
Home >Database >Mysql Tutorial >Detailed explanation of common functions of mysql
Detailed explanation of common functions of mysql

- coldplay.xixiforward
- 2020-11-24 16:36:383734browse
mysql video tutorial column introduces common functions of mysql.

Related free learning recommendations: mysql video tutorial
1. Basic part
- 1. Using MySQL
- ##1.1. SELECT statement
- 1.2. Sorting and retrieving data
- 1.3. Filtering data
- 1.4. Data filtering
- 1.5. Use wildcards to filter
- 1.6. Use regular expressions to search
- 1.6.1 Basic character matching
- 1.6.2 Perform OR matching
- 1.6.3 Match one of several characters
- 1.6.4 Match range
- 1.6.5 Match special characters
- 1.6.6 Match character class
- 1.6.7 Match multiple instances
- 1.6.8 Locator
1.7, create Calculated fields
USE user
USE is followed by the database you want to open. If you don’t know the name of the database, use SHOW DATABASES to view it. Use SHOW TABLES to view the tables in a database. Of course, you can also view the columns in the table SHOW user_id FROM user , it returns a row for each field, which contains the field name, data type, whether NULL is allowed, key information, default value and other information (DESCRIBE user is a shortcut for the above statement)
The required column names are given after the SELECT keyword, and the FROM keyword indicates the name of the table from which the data is to be retrieved.
To retrieve multiple columns from a table, use the same SELECT statement. The only difference is that multiple column names must be given after the SELECT keyword, and the column names must be separated by commas.
Use the DISTINCT keyword to retrieve only rows with different values, and duplicates will not be displayed (note: the DISTINCT keyword applies to all columns, not just the columns that precede it)
The SELECT statement returns all matching rows, which may be each row in the specified table. To return the first row or rows, use the LIMIT clause.
LIMIT 5,5 instructs MySQL to return 5 rows starting from row 5. The first number is the starting position, and the second number is the number of rows to be retrieved.
To sort by multiple columns, just specify the column names separated by commas.
Data sorting is not limited to ascending order (from A to Z). This is just the default sort order, you can also sort in descending (Z to A) order using the ORDER BY clause. In order to sort in descending order, the DESC keyword must be specified. (The DESC keyword only applies to the column name directly preceding it)
The AND operator is evaluated in a higher order than the OR operator
1.5、用通配符进行过滤
本章介绍什么是通配符、如何使用通配符以及怎样使用LIKE 操作符进行通配搜索,以便对数据进行复杂过滤。
为在搜索子句中使用通配符,必须使用LIKE 操作符。LIKE 指示MySQL,后跟的搜索模式利用通配符匹配而不是直接相等匹配进行比较。
最常使用的通配符是百分号(% )。在搜索串中,% 表示任何字符出现任意次数 。( 根据MySQL的配置方式,搜索可以是区分大小写的。如果区分大小写)。
另一个有用的通配符是下划线(_ )。下划线的用途与% 一样,但下划线只匹配单个字符而不是多个字符。
正如所见,MySQL的通配符很有用。但这种功能是有代价的:通配符搜索的处理一般要比前面讨论的其他搜索所花时间更长。这里给出一些使用通配符要记住的技巧。
1.不要过度使用通配符。如果其他操作符能达到相同的目的,应该使用其他操作符。
2.在确实需要使用通配符时,除非绝对有必要,否则不要把它们用在搜索模式的开始处。把通配符置于搜索模式的开始处,搜索起来是最慢的。
3.仔细注意通配符的位置。如果放错地方,可能不会返回想要的数据。
1.6、用正则表达式进行搜索
1.6.1 基本字符匹配
我们从一个非常简单的例子开始。下面的语句检索列prod_name 包含文本1000 的所有行:
SELECT prod_name
FROM products
WHERE prod_name REGEXP ‘1000’
ORDER BY prod_name;
它告诉MySQL:REGEXP 后所跟的东西作为正则表达式(与文字正文1000 匹配的一个正则表达式)处理。
SELECT prod_name
FROM products
WHERE prod_name REGEXP ‘.000’
ORDER BY prod_name;
. 是正则表达式语言中一个特殊的字符。它表示匹配任意一个字符 ,因此,1000 和2000 都匹配且返回。
MySQL中的正则表达式匹配(自版本3.23.4后)不区分大小写(即,大写和小写都匹配)。为区分大小写,可使用BINARY 关键字,如WHERE prod_name REGEXP BINARY ‘JetPack .000’ 。
1.6.2 进行OR 匹配
为搜索两个串之一(或者为这个串,或者为另一个串),使用|,如下所示:
SELECT prod_name
FROM products
WHERE prod_name REGEXP ‘1000|2000’
ORDER BY prod_name;
1.6.3 匹配几个字符之一
如果你只想匹配特定的字符,怎么办?可通过指定一组用[和]括起来的字符来完成,如下所示:
SELECT prod_name
FROM products
WHERE prod_name REGEXP ‘[123] Ton’
ORDER BY prod_name;
字符集合也可以被否定,即,它们将匹配除指定字符外的任何东西。为否定一个字符集,在集合的开始处放置一个^即可。因此,尽管[123] 匹配字符1 、2 或3 ,但[^123] 却匹配除这些字符外的任何东西。
1.6.4 匹配范围
SELECT prod_name
FROM products
WHERE prod_name REGEXP ‘[1-5] Ton’
ORDER BY prod_name;
1.6.5 匹配特殊字符
正则表达式语言由具有特定含义的特殊字符构成。我们已经看到. 、[ ] 、| 和- 等,还有其他一些字符。请问,如果你需要匹配这些字符,应该怎么办呢?例如,如果要找出包含. 字符的值,怎样搜索?为了匹配特殊字符,必须用\\为前导。\\- 表示查找- ,\\. 表示查找. 。
SELECT vend_nameFROM vendorsWHERE vend_name REGEXP '\\.'ORDER BY vend_name;
正则表达式内具有特殊意义的所有字符都必须以这种方式转义。这包括. 、| 、[ ] 以及迄今为止使用过的其他特殊字符。
1.6.6 匹配字符类
存在找出你自己经常使用的数字、所有字母字符或所有数字字母字符等的匹配。为更方便工作,可以使用预定义的字符集,称为字符类 (characterclass)。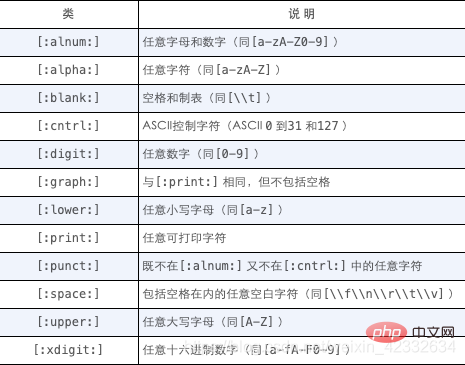
1.6.7 匹配多个实例
目前为止使用的所有正则表达式都试图匹配单次出现。如果存在一个匹配,该行被检索出来,如果不存在,检索不出任何行。但有时需要对匹配的数目进行更强的控制。例如,你可能需要寻找所有的数,不管数中包含多少数字,或者你可能想寻找一个单词并且还能够适应一个尾随的s (如果存在),等等。

SELECT prod_nameFROM productsWHERE prod_name REGEXP '\\([0-9] sticks?\\)'ORDER BY prod_name;正则表达式\\([0-9]sticks?\\) 需要解说一下。\\( 匹配(,[0-9] 匹配任意数字(这个例子中为1和5),sticks? 匹配stick 和sticks (s 后的? 使s 可选,因为? 匹配它前面的任何字符的0次或1次出现),\\) 匹配) 。没有? ,匹配stick 和sticks 会非常困难。
以下是另一个例子。这次我们打算匹配连在一起的4位数字:
SELECT prod_nameFROM productsWHERE prod_name REGEXP '[[:digit:]]{4}'ORDER BY prod_name;
1.6.8 定位符
目前为止的所有例子都是匹配一个串中任意位置的文本。为了匹配特定位置的文本,需要使用下表列出的定位符。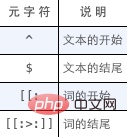
例如,如果你想找出以一个数(包括以小数点开始的数)开始的所有产品,怎么办?简单搜索[0-9\.] (或[[:digit:]\. ])不行,因为它将在文本内任意位置查找匹配。解决办法是使用^定位符,如下所示:
SELECT prod_nameFROM productsWHERE prod_name REGEXP '^[0-9\\.]'ORDER BY prod_name;
1.7、创建计算字段
存储在表中的数据都不是应用程序所需要的。我们需要直接从数据库中检索出转换、计算或格式化过的数据;而不是检索出数据,然后再在客户机应用程序或报告程序中重新格式化。这就是计算字段发挥作用的所在了。与前面各章介绍过的列不同,计算字段并不实际存在于数据库表中。计算字段是运行时在SELECT 语句内创建的。
在MySQL的SELECT 语句中,可使用Concat() 函数来拼接两个列。
SELECT Concat(vend_name, ' (', vend_country, ')')FROM vendorsORDER BY vend_name;
过删除数据右侧多余的空格来整理数据,这可以使用MySQL的RTrim() 函数来完成,如下所示:
SELECT Concat(RTrim(vend_name), ' (', RTrim(vend_country), ')')FROM vendorsORDER BY vend_name;
别名 (alias)是一个字段或值的替换名。别名用AS 关键字赋予。请看下面的SELECT 语句:
SELECT Concat(RTrim(vend_name), ' (', RTrim(vend_country), ')') ASvend_titleFROM vendorsORDER BY vend_name;
一、基础部分
- 一、使用MySQL
- 1.1、SELECT语句
- 1.2、排序检索数据
- 1.3、过滤数据
- 1.4、数据过滤
- 1.5、用通配符进行过滤
- 1.6、用正则表达式进行搜索
- 1.6.1 基本字符匹配
- 1.6.2 进行OR 匹配
- 1.6.3 匹配几个字符之一
- 1.6.4 匹配范围
- 1.6.5 匹配特殊字符
- 1.6.6 匹配字符类
- 1.6.7 匹配多个实例
- 1.6.8 定位符
- 1.7、创建计算字段
一、使用MySQL
连接到MySQL时不会由数据库打开,所以首先要做的就是打开一个数据库:
USE user
USE后面加上想要打开的数据库,如果不知道数据库的名字,使用SHOW DATABASES查看,使用SHOW TABLES可以查看一个数据库中的表,当然也可以查看表中的列SHOW user_id FROM user,它对每个字段返回一行,行中包含字段名、数据类型、是否允许NULL 、键信息、默认值以及其他信息(DESCRIBE user是上面语句的快捷方式)
1.1、SELECT语句
为了使用SELECT 检索表数据,必须至少给出两条信息——想选择什么,以及从什么地方选择。
所需的列名在SELECT 关键字之后给出,FROM 关键字指出从其中检索数据的表名。
要想从一个表中检索多个列,使用相同的SELECT 语句。唯一的不同是必须在SELECT 关键字后给出多个列名,列名之间必须以逗号分隔。
使用DISTINCT关键字可以只检索出不同值的行,重复的不会再显示(注意: DISTINCT 关键字应用于所有列而不仅是前置它的列)
SELECT 语句返回所有匹配的行,它们可能是指定表中的每个行。为了返回第一行或前几行,可使用LIMIT 子句。
LIMIT 5 ,5 指示MySQL返回从行5开始的5行。第一个数为开始位置,第二个数为要检索的行数。
1.2、排序检索数据
为了明确地排序用SELECT 语句检索出的数据,可使用ORDER BY 子句。ORDER BY 子句取一个或多个列的名字,据此对输出进行排序。
为了按多个列排序,只要指定列名,列名之间用逗号分开即可。
数据排序不限于升序排序(从A 到Z )。这只是默认的排序顺序,还可以使用ORDER BY 子句以降序(从Z 到A )顺序排序。为了进行降序排序,必须指定DESC 关键字。(DESC 关键字只应用到直接位于其前面的列名)
1.3、过滤数据
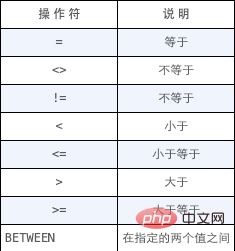
本章将讲授如何使用SELECT 语句的WHERE 子句指定搜索条件。在SELECT 语句中,数据根据WHERE 子句中指定的搜索条件进行过滤。WHERE 子句在表名(FROM 子句)之后给出。在同时使用ORDER BY 和WHERE 子句时,应该让ORDER BY 位于WHERE 之后。WHERE子句操作符如下图所示:
1.4、数据过滤
本章讲授如何组合WHERE 子句以建立功能更强的更高级的搜索条件。我们还将学习如何使用NOT 和IN 操作符。
AND操作符计算次序高于OR操作符
1.5、用通配符进行过滤
本章介绍什么是通配符、如何使用通配符以及怎样使用LIKE 操作符进行通配搜索,以便对数据进行复杂过滤。
为在搜索子句中使用通配符,必须使用LIKE 操作符。LIKE 指示MySQL,后跟的搜索模式利用通配符匹配而不是直接相等匹配进行比较。
最常使用的通配符是百分号(% )。在搜索串中,% 表示任何字符出现任意次数 。( 根据MySQL的配置方式,搜索可以是区分大小写的。如果区分大小写)。
另一个有用的通配符是下划线(_ )。下划线的用途与% 一样,但下划线只匹配单个字符而不是多个字符。
正如所见,MySQL的通配符很有用。但这种功能是有代价的:通配符搜索的处理一般要比前面讨论的其他搜索所花时间更长。这里给出一些使用通配符要记住的技巧。
1.不要过度使用通配符。如果其他操作符能达到相同的目的,应该使用其他操作符。
2.在确实需要使用通配符时,除非绝对有必要,否则不要把它们用在搜索模式的开始处。把通配符置于搜索模式的开始处,搜索起来是最慢的。
3.仔细注意通配符的位置。如果放错地方,可能不会返回想要的数据。
1.6、用正则表达式进行搜索
1.6.1 基本字符匹配
我们从一个非常简单的例子开始。下面的语句检索列prod_name 包含文本1000 的所有行:
SELECT prod_name
FROM products
WHERE prod_name REGEXP ‘1000’
ORDER BY prod_name;
它告诉MySQL:REGEXP 后所跟的东西作为正则表达式(与文字正文1000 匹配的一个正则表达式)处理。
SELECT prod_name
FROM products
WHERE prod_name REGEXP ‘.000’
ORDER BY prod_name;
. 是正则表达式语言中一个特殊的字符。它表示匹配任意一个字符 ,因此,1000 和2000 都匹配且返回。
MySQL中的正则表达式匹配(自版本3.23.4后)不区分大小写(即,大写和小写都匹配)。为区分大小写,可使用BINARY 关键字,如WHERE prod_name REGEXP BINARY ‘JetPack .000’ 。
1.6.2 进行OR 匹配
为搜索两个串之一(或者为这个串,或者为另一个串),使用|,如下所示:
SELECT prod_name
FROM products
WHERE prod_name REGEXP ‘1000|2000’
ORDER BY prod_name;
1.6.3 匹配几个字符之一
如果你只想匹配特定的字符,怎么办?可通过指定一组用[和]括起来的字符来完成,如下所示:
SELECT prod_name
FROM products
WHERE prod_name REGEXP ‘[123] Ton’
ORDER BY prod_name;
字符集合也可以被否定,即,它们将匹配除指定字符外的任何东西。为否定一个字符集,在集合的开始处放置一个^即可。因此,尽管[123] 匹配字符1 、2 或3 ,但[^123] 却匹配除这些字符外的任何东西。
1.6.4 匹配范围
SELECT prod_name
FROM products
WHERE prod_name REGEXP ‘[1-5] Ton’
ORDER BY prod_name;
1.6.5 匹配特殊字符
正则表达式语言由具有特定含义的特殊字符构成。我们已经看到. 、[ ] 、| 和- 等,还有其他一些字符。请问,如果你需要匹配这些字符,应该怎么办呢?例如,如果要找出包含. 字符的值,怎样搜索?为了匹配特殊字符,必须用\\为前导。\\- 表示查找- ,\\. 表示查找. 。
SELECT vend_nameFROM vendorsWHERE vend_name REGEXP '\\.'ORDER BY vend_name;
正则表达式内具有特殊意义的所有字符都必须以这种方式转义。这包括. 、| 、[ ] 以及迄今为止使用过的其他特殊字符。
1.6.6 匹配字符类
存在找出你自己经常使用的数字、所有字母字符或所有数字字母字符等的匹配。为更方便工作,可以使用预定义的字符集,称为字符类 (characterclass)。
1.6.7 匹配多个实例
目前为止使用的所有正则表达式都试图匹配单次出现。如果存在一个匹配,该行被检索出来,如果不存在,检索不出任何行。但有时需要对匹配的数目进行更强的控制。例如,你可能需要寻找所有的数,不管数中包含多少数字,或者你可能想寻找一个单词并且还能够适应一个尾随的s (如果存在),等等。
SELECT prod_nameFROM productsWHERE prod_name REGEXP '\\([0-9] sticks?\\)'ORDER BY prod_name;正则表达式\\([0-9]sticks?\\) 需要解说一下。\\( 匹配(,[0-9] 匹配任意数字(这个例子中为1和5),sticks? 匹配stick 和sticks (s 后的? 使s 可选,因为? 匹配它前面的任何字符的0次或1次出现),\\) 匹配) 。没有? ,匹配stick 和sticks 会非常困难。
以下是另一个例子。这次我们打算匹配连在一起的4位数字:
SELECT prod_nameFROM productsWHERE prod_name REGEXP '[[:digit:]]{4}'ORDER BY prod_name;
1.6.8 定位符
目前为止的所有例子都是匹配一个串中任意位置的文本。为了匹配特定位置的文本,需要使用下表列出的定位符。
例如,如果你想找出以一个数(包括以小数点开始的数)开始的所有产品,怎么办?简单搜索[0-9\.] (或[[:digit:]\. ])不行,因为它将在文本内任意位置查找匹配。解决办法是使用^定位符,如下所示:
SELECT prod_nameFROM productsWHERE prod_name REGEXP '^[0-9\\.]'ORDER BY prod_name;
1.7、创建计算字段
存储在表中的数据都不是应用程序所需要的。我们需要直接从数据库中检索出转换、计算或格式化过的数据;而不是检索出数据,然后再在客户机应用程序或报告程序中重新格式化。这就是计算字段发挥作用的所在了。与前面各章介绍过的列不同,计算字段并不实际存在于数据库表中。计算字段是运行时在SELECT 语句内创建的。
在MySQL的SELECT 语句中,可使用Concat() 函数来拼接两个列。
SELECT Concat(vend_name, ' (', vend_country, ')')FROM vendorsORDER BY vend_name;
过删除数据右侧多余的空格来整理数据,这可以使用MySQL的RTrim() 函数来完成,如下所示:
SELECT Concat(RTrim(vend_name), ' (', RTrim(vend_country), ')')FROM vendorsORDER BY vend_name;
别名 (alias)是一个字段或值的替换名。别名用AS 关键字赋予。请看下面的SELECT 语句:
SELECT Concat(RTrim(vend_name), ' (', RTrim(vend_country), ')') ASvend_titleFROM vendorsORDER BY vend_name;The above is the detailed content of Detailed explanation of common functions of mysql. For more information, please follow other related articles on the PHP Chinese website!