

A framework is actually a collection of reusable codes. The code of the framework is the code of the framework architecture, not the business logic code. The framework code protects classes, methods, functions, etc. The framework code is combined according to certain rules to form a framework.
Programmers at most large domestic Internet companies are called R&D engineers, but in fact there are almost no R&D projects in the country and can only be called development.
Most of the work of development programmers is repetitive work, which is easy to cause fatigue. The salary reaches a peak within 2-5 years of work, and it is more difficult to improve. This has led to many programmers ending up Switched to other industries.
JAVA is sophisticated and powerful, and has irreplaceable performance and maintainability of other languages. It has already become one of the most popular programming languages. Many people want to enter the IT industry, and the language of choice is JAVA.

However, in the next 10 years, the world will definitely be dominated by big data. With the outbreak of artificial intelligence, a large number of companies will enter the field of big data, and those who switch from JAVA programmers will JAVA big data will have natural advantages, because the current big data architecture is basically completed in the JAVA language. In the next 10 years, the demand for JAVA big data will be increasing.
If those who are learning JAVA now do not want to be eliminated in the future, they will definitely join the ranks of big data in the future. According to the current industry trends, JAVA programmers are less competitive due to development limitations and age. It is also becoming more and more easy to be overtaken by the younger generation in terms of technology. Because JAVA programmers work too long overtime, a large number of senior JAVA engineers have already entered big data.
The biggest challenge faced by IT developers today is complexity. Hardware is becoming more and more complex, OS is becoming more and more complex, programming languages and APIs are becoming more and more complex, and the applications we build are also becoming more and more complex. According to a survey report by foreign media, experts have listed some tools or frameworks that Java programmers have been using in the past 12 months, which may be meaningful to you.
1. MongoDB - the most popular, cross-platform, document-oriented database.
MongoDB is a database based on distributed file storage, written in C language. Designed to provide scalable, high-performance data storage solutions for web applications. Application performance depends on database performance. MongoDB is the most feature-rich among non-relational databases and is most like a relational database. With the release of MongoDB 3.4, its application scenario capabilities have been further expanded.
The core advantages of MongoDB are its flexible document model, highly available replica sets, and scalable sharded clusters. You can try to understand MongoDB from several aspects, such as real-time monitoring of MongoDB tools, memory usage and page faults, number of connections, database operations, replication sets, etc.
2. Elasticsearch - a distributed RESTful search engine built for the cloud.
ElasticSearch is a search server based on Lucene. It provides a distributed multi-user capable full-text search engine based on a RESTful web interface. Elasticsearch, developed in Java and released as open source under the terms of the Apache license, is a popular enterprise-level search engine.
ElasticSearch is not only a full-text search engine, but also a distributed real-time document storage, in which each field is indexed data and can be searched; it is also a distributed search engine with real-time analysis capabilities. And it can be expanded to hundreds of servers to store and process petabytes of data. ElasticSearch uses Lucene to complete its indexing function at the bottom level, so many of its basic concepts originate from Lucene.
3. Cassandra - an open source distributed database management system, originally developed by Facebook, designed to handle large amounts of data on many commodity servers, provide high availability, and have no single point of failure.
Apache Cassandra is an open source distributed NoSQL database system. It combines the data model of Google BigTable with the fully distributed architecture of Amazon Dynamo. It was open sourced in 2008. Since then, due to its good scalability, Cassandra has been adopted by Web 2.0 websites such as Digg and Twitter, and has become a popular distributed structured data storage solution.
Because Cassandra is written in Java, it can theoretically run on machines with JDK6 and above. The officially tested JDKs include OpenJDK and Sun's JDK. The operation commands of Cassandra are similar to the relational databases we usually operate. For friends who are familiar with MySQL, the operation will be easy to get started.
4. Redis - open source (BSD licensed) in-memory data structure storage, used as a database, cache and message broker.
Redis is an open source log-type Key-Value database written in ANSI C language, supports network, can be memory-based and persistent, and provides APIs in multiple languages. Redis has three main features that set it apart from many other competitors: Redis is a database that saves data entirely in memory, using disk only for persistence purposes; Redis has a relatively rich set of data types compared to many key-value data storage systems ; Redis can copy data to any number
5. Hazelcast - an open source memory data grid based on Java.
Hazelcast is an in-memory data grid that provides Java programmers with mission-critical transactions and trillion-level memory applications. Although Hazelcast does not have a so-called "Master", it still has a Leader node (the oldest member). This concept is similar to the Leader in ZooKeeper, but the implementation principle is completely different. At the same time, the data in Hazelcast is distributed, and each member holds part of the data and corresponding backup data, which is also different from ZooKeeper.
The application convenience of Hazelcast is loved by developers, but if you want to put it into use, you need to consider it carefully.
6. EHCache - a widely used open source Java distributed cache. Mainly for general cache, Java EE and lightweight containers.
EhCache is a pure Java in-process caching framework, which is fast and capable. It is the default CacheProvider in hibernate. The main features are: fast and simple, with multiple caching strategies; cached data has two levels, memory and disk, so there is no need to worry about capacity issues; cached data will be written to disk during the restart of the virtual machine; it can be accessed through RMI and pluggable API Distributed caching in other ways; has a listening interface for cache and cache managers; supports multiple cache manager instances, as well as multiple cache areas for one instance; provides Hibernate cache implementation.
7. Hadoop - an open source software framework written in Java, used for distributed storage, and for very large data users can develop distributed programs without understanding the underlying details of distribution.
Make full use of the cluster for high-speed computing and storage. Hadoop implements a distributed file system (Hadoop Distributed File System), referred to as HDFS. The core design of the Hadoop framework is: HDFS and MapReduce. HDFS provides storage for massive data, and MapReduce provides calculation for massive data.

8. Solr - an open source enterprise search platform, written in Java, from the Apache Lucene project.
Solr is an independent enterprise-level search application server that provides an API interface similar to Web-service. Users can submit XML files in a certain format to the search engine server through http requests to generate indexes; they can also make search requests through Http Get operations and get returned results in XML format.
Like ElasticSearch, it is also based on Lucene, but it extends it to provide a richer query language than Lucene, while being configurable, scalable and optimizing query performance.
9. Spark - the most active project in the Apache Software Foundation, is an open source cluster computing framework.
Spark is an open source cluster computing environment similar to Hadoop, but there are some differences between the two that make Spark superior in certain workloads. In other words That being said, Spark enables in-memory distributed datasets, which in addition to being able to provide interactive queries, can also optimize iterative workloads.
Spark is implemented in the Scala language and uses Scala as its application framework. Unlike Hadoop, Spark and Scala are tightly integrated, and Scala can operate as easily as local collection objects.
10. Memcached - a general distributed memory cache system.
Memcached is a distributed caching system that was originally developed by Danga Interactive for LiveJournal, but is used by many software (such as MediaWiki). As a high-speed distributed cache server, Memcached has the following characteristics: simple protocol, event processing based on libevent, and built-in memory storage.
11. Apache Hive--Provides a SQL-like layer on top of Hadoop.
Hive is a data warehouse platform based on Hadoop. Through hive, ETL work can be easily performed. hive defines a query language similar to SQL, which can convert user-written SQL into corresponding Mapreduce programs for execution based on Hadoop. Currently, Apache Hive 2.1.1 version has been released.
12. Apache Kafka - a high-throughput, distributed subscription messaging system originally developed by LinkedIn.
Apache Kafka is an open source messaging system project written in Scala. The goal of this project is to provide a unified, high-throughput, low-latency platform for processing real-time data. Kafka maintains messages differentiated by classes, called topics. Producers publish messages to Kafka topics, and consumers register with topics and receive messages published to these topics.
13. Akka – A toolkit for building highly concurrent, distributed and resilient message-driven applications on the JVM.
Akka is a library written in Scala that simplifies writing fault-tolerant, highly scalable Java and Scala actor model applications. It has been successfully used in the telecommunications industry, and the system almost never goes down.
14. HBase - open source, non-relational, distributed database, modeled using Google's BigTable, written in Java, and runs on HDFS.
Different from commercial big data products such as FUJITSU Cliq, HBase is an open source implementation of Google Bigtable. Similar to Google Bigtable, which uses GFS as its file storage system, HBase uses Hadoop HDFS as its file storage system; Google runs MapReduce to process Bigtable. Massive data, HBase also uses Hadoop MapReduce to process massive data in HBase; Google Bigtable uses Chubby as a collaborative service, and HBase uses Zookeeper as a counterpart.
15. Neo4j - an open source graph database implemented in Java.
Neo4j is a high-performance NOSQL graph database that stores structured data on the network instead of in tables. It is an embedded, disk-based, fully transactional Java persistence engine.
Summary:
Java is sought after by millions of developers around the world and has evolved into an excellent programming language. Ultimately, the language is constantly being improved to meet changing market needs as technology changes.
Whether you own a technology company or not, software has become an integral part of almost every business, and in order to attract your potential customers, you should deliver a technically innovative product to your customers. Well, Java can provide such a platform to help you realize this technological innovation. Java contributors have been maintaining extensive updates to provide the latest and most powerful features.
Related recommendations:
ThinkPHP framework one, ThinkPHP framework
ci framework (1), ci framework (
The above is the detailed content of Java developers must know these 15 big data tools and frameworks. For more information, please follow other related articles on the PHP Chinese website!

 解读CRISP-ML(Q):机器学习生命周期流程Apr 08, 2023 pm 01:21 PM
解读CRISP-ML(Q):机器学习生命周期流程Apr 08, 2023 pm 01:21 PM译者 | 布加迪审校 | 孙淑娟目前,没有用于构建和管理机器学习(ML)应用程序的标准实践。机器学习项目组织得不好,缺乏可重复性,而且从长远来看容易彻底失败。因此,我们需要一套流程来帮助自己在整个机器学习生命周期中保持质量、可持续性、稳健性和成本管理。图1. 机器学习开发生命周期流程使用质量保证方法开发机器学习应用程序的跨行业标准流程(CRISP-ML(Q))是CRISP-DM的升级版,以确保机器学习产品的质量。CRISP-ML(Q)有六个单独的阶段:1. 业务和数据理解2. 数据准备3. 模型
 thinkphp是不是国产框架Sep 26, 2022 pm 05:11 PM
thinkphp是不是国产框架Sep 26, 2022 pm 05:11 PMthinkphp是国产框架。ThinkPHP是一个快速、兼容而且简单的轻量级国产PHP开发框架,是为了简化企业级应用开发和敏捷WEB应用开发而诞生的。ThinkPHP从诞生以来一直秉承简洁实用的设计原则,在保持出色的性能和至简的代码的同时,也注重易用性。
 Python 强大的任务调度框架 Celery!Apr 12, 2023 pm 09:55 PM
Python 强大的任务调度框架 Celery!Apr 12, 2023 pm 09:55 PM什么是 celery这次我们来介绍一下 Python 的一个第三方模块 celery,那么 celery 是什么呢? celery 是一个灵活且可靠的,处理大量消息的分布式系统,可以在多个节点之间处理某个任务; celery 是一个专注于实时处理的任务队列,支持任务调度; celery 是开源的,有很多的使用者; celery 完全基于 Python 语言编写;所以 celery 本质上就是一个任务调度框架,类似于 Apache 的 airflow,当然 airflow 也是基于 Python
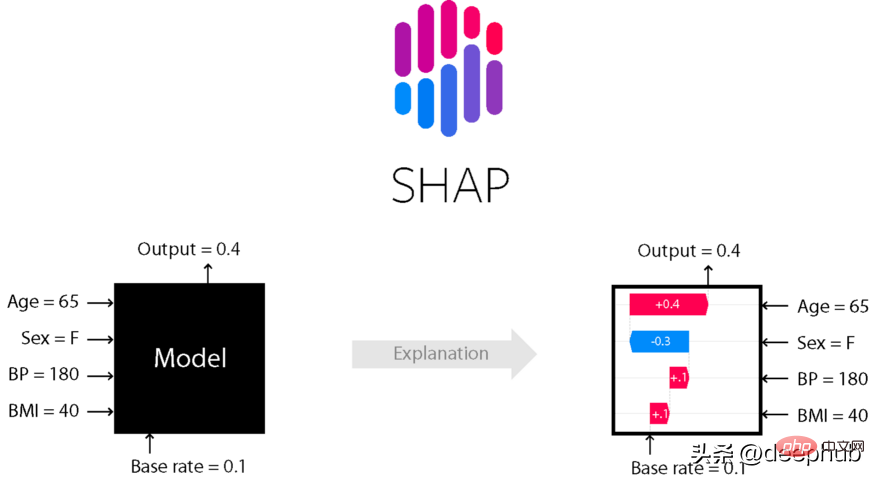 6个推荐的Python框架,用于构建可解释的人工智能系统(XAI)Apr 26, 2023 am 10:49 AM
6个推荐的Python框架,用于构建可解释的人工智能系统(XAI)Apr 26, 2023 am 10:49 AMAI就像一个黑匣子,能自己做出决定,但是人们并不清楚其中缘由。建立一个AI模型,输入数据,然后再输出结果,但有一个问题就是我们不能解释AI为何会得出这样的结论。需要了解AI如何得出某个结论背后的原因,而不是仅仅接受一个在没有上下文或解释的情况下输出的结果。可解释性旨在帮助人们理解:如何学习的?学到了什么?针对一个特定输入为什么会做出如此决策?决策是否可靠?在本文中,我将介绍6个用于可解释性的Python框架。SHAPSHapleyAdditiveexplanation(SHapleyAdditi
 如何在PHP中使用AOP框架May 19, 2023 pm 01:21 PM
如何在PHP中使用AOP框架May 19, 2023 pm 01:21 PMAOP(面向切面编程)是一种编程思想,用于解耦业务逻辑和横切关注点(如日志、权限等)。在PHP中,使用AOP框架可以简化编码,提高代码可维护性和可扩展性。本文将介绍在PHP中使用AOP框架的基本原理和实现方法。一、AOP的概念和原理面向切面编程,指的是将程序的业务逻辑和横切关注点分离开来,通过AOP框架来实现统一管理。横切关注点指的是在程序中需要重复出现并且
 Microsoft .NET Framework 4.5.2、4.6 和 4.6.1 将于 2022 年 4 月终止支持Apr 17, 2023 pm 02:25 PM
Microsoft .NET Framework 4.5.2、4.6 和 4.6.1 将于 2022 年 4 月终止支持Apr 17, 2023 pm 02:25 PM已安装Microsoft.NET版本4.5.2、4.6或4.6.1的MicrosoftWindows用户如果希望Microsoft将来通过产品更新支持该框架,则必须安装较新版本的Microsoft框架。据微软称,这三个框架都将在2022年4月26日停止支持。支持日期结束后,产品将不会收到“安全修复或技术支持”。大多数家庭设备通过Windows更新保持最新。这些设备已经安装了较新版本的框架,例如.NETFramework4.8。未自动更新的设备可能
 KB5013943 2022 年 5 月更新使 Windows 11 上的应用程序崩溃Apr 16, 2023 pm 10:52 PM
KB5013943 2022 年 5 月更新使 Windows 11 上的应用程序崩溃Apr 16, 2023 pm 10:52 PM如果你在Windows11上安装了2022年5月累积更新,你可能已经注意到你一直使用的许多应用程序都不像以前那样工作了。强制性安全更新KB5013943正在使某些使用.NET框架的应用程序崩溃。在某些情况下,用户会收到错误代码:0xc0000135。可选更新中报告了类似的问题,但并不普遍。随着2022年5月的更新,该错误似乎已进入生产渠道,这次有更多用户受到影响。崩溃在使用.NETFramework的应用程序中很常见,Discord或MicrosoftTeams等
 朱军团队在清华开源了首个基于Transformer的多模态扩散大型模型,经过文本和图像改写全部完成。May 08, 2023 pm 08:34 PM
朱军团队在清华开源了首个基于Transformer的多模态扩散大型模型,经过文本和图像改写全部完成。May 08, 2023 pm 08:34 PM据悉GPT-4将于本周发布,多模态将成为其一大亮点。当前的大语言模型正在成为理解各种模态的通用接口,能够根据不同模态信息来给出回复文本,但大语言模型生成的内容也仅仅局限于文本。另一方面,当前的扩散模型DALL・E2、Imagen、StableDiffusion等在视觉创作上掀起一场革命,但这些模型仅仅支持文到图的单一跨模态功能,离通用式生成模型还有一定距离。而多模态大模型将能够打通各种模态能力,实现任意模态之间转化,被认为是通用式生成模型的未来发展方向。清华大学计算机系朱军教授带领的TSAI


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

WebStorm Mac version
Useful JavaScript development tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

