
Home >Backend Development >PHP Tutorial >Strategies and methods to prevent repeated submission of orders
Strategies and methods to prevent repeated submission of orders

- 藏色散人forward
- 2019-05-14 09:17:275790browse
Background
In business development, we often face the problem of preventing repeated requests. When the server's response to a request involves data modification or status change, it may cause great harm. The consequences of repeated requests are particularly serious in transaction systems, after-sales rights protection, and payment systems.
Jitter in foreground operations, fast operations, network communication or slow back-end response will increase the probability of repeated back-end processing. To take measures to debounce front-end operations and prevent fast operations, we first think of a layer of control on the front-end. When the front end triggers an operation, a confirmation interface may pop up, or the entry may be disabled and countdown, etc. will not be detailed here. However, front-end restrictions can only solve a small number of problems and are not thorough enough. The back-end's own anti-duplication measures are indispensable and obligatory.
In interface implementation, we often require the interface to satisfy idempotence to ensure that only one of the repeated requests is valid.
The interface of query class is almost always idempotent, but when it includes data insertion and multi-module data update, it will be more difficult to achieve idempotence, especially the idempotence requirements during high concurrency. For example, third-party payment front-end callbacks and background callbacks, third-party payment batch callbacks, slow business logic (such as users submitting refund applications, merchants agreeing to return/refund, etc.) or slow network environments are high-risk scenarios for repeated processing.
Try
Here is an example of "user submitting a refund application" to illustrate the effect of the tried anti-duplication processing method. We have tried three methods of back-end anti-duplication processing:
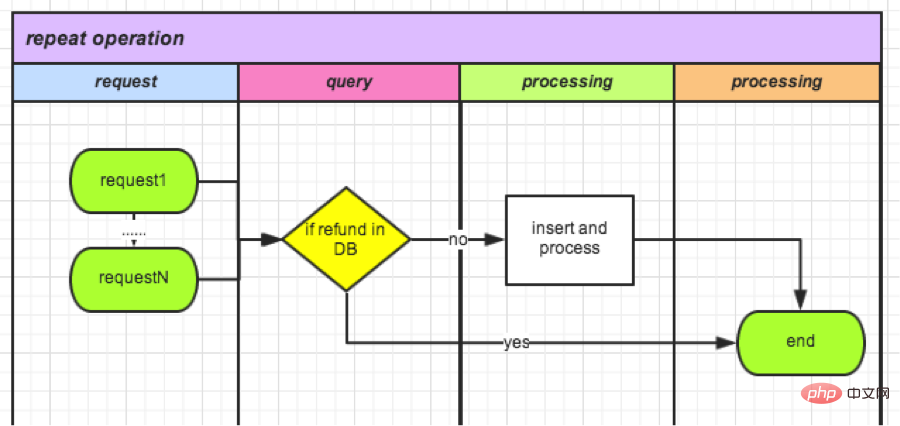
(1) Verification based on refund order status in DB
This method is simple and intuitive, and is queried from DB Refund details (including status) can often also be used in subsequent logic, without spending extra work specifically to deal with repeated requests.
This kind of logic for verification after querying the status has always existed in all business logic processing containing status since the code went online, and is essential. However, the effect of anti-duplication processing is not good: before adding anti-duplication submission on the front end, the average number was 25 per week; after the front-end optimization, it dropped to 7 per week. This number accounts for 3% of the total number of refund applications, a proportion that is still unacceptable.
Theoretically, as long as any request completes the query operation before the data status is updated, repeated processing of the business logic will occur. As shown below. The optimization direction is to reduce the business processing time between query and update, which can reduce the concurrency impact of the gap period. In the extreme case, if queries and updates become atomic operations, our current problem will not exist.
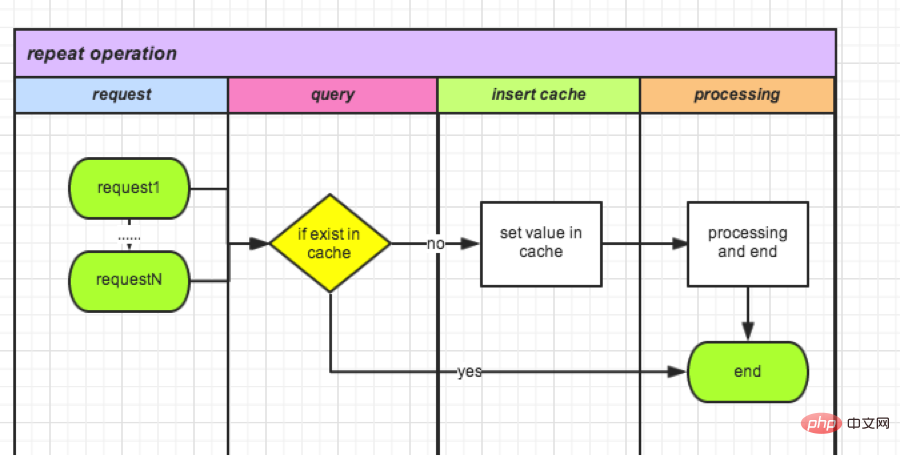
# (2) Verification based on cached data status
Redis storage query is lightweight and fast. When the request comes in, it can be recorded in the cache first. Subsequent incoming requests will be verified each time. The entire process is completed and the cache is cleared. Take refund as an example:
- I. Each time a refund application is initiated, read whether there is a value with orderId as the key in the cache
- II. If not, go to the cache Write value
- III with orderId as key. If yes, it means that the refund for this order is in progress.
- IV. Clear the cache after the operation, or set the life cycle when the cache stores the value.
Compared with 1) issuance, the database is replaced by a cache with faster response. But still not an atomic operation. There is still a time interval between inserting and reading the cache. In extreme cases, there are still repeated operations. After this method is optimized, the operation will be repeated once a week.
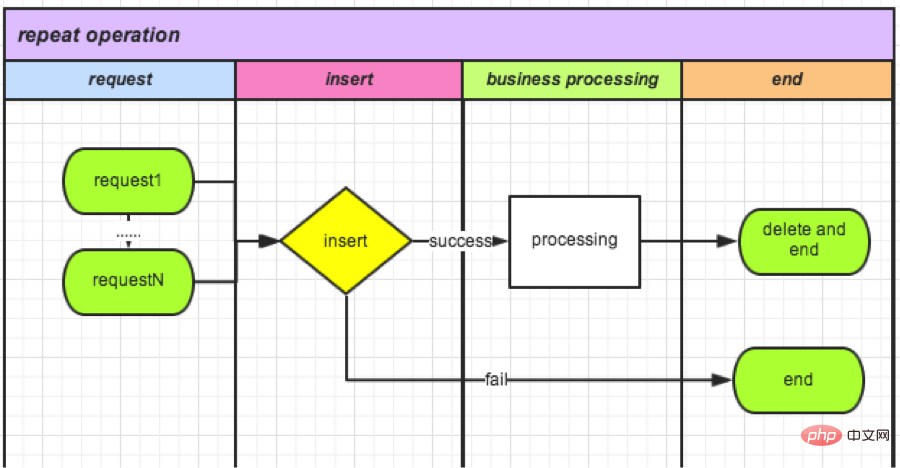
(3) Verification using the unique index mechanism
requires atomic operations, so I thought of the unique index of the database. Create a new TradeLock table:
CREATE TABLE `TradeLock` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT, `type` int(11) NOT NULL COMMENT '锁类型', `lockId` int(11) NOT NULL DEFAULT '0' COMMENT '业务ID', `status` int(11) NOT NULL DEFAULT '0' COMMENT '锁状态', PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='Trade锁机制';
● Every time a request comes in, data is inserted into the table:
成功,则可以继续操作(相当于获取锁); 失败,则说明有操作在进行。
● After the operation is completed, delete this record. (Equivalent to releasing the lock).
It is now online, waiting for the data statistics next week.
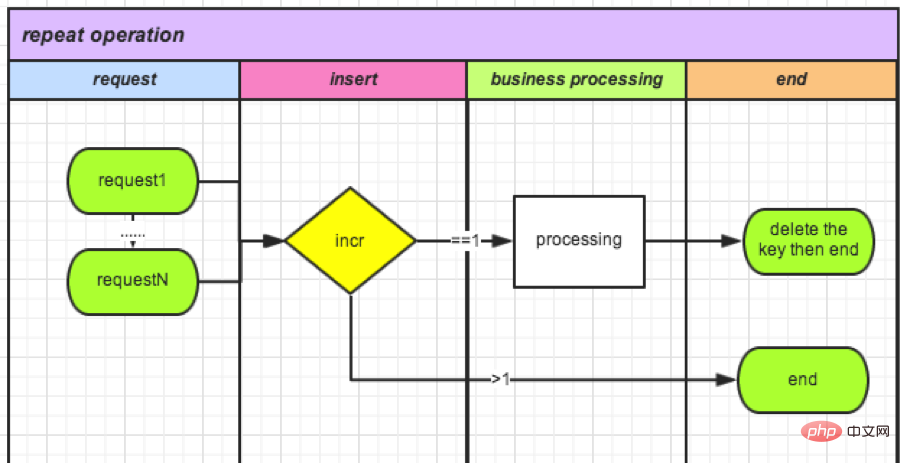
(4) Cache-based counter verification
Since database operations consume relatively high performance, we learned that redis counters are also atomic operations. Use counters decisively. It can not only improve performance, but also eliminate the need for storage, and can increase the peak qps.
Let’s take the order refund as an example:
● Every time a request comes in, a new counter with orderId as the key is created, and then +1.
如果>1(不能获得锁): 说明有操作在进行,删除。 如果=1(获得锁): 可以操作。
● End of operation (delete lock): Delete this counter.
要了解计数器,可以参考:http://www.redis.cn/commands/incr.html
总结:
PHP语言自身没有提供进程互斥和锁定机制。因此才有了我们上面的尝试。网上也有文件锁机制,但是考虑到我们的分布式部署,建议还是用缓存。在大并发的情况下,程序各种情况的发生。特别是涉及到金额操作,不能有一分一毫的差距。所以在大并发要互斥的情况下可以考虑3、4两种方案。
爱迪生尝试了1600多种材料选择了钨丝发明了灯泡,实践出真知。遇到问题,和问题斗争,最后解决问题是一个最大提升自我的过程,不但加宽自己的知识广度,更加深了自己的技能深度。达到目标之后的成就感更是不言而喻。
The above is the detailed content of Strategies and methods to prevent repeated submission of orders. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- Asynchronous notification and verification order method of calling SDK after payment in WeChat applet
- Detailed explanation of the asynchronous notification and verification processing method of calling the SDK after payment in the WeChat applet
- 5 ways to generate unique order numbers in php
- PHP code for processing WeChat payment callbacks to change order payment status