
Home >Database >Mysql Tutorial >My understanding of MySQL five: locks and locking rules
My understanding of MySQL five: locks and locking rules

- coldplay.xixiforward
- 2020-11-11 17:10:282051browse
mysql tutorial column introduces the fifth article of MySQL, about locks and locking rules.

The fifth part of the MySQL series, the main content is lock (Lock), including granular classification of locks, row locks, gap locks and locking rules.
MySQL introduces locks to solve the problem of concurrent writing. For example, two transactions write to the same record at the same time. If they are allowed to do so at the same time, dirty writing will occur. This is an abnormal situation that is not allowed to occur at any isolation level. The function of the lock is to allow two concurrent write operations to be executed in a certain order to avoid dirty write problems.
First of all, declare the examples used in this article
CREATE TABLE `user` ( `id` int(12) NOT NULL AUTO_INCREMENT, `name` varchar(36) NULL DEFAULT NULL, `age` int(12) NULL DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE, INDEX `age`(`age`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 1;insert into user values (5,'重塑',5),(10,'达达',10),(15,'刺猬',15);复制代码
The examples described in this article are all under the MySQL InnoDB storage engine and Repeatable Read (Repeatable Read) isolation level.
1. Granular classification of locks
From the perspective of lock granularity, locks in MySQL can be divided into three types: global locks, table-level locks and row locks.
1.1 Global lock
Global lock will lock the entire database. At this time, the database will be in a read-only state. Any statements that modify the database, including DDL (Data Definition Language) and add All deleted DML (Data Manipulation Language) statements will be blocked until the database global lock is released.
The most common place to use global locks is to perform full database backup. We can implement global lock locking and lock release operations through the following statements:
-- 加全局锁flush tables with read lock;-- 释放全局锁unlock table;复制代码
If the client connection is disconnected, the global lock will be automatically released.
1.2 Table-level lock
Table-level lock will lock the entire table. Table-level locks in MySQL include: Table lock, Meta Data Lock(Meta Data Lock), Intention Lock(Intention Lock) and Auto-increment Lock(AUTO-INC Lock).
1.2.1 Table lock
How to lock and release table lock:
- Lock:
lock table tableName read/write; - Release the lock:
unlock table;
It should be noted that locking the table lock also limits the operation permissions of the same client connection , if a table-level read lock (lock table user read) is added, then in the same client connection, before the table-level read lock is released, the same table (user table) can only be read Operations cannot be performed, and other client connections can only perform read operations on this table (user table), but cannot perform write operations.
If a table-level write lock (lock table user write) is added, the table can be read and written in the same client connection, but other client connections cannot read. Operations also cannot perform write operations.
1.2.2 Metadata Lock
The second type of table-level lock is Metadata Lock (MDL, Meta Data Lock). The metadata lock will be accessed on the client The lock is automatically locked when the table is entered, and the lock is released when the client submits the transaction. It prevents problems in the following scenarios:
| sessionA | sessionB |
|---|---|
| begin; | |
|
##alter table user add column birthday datetime; |
|
opens a transaction and performs a query. After that, another client sessionB adds a birthday field to the user table, and then sessionA performs another query. If there is no metadata lock, it is possible In the same transaction, the records queried twice before and after, the number of table fields and columns are inconsistent, which obviously needs to be avoided. The DDL operation adds a metadata write lock to the table, which is not compatible with the metadata read and write locks of other transactions; the DML operation adds a metadata read lock to the table, which is compatible with the metadata of other transactions. Read locks are shared but are incompatible with metadata write locks from other transactions.
1.2.3 Intention lock
The third type of table-level lock is
Intention lock, which indicates that the transaction wants to acquire locks for certain rows in a table (shared lock or exclusive lock). Intention lock is to avoid the system consumption of another transaction applying for a table lock and scanning each row in the table to see if there is a row lock in the table.
| sessionB | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ##flush table user read; |
| 事务A\事务B | 共享锁(S锁) | 排它锁(X锁) |
|---|---|---|
| 共享锁(S锁) | 兼容 | 冲突 |
| 排它锁(X锁) | 冲突 | 冲突 |
而从行锁的粒度继续细分,又可以分为记录锁(Record Lock)、间隙锁(Gap Lock)、Next-key Lock。
1.3.1 记录锁(Record Lock)
我们一般所说的行锁都是指记录锁,它会把数据库中的指定记录行加上锁。
假设事务A中执行以下语句(未提交):
begin;update user set name='达闻西' where id=5;复制代码
InnoDB 至少会在 id=5 这一行上加一把行级排它锁(X锁),不允许其他事务操作 id=5 这一行。
需要注意的是,这把锁是加在 id 列的主键索引上的,也就是说行级锁是加在索引上的。
假设现在有另一个事务B想要执行一条更新语句:
update user set name='大波浪' where id=5;复制代码
这时候,这条更新语句将被阻塞,直到事务A提交以后,事务B才能继续执行。
1.3.2 间隙锁(Gap Lock)
间隙锁,顾名思义就是给记录之间的间隙加上锁。
需要注意的是,间隙锁只存在于可重复读(Repeatable Read)隔离级别下。
不知道大家还记不记得幻读?
幻读是指在同一事务中,连续执行两次同样的查询语句,第二次的查询语句可能会返回之前不存在的行。
间隙锁的提出正是为了防止幻读中描述的幻影记录的插入而提出的,举个例子。
| sessionA | sessionB |
|---|---|
| begin; | |
| select * from user where age=5;(N1) | |
| insert into user values(2, '大波浪', 5) | |
| update user set name='达闻西' where age=5; | |
| select * from user where age=5;(N2) |
sessionA 中有两处查询N1和N2,它们的查询条件都是 age=5,唯一不同的是在N2处的查询前有一条更新语句。
照理说在 RR 隔离级别下,同一个事务中两次查询相同的记录,结果应该是一样的。但是在经过更新语句的当前读查询后(更新语句的影响行数是2),N1和N2的查询结果并不相同,N2的查询将 sessionB 插入的数据也查出来了,这就是幻读。
而如果在 sessionA 中的两次次查询都用上间隙锁,比如都改为select * from user where age=5 for update。那么 sessionA 中的当前读查询语句至少会将id在(-∞, 5)和(5, 10)之间的间隙加上间隙锁,不允许其他事务插入主键id属于这两个区间的记录,即会将 sessionB 的插入语句阻塞,直到 sessionA 提交之后,sessionB 才会继续执行。
也就是说,当N2处的查询执行时,sessionB 依旧是被阻塞的状态,所以N1和N2的查询结果是一样的,都是(5,重塑,5),也就解决了幻读的问题。
1.3.3 Next-key Lock
Next-key Lock 其实就是记录锁与记录锁前面间隙的间隙锁组合的产物,它既阻止了其他事务在间隙的插入操作,也阻止了其他事务对记录的修改操作。
2. 加锁规则
不知道大家有没有注意到,我在行锁部分描述记录锁、间隙锁加锁的具体记录时,用的是「至少」二字,并没有详细说明具体加锁的是哪些记录,这是因为记录锁、间隙锁和 Next-key Lock 的加锁规则是十分复杂的,这也是本文主要讨论的内容。
关于加锁规则的叙述将分为三个方面:唯一索引列、普通索引列和普通列,每一方面又将细分为等值查询和范围查询两方面。
需要注意的是,这里加的锁都是指排它锁。
在开始之前,先来回顾一下示例表以及表中可能存在的行级锁。
mysql> select * from user; +----+--------+------+| id | name | age | +----+--------+------+| 5 | 重塑 | 5 | | 10 | 达达 | 10 | | 15 | 刺猬 | 15 | +----+--------+------+3 rows in set (0.00 sec)复制代码
表中可能包含的行级锁首先是每一行的记录锁——(5,重塑,5),(10,达达,5),(15,刺猬,15)。
假设 user 表的索引值有最大值 maxIndex 和最小值 minIndex,user 表还可能存在间隙锁(minIndex,5),(5,10),(10,15),(15,maxIndex)。
共三个记录锁和四个间隙锁。
2.1 唯一索引列等值查询
首先来说唯一索引列的等值查询,这里的等值查询可以分为两种情况:命中与未命中。
当唯一索引列的等值查询命中时:
| sessionA | sessionB |
|---|---|
| begin; | |
| select * from user where id=5 for update; | |
| insert into user values(1,'斯斯与帆',1),(6,'夏日阳光',6),(11,'告五人',11),(16,'面孔',16); | |
| update user set age=18 where id=5;(Blocked) | |
| update user set age=18 where id=10; | |
| update user set age=18 where id=15; |
The execution result of sessionB in the above table is that except for the update statement of row id=5, which is blocked, other statements are executed normally.
sessionB The insert statement is to check the gap lock, and the update statement is to check the record lock (row lock). The execution results show that all gaps in the user table are not locked, and only the row with id=5 is locked in the record lock.
So, when the equivalent query of the unique index column hits, only the hit record will be locked.
When the equality query for the unique index column misses:
| sessionA | sessionB |
|---|---|
| #begin; | |
|
##insert into user values (2,'Reflector',2);( | Blocked) |
| ##update user set age=18 where id=5; |
|
| ##insert into user values (11,'Sue five people',11); | |
|
|
update user set age=18 where id=15; |
| insert into user values (16,'face ',16); | |
| sessionB | is blocked, and other statements are executed normally.
The lock added to the user table is gap lock (1,5).
So, when the equal value query of the unique index column misses, will add a gap lock
 2.2 Unique index column range query
2.2 Unique index column range query
Range query is more complex than equal value query. It needs to take into account whether the boundary value exists in the table and whether the boundary value is hit. First let’s look at the situation where the boundary value exists in the table but is missed:
sessionAsessionB| #begin; | |
|---|---|
| ##select * from user where id | |
|
insert into user values (1,'Sisi and Sail',1);( | Blocked|
| update user set age=18 where id=5;( | Blocked|
| |
insert into user values (6,'Summer Sunshine',6);( | Blocked
| update user set age=18 where id=10;( | Blocked|
| insert into user values (11,'Sue five people',11); | |
|
##insert into user values (16,'face',16) ; |
|
| sessionA are record locks | id=5,id=10and gap locks (minIndex,5),(5,10). |
Next-key Lock: (minIndex, 5], (5,10], that is, Next-key Lock —— (minIndex,10].
##When the boundary value exists In the table, simultaneous hits: ##sessionA
sessionB
| ##select * from user where id | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ) |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| update user set age=18 where id=5;( Blocked | )|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| insert into user values (6,'Summer Sunshine',6);( Blocked | )|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Blocked ) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| ) |
##update user set age=18 where id=15;( | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| insert into user values (16,'face',16) ; | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 此时
当边界值不存在于表中时,不可能命中,故只有未命中一种情况:
此时
综上所述,在对唯一索引进行范围查询时:
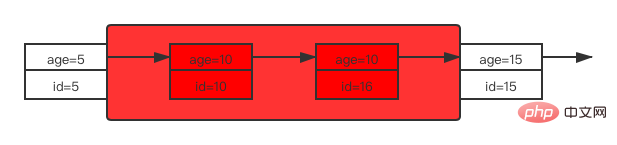
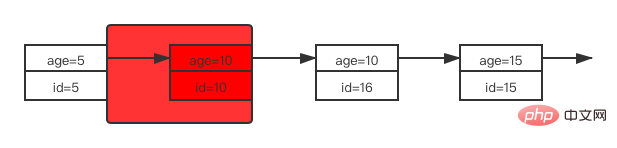
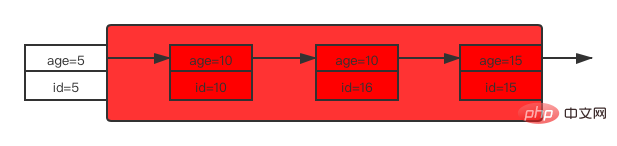
2.3 普通索引列等值查询普通索引与唯一索引的区别就在于唯一索引可以根据索引列确定唯一性,所以等值查询的加锁规则也有不同之处。 给 user 表再加一条记录: INSERT INTO user VALUES (11, '达达2.0', 10);复制代码 这时 user 表的索引 age 结构如下图所示:
在索引 age 中可能存在的行锁是4个记录锁以及5个间隙锁。 先来看索引 age 上的加锁情况:
Judging from the statements and execution results in the above table, the locking situation on the index age is:
That is, the locking area on the index age is (5, 15). Since the ordinary index cannot determine the uniqueness of the record, when locking the index age in the ordinary index column equal value query, will find the first age value less than 10 (i.e. 5) and The first age is greater than 10 (i.e. 15), gaps within this range are added with gap locks, and records are added with record locks. This is the locking situation on the index age. Since the query statement is to query all columns of the record, according to the query rules, the corresponding id value on the index age will be returned to the primary key index tree for table return operations, and we get All columns, so the primary key index will also be locked. Here, the primary key IDs of the records that satisfy age=10 are 10 and 16 respectively, so these two rows will also be locked exclusively on the primary key index. That is, ordinary index column equivalent queryIf the table needs to be returned, the primary key corresponding to the record that meets the conditions will also be added with a record lock.
2.4 Ordinary index column equal value query limitWe need to mention the limit syntax here. Its locking range (only ordinary indexes are discussed) is smaller. Please See example:
It can be seen that: limit syntax Locks will only be added to records that meet the conditions, which can reduce the locking scope. Next, let’s look at the range query on ordinary index columns (only the lock range of the index age is discussed here. The lock of the primary key index will be locked if there is a return table. Corresponding id value): sessionA
|

The above is the detailed content of My understanding of MySQL five: locks and locking rules. For more information, please follow other related articles on the PHP Chinese website!