
Home >Database >Mysql Tutorial >Understand InnoDB's Checkpoint technology
Understand InnoDB's Checkpoint technology

- coldplay.xixiforward
- 2020-10-28 17:14:332724browse
mysql教程栏目带大家了解InnoDB的Checkpoint技术。

一句话概括,Checkpoint技术就是将缓存池中脏页在某个时间点刷回到磁盘的操作
遇到的问题 ?
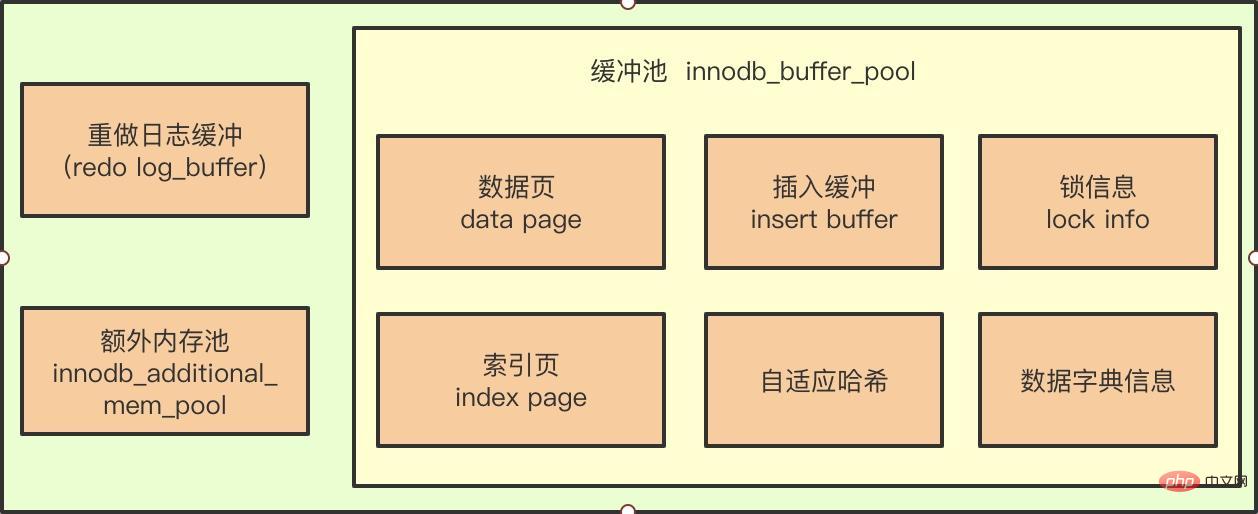
都知道缓冲池的出现就是为了解决CPU与磁盘速度之间的鸿沟,免得我们在读写数据库时还需要进行磁盘IO操作。有了缓冲池后,所有的页操作首先都是在缓冲池内完成的。
如一个DML语句,进行数据update或delete 操作时,此时改变了缓冲池页中的记录,此时因为缓冲池页的数据比磁盘的新,此时的页就叫做脏页。
不管怎样,总会后的内存页数据需要刷回到磁盘里,这里就涉及几个问题:
- 若每次一个页发生变化,就将新页的版本刷新到磁盘,那么这个开销是非常大的
- 若热点数据集中在某几个页中,那么数据库的性能将变得非常差
- 如果在从缓冲池将页的新版本刷新到磁盘时发生了宕机,那么数据就不能恢复了
Write Ahead Log(预写式日志)
WAL策略解决了刷新页数据到磁盘时发生宕机而导致数据丢失的问题,它是关系数据库系统中用于提供原子性和持久性(ACID 属性中的两个)的一系列技术。
WAL策略核心点就是
redo log,每当有事务提交时,先写入 redo log(重做日志),在修改缓冲池数据页,这样当发生掉电之类的情况时系统可以在重启后继续操作
WAL策略机制原理
InnoDB为了保证数据不丢失,维护了redo log。在缓冲池的数据页修改之前,需要先将修改的内容记录到redo log中,并保证redo log早于对应的数据页落盘,这就是WAL策略。
When a failure occurs and memory data is lost, InnoDB will restore the buffer pool data pages to the state before the crash by replaying the redo log when restarting.
Checkpoint
It stands to reason that with the WAL strategy, we can sit back and relax. But the problem appears again in the redo log:
- The redo log cannot be infinite, and we cannot endlessly store our data waiting to be refreshed to the disk
- In When the database is idle and restored, if the redo log is too large, the cost of recovery will also be very high
So in order to solve the refresh performance of dirty pages, at what time and under what circumstances should dirty pages be refreshed? The refresh uses Checkpoint technology.
Purpose of Checkpoint
1. Shorten the recovery time of the database
When the database is idle and restored, there is no need to redo all log information. Because the data page before Checkpoint has been flushed back to the disk. Just restore the redo log after the Checkpoint.
2. When the buffer pool is not enough, flush the dirty pages to the disk.
When the buffer pool space is insufficient, the least recently used page will overflow according to the LRU algorithm. If This page is a dirty page, so you need to force a Checkpoint to flush the dirty page, that is, the new version of the page, back to the disk.
3. When the redo log is unavailable, refresh the dirty pages
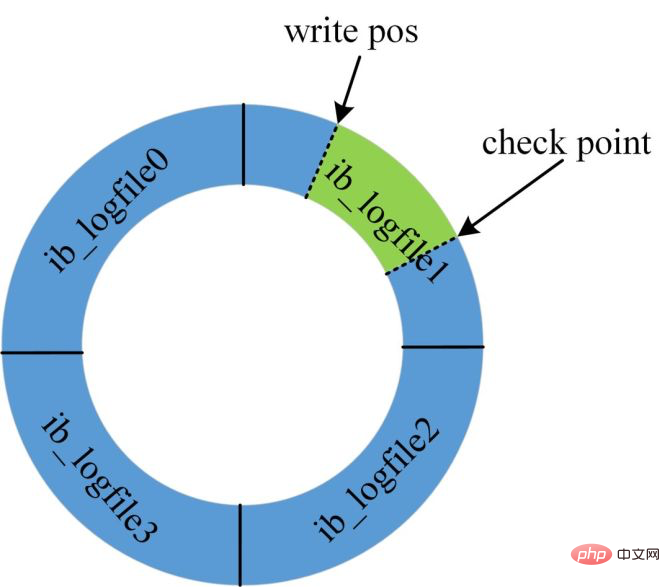
As shown in the figure, the redo log is unavailable because the current database The designs are all recycled, so the space is not infinite.
When the redo log is full, because the system cannot accept updates at this time, all update statements will be blocked.
At this time, a Checkpoint must be forced to be generated. The write pos needs to be pushed forward, and the dirty pages within the pushing range need to be flushed to the disk.
Type of Checkpoint
The time when the Checkpoint occurs , conditions and selection of dirty pages are very complex.
Checkpoint How many dirty pages are flushed to disk each time?
Where does Checkpoint get dirty pages from every time?
When is Checkpoint triggered?
Faced with the above problems, the InnoDB storage engine provides us with two Checkpoints internally:
-
Sharp Checkpoint
When the database is shut down, all dirty pages are flushed back to the disk. This is the default working method. The parameter innodb_fast_shutdown=1
-
Fuzzy Checkpoint
Inside the InnoDB storage engine Using this mode, only a part of the dirty pages are flushed, instead of flushing all dirty pages back to disk
What happens with FuzzyCheckpoint
-
Master Thread Checkpoint
Flushes a certain proportion of pages back to disk from the dirty page list in the buffer pool almost every second or every ten seconds.
This process is asynchronous, that is, the InnoDB storage engine can perform other operations at this time, and the user query thread will not be blocked
-
FLUSH_LRU_LIST Checkpoint
Because the LRU list must ensure that a certain number of free pages can be used, if there are not enough, pages will be removed from the tail. If the removed pages have dirty pages, this Checkpoint will be performed.
After version 5.6, this Checkpoint is placed in a separate Page Cleaner thread, and users can control the number of available pages in the LRU list through the parameter innodb_lru_scan_depth. The default value is 1024
-
Async/Sync Flush Checkpoint
refers to the situation where the redo log file is unavailable. At this time, some pages need to be forcibly flushed back to the disk, and the dirty pages are removed from the dirty page list. The selected
5.6 version will not block user queries
-
Dirty Page too much Checkpoint That is, the number of dirty pages is too large, causing the InnoDB storage engine to force a Checkpoint.
The purpose is generally to ensure that there are enough available pages in the buffer pool.
It can be controlled by the parameter innodb_max_dirty_pages_pct. For example, the value is 75, which means that when the dirty pages in the buffer pool occupy 75%, CheckPoint is forced to be performed
Summary
Because of the gap between CPU and disk, buffer pool data pages appear to speed up database DML operations
Because buffer pool data pages are consistent with disk data Sexual problems, resulting in WAL strategy (the core is redo log)
Because of the refresh performance problem of buffer pool dirty pages, Checkpoint technology appeared
InnoDB In order to improve execution efficiency, every DML operation does not interact with the disk for persistence. Instead, write the redo log first through Write Ahead Log to ensure the persistence of things.
For the buffer pool dirty pages modified in the transaction, the disk will be flushed asynchronously, and the availability of memory free pages and redo log is guaranteed through Checkpoint technology.
More related free learning recommendations: mysql tutorial(Video)
The above is the detailed content of Understand InnoDB's Checkpoint technology. For more information, please follow other related articles on the PHP Chinese website!