
Detailed explanation of RDB persistence in redis

- 尚forward
- 2019-11-30 16:08:462175browse
Compared with other caching products such as Memcache, Redis has an obvious advantage in that Redis not only supports simple key-value type data, but also provides list, set, and zset. , storage of data structures such as hash. We have spent two articles introducing these rich data types in detail. Next, we will introduce another major advantage of Redis - persistence. (Recommended: redis video tutorial)
Since Redis is an in-memory database, the so-called in-memory database means to store the contents of the database in memory, which is related to traditional MySQL, Oracle, etc. Compared with traditional databases that directly save content to the hard disk, the read and write efficiency of an in-memory database is much faster than that of a traditional database (the read and write efficiency of the memory is much greater than the read and write efficiency of the hard disk). However, saving it in memory also brings a disadvantage. Once the power is cut off or the computer is down, all the data in the memory database will be lost.
In order to solve this shortcoming, Redis provides the function of persisting memory data to the hard disk and using persistent files to restore database data. Redis supports two forms of persistence, one is RDB snapshotting (snapshotting) and the other is AOF (append-only-file). This blog first introduces RDB snapshots.
1. Introduction to RDB
RDB is a method used by Redis for persistence. It is a snapshot of the data set currently in memory. Write to disk, that is, Snapshot snapshot (all key-value pair data in the database). During recovery, the snapshot file is read directly into memory.
Back to top
2. Triggering method
RDB has two triggering methods, namely automatic triggering and manual triggering.
①, Automatically trigger
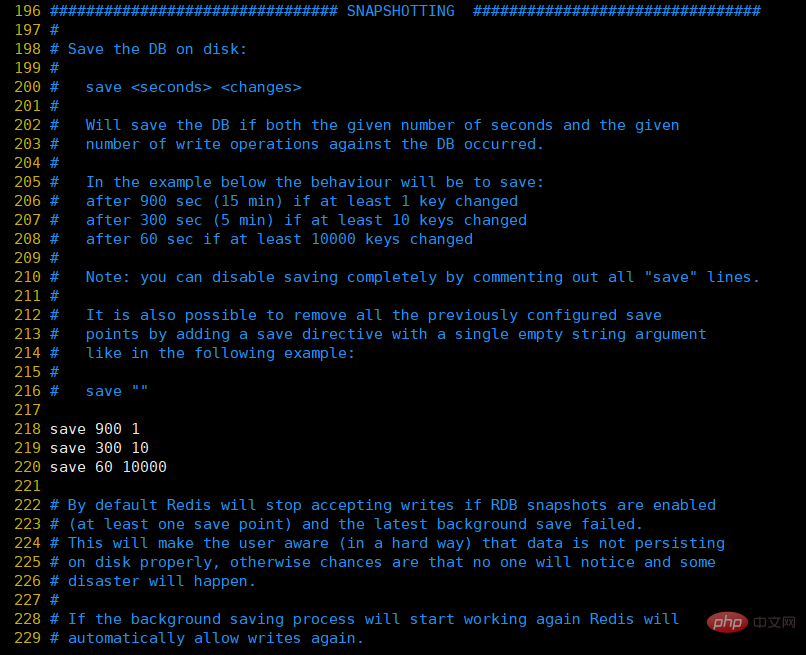
Under SNAPSHOTTING in the redis.conf configuration file
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存 save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存 save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存Of course, if you If you are just using the caching function of Redis and do not need persistence, you can comment out all save lines to disable the saving function. You can directly use an empty string to achieve deactivation: save ""②, stop-writes-on-bgsave-error: The default value is yes. When RDB is enabled and the last background save of data fails, whether Redis stops receiving data. This would make the user aware that the data was not persisted to disk correctly, otherwise no one would notice that a disaster had occurred. If Redis restarts, it can start receiving data again③, rdbcompression; the default value is yes. For snapshots stored on disk, you can set whether to compress them for storage. If so, redis will use the LZF algorithm for compression. If you don't want to consume CPU for compression, you can set this feature to off, but the snapshots stored on disk will be larger. ④, rdbchecksum: The default value is yes. After storing the snapshot, we can also let redis use the CRC64 algorithm for data verification, but this will increase performance consumption by about 10%. If you want to get the maximum performance improvement, you can turn off this function. ⑤, dbfilename: Set the file name of the snapshot, the default is dump.rdb⑥, dir: Set the storage path of the snapshot file, this configuration item must be a directory, not a file name . The default is to save it in the same directory as the current configuration file. That is to say, through the save method configured in the configuration file, when the actual operation meets the configuration form, RDB persistence will be performed, and the current memory snapshot will be saved in the directory configured by dir. The file name is Determined by the configured dbfilename. ②. Manual trigger There are two commands to manually trigger Redis for RDB persistence: 1. saveThis command will block the current Redis Server, during the execution of the save command, Redis cannot process other commands until the RDB process is completed. Obviously, this command will cause long-term blocking for instances with relatively large memory, which is a fatal flaw. In order to solve this problem, Redis provides a second way. 2. bgsaveWhen executing this command, Redis will perform snapshot operations asynchronously in the background, and the snapshot can also respond to client requests. The specific operation is that the Redis process performs a fork operation to create a child process. The RDB persistence process is responsible for the child process and ends automatically after completion. Blocking only occurs in the fork phase and is generally very short-lived. Basically all RDB operations inside Redis use the bgsave command. ps: Executing the flushall command will also generate the dump.rdb file, but it is empty and meaningless
3. Restore data
将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可,redis就会自动加载文件数据至内存了。Redis 服务器在载入 RDB 文件期间,会一直处于阻塞状态,直到载入工作完成为止。
获取 redis 的安装目录可以使用 config get dir 命令

4、停止 RDB 持久化
有些情况下,我们只想利用Redis的缓存功能,并不像使用 Redis 的持久化功能,那么这时候我们最好停掉 RDB 持久化。可以通过上面讲的在配置文件 redis.conf 中,可以注释掉所有的 save 行来停用保存功能或者直接一个空字符串来实现停用:save ""
也可以通过命令:
redis-cli config set save " "
回到顶部
5、RDB 的优势和劣势
①、优势
1.RDB是一个非常紧凑(compact)的文件,它保存了redis 在某个时间点上的数据集。这种文件非常适合用于进行备份和灾难恢复。
2.生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
3.RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
②、劣势
1、RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作(内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑),频繁执行成本过高(影响性能)
2、RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题(版本不兼容)
3、在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改(数据有丢失)
回到顶部
6、RDB 自动保存的原理
Redis有个服务器状态结构:
struct redisService{
//1、记录保存save条件的数组
struct saveparam *saveparams;
//2、修改计数器
long long dirty;
//3、上一次执行保存的时间
time_t lastsave;
}①、首先看记录保存save条件的数组 saveparam,里面每个元素都是一个 saveparams 结构:
struct saveparam{
//秒数
time_t seconds;
//修改数
int changes;
};前面我们在 redis.conf 配置文件中进行了关于save 的配置:
save 900 1:表示900 秒内如果至少有 1 个 key 的值变化,则保存 save 300 10:表示300 秒内如果至少有 10 个 key 的值变化,则保存 save 60 10000:表示60 秒内如果至少有 10000 个 key 的值变化,则保存
那么服务器状态中的saveparam 数组将会是如下的样子:
②、dirty 计数器和lastsave 属性
dirty 计数器记录距离上一次成功执行 save 命令或者 bgsave 命令之后,Redis服务器进行了多少次修改(包括写入、删除、更新等操作)。
lastsave 属性是一个时间戳,记录上一次成功执行 save 命令或者 bgsave 命令的时间。
通过这两个命令,当服务器成功执行一次修改操作,那么dirty 计数器就会加 1,而lastsave 属性记录上一次执行save或bgsave的时间,Redis 服务器还有一个周期性操作函数 severCron ,默认每隔 100 毫秒就会执行一次,该函数会遍历并检查 saveparams 数组中的所有保存条件,只要有一个条件被满足,那么就会执行 bgsave 命令。
执行完成之后,dirty 计数器更新为 0 ,lastsave 也更新为执行命令的完成时间。
更多redis知识请关注redis数据库教程栏目。
The above is the detailed content of Detailed explanation of RDB persistence in redis. For more information, please follow other related articles on the PHP Chinese website!