
Home >Web Front-end >JS Tutorial >Understand the basic principles of JavaScript engines
Understand the basic principles of JavaScript engines

- coldplay.xixiforward
- 2020-10-10 17:28:592461browse
As a JavaScript column developer, a deep understanding of how the JavaScript engine works will help you understand the performance characteristics of your code. This article covers some key basics common to all JavaScript engines, not just V8.
JavaScript engine workflow (pipeline)
It all starts with the JavaScript code you write. The JavaScript engine parses the source code and converts it into an abstract syntax tree (AST). Based on the AST, the interpreter can start working and generate bytecode. At this point, the engine starts actually running JavaScript code. 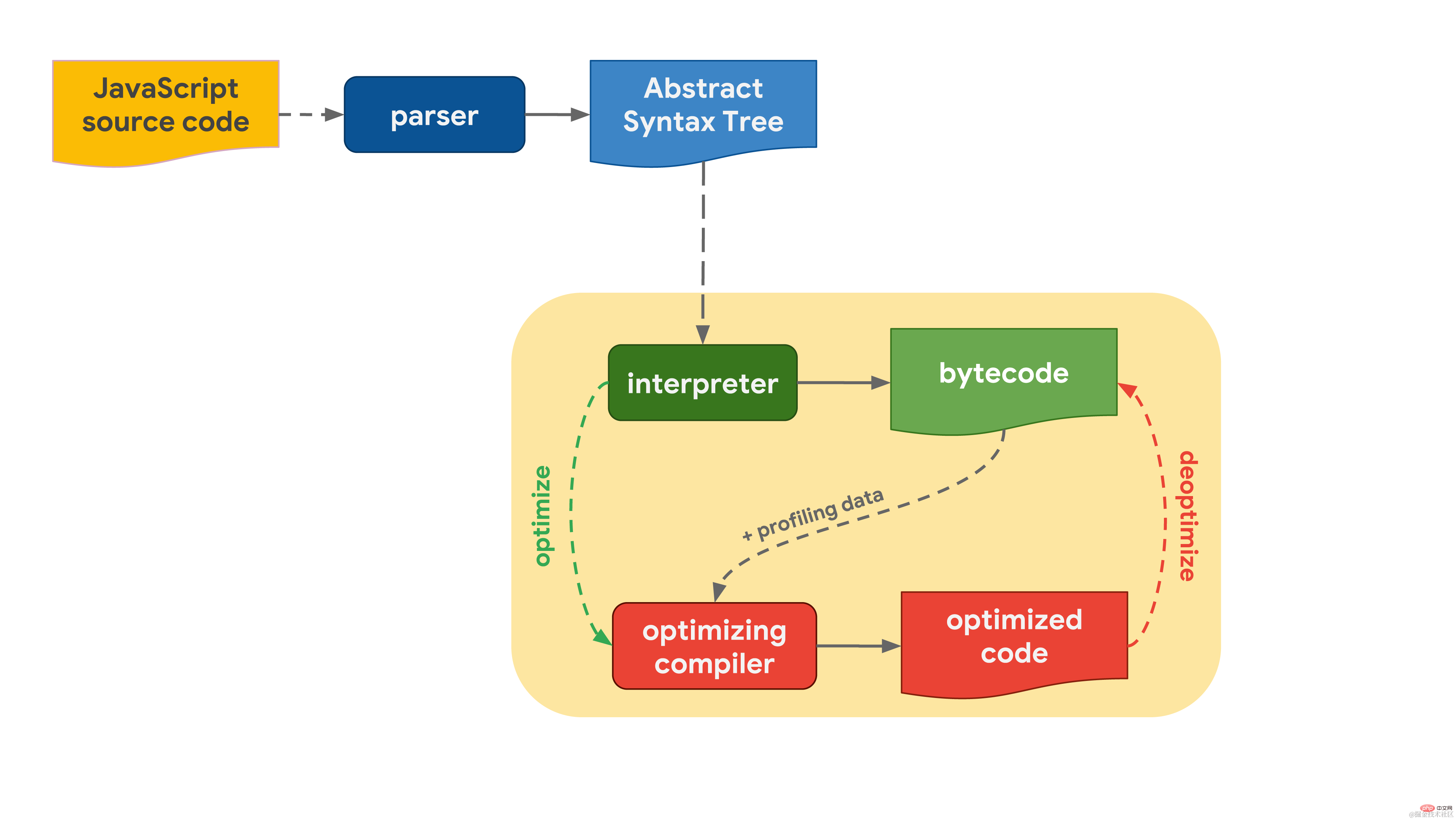 To make it run faster, the bytecode can be sent to the optimizing compiler along with the profiling data. An optimizing compiler makes certain assumptions based on available profiling data and then generates highly optimized machine code.
To make it run faster, the bytecode can be sent to the optimizing compiler along with the profiling data. An optimizing compiler makes certain assumptions based on available profiling data and then generates highly optimized machine code.
If at some point an assumption proves to be incorrect, the optimizing compiler will cancel the optimization and return to the interpreter stage.
Interpreter/Compiler Workflow in JavaScript Engine
Now, let’s look at the part of the process that actually executes JavaScript code, that is, the part where the code is interpreted and optimized, and discuss it There are some differences between the major JavaScript engines.
Generally speaking, the JavaScript engine has a processing flow that includes an interpreter and an optimizing compiler. Among them, the interpreter can quickly generate unoptimized bytecode, while the optimizing compiler will take longer, but can ultimately generate highly optimized machine code. 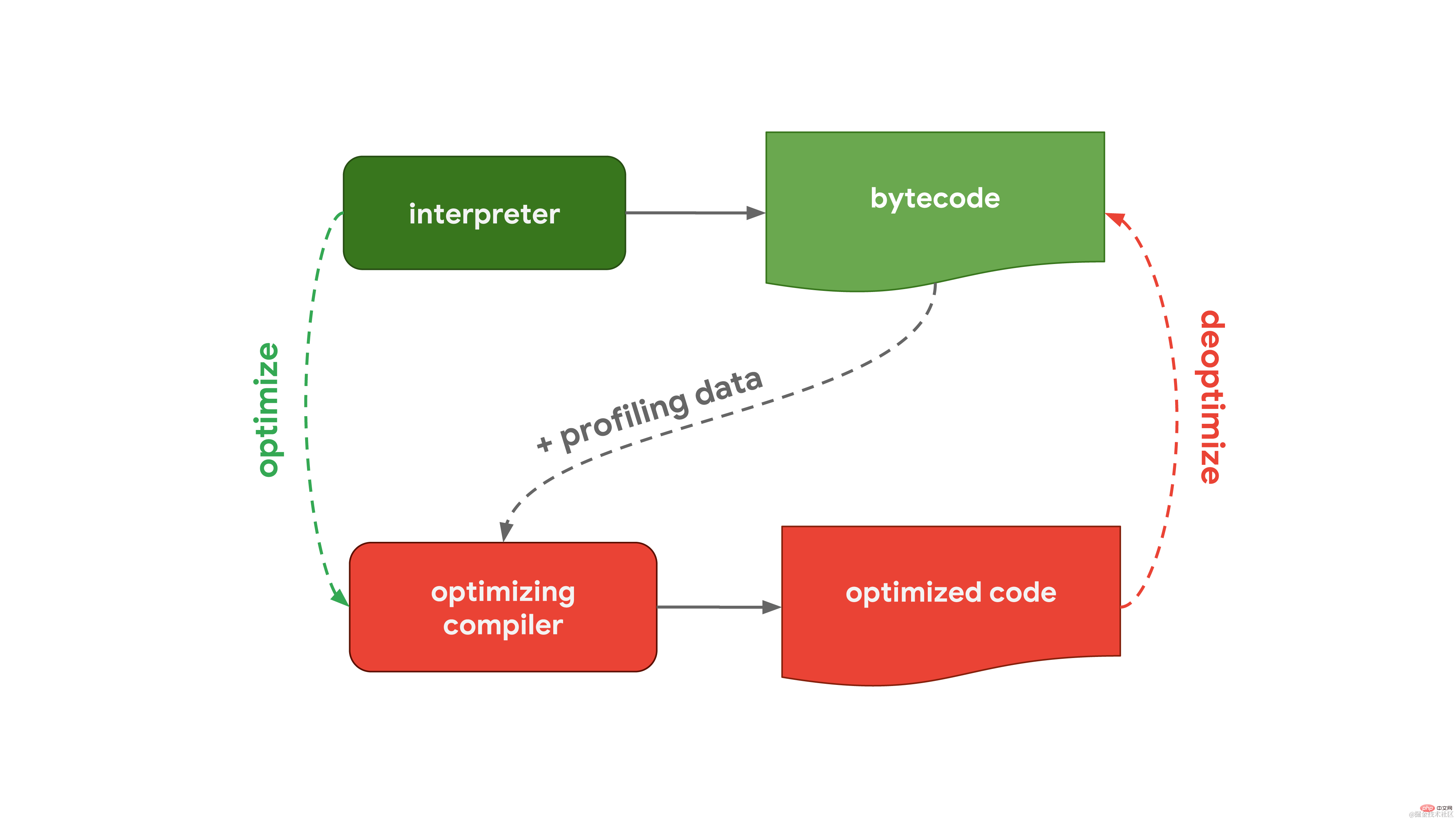 This general process is almost the same as the workflow of V8, the Javascript engine used in Chrome and Node.js:
This general process is almost the same as the workflow of V8, the Javascript engine used in Chrome and Node.js: 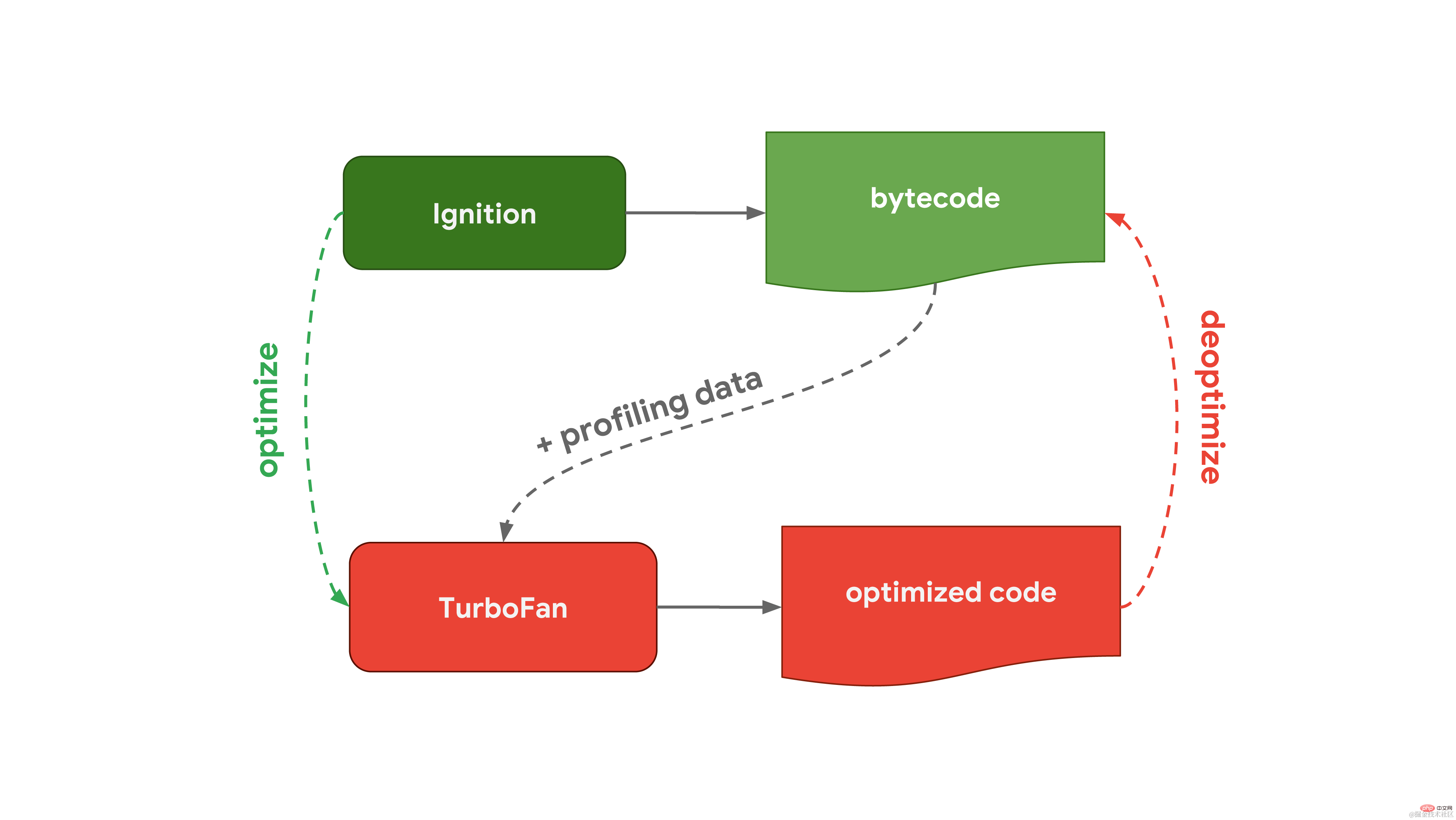 The interpreter in V8 is called Ignition and is responsible for generating and executing bytecode. As it runs the bytecode, it collects profiling data that can be used later to speed up the execution of the code. When a function becomes hot, such as when it is run frequently, the generated bytecode and profiling data are passed to Turbofan, our optimizing compiler, to generate highly optimized machine code based on the profiling data.
The interpreter in V8 is called Ignition and is responsible for generating and executing bytecode. As it runs the bytecode, it collects profiling data that can be used later to speed up the execution of the code. When a function becomes hot, such as when it is run frequently, the generated bytecode and profiling data are passed to Turbofan, our optimizing compiler, to generate highly optimized machine code based on the profiling data. 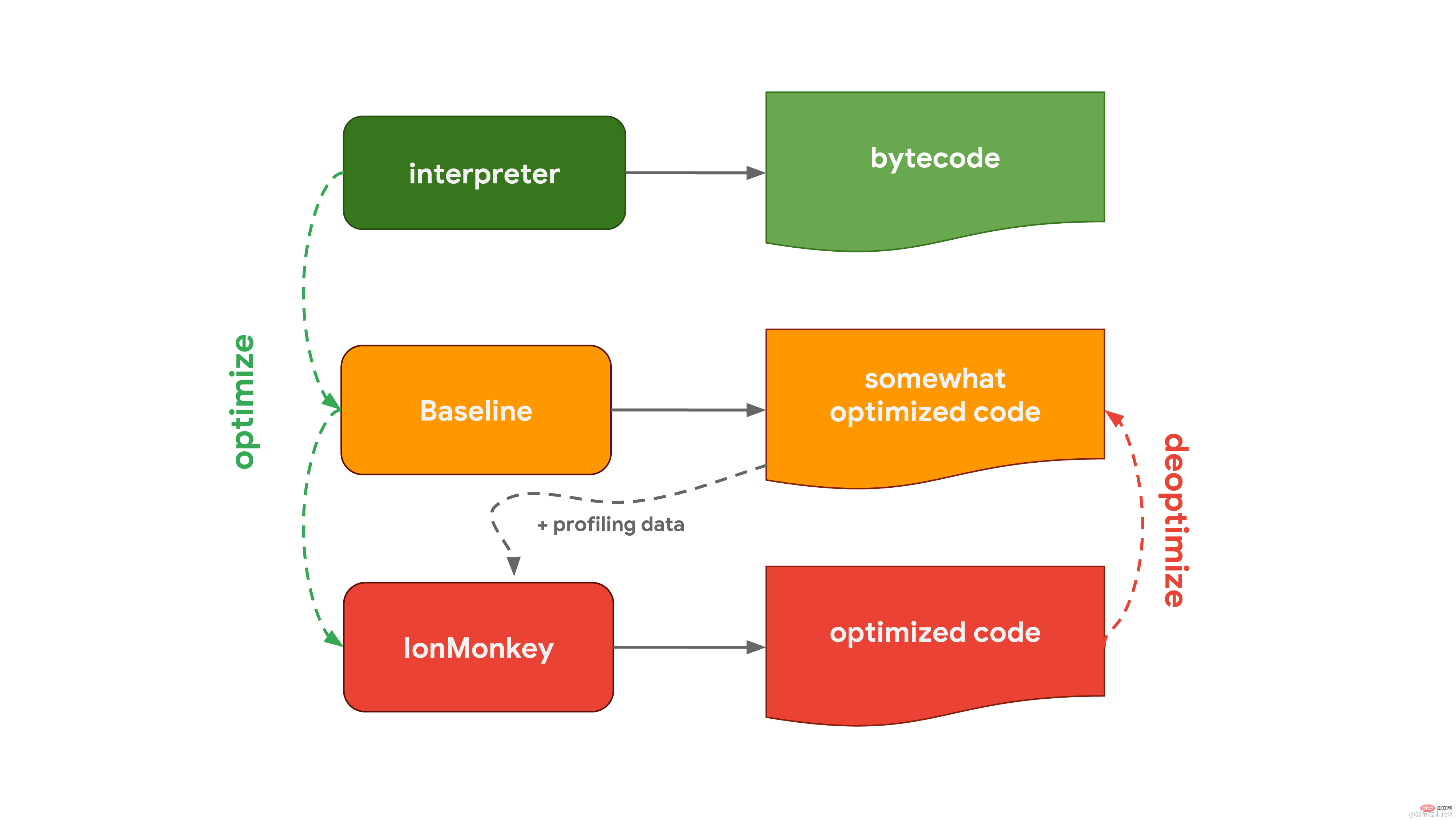 SpiderMonkey, the JavaScript engine used by Mozilla in Firefox and Spidernode, is different. They have two optimizing compilers instead of one. The interpreter first passes through the Baseline compiler to generate some optimized code. Then, combined with profiling data collected while running the code, the IonMonkey compiler can generate more highly optimized code. If the optimization attempt fails, IonMonkey will return to the code in the Baseline stage.
SpiderMonkey, the JavaScript engine used by Mozilla in Firefox and Spidernode, is different. They have two optimizing compilers instead of one. The interpreter first passes through the Baseline compiler to generate some optimized code. Then, combined with profiling data collected while running the code, the IonMonkey compiler can generate more highly optimized code. If the optimization attempt fails, IonMonkey will return to the code in the Baseline stage.
Chakra, Microsoft's JavaScript engine used in Edge, is very similar and also has 2 optimizing compilers. The interpreter optimizes the code into SimpleJIT (JIT stands for Just-In-Time compiler, just-in-time compiler), which produces slightly optimized code. FullJIT combines analysis data to generate more optimized code. 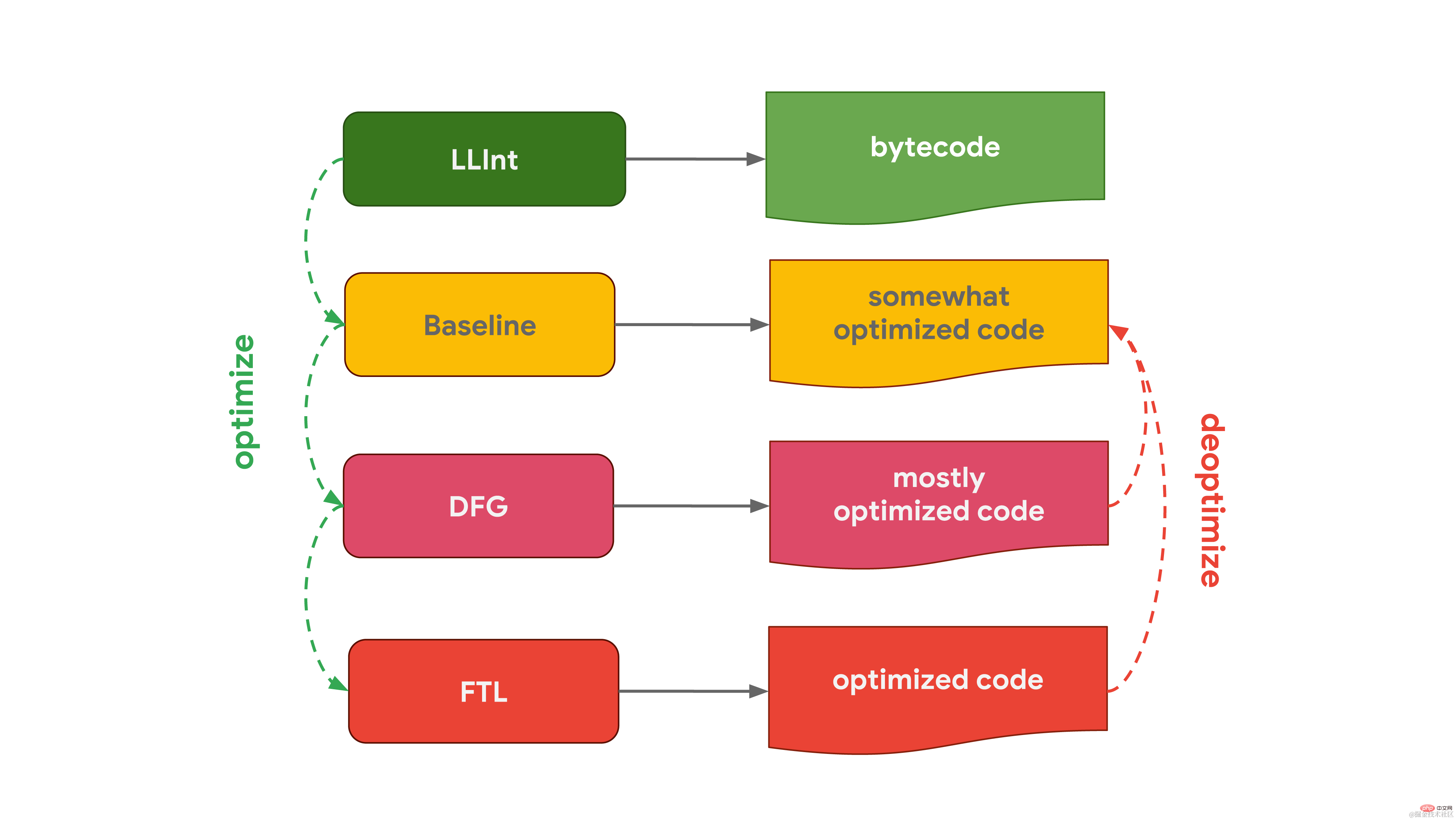 JavaScriptCore (abbreviated as JSC), Apple’s JavaScript engine used in Safari and React Native, takes it to the extreme with three different optimizing compilers. The low-level interpreter LLInt optimizes the code into the Baseline compiler, and then optimizes the code into the DFG (Data Flow Graph) compiler. The DFG (Data Flow Graph) compiler can in turn pass the optimized code to FTL (Faster Than Light) for compilation. in the vessel.
JavaScriptCore (abbreviated as JSC), Apple’s JavaScript engine used in Safari and React Native, takes it to the extreme with three different optimizing compilers. The low-level interpreter LLInt optimizes the code into the Baseline compiler, and then optimizes the code into the DFG (Data Flow Graph) compiler. The DFG (Data Flow Graph) compiler can in turn pass the optimized code to FTL (Faster Than Light) for compilation. in the vessel.
Why do some engines have more optimizing compilers? This is a result of weighing the pros and cons. Interpreters can generate bytecode quickly, but bytecode is generally not very efficient. Optimizing compilers, on the other hand, take longer but ultimately produce more efficient machine code. There is a trade-off between getting the code to run quickly (interpreter) or taking more time, but ultimately running the code with optimal performance (optimizing compiler). Some engines choose to add multiple optimizing compilers with different time/efficiency characteristics, allowing more fine-grained control of these trade-offs at the cost of additional complexity. Another aspect that needs to be weighed is related to memory usage, which will be detailed in a dedicated article later.
We have just highlighted the major differences in the interpreter and optimizing compiler processes in each JavaScript engine. Aside from these differences, at a high level, all JavaScript engines have the same architecture: there is a parser and some kind of interpreter/compiler flow.
JavaScript's Object Model
Let's see what else JavaScript engines have in common by zooming in on some aspects of implementation.
For example, how do JavaScript engines implement the JavaScript object model, and what techniques do they use to speed up accessing properties of JavaScript objects? It turns out that all major engines have similar implementations at this point.
The ECMAScript specification basically defines all objects as dictionaries with string keys mapped to property properties.
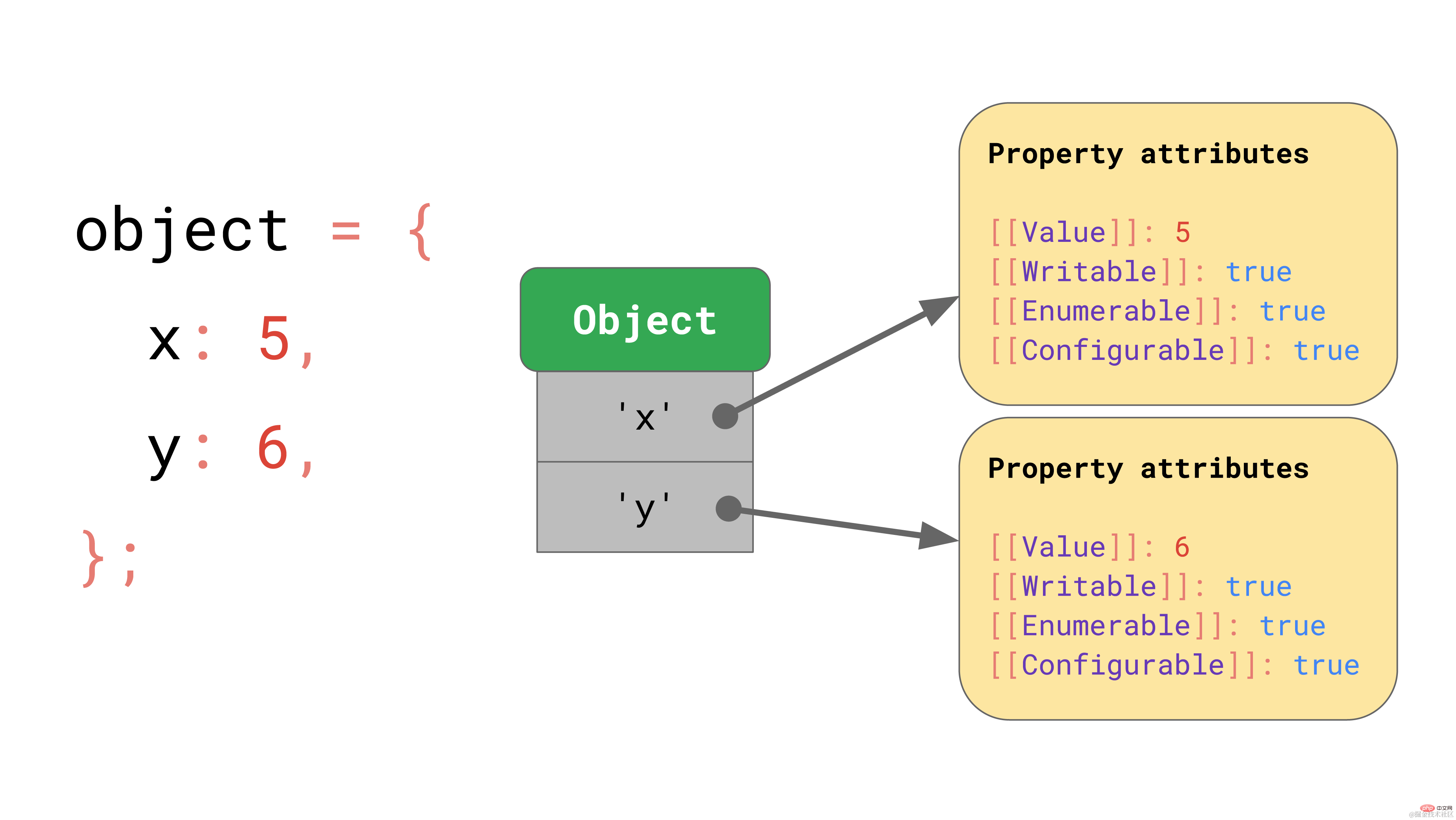 In addition to [[Value]] itself, the specification also defines these properties:
In addition to [[Value]] itself, the specification also defines these properties:
- [[Writable]] determines whether the property can be reassigned,
- [[Enumerable]] determines whether the attribute appears in the for in loop,
- [[Configurable]] determines whether the attribute can be deleted. The notation for
[[square brackets]] looks a bit unusual, but this is how the specification defines properties that cannot be directly exposed to JavaScript. In JavaScript you can still get the property value of a specified object through the Object.getOwnPropertyDescriptor API:
const object = { foo: 42 };Object.getOwnPropertyDescriptor(object, 'foo');// → { value: 42, writable: true, enumerable: true, configurable: true }复制代码
This is how JavaScript defines objects, but what about arrays?
You can think of an array as a special object. One of the differences is that arrays perform special processing on array indexes. Array indexing here is a special term in the ECMAScript specification. Arrays are limited in JavaScript to have at most 2³²−1 elements, and the array index is any valid index in that range, i.e. any integer from 0 to 2³²−2.
Another difference is that arrays also have a special length property.
const array = ['a', 'b']; array.length; // → 2array[2] = 'c'; array.length; // → 3复制代码
In this example, the array is created with length 2. When we assign another element to index 2, length is automatically updated.
JavaScript defines arrays in a similar way to objects. For example, all key values, including array indices, are explicitly represented as strings. The first element in the array is stored under the key value '0'. 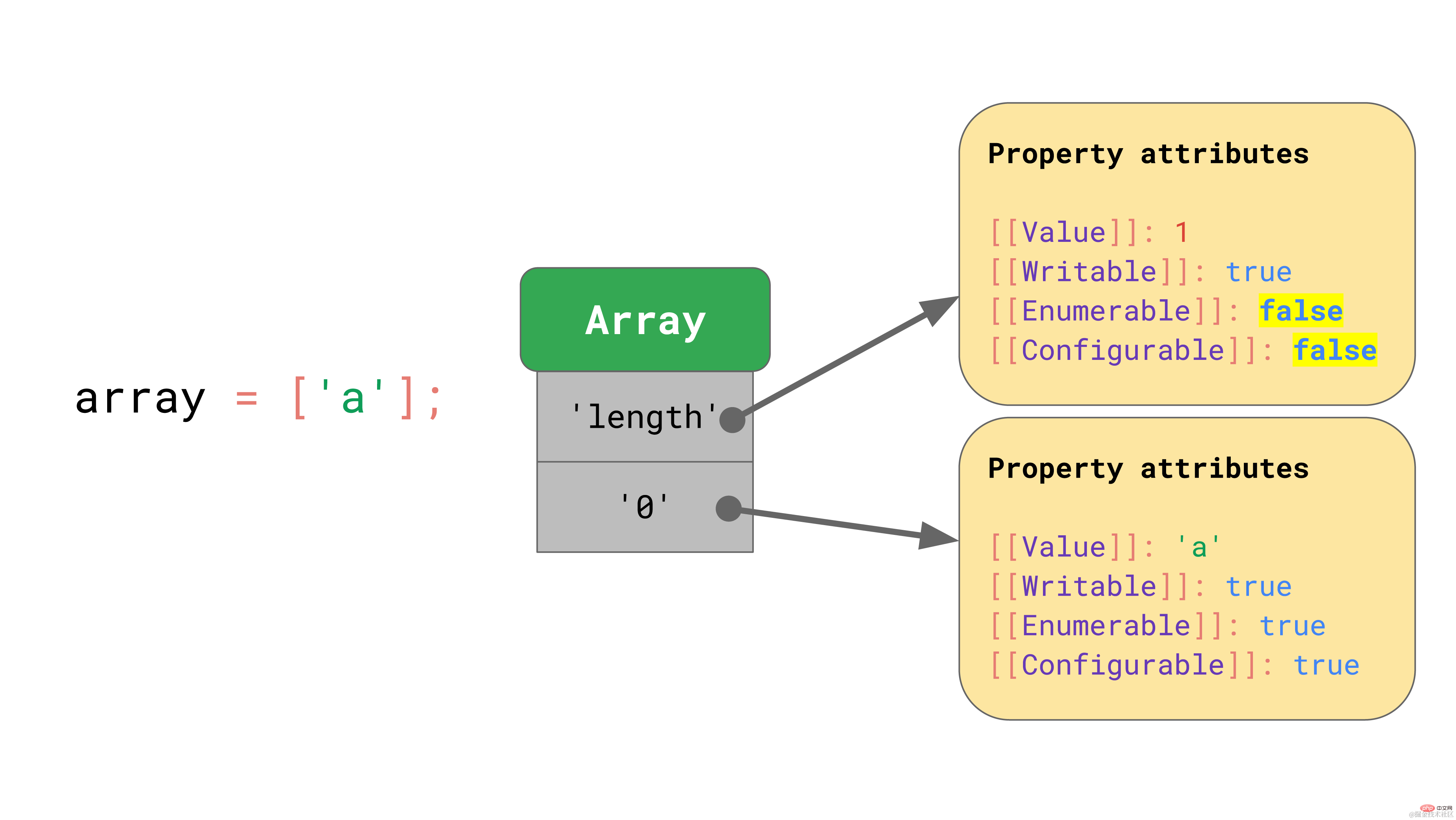 The "length" property is another non-enumerable and non-configurable property.
When an element is added to the array, JavaScript automatically updates the [[value]] property of the “length” property.
The "length" property is another non-enumerable and non-configurable property.
When an element is added to the array, JavaScript automatically updates the [[value]] property of the “length” property. 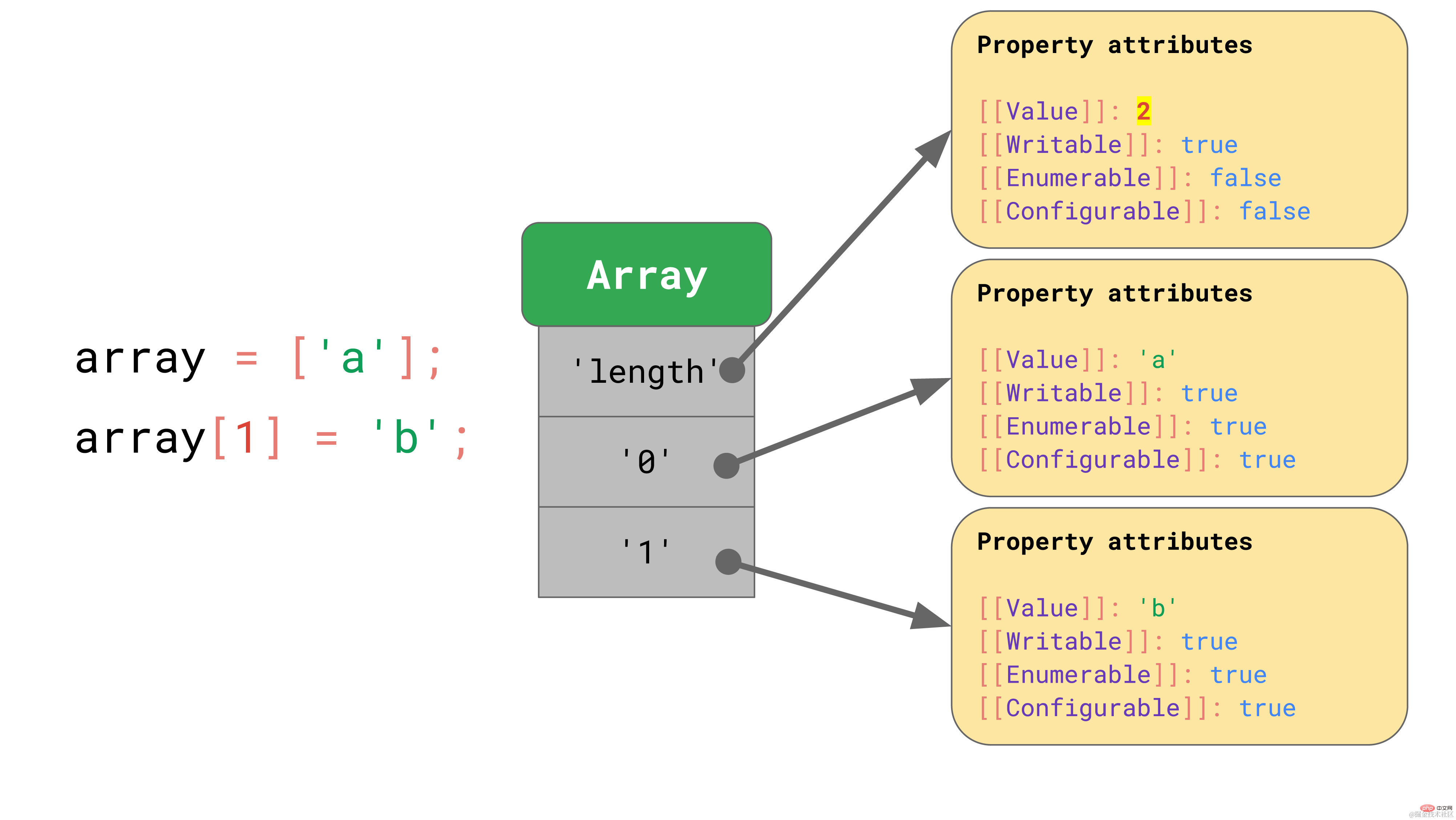
Optimize attribute access
Now that we know how objects are defined in JavaScript, let us take a deeper look at how the JavaScript engine uses objects efficiently. Overall, accessing properties is by far the most common operation in JavaScript programs. Therefore, it is crucial that the JavaScript engine can access properties quickly.
Shapes
In JavaScript programs, it is very common for multiple objects to have the same key-value properties. We can say that these objects have the same shape.
const object1 = { x: 1, y: 2 };const object2 = { x: 3, y: 4 };// object1 and object2 have the same shape.复制代码
It is also very common to access the same properties of objects with the same shape:
function logX(object) { console.log(object.x);
}const object1 = { x: 1, y: 2 };const object2 = { x: 3, y: 4 };
logX(object1);
logX(object2);复制代码
With this in mind, JavaScript engines can optimize object property access based on the object's shape. Below we will introduce its principle.
Suppose we have an object with properties x and y that uses the dictionary data structure we discussed earlier: it contains keys in the form of strings that point to their respective property values. 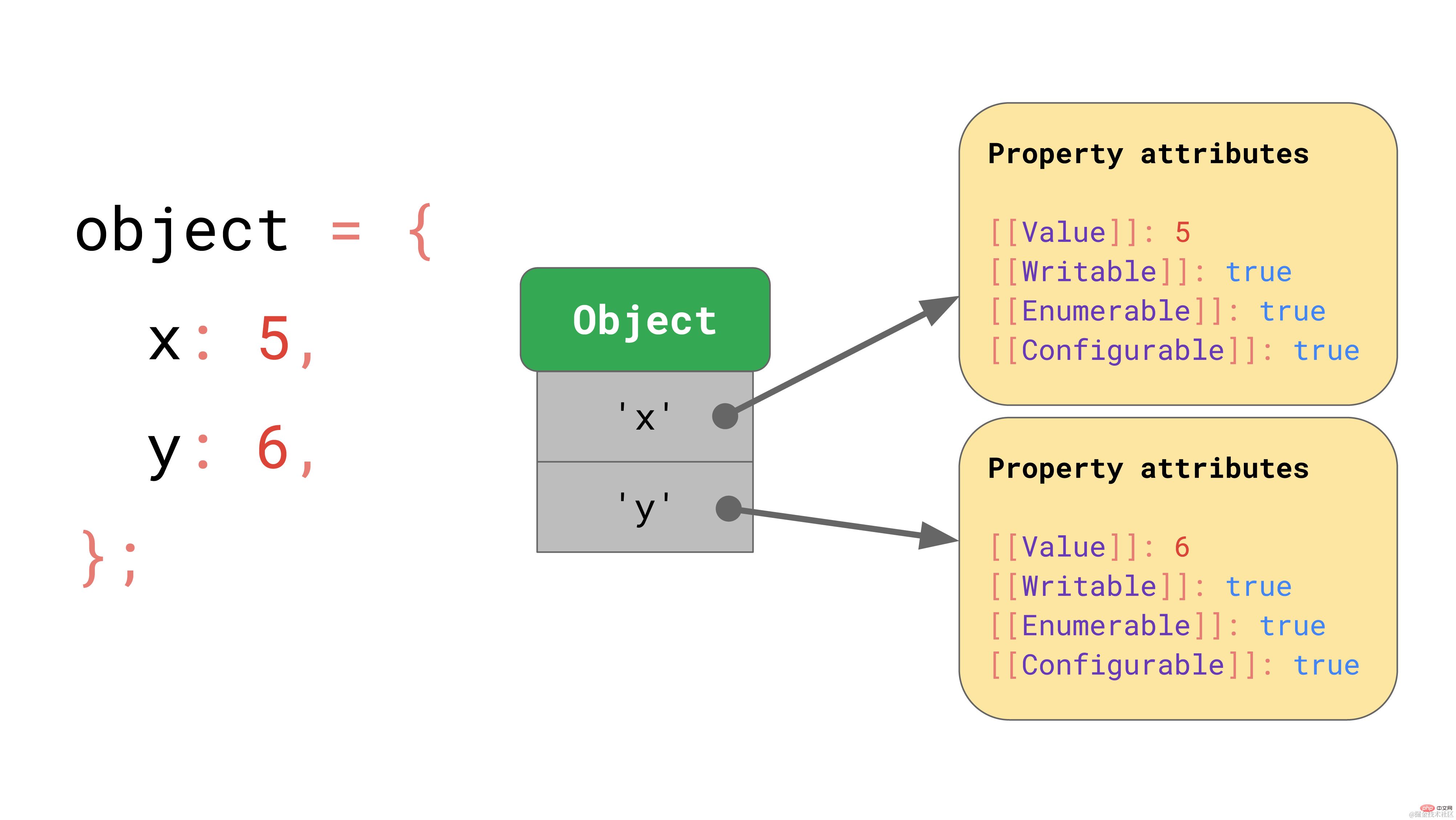
If you access a property, such as object.y, the JavaScript engine will look for the key value 'y' in the JSObject, then load the corresponding property value, and finally return [[Value]].
But where are these attribute values stored in memory? Should we store them as part of JSObject? Assuming that we will encounter more objects of the same shape later, storing a complete dictionary containing property names and property values in the JSObject itself is a waste, because the property names will be repeated for all objects with the same shape. This is a lot of duplication and unnecessary memory usage. As an optimization, the engine stores the object's Shape separately. 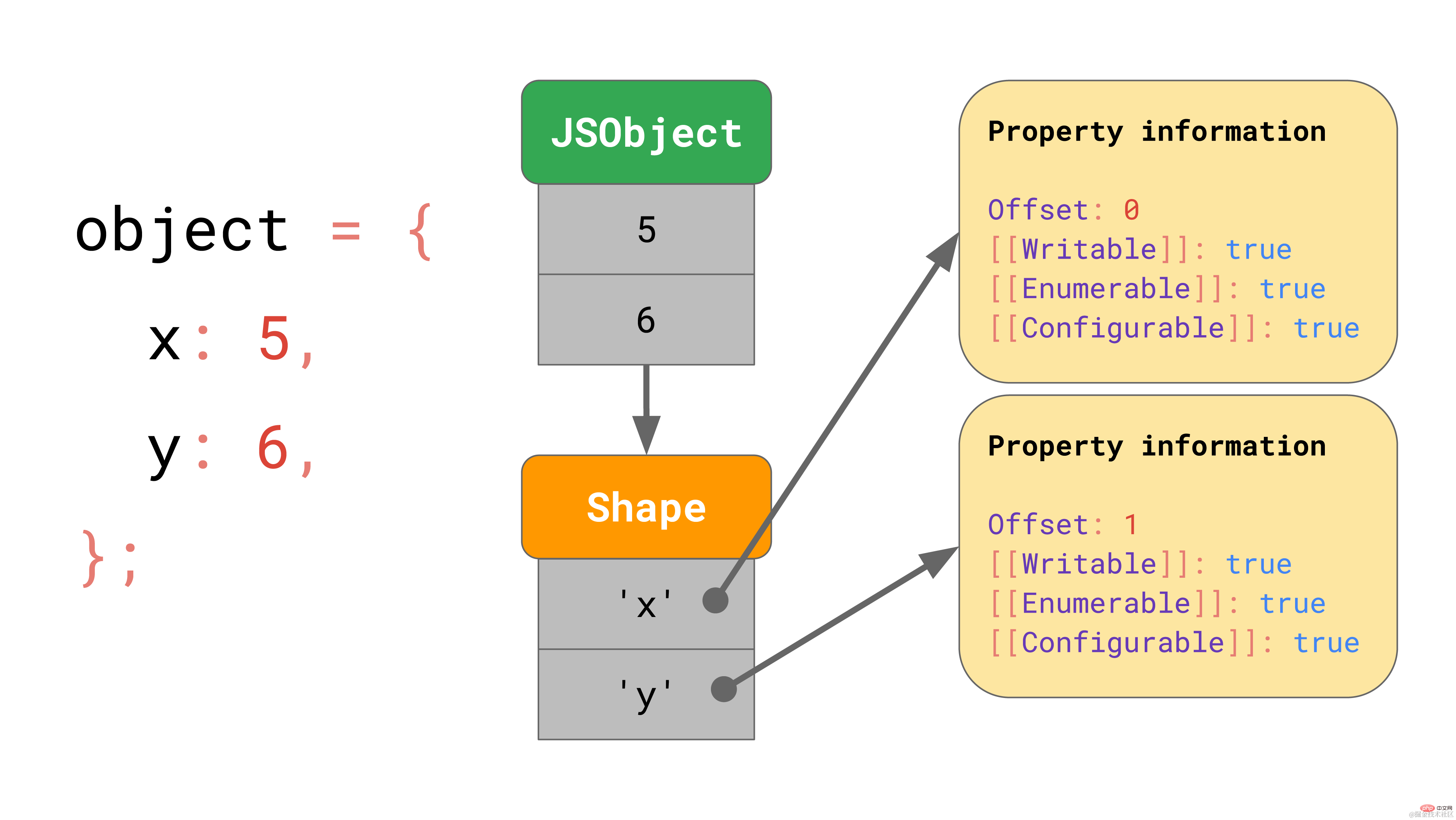 shape contains all attribute names and attributes except [[Value]]. Additionally, the shape contains the offset of the JSObject's internal value so that the JavaScript engine knows where to look for the value. Every JSObject with the same shape points to that shape instance. Now each JSObject only needs to store a value that is unique to that object.
shape contains all attribute names and attributes except [[Value]]. Additionally, the shape contains the offset of the JSObject's internal value so that the JavaScript engine knows where to look for the value. Every JSObject with the same shape points to that shape instance. Now each JSObject only needs to store a value that is unique to that object. 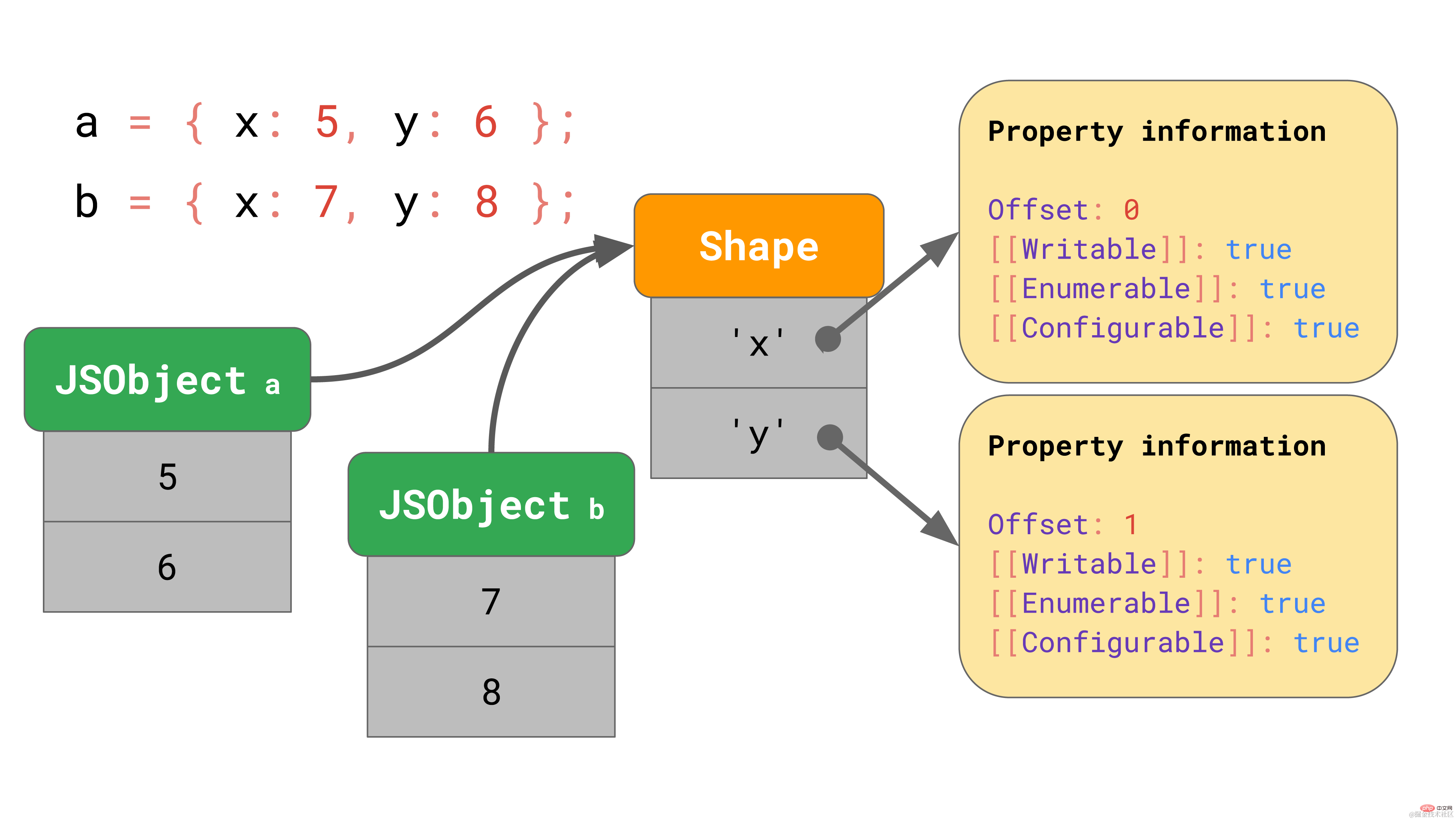 When we have multiple objects, the benefits are obvious. No matter how many objects there are, as long as they have the same shape, we only need to store the shape and attribute information once!
When we have multiple objects, the benefits are obvious. No matter how many objects there are, as long as they have the same shape, we only need to store the shape and attribute information once!
All JavaScript engines use shapes as optimization, but the names are different:
- 学术论文称它们为 Hidden Classes(容易与 JavaScript 中的 class 混淆)
- V8 称它们为 Maps (容易与 JavaScript 中的 Map 混淆)
- Chakra 称它们为 Types (容易与 JavaScript 中的动态类型以及 typeof 混淆)
- JavaScriptCore 称它们为 Structures
- SpiderMonkey 称它们为 Shapes
本文中,我们将继续使用术语 shapes.
转换链和树
如果你有一个具有特定 shape 的对象,但你又向它添加了一个属性,此时会发生什么? JavaScript 引擎是如何找到这个新 shape 的?
const object = {};
object.x = 5;
object.y = 6;复制代码
这些 shapes 在 JavaScript 引擎中形成所谓的转换链(transition chains)。下面是一个例子:
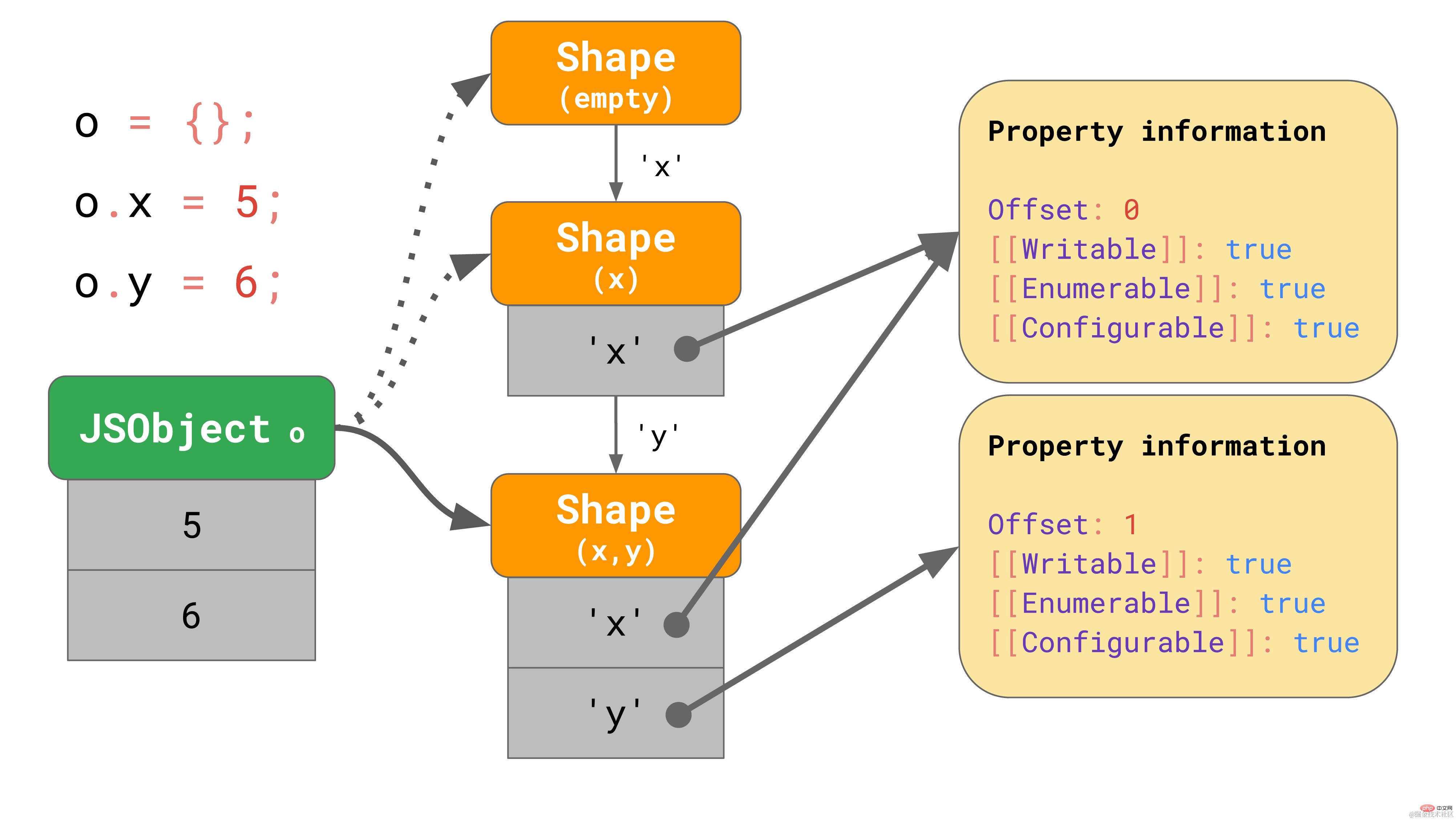
该对象开始没有任何属性,因此它指向一个空的 shape。下一个语句为该对象添加一个值为 5 的属性 "x",所以 JavaScript 引擎转向一个包含属性 "x" 的 shape,并在第一个偏移量为 0 处向 JSObject 添加了一个值 5。 下一行添加了一个属性 'y',引擎便转向另一个包含 'x' 和 'y' 的 shape,并将值 6 添加到 JSObject(位于偏移量 1 处)。
我们甚至不需要为每个 shape 存储完整的属性表。相反,每个shape 只需要知道它引入的新属性。例如,在本例中,我们不必将有关 “x” 的信息存储在最后一个 shape 中,因为它可以在更早的链上找到。要实现这一点,每个 shape 都会链接回其上一个 shape: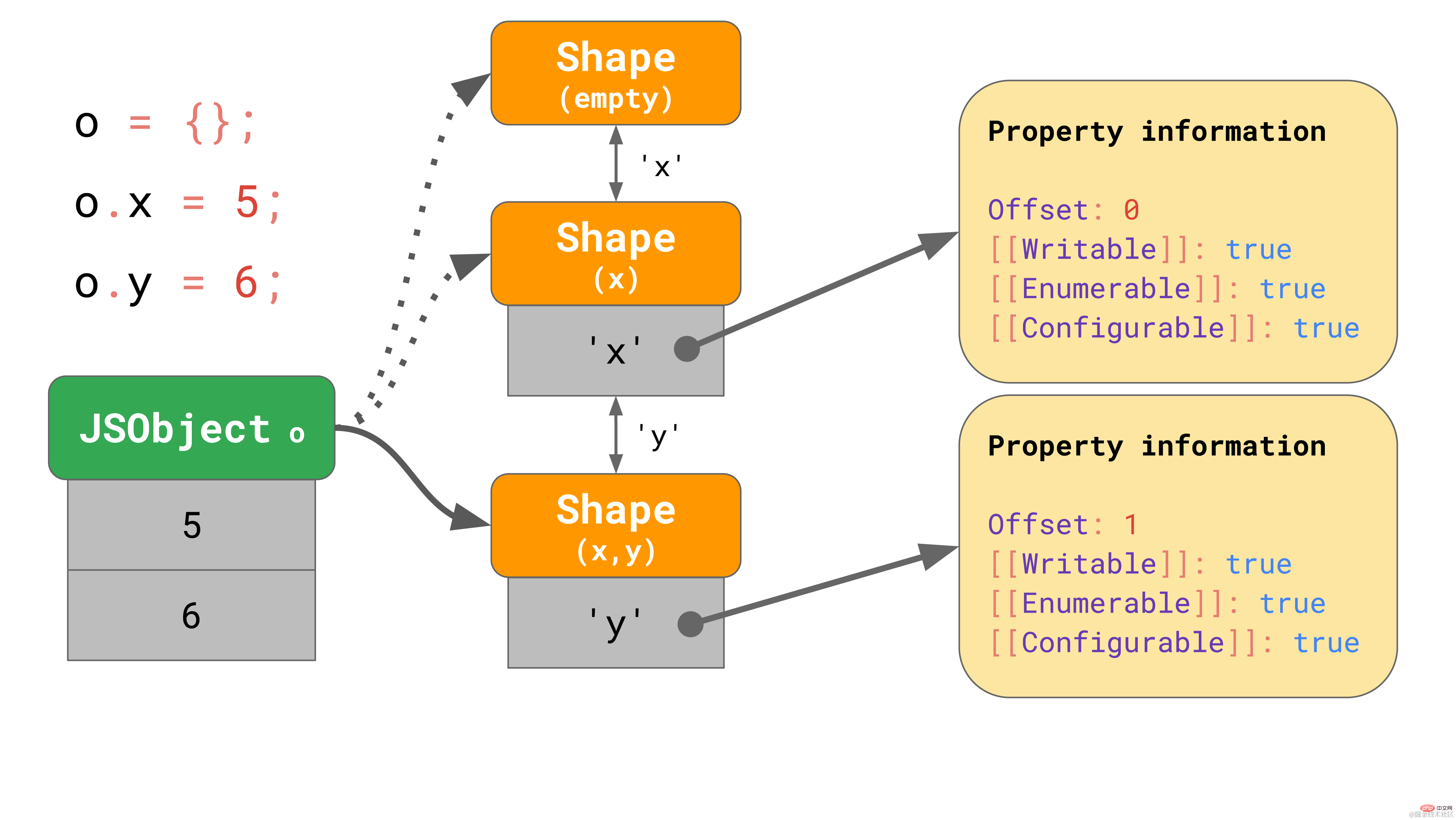
如果你在 JavaScript 代码中写 o.x,JavaScript 引擎会沿着转换链去查找属性 "x",直到找到引入属性 "x" 的 Shape。
但是如果没有办法创建一个转换链会怎么样呢?例如,如果有两个空对象,并且你为每个对象添加了不同的属性,该怎么办?
const object1 = {};
object1.x = 5;const object2 = {};
object2.y = 6;复制代码
在这种情况下,我们必须进行分支操作,最终我们会得到一个转换树而不是转换链。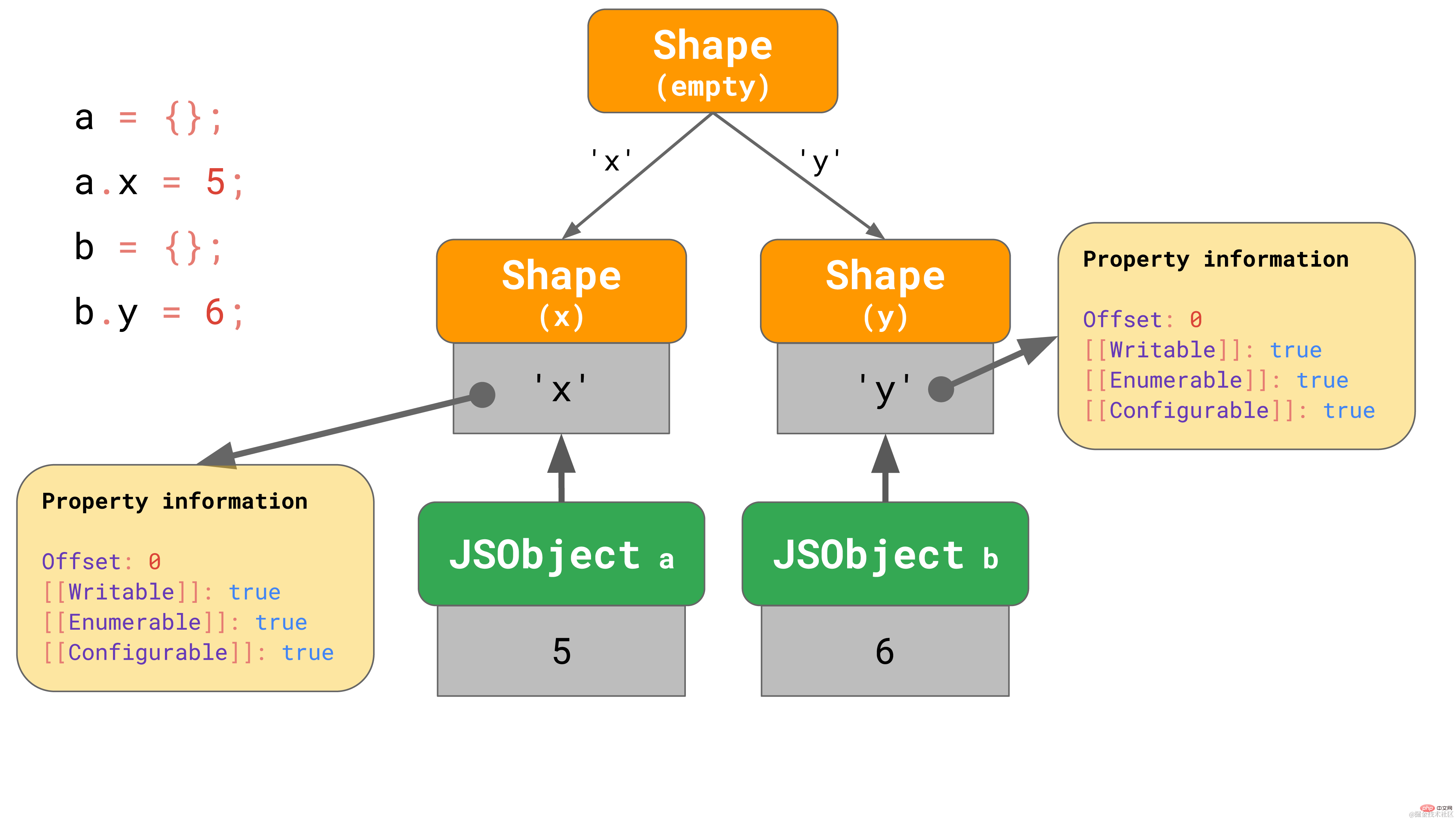
这里,我们创建了一个空对象 a,然后给它添加了一个属性 ‘x’。最终,我们得到了一个包含唯一值的 JSObject 和两个 Shape :空 shape 以及只包含属性 x 的 shape。
第二个例子也是从一个空对象 b 开始的,但是我们给它添加了一个不同的属性 ‘y’。最终,我们得到了两个 shape 链,总共 3 个 shape。
这是否意味着我们总是需要从空 shape 开始呢? 不一定。引擎对已含有属性的对象字面量会进行一些优化。比方说,我们要么从空对象字面量开始添加 x 属性,要么有一个已经包含属性 x 的对象字面量:
const object1 = {};
object1.x = 5;const object2 = { x: 6 };复制代码
在第一个例子中,我们从空 shape 开始,然后转到包含 x 的shape,这正如我们之前所见那样。
在 object2 的例子中,直接在一开始就生成含有 x 属性的对象,而不是生成一个空对象是有意义的。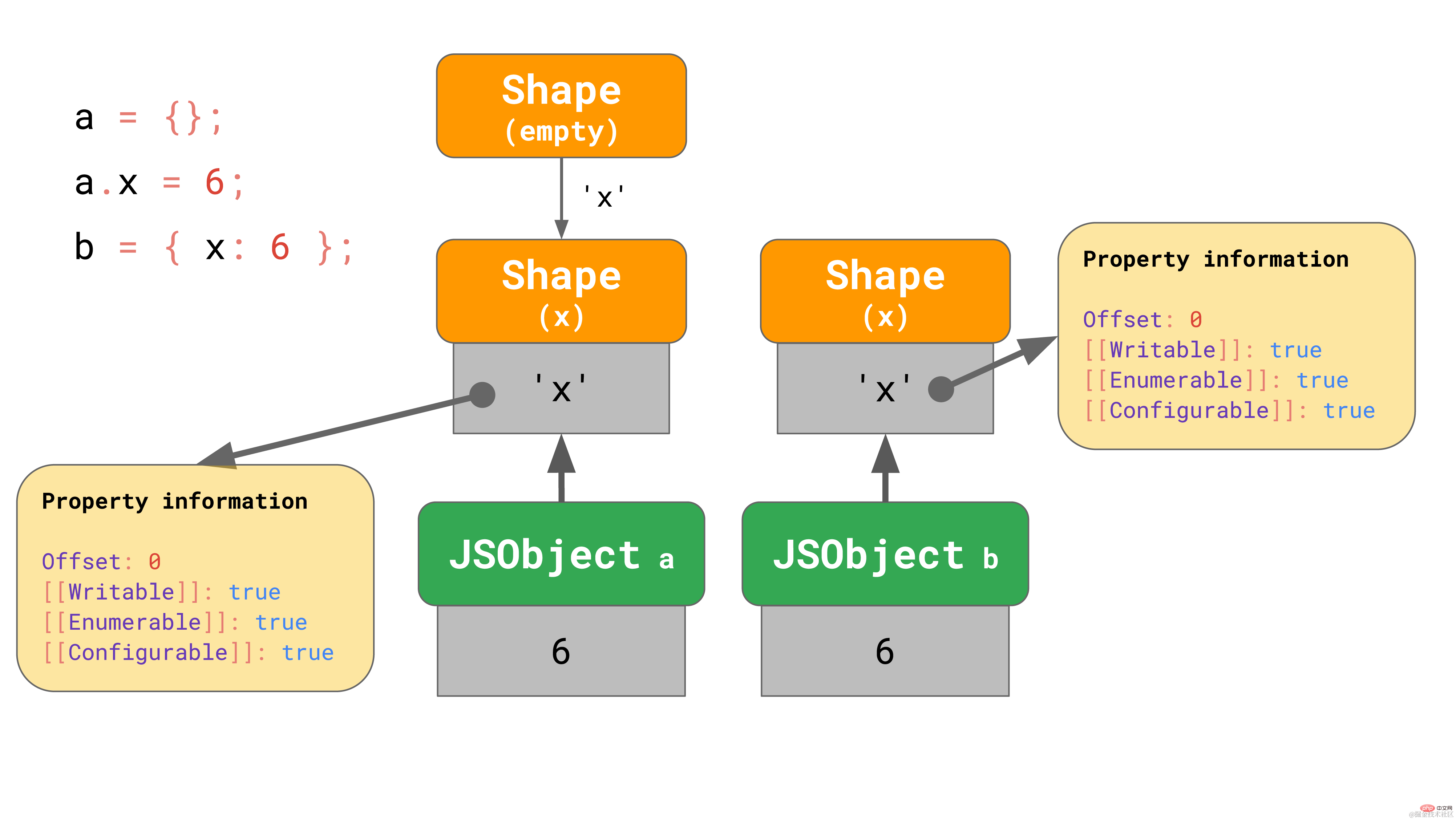
包含属性 ‘x’ 的对象字面量从含有 ‘x’ 的 shape 开始,有效地跳过了空 shape。V8 和 SpiderMonkey (至少)正是这么做的。这种优化缩短了转换链并且使从字面量构建对象更加高效。
下面是一个包含属性 ‘x'、'y' 和 'z' 的 3D 点对象的示例。
const point = {};
point.x = 4;
point.y = 5;
point.z = 6;复制代码
正如我们之前所了解的, 这会在内存中创建一个有3个 shape 的对象(不算空 shape 的话)。 当访问该对象的属性 ‘x’ 的时候,比如, 你在程序里写 point.x,javaScript 引擎需要循着链接列表寻找:它会从底部的 shape 开始,一层层向上寻找,直到找到顶部包含 ‘x’ 的 shape。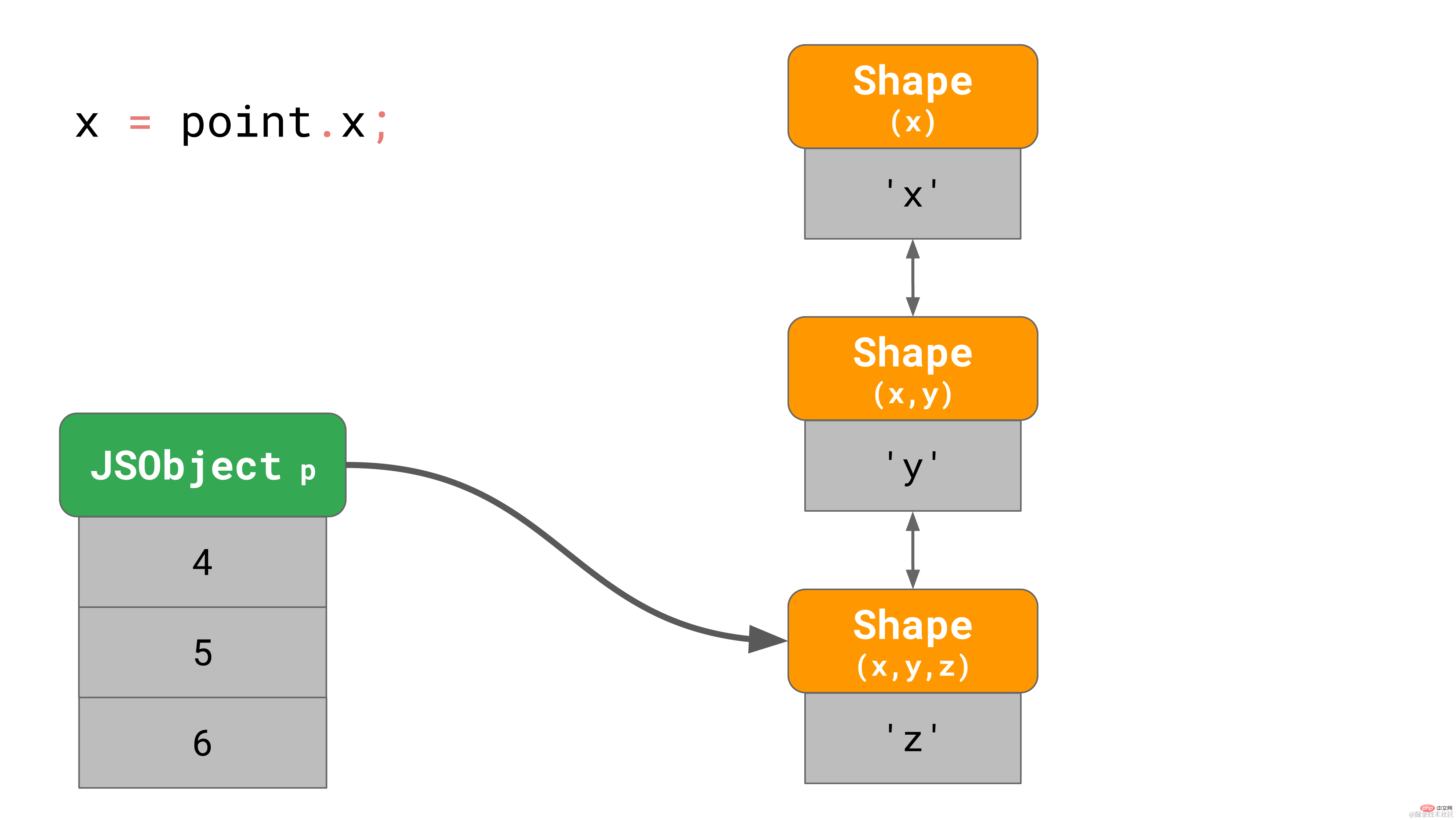
当这样的操作更频繁时, 速度会变得非常慢,特别是当对象有很多属性的时候。寻找属性的时间复杂度为 O(n), 即和对象上的属性数量线性相关。为了加快属性的搜索速度, JavaScript 引擎增加了一种 ShapeTable 的数据结构。这个 ShapeTable 是一个字典,它将属性键映射到描述对应属性的 shape 上。
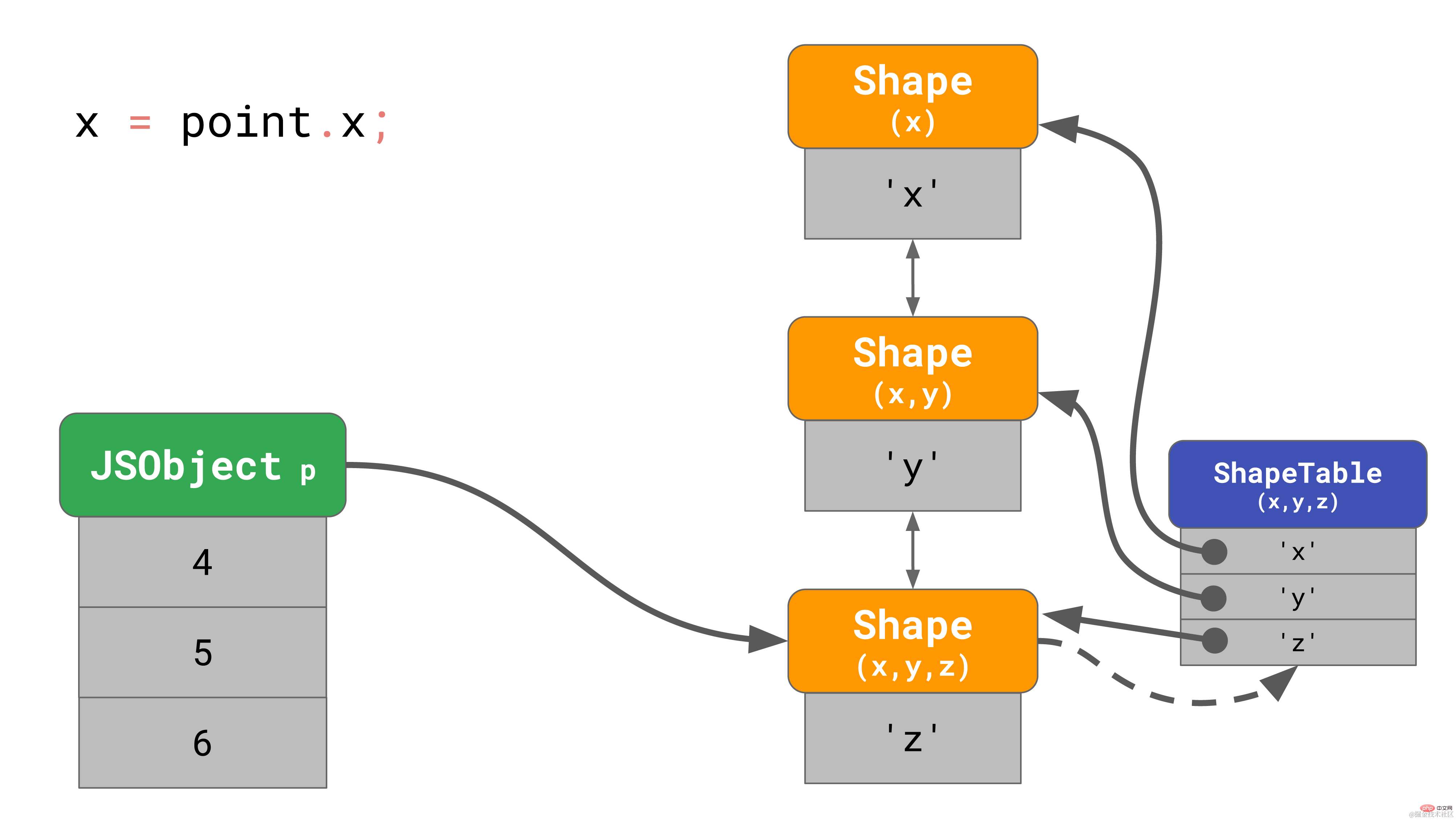
现在我们又回到字典查找了我们添加 shape 就是为了对此进行优化!那我们为什么要去纠结 shape 呢? 原因是 shape 启用了另一种称为 Inline Caches 的优化。
Inline Caches (ICs)
shapes 背后的主要动机是 Inline Caches 或 ICs 的概念。ICs 是让 JavaScript 快速运行的关键要素!JavaScript 引擎使用 ICs 来存储查找到对象属性的位置信息,以减少昂贵的查找次数。
这里有一个函数 getX,该函数接收一个对象并从中加载属性 x:
function getX(o) { return o.x;
}复制代码
如果我们在 JSC 中运行该函数,它会产生以下字节码:
第一条 get_by_id 指令从第一个参数(arg1)加载属性 ‘x’,并将结果存储到 loc0 中。第二条指令将存储的内容返回给 loc0。
JSC 还将一个 Inline Cache 嵌入到 get_by_id 指令中,该指令由两个未初始化的插槽组成。
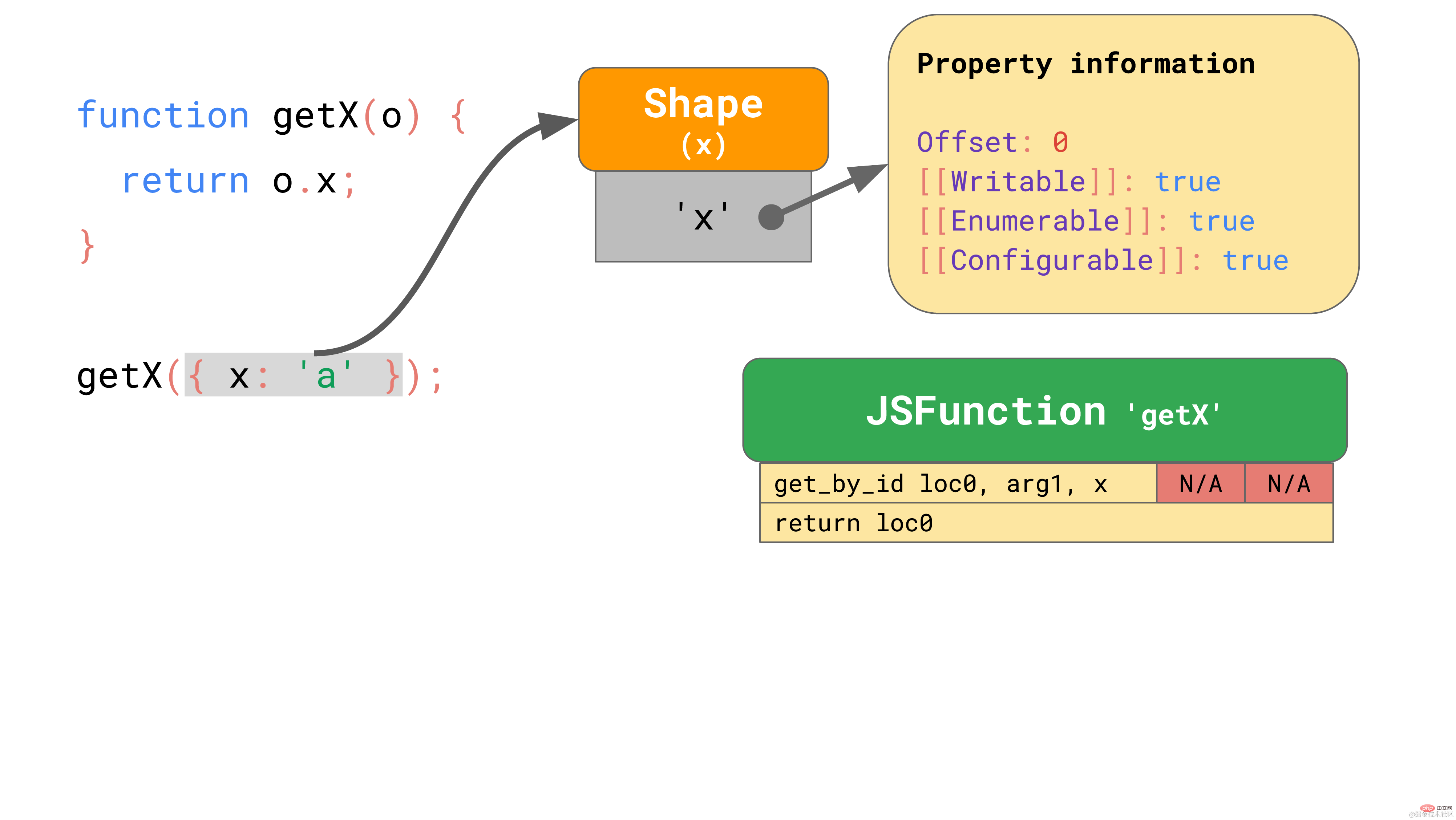 现在, 我们假设用一个对象 { x: 'a' },来执行 getX 这个函数。正如我们所知,,这个对象有一个包含属性 ‘x’ 的 shape, 该 shape存储了属性 ‘x’ 的偏移量和特性。当你在第一次执行这个函数的时候,get_by_id 指令会查找属性 ‘x’,然后发现其值存储在偏移量为 0 的位置。
现在, 我们假设用一个对象 { x: 'a' },来执行 getX 这个函数。正如我们所知,,这个对象有一个包含属性 ‘x’ 的 shape, 该 shape存储了属性 ‘x’ 的偏移量和特性。当你在第一次执行这个函数的时候,get_by_id 指令会查找属性 ‘x’,然后发现其值存储在偏移量为 0 的位置。
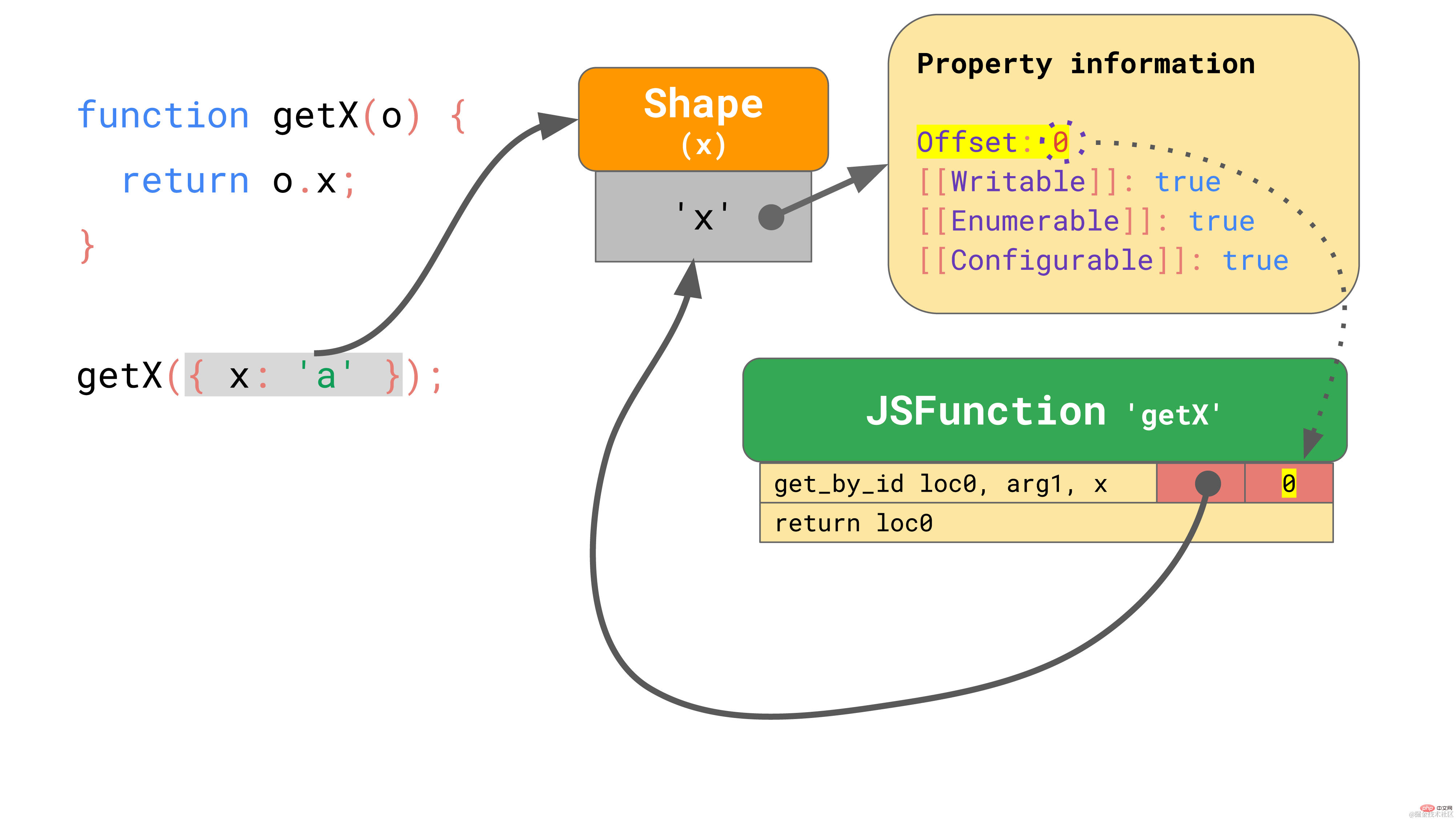
嵌入到 get_by_id 指令中的 IC 存储了 shape 和该属性的偏移量:
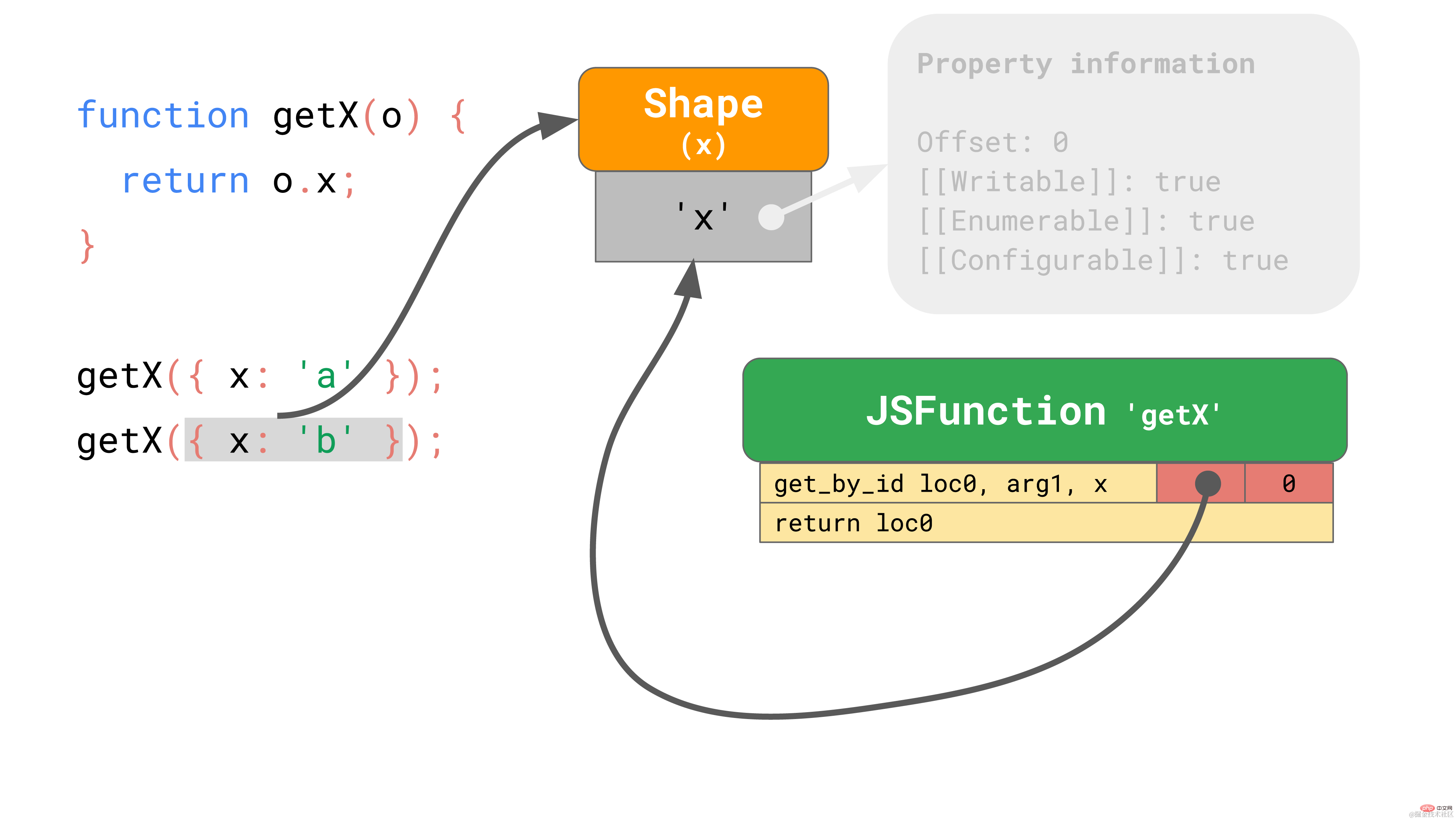
对于后续运行,IC 只需要比较 shape,如果 shape 与之前相同,只需从存储的偏移量加载值。具体来说,如果 JavaScript 引擎看到对象的 shape 是 IC 以前记录过的,那么它根本不需要接触属性信息,相反,可以完全跳过昂贵的属性信息查找过程。这要比每次都查找属性快得多。
高效存储数组
对于数组,存储数组索引属性是很常见的。这些属性的值称为数组元素。为每个数组中的每个数组元素存储属性特性是非常浪费内存的。相反,默认情况下,数组索引属性是可写的、可枚举的和可配置的,JavaScript 引擎基于这一点将数组元素与其他命名属性分开存储。
思考下面的数组:
const array = [ '#jsconfeu', ];复制代码
引擎存储了数组长度(1),并指向包含偏移量和 'length' 属性特性的 shape。
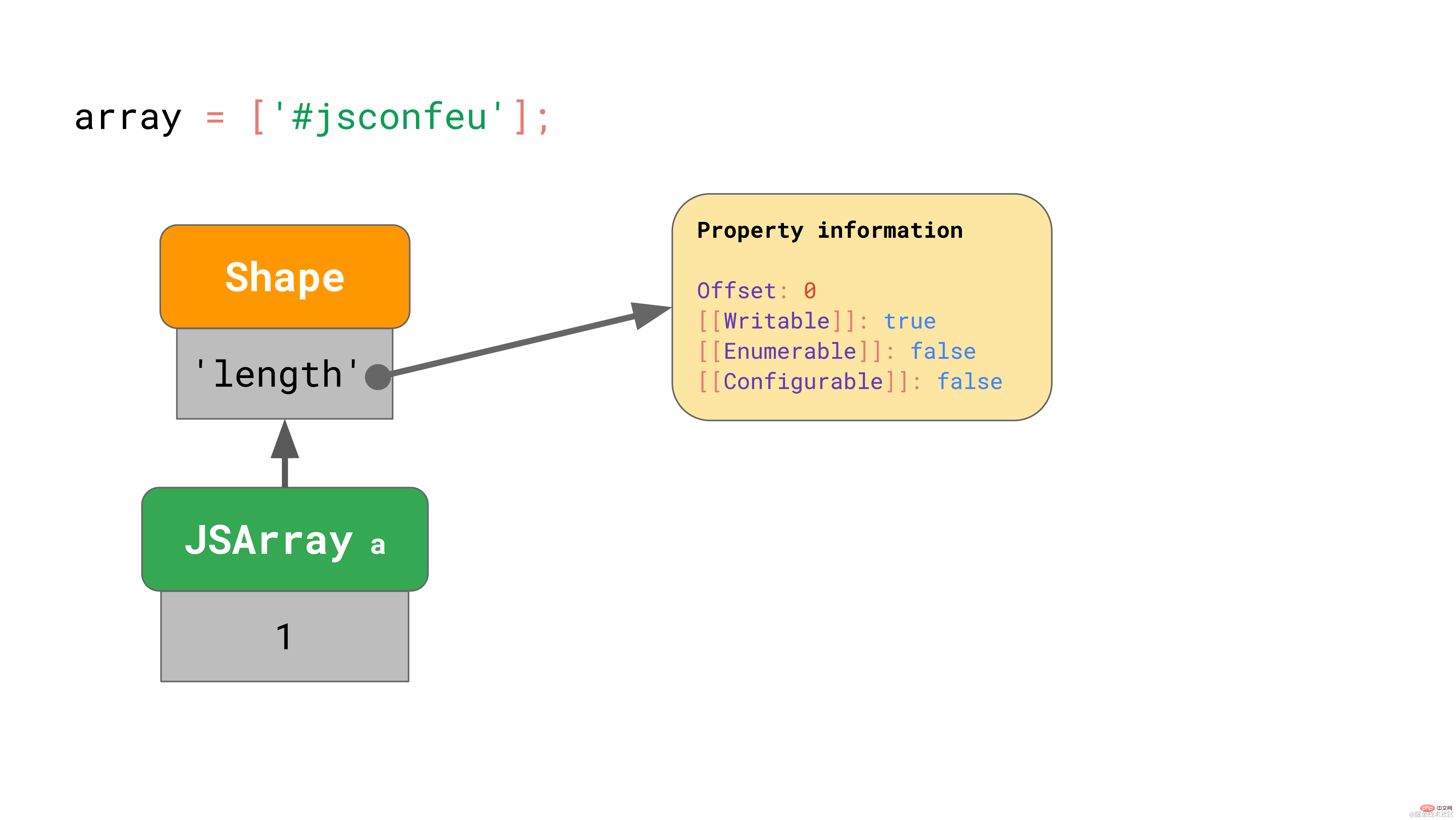
这和我们之前看到的很相似……但是数组的值存到哪里了呢?
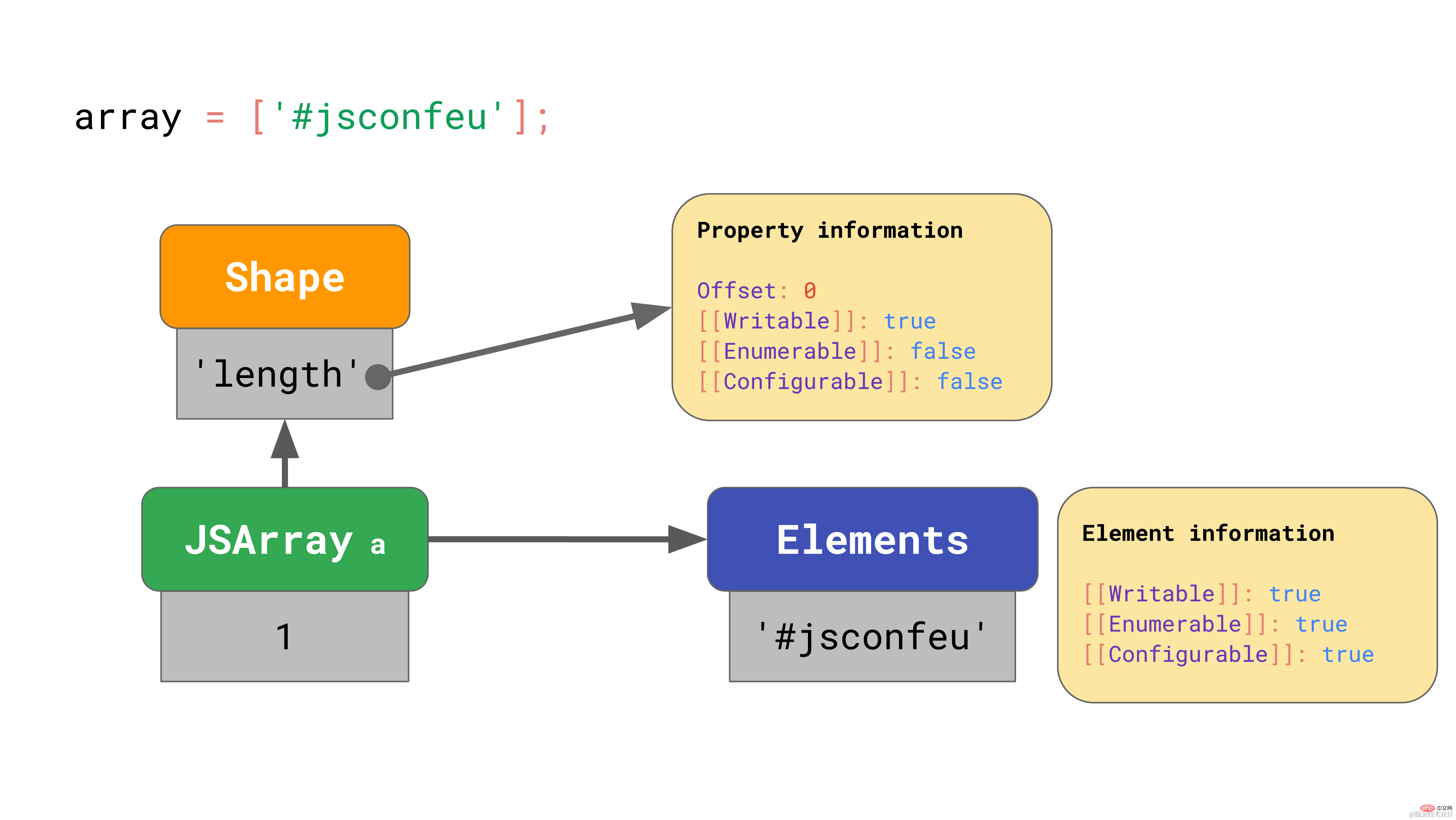
每个数组都有一个单独的元素备份存储区,包含所有数组索引的属性值。JavaScript 引擎不必为数组元素存储任何属性特性,因为它们通常都是可写的、可枚举的和可配置的。
那么,在非通常情况下会怎么样呢?如果更改了数组元素的属性特性,该怎么办?
// Please don’t ever do this!const array = Object.defineProperty(
[], '0',
{
value: 'Oh noes!!1',
writable: false,
enumerable: false,
configurable: false,
});复制代码上面的代码片段定义了名为 “0” 的属性(恰好是数组索引),但将其特性设置为非默认值。
在这种边缘情况下,JavaScript 引擎将整个元素备份存储区表示成一个字典,该字典将数组索引映射到属性特性。
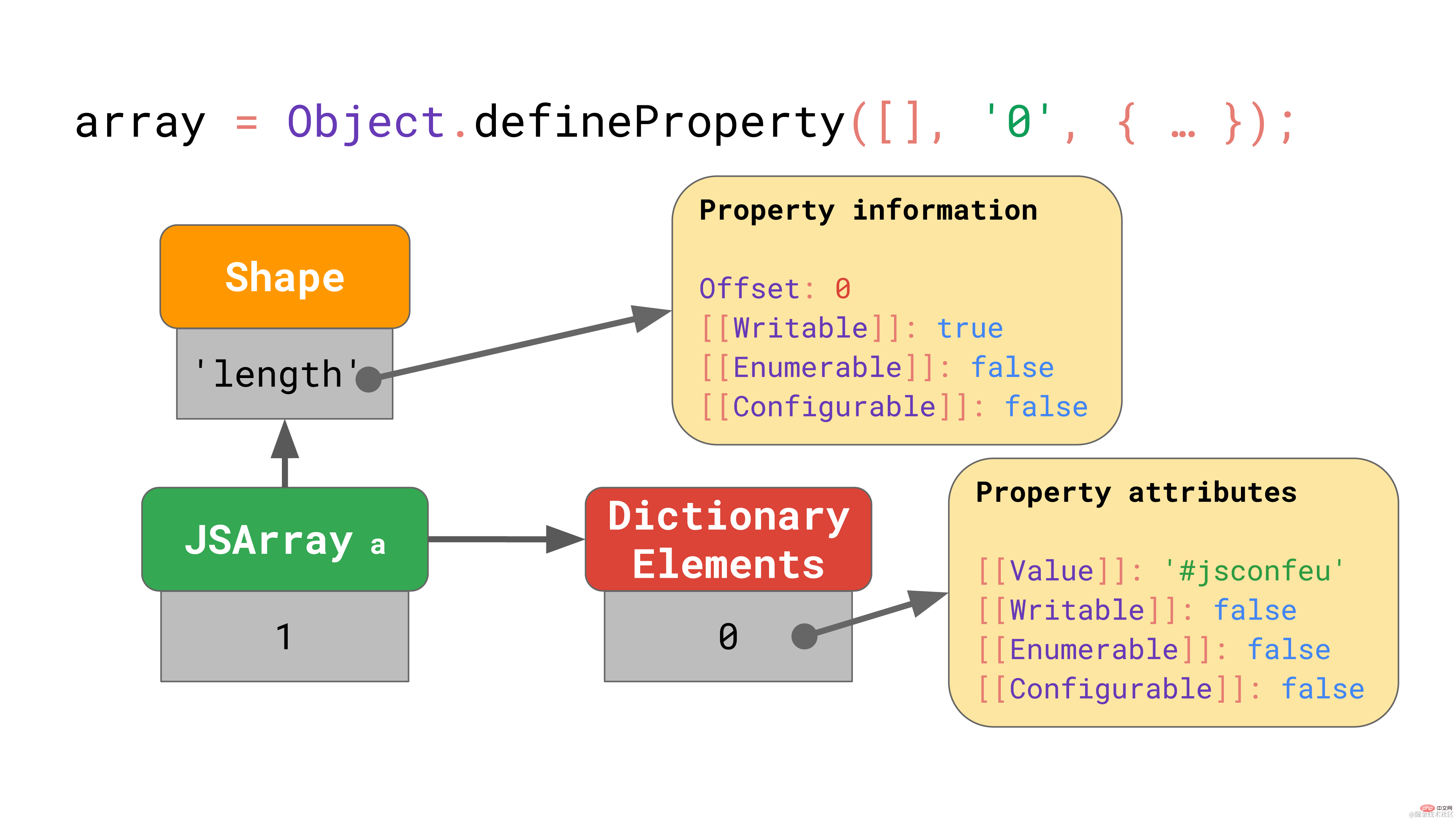
即使只有一个数组元素具有非默认特性,整个数组的备份存储区也会进入这种缓慢而低效的模式。避免对数组索引使用Object.defineProperty!
建议
我们已经了解了 JavaScript 引擎如何存储对象和数组,以及 shape 和 ICs 如何优化对它们的常见操作。基于这些知识,我们确定了一些可以帮助提高性能的实用的 JavaScript 编码技巧:
- Always initialize objects the same way so they don't have different shapes.
- Don't mess with the attribute properties of array elements so they can be stored and manipulated efficiently.
Related free learning recommendations: javascript (Video)
The above is the detailed content of Understand the basic principles of JavaScript engines. For more information, please follow other related articles on the PHP Chinese website!