
Home >Backend Development >Golang >Detailed graphic explanation of Go language concurrency mechanism
Detailed graphic explanation of Go language concurrency mechanism

- 尚forward
- 2019-11-30 14:31:492414browse
Go languageOne of the great advantages compared to Java is that it can easily write concurrent programs. The Go language has a built-in goroutine mechanism. Using goroutine, you can quickly develop concurrent programs and better utilize multi-core processor resources. This article learns the application of goroutine and its scheduling implementation.
1. Go language’s support for concurrency
Use goroutine programming (recommended: go video tutorial)
Use the go keyword to create goroutine. Place the go declaration before a function that needs to be called, and call and run the function in the same address space, so that the function will be executed as an independent concurrent thread. This kind of thread is called goroutine in Go language.
The usage of goroutine is as follows:
//go 关键字放在方法调用前新建一个 goroutine 并执行方法体
go GetThingDone(param1, param2);
//新建一个匿名方法并执行
go func(param1, param2) {
}(val1, val2)
//直接新建一个 goroutine 并在 goroutine 中执行代码块
go {
//do someting...
}Because goroutine is parallel in a multi-core CPU environment. If a block of code is executed in multiple goroutines, we achieve code parallelism.
If you need to know the execution of the program, how to get the parallel results? It needs to be used in conjunction with channel.
Use Channel to control concurrency
Channels are used to synchronize concurrently executed functions and provide them with some kind of value-passing communication mechanism.
The element type, container (or buffer) and transfer direction passed through the channel are specified by the "
You can use the built-in function make to allocate a channel:
i := make(chan int) // by default the capacity is 0 s := make(chan string, 3) // non-zero capacity r := make(<-chan bool) // can only read from w := make(chan<- []os.FileInfo) // can only write to
Configure runtime.GOMAXPROCS
Use the following code to explicitly set whether to use multi-core To execute concurrent tasks:
runtime.GOMAXPROCS()
The number of GOMAXPROCS can be allocated according to the amount of tasks, but it should not be greater than the number of cpu cores.
Configuring parallel execution is more suitable for CPU-intensive and high-parallel scenarios. If it is IO-intensive, using multiple cores will increase the performance loss caused by CPU switching.
After understanding the concurrency mechanism of Go language, let’s take a look at the specific implementation of the goroutine mechanism.
2. The difference between parallelism and concurrency
##Process, thread and processor
In modern operating systems, threads are the basic unit of processor scheduling and allocation, and processes are the basic unit of resource ownership. Each process is composed of private virtual address space, code, data and other various system resources. A thread is an execution unit within a process. Each process has at least one main execution thread, which does not need to be actively created by the user but is automatically created by the system. Users create other threads in the application as needed, and multiple threads run concurrently in the same process.Parallelism and Concurrency
Parallelism and concurrency (Concurrency and Parallelism) are two different concepts. Understanding them is very important for understanding the multi-threading model. When describing the concurrency or parallelism of a program, it should be stated from the perspective of a process or thread. Concurrency: There are many threads or processes executing in a time period, but only one is executing at any point in time. Multiple threads or processes compete for time slices and take turns executing Parallel : There are multiple threads or processes executing in a time period and point in time.A non-concurrent program has only one vertical control logic. At any time, the program will only be in a certain position of this control logic. , that is, sequential execution. If a program is processed by multiple CPU pipelines at the same time at a certain time, then we say that the program is running in parallel. Parallelism requires hardware support. Single-core processors can only be concurrent, and multi-core processors can achieve parallel execution. Concurrency is a necessary condition for parallelism. If a program itself is not concurrent, that is, there is only one logical execution sequence, then we cannot allow it to be processed in parallel. Concurrency is not a sufficient condition for parallelism. If a concurrent program is processed by only one CPU (through time sharing), then it is not parallel. For example, write the simplest sequential structure program to output "Hello World", which is non-concurrent. If you add multiple threads to the program and each thread prints a "Hello World", then this Programs are concurrent. If only a single CPU is allocated to this program during runtime, this concurrent program is not yet parallel and needs to be deployed on a multi-core processor to achieve program parallelism.3. Several different multi-threading models
User threads and kernel-level threads
The implementation of threads can be divided into two categories: user-level threads (User-LevelThread, ULT) and kernel-level threads (Kemel-LevelThread, KLT). User threads are backed by user code, and kernel threads are backed by the operating system kernel.Multi-threading model
The multi-threading model is the different connection methods of user-level threads and kernel-level threads.(1) Many-to-one model (M: 1)
Map multiple user-level threads to one kernel-level thread, and thread management is completed in user space. In this mode, user-level threads are invisible (that is, transparent) to the operating system.
Advantages: The advantage of this model is that thread context switching occurs in user space, avoiding mode switch (mode switch), which has a positive impact on performance.
Disadvantages: All threads are based on one kernel scheduling entity, namely the kernel thread, which means that only one processor can be utilized. This is unacceptable in a multi-processor environment. In essence, user threads It only solves the concurrency problem, but not the parallel problem. If a thread falls into the kernel state due to an I/O operation and the kernel state thread blocks waiting for I/O data, all threads will be blocked. User space can also use non-blocking I/O, but performance and complexity cannot be avoided. degree problem.
(2) One-to-one model (1:1)
Map each user-level thread to a kernel-level thread.
Each thread is scheduled independently by the kernel scheduler, so if one thread blocks, it will not affect other threads.
Advantages: With the support of multi-core processor hardware, the kernel space thread model supports true parallelism. When one thread is blocked, another thread is allowed to continue executing, so the concurrency capability is strong.
Disadvantages: Every time a user-level thread is created, a kernel-level thread needs to be created to correspond to it. This creates a relatively high overhead and will affect the performance of the application.
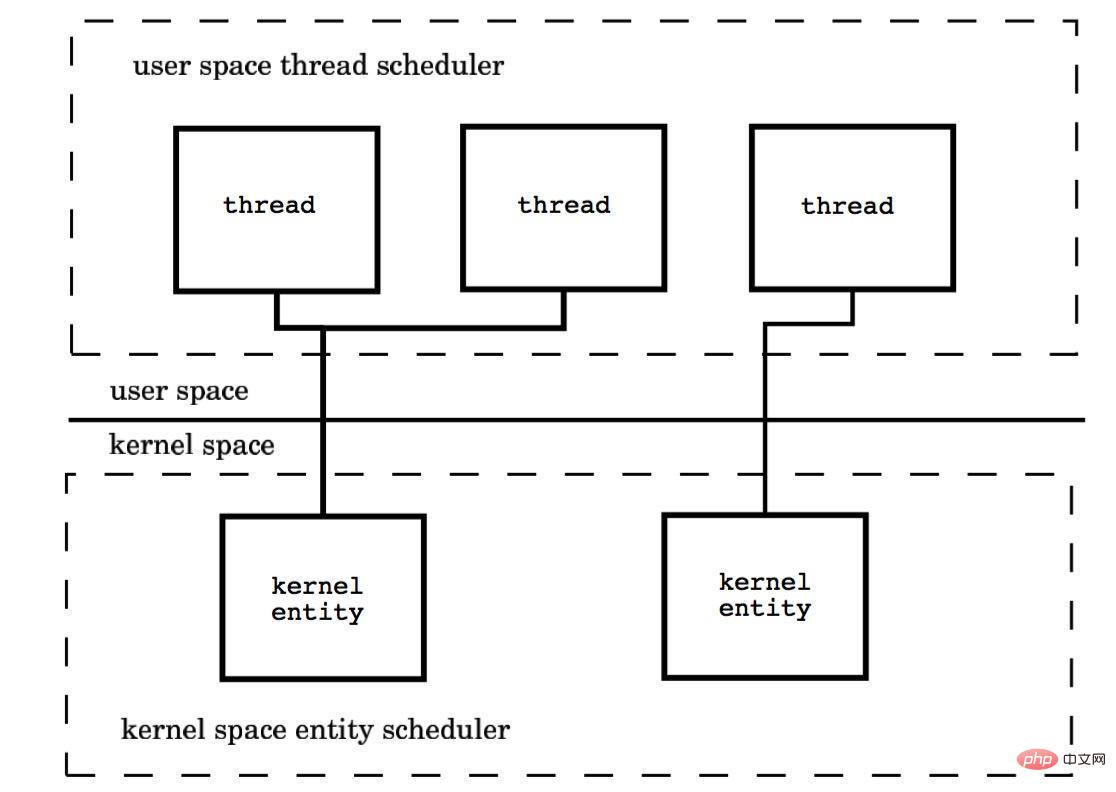
(3) Many-to-many model (M : N)
The ratio of the number of kernel threads and user threads is M : N. The kernel user space combines the advantages of the first two.
This model requires the kernel thread scheduler and the user space thread scheduler to interoperate. Essentially, multiple threads are bound to multiple kernel threads, which makes Most thread context switching occurs in user space, and multiple kernel threads can fully utilize processor resources.
4. Scheduling implementation of goroutine mechanism
The goroutine mechanism implements the M:N thread model, and the goroutine mechanism is a coroutine. An implementation of golang's built-in scheduler, which allows each CPU in a multi-core CPU to execute a coroutine.
The key to understanding the principles of the goroutine mechanism is to understand the implementation of the Go language scheduler.
How the scheduler works
There are four important structures in the Go language that support the entire scheduler implementation, namely M, G, P, and Sched. Previous The three definitions are in runtime.h, and Sched is defined in proc.c.
Sched structure is the scheduler, which maintains queues that store M and G and some status information of the scheduler.
The M structure is Machine, a system thread, which is managed by the operating system. Goroutine runs on M; M is a large structure that maintains small object memory cache (mcache), current execution There is a lot of information about goroutines, random number generators, etc.
P structure is Processor, processor. Its main purpose is to execute goroutine. It maintains a goroutine queue, namely runqueue. Processor is an important part of allowing us to move from N:1 scheduling to M:N scheduling.
G is the core structure of goroutine implementation. It contains the stack, instruction pointer, and other information important for scheduling goroutine, such as its blocked channel.
The number of Processors is set to the value of the environment variable GOMAXPROCS at startup, or is set by calling the function GOMAXPROCS() at runtime. The fixed number of Processors means that only GOMAXPROCS threads are running go code at any time.
We use triangles, rectangles and circles to represent Machine Processor and Goroutine respectively.

In the scenario of a single-core processor, all goroutines run in the same M system thread. Each M system thread maintains a Processor. At any time, a Processor There is only one goroutine, and other goroutines are waiting in the runqueue. After a goroutine finishes running its own time slice, it gives up the context and returns to the runqueue. In the scenario of multi-core processors, in order to run goroutines, each M system thread will hold a Processor.
Under normal circumstances, the scheduler will schedule according to the above process, but threads will be blocked. Take a look at goroutine's handling of thread blocking.
Thread blocking
When the running goroutine is blocked, such as making a system call, another system thread (M1) will be created, and the current M thread will give up. Its Processor, P is transferred to a new thread to run.

runqueue execution is completed
When one of the Processor's runqueues is empty, no goroutine can be scheduled. It will steal half of the goroutine from another context.

5. Further thoughts on concurrency implementation
The concurrency mechanism of Go language still has a lot to offer. Discussed, such as the difference between Go language and Scala concurrency implementation, the comparison between Golang CSP and Actor model, etc.
Understanding these implementations of concurrency mechanisms can help us better develop concurrent programs and optimize performance.
Regarding the three multi-threading models, you can pay attention to the implementation of the Java language.
We know that Java encapsulates the differences in the underlying operating system through the JVM, and different operating systems may use different thread models. For example, Linux and windows may use a one-to-one model, and some versions of solaris and unix may Use a many-to-many model. The JVM specification does not stipulate the specific implementation of the multi-threading model. Any of the 1:1 (kernel threads), N:1 (user state threads), and M:N (mixed) models is acceptable. When it comes to the multi-threading model of the Java language, it needs to be implemented for a specific JVM. For example, Oracle/Sun's HotSpot VM uses the 1:1 threading model by default.
The above is the detailed content of Detailed graphic explanation of Go language concurrency mechanism. For more information, please follow other related articles on the PHP Chinese website!