
 Web Front-endJS TutorialNodejs practical experience: eventproxy module controls concurrency_node.js
Web Front-endJS TutorialNodejs practical experience: eventproxy module controls concurrency_node.js
Goal
Create a lesson4 project and write code in it.
The entry point of the code is app.js. When node app.js is called, it will output the titles, links and chapters of all topics on the CNode (https://cnodejs.org/) community homepage. A comment, in json format.
Output example:
[
{
"title": "【公告】发招聘帖的同学留意一下这里",
"href": "http://cnodejs.org/topic/541ed2d05e28155f24676a12",
"comment1": "呵呵呵呵"
},
{
"title": "发布一款 Sublime Text 下的 JavaScript 语法高亮插件",
"href": "http://cnodejs.org/topic/54207e2efffeb6de3d61f68f",
"comment1": "沙发!"
}
]
Challenge
Based on the above goal, output the author of comment1 and his points value in the cnode community.
Example:
[
{
"title": "【公告】发招聘帖的同学留意一下这里",
"href": "http://cnodejs.org/topic/541ed2d05e28155f24676a12",
"comment1": "呵呵呵呵",
"author1": "auser",
"score1": 80
},
...
]
Knowledge Points
Experience the beauty of Node.js’ callback hell
Learn to use eventproxy, a tool to control concurrency
Course content
In this chapter we come to the most awesome part of Node.js - asynchronous concurrency.
In the previous lesson, we introduced how to use superagent and cheerio to get the homepage content. It only needs to initiate an http get request. But this time, we need to retrieve the first comment of each topic, which requires us to initiate a request for the link of each topic and use cheerio to retrieve the first comment.
CNode currently has 40 topics per page, so we need to initiate 1 40 requests to achieve our goal in this lesson.
We initiated the latter 40 requests concurrently :), and we will not encounter multi-threading or locking. The concurrency model of Node.js is different from multi-threading, so abandon those concepts. To be more specific, I won't go into scientific issues such as why asynchronous is asynchronous and why Node.js can be single-threaded but concurrent. For students who are interested in this aspect, I highly recommend @puling's "Nine Lights and One Deep Node.js": http://book.douban.com/subject/25768396/.
Some friends who are more sophisticated may have heard of concepts such as promises and generators. But as for me, I can only talk about callbacks. The main reason is that I personally only like callbacks.
We need to use three libraries for this course: superagent cheerio eventproxy(https://github.com/JacksonTian/eventproxy )
You can do the scaffolding work yourself, and we will write the program together step by step.
First app.js should look like this
var eventproxy = require('eventproxy');
var superagent = require('superagent');
var cheerio = require('cheerio');
// url 模块是 Node.js 标准库里面的
// http://nodejs.org/api/url.html
var url = require('url');
var cnodeUrl = 'https://cnodejs.org/';
superagent.get(cnodeUrl)
.end(function (err, res) {
if (err) {
return console.error(err);
}
var topicUrls = [];
var $ = cheerio.load(res.text);
// 获取首页所有的链接
$('#topic_list .topic_title').each(function (idx, element) {
var $element = $(element);
// $element.attr('href') 本来的样子是 /topic/542acd7d5d28233425538b04
// 我们用 url.resolve 来自动推断出完整 url,变成
// https://cnodejs.org/topic/542acd7d5d28233425538b04 的形式
// 具体请看 http://nodejs.org/api/url.html#url_url_resolve_from_to 的示例
var href = url.resolve(cnodeUrl, $element.attr('href'));
topicUrls.push(href);
});
console.log(topicUrls);
});
Run node app.js
The output is as shown below:
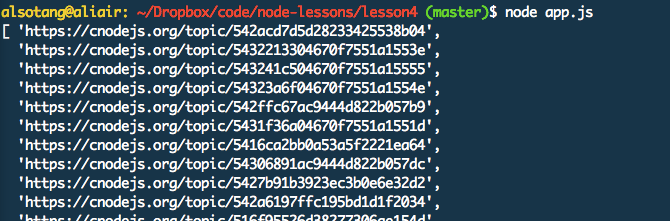
OK, now we have got the addresses of all urls. Next, we crawl all these addresses and we are done. Node.js is that simple.
Before crawling, we still need to introduce the eventproxy library.
Students who have written asynchronously in js should all know that if you want to obtain data from two or three addresses concurrently and asynchronously, and after obtaining the data, use these data together, the conventional way of writing is to maintain one yourself counter.
First define a var count = 0, and then count every time the crawl is successful. If you want to capture data from three sources, since you don’t know who will complete these asynchronous operations first, then every time the capture is successful, check count === 3. When the value is true, use another function to continue the operation.
Eventproxy plays the role of this counter. It helps you manage whether these asynchronous operations are completed. After completion, it will automatically call the processing function you provided and pass the captured data as parameters.
Assuming that we do not use eventproxy or counters, the way to capture three sources is as follows:
// Refer to jquery’s $.get method
$.get("http://data1_source", function (data1) {
// something
$.get("http://data2_source", function (data2) {
// something
$.get("http://data3_source", function (data3) {
// something
var html = fuck(data1, data2, data3);
render(html);
});
});
});
Everyone has written the above code. First get data1, then get data2, then get data3, then fuck them and output.
But everyone should have thought that in fact, the data from these three sources can be obtained in parallel. The acquisition of data2 does not depend on the completion of data1, and similarly, data3 does not depend on data2.
So we use a counter to write it, and it will be written like this:
(function () {
var count = 0;
var result = {};
$.get('http://data1_source', function (data) {
result.data1 = data;
count++;
handle();
});
$.get('http://data2_source', function (data) {
result.data2 = data;
count++;
handle();
});
$.get('http://data3_source', function (data) {
result.data3 = data;
count++;
handle();
});
function handle() {
if (count === 3) {
var html = fuck(result.data1, result.data2, result.data3);
render(html);
}
}
})();
Even though it’s ugly, it’s not that ugly. The main thing is that the code I write looks good.
If we use eventproxy, it would be written like this:
var ep = new eventproxy();
ep.all('data1_event', 'data2_event', 'data3_event', function (data1, data2, data3) {
var html = fuck(data1, data2, data3);
render(html);
});
$.get('http://data1_source', function (data) {
ep.emit('data1_event', data);
});
$.get('http://data2_source', function (data) {
ep.emit('data2_event', data);
});
$.get('http://data3_source', function (data) {
ep.emit('data3_event', data);
});
It looks much better, right? It’s just an advanced counter.
ep.all('data1_event', 'data2_event', 'data3_event', function (data1, data2, data3) {});
这一句,监听了三个事件,分别是 data1_event, data2_event, data3_event,每次当一个源的数据抓取完成时,就通过 ep.emit() 来告诉 ep 自己,某某事件已经完成了。
当三个事件未同时完成时,ep.emit() 调用之后不会做任何事;当三个事件都完成的时候,就会调用末尾的那个回调函数,来对它们进行统一处理。
eventproxy 提供了不少其他场景所需的 API,但最最常用的用法就是以上的这种,即:
先 var ep = new eventproxy(); 得到一个 eventproxy 实例。
告诉它你要监听哪些事件,并给它一个回调函数。ep.all('event1', 'event2', function (result1, result2) {})。
在适当的时候 ep.emit('event_name', eventData)。
eventproxy 这套处理异步并发的思路,我一直觉得就像是汇编里面的 goto 语句一样,程序逻辑在代码中随处跳跃。本来代码已经执行到 100 行了,突然 80 行的那个回调函数又开始工作了。如果你异步逻辑复杂点的话,80 行的这个函数完成之后,又激活了 60 行的另外一个函数。并发和嵌套的问题虽然解决了,但老祖宗们消灭了几十年的 goto 语句又回来了。
至于这套思想糟糕不糟糕,我个人倒是觉得还是不糟糕,用熟了看起来蛮清晰的。不过 js 这门渣渣语言本来就乱嘛,什么变量提升(http://www.cnblogs.com/damonlan/archive/2012/07/01/2553425.html )啊,没有 main 函数啊,变量作用域啊,数据类型常常简单得只有数字、字符串、哈希、数组啊,这一系列的问题,都不是事儿。
编程语言美丑啥的,咱心中有佛就好。
回到正题,之前我们已经得到了一个长度为 40 的 topicUrls 数组,里面包含了每条主题的链接。那么意味着,我们接下来要发出 40 个并发请求。我们需要用到 eventproxy 的 #after API。
大家自行学习一下这个 API 吧:https://github.com/JacksonTian/eventproxy#%E9%87%8D%E5%A4%8D%E5%BC%82%E6%AD%A5%E5%8D%8F%E4%BD%9C
我代码就直接贴了哈。
// 得到 topicUrls 之后
// 得到一个 eventproxy 的实例
var ep = new eventproxy();
// 命令 ep 重复监听 topicUrls.length 次(在这里也就是 40 次) `topic_html` 事件再行动
ep.after('topic_html', topicUrls.length, function (topics) {
// topics 是个数组,包含了 40 次 ep.emit('topic_html', pair) 中的那 40 个 pair
// 开始行动
topics = topics.map(function (topicPair) {
// 接下来都是 jquery 的用法了
var topicUrl = topicPair[0];
var topicHtml = topicPair[1];
var $ = cheerio.load(topicHtml);
return ({
title: $('.topic_full_title').text().trim(),
href: topicUrl,
comment1: $('.reply_content').eq(0).text().trim(),
});
});
console.log('final:');
console.log(topics);
});
topicUrls.forEach(function (topicUrl) {
superagent.get(topicUrl)
.end(function (err, res) {
console.log('fetch ' + topicUrl + ' successful');
ep.emit('topic_html', [topicUrl, res.text]);
});
});
输出长这样:
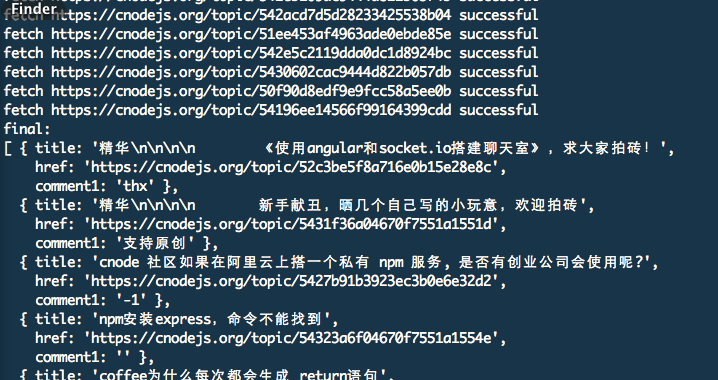
完整的代码请查看 lesson4 目录下的 app.js 文件
总结
今天介绍的 eventproxy 模块是控制并发用的,有时我们需要同时发送 N 个 http 请求,然后利用得到的数据进行后期的处理工作,如何方便地判断数据已经全部并发获取得到,就可以用到该模块了。而模块不仅可以在服务端使用,也可以应用在客户端

 Replace String Characters in JavaScriptMar 11, 2025 am 12:07 AM
Replace String Characters in JavaScriptMar 11, 2025 am 12:07 AMDetailed explanation of JavaScript string replacement method and FAQ This article will explore two ways to replace string characters in JavaScript: internal JavaScript code and internal HTML for web pages. Replace string inside JavaScript code The most direct way is to use the replace() method: str = str.replace("find","replace"); This method replaces only the first match. To replace all matches, use a regular expression and add the global flag g: str = str.replace(/fi
 Custom Google Search API Setup TutorialMar 04, 2025 am 01:06 AM
Custom Google Search API Setup TutorialMar 04, 2025 am 01:06 AMThis tutorial shows you how to integrate a custom Google Search API into your blog or website, offering a more refined search experience than standard WordPress theme search functions. It's surprisingly easy! You'll be able to restrict searches to y
 8 Stunning jQuery Page Layout PluginsMar 06, 2025 am 12:48 AM
8 Stunning jQuery Page Layout PluginsMar 06, 2025 am 12:48 AMLeverage jQuery for Effortless Web Page Layouts: 8 Essential Plugins jQuery simplifies web page layout significantly. This article highlights eight powerful jQuery plugins that streamline the process, particularly useful for manual website creation
 Build Your Own AJAX Web ApplicationsMar 09, 2025 am 12:11 AM
Build Your Own AJAX Web ApplicationsMar 09, 2025 am 12:11 AMSo here you are, ready to learn all about this thing called AJAX. But, what exactly is it? The term AJAX refers to a loose grouping of technologies that are used to create dynamic, interactive web content. The term AJAX, originally coined by Jesse J
 What is 'this' in JavaScript?Mar 04, 2025 am 01:15 AM
What is 'this' in JavaScript?Mar 04, 2025 am 01:15 AMCore points This in JavaScript usually refers to an object that "owns" the method, but it depends on how the function is called. When there is no current object, this refers to the global object. In a web browser, it is represented by window. When calling a function, this maintains the global object; but when calling an object constructor or any of its methods, this refers to an instance of the object. You can change the context of this using methods such as call(), apply(), and bind(). These methods call the function using the given this value and parameters. JavaScript is an excellent programming language. A few years ago, this sentence was
 10 Mobile Cheat Sheets for Mobile DevelopmentMar 05, 2025 am 12:43 AM
10 Mobile Cheat Sheets for Mobile DevelopmentMar 05, 2025 am 12:43 AMThis post compiles helpful cheat sheets, reference guides, quick recipes, and code snippets for Android, Blackberry, and iPhone app development. No developer should be without them! Touch Gesture Reference Guide (PDF) A valuable resource for desig
 Improve Your jQuery Knowledge with the Source ViewerMar 05, 2025 am 12:54 AM
Improve Your jQuery Knowledge with the Source ViewerMar 05, 2025 am 12:54 AMjQuery is a great JavaScript framework. However, as with any library, sometimes it’s necessary to get under the hood to discover what’s going on. Perhaps it’s because you’re tracing a bug or are just curious about how jQuery achieves a particular UI
 How do I create and publish my own JavaScript libraries?Mar 18, 2025 pm 03:12 PM
How do I create and publish my own JavaScript libraries?Mar 18, 2025 pm 03:12 PMArticle discusses creating, publishing, and maintaining JavaScript libraries, focusing on planning, development, testing, documentation, and promotion strategies.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

WebStorm Mac version
Useful JavaScript development tools

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

