
Home >Common Problem >What is data mining?
What is data mining?

- 青灯夜游Original
- 2020-07-24 11:53:148280browse
Data Mining is the process of extracting potentially useful information that is unknown in advance from a large amount of data. The goal of data mining is to build a decision-making model to predict future behavior based on past action data.
#Data mining refers to the process of searching for information hidden in large amounts of data through algorithms.
Data mining is usually related to computer science and achieves the above goals through many methods such as statistics, online analytical processing, intelligence retrieval, machine learning, expert systems (relying on past rules of thumb) and pattern recognition.
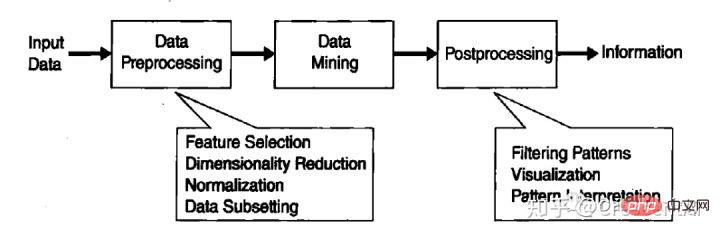
Data mining is an indispensable part of knowledge discovery in database (KDD), and KDD is the entire process of converting raw data into useful information. This process includes a series of conversion steps. From data pre-processing to post-processing of data mining results.
The Origin of Data Mining
Researchers from different disciplines came together and began to develop tools that could handle different data types. More efficient, scalable tools. These works are based on the methodologies and algorithms previously used by researchers, and culminate in the field of data mining.
In particular, data mining utilizes ideas from the following fields: (1) sampling, estimation, and hypothesis testing from statistics; (2) search algorithm modeling of artificial intelligence, pattern recognition, and machine learning Technology and learning theory.
Data mining has also rapidly embraced ideas from other fields, including optimization, evolutionary computation, information theory, signal processing, visualization, and information retrieval.
Some other areas also play an important supporting role. Database systems provide efficient storage, indexing, and query processing support. Technologies derived from high-performance (parallel) computing are often important in processing massive data sets. Distributed technologies can also help with processing massive amounts of data, and are even more critical when data cannot be processed centrally.

KDD(Knowledge Discovery from Database)
-
Data cleaning
Eliminate noise and inconsistent data;
-
Data integration
Multiple data sources can be combined together;
-
Data selection
Extract data related to analysis tasks from the database;
-
Data transformation
Transform and unify the data into data suitable for mining through summary or aggregation operations Form;
-
Data mining
Basic steps, using intelligent methods to extract data patterns;
-
Pattern evaluation
Identify truly interesting patterns representing knowledge based on a certain degree of interest;
-
Knowledge Representation
Use visualization and knowledge representation technology to provide users with mined knowledge .

Data mining methodology
-
Business understanding
Understand the goals and requirements of the project from a business perspective, and then transform this understanding into operational problems for data mining through theoretical analysis, and formulate a preliminary plan to achieve the goals;
-
Data understanding
The data understanding phase begins with the collection of raw data, then becomes familiar with the data, identifies data quality issues, explores a preliminary understanding of the data, and discovers interesting subsets to formulate Hypotheses for exploring information;
-
Data preparation
The data preparation stage refers to the activity of constructing the information required for data mining from the unprocessed data in the original raw data. . Data preparation tasks may be performed multiple times without any prescribed order. The main purpose of these tasks is to obtain the required information from the source system according to the requirements of dimensional analysis, which requires data preprocessing such as conversion, cleaning, construction, and integration of data;
-
Modeling
At this stage, it is mainly about selecting and applying various modeling techniques. At the same time, their parameters are tuned to achieve optimal values. Usually there are multiple modeling techniques for the same data mining problem type. Some technologies have special requirements for data forms, and often need to return to the data preparation stage;
-
Model evaluation (evaluation)
Before model deployment and release, it is necessary to start from At the technical level, judge the effect of the model and examine each step of building the model, as well as evaluate the practicability of the model in actual business scenarios based on business goals. The key purpose of this stage is to determine whether there are some important business issues that have not been fully considered;
-
Model deployment (deployment)
After the model is completed, the (Customer) Based on the current background and goal completion status, the package meets the business system usage needs.
Data mining tasks
Generally, data mining tasks are divided into the following two categories.
Prediction task. The goal of these tasks is to predict the value of a specific attribute based on the value of other attributes. The attributes being predicted are generally called target variables or dependent variables, and the attributes used for prediction are called explanatory variables or independent variables.
-
Describe the task. The goal is to derive patterns (correlations, trends, clusters, trajectories, and anomalies) that summarize underlying connections in the data. Descriptive data mining tasks are often exploratory in nature and often require post-processing techniques to verify and interpret the results.

Predictive modeling (predictive modeling) Involves building a model for the target variable by explaining the function of the variable.
There are two types of predictive modeling tasks: classification, used to predict discrete target variables; regression, used to predict continuous target variables.
For example, predicting whether a Web user will buy a book in an online bookstore is a classification task because the target variable is binary, while predicting the future price of a stock is a regression task because the price has continuous value attributes.
The goal of both tasks is to train a model to minimize the error between the predicted value and the actual value of the target variable. Predictive modeling can be used to determine customer responses to product promotions, predict disturbances in Earth's ecosystems, or determine whether a patient has a disease based on test results.
Association analysis (association analysis) is used to discover patterns that describe strong correlation features in the data.
The discovered patterns are usually expressed in the form of implication rules or subsets of features. Since the search space is exponential in size, the goal of correlation analysis is to extract the most interesting patterns in an efficient manner. Applications of association analysis include finding genomes with related functions, identifying Web pages that users visit together, and understanding the connections between different elements of the Earth's climate system.
Cluster analysis(cluster analysis) aims to find groups of observations that are closely related, so that observations belonging to the same cluster are more similar to each other than observations belonging to different clusters. as similar as possible. Clustering can be used to group related customers, identify areas of the ocean that significantly affect Earth's climate, compress data, and more.
Anomaly detection (anomaly detection) The task is to identify observations whose characteristics are significantly different from other data.
Such observations are called anomalies or outliers. The goal of anomaly detection algorithms is to discover real anomalies and avoid mistakenly labeling normal objects as anomalies. In other words, a good anomaly detector must have a high detection rate and a low false alarm rate.
Applications of anomaly detection include detecting fraud, cyberattacks, unusual patterns of disease, ecosystem disturbances, and more.
For more related knowledge, please visit: PHP Chinese website!
The above is the detailed content of What is data mining?. For more information, please follow other related articles on the PHP Chinese website!