOINT, 不能再执行 ROLLBACK TO SAVEPOINT命令。
Mysql默认采用自动提交模式,可以通过设置autocommit变量来启用或禁用自动提交模式select ... lock in share mode //共享锁 select ... for update //排他锁
lock table和unlock table
XA {START|BEGIN} xid [JOIN|RESUME]
如果分支事务在达到 prepare 状态时,数据库异常重新启动,服务器重新启动以后,可以继续对分支事务进行提交或者回滚得操作,但是提交的事务没有写 binlog,存在一定的隐患,可能导致使用 binlog 恢复丢失部分数据。如果存在复制的数据库,则有可能导致主从数据库的数据不一致。
总之, MySQL 的分布式事务还存在比较严重的缺陷, 在数据库或者应用异常的情况下,
可能会导致分布式事务的不完整。如果应用对于数据的完整性要求不是很高,则可以考虑使
用。如果应用对事务的完整性有比较高的要求,那么对于当前的版本,则不推荐使用分布式
事务。
The above is the detailed content of Summary of database transactions and MySQL transactions. For more information, please follow other related articles on the PHP Chinese website!