
Home >Backend Development >PHP Tutorial >How to use php to get the parsing of images in documents
How to use php to get the parsing of images in documents

- 不言Original
- 2018-07-10 11:22:441967browse
This article mainly introduces about php parsing word and obtaining the pictures in the document, which has a certain reference value. Now I share it with everyone. Friends in need can refer to it
Background
I was writing a function some time ago: using native PHP to obtain the content in word and import it into the website system. Because there are formulas, pictures, tables, etc. in the document, writing is more troublesome.
Idea
The general idea is to first convert the document formatted as doc in word into docx, and then use the preprocessing program to convert the formulas in the document into swf image format. Convert word to xml format, and then convert the content in xml to json format.
Preliminary knowledge
1. Understand the basics of xml
xml is an extensible markup Language is an important tool for Internet data transmission. XML can realize cross-Internet platforms without being restricted by programming languages and operating systems. It can be said to be a data carrier with the highest level pass on the Internet.
xml is the current technology used in processing structured document information, which helps shuttle structured issuance between servers, allowing developers to more conveniently control the storage and transmission of data
xml is a markup language used to mark electronic documents to make them structural. It can be used to mark data and define data types. It is a source language that allows users to define their own markup language. It is a subset of the standard general-purpose language and is well suited for web transmission.
2. Two different storage methods of word
Two storage formats of word documents: doc and docx
doc: Traditionally called word, it uses binary to store data
docx: That is word2007, uses xml to store data
Then the suffix is obviously in docx format, why is it in xml format?
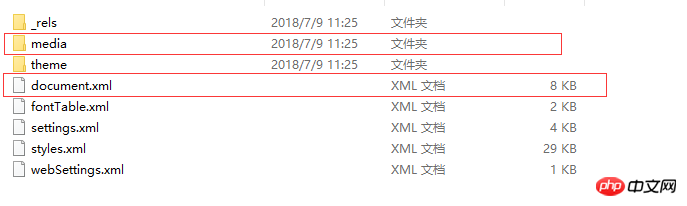
Select a test.docx, change the suffix name to .zip, and then unzip it to get the following directory structure:

So the docx you think is The document is actually a compressed file~
3. Understand DOM and PHP DOM XML parsing
DOM provides html and xml documents A standard set of objects, and a standard interface for accessing and manipulating these documents. XML DOM is a set of objects that defines a standard for documents. Using the PHP DOM extension, you can implement a series of operations on the DOM tree by PHP.
Use PHP DOM to read an XML document:
test.xml:
2aaf03e419584feed0654e5769a6311a5f2b62dd45854a241b02c0e88071fa06eae70f81f7ceb6e15d3307d0fcbf32c3 8a11bc632ea32a57b3e3693c7987c420php dom testdf406f776eecbaf16b62325323196f14 48fe722b397613e801e59f453d6c9330test-one069b8d673ec8f2ad312c1b3588acdb707d69b0364ce0178ed42ed498fb3f0eb8eae70f81f7ceb6e15d3307d0fcbf32c3 b2386ffb911b14667cb8f0f91ea547a7php dom test 26e916e0f7d1e588d4f442bf645aedb2f 48fe722b397613e801e59f453d6c9330test-two069b8d673ec8f2ad312c1b3588acdb707d69b0364ce0178ed42ed498fb3f0eb8c9cf1940f1608be1d86487a1d136ab67
test.php:
<?php $doc = new DOMDocument();
$doc->load("test.xml"); //获取标签对象
$book=$doc->getElementsByTagName("test"); //输出第一个中的值
echo $book->item(0)->nodeValue;
echo "<br>----------------<br>";
$title=$doc->getElementsByTagName("name");
echo $title->item(0)->nodeValue;
echo "<br>----------------<br>"; //遍历所有book标签中的内容
foreach ($book as $note)
{
echo $note->nodeValue;
echo "<br>";
}Result:

#4. The definition format of xml in word
How is the data in word defined? ?
We will only introduce two files/folders:
One file is word/document.xml, which defines the content of the entire word document.
Another folder is word/media. This folder stores the multimedia content of the document. In other words, all the pictures, audio and video in the document are stored in this folder.
Overall structure definition in document.ml:
30d62aeab593692457df6e48e31325f9 e4ea90d088e5c3d39154b2b9bfcd44c2 1cd73415ec6d15389d18b3b1f8dcba73 c40f7c91b7c20fc0eee95738e8d6cdff 5ad83e1c1232860a66f65a2e251f9221 e84b923c826a7c196bcb2565b9319b06 935b03d7bdfa227b85704d808f41fdda e8680000f363cb82b7f2c930f58633dc 4a2ba5a38d84be8c24b4e12ff061a6d7 6a7c515d155c69f94eafd9ac6ebf31a8 5daa03b38a0771a1fb69d9fff2858b67 2120a1776e013bfe32d8a05445dece29 5c04078d4c1cc5dc421de8f564ce6d1a 43f64d12e97790c1029480f923dbbb83 6a2483cbb124097fbc34371f16c0467f ce59d359290a70215a50ffa4f0fbbbd2 96ed9439c659e8e450875c49b8df9adc a17c39f82718fecc9dbbff60be677f0f 63065aaf547c6c6b49aca55a3f6a9397 be7e9f989cd506ea9ad858af9502dea9 b639aab6f233ca2658a121ea5cd71fb1 567cc2e2e2ff9e9f13cfa6106a0f1fda e919aea4579131530d90ded08e57a82a 05f489e411da99fbc1416db39abdfef1
Document paragraph content:
1cd73415ec6d15389d18b3b1f8dcba73 c40f7c91b7c20fc0eee95738e8d6cdff 5ad83e1c1232860a66f65a2e251f9221 e84b923c826a7c196bcb2565b9319b06 935b03d7bdfa227b85704d808f41fdda e8680000f363cb82b7f2c930f58633dc 4a2ba5a38d84be8c24b4e12ff061a6d7 6a7c515d155c69f94eafd9ac6ebf31a8 5daa03b38a0771a1fb69d9fff2858b67 2120a1776e013bfe32d8a05445dece29 5c04078d4c1cc5dc421de8f564ce6d1a 43f64d12e97790c1029480f923dbbb83 6a2483cbb124097fbc34371f16c0467f ce59d359290a70215a50ffa4f0fbbbd2 96ed9439c659e8e450875c49b8df9adc a17c39f82718fecc9dbbff60be677f0f 63065aaf547c6c6b49aca55a3f6a9397 be7e9f989cd506ea9ad858af9502dea9 b639aab6f233ca2658a121ea5cd71fb1 567cc2e2e2ff9e9f13cfa6106a0f1fda e919aea4579131530d90ded08e57a82a 05f489e411da99fbc1416db39abdfef1 73df4e15f25b21cddc06e6cda5b77ade 73389815fe15e18235e4a05d06404a4b c9b65e209bc0d1e767d43c26b8ed832c ba0b29a083f458e453efe56a6be4f669 b57dd4d9cd374504bf5ceeec04527221 7dad62032a64d4af59db0f2491b761e0 e4b2c9b67897f745d21b20ef39352a11 b5b013232cdc3f01d8d21978ce7935e7 fce2809517fbd180cb62f9e6581144f1 377e20077303a61974ea8a8d644f3e0c d0d62db2ea7aee96ea4d87f3c2e46160 7af433e0a9c902263bd5fbd5c86eefb3 91a6045fcd7a6179028b6c4c461ec5e4 e5c87018381bba5f884dd35592cc2986 0eb30ced7ecbd0716fe8dc54ce343561 e8f607ae0f4850aa3576e2e254f34727 ba0b29a083f458e453efe56a6be4f669 ba1ee891a533d9683d9b38533400e609 0fe0f1fb9eb7a3dac789acb4a70b2d28 d7c531b1416166352b3f693a25619702 166634fe8d1388f900439ffb8657dbe0 206a91743cf9d008bd6f9e34b33547c4 c0d0d8aafb565380c0c31df9f981293e 2631240fe01283848323e5f9b73e3834 e4b2c9b67897f745d21b20ef39352a11 b5b013232cdc3f01d8d21978ce7935e7 fce2809517fbd180cb62f9e6581144f1 377e20077303a61974ea8a8d644f3e0c d0d62db2ea7aee96ea4d87f3c2e46160 7af433e0a9c902263bd5fbd5c86eefb3 91a6045fcd7a6179028b6c4c461ec5e4 e5c87018381bba5f884dd35592cc2986 0eb30ced7ecbd0716fe8dc54ce343561 e8f607ae0f4850aa3576e2e254f34727 ba0b29a083f458e453efe56a6be4f669 ba1ee891a533d9683d9b38533400e609 0fe0f1fb9eb7a3dac789acb4a70b2d28 d7c531b1416166352b3f693a25619702 166634fe8d1388f900439ffb8657dbe0 2425b69ea0d5675c89ef2d87c266b6d5 a6404c91941ab243c3e2acf77a6c1ddf 73df4e15f25b21cddc06e6cda5b77ade 73389815fe15e18235e4a05d06404a4b 206a91743cf9d008bd6f9e34b33547c4 a6c5b28f669f1bd5d83a87716f82bb27 作者: Test 84fcc76c32527fcfce5a40543da17a12 875eefd8ce6290d581339ced7c38c2a2 5d154b7604550fdd28d5dcb7a20784b6
Image content definition:
2631240fe01283848323e5f9b73e3834 e4b2c9b67897f745d21b20ef39352a11 b5b013232cdc3f01d8d21978ce7935e7 fce2809517fbd180cb62f9e6581144f1 377e20077303a61974ea8a8d644f3e0c d0d62db2ea7aee96ea4d87f3c2e46160 7af433e0a9c902263bd5fbd5c86eefb3 91a6045fcd7a6179028b6c4c461ec5e4 e5c87018381bba5f884dd35592cc2986 0eb30ced7ecbd0716fe8dc54ce343561 e8f607ae0f4850aa3576e2e254f34727 ba0b29a083f458e453efe56a6be4f669 ba1ee891a533d9683d9b38533400e609 0fe0f1fb9eb7a3dac789acb4a70b2d28 d7c531b1416166352b3f693a25619702 166634fe8d1388f900439ffb8657dbe0 2425b69ea0d5675c89ef2d87c266b6d5 a6404c91941ab243c3e2acf77a6c1ddf 73df4e15f25b21cddc06e6cda5b77ade 73389815fe15e18235e4a05d06404a4b 206a91743cf9d008bd6f9e34b33547c4 2f1bd8167d633807671a2ebd53e0748c ed73879f4eec7bacba27f82cfff7a884 e622c0055287012ad1d06c9e3c46532f ae023d86a419a18fd24b2d50f3af5239 76798d30975e8fb2288a431b53bd8d4d fc585e894391f877485e7361d7236bd0 aeaa65628bf0c4a3def5a14a7988c1e6 fd7d1cff4ef8857ca9f75c920f409a13 43ba7d3da3e84a2c9732fd8b2afbd149 25e0a02ef41c2c94030f334b9922ff4f 5f6f4c96f4cd149834df6c58fb325c91 bb881ec15a06ba925d40484506d01e4c d447baf070845f0527c98ba353c81199 6406e760d3a8e4c5442ee41c596ac5e1 adc09985359478aef59a64ef8e5d25dd 14b93225c3e87c8c36443e74e8a4f761 2dd332b5b8c7292c9c1849b97e60c9c9 2a2aac47dd68dbc81fa12a10e201b3ec 28136e6fdc182844d18bc36c95a3f753 b72baa4f585df6cda9287f0b98e99588 12ea31b367e74e4d56848c78b93bf9b0 cf46531cc89ba0dd47269c9b95b20213 004002e582d7f8698b2e0c8f954aaca8 f1f3cff7c99aac51f998ac1409da3381 9e6acf6613235edb80ef1f7280339341 e92a8dc3d47a1b08cf9b312fb6063035 98f90394c28be5fa14019c82ce0ed684 de804f3e9e111ff0903befb2c391ae68 f78134bd20986e39d7646414873438b1 1b51e0be50c29fe6a40a123f66b45068 21b3578f6e93fb23adb74ec24f5f62dc ce9a65951d680fc72386e0d97583fa2d e53c1b01c775e255360cea99c60c3f86 7cac5f8862635b73e9bb85c465424a97 9cf60189a627ac1e49661c31d0dc108f aeed961f5585b4a42d515216acb68900 bad74176c3e461b8dc8de9541a5f5094 d4b4ce3fef058a7eba28a6cfd6e59032 1bb3eeab69df875ac92e8428eb167557 611ade5a87841a884119f7eaec502cb2 43bc92e64aab8aa9677cfe9d4f4ef16a 960159f8049ef2692c80fbf2b850b9e9 e2a5dc931c639599976cf22abca1d4ca 98bda0a5def2268f8477d6386de06afe 9c9300fbe2fb0a0f8a2fe8c46e0ef116 e2a5dc931c639599976cf22abca1d4ca 98bda0a5def2268f8477d6386de06afe 9dbda594f5587c3bc54d029a07d08d33 21994f0048728f4e00f962321258d6bf e385c128d23a97a4e87fe1b8348181af ddb9e1cb53994ed3161f247f01734c5a 4136914b9788fa90e03086cffd803037 892961627f03d7692d68e414096d777e b289ceb1fb2cd9605f6cd9cd02cd8963 875eefd8ce6290d581339ced7c38c2a2
Conclusion:
c1288db3edc33ea81d8279cf3b3389b0 定义整个文档的开始 e4ea90d088e5c3d39154b2b9bfcd44c2 document的子节点,文档的主体内容 1cd73415ec6d15389d18b3b1f8dcba73 body的子节点,一个段落,就是word文档中的段落 2631240fe01283848323e5f9b73e3834 p元素的子节点,一个Run定义了段落中具有相同格式的一段内容 a6c5b28f669f1bd5d83a87716f82bb27 Run元素节点的子节点,就是文档的内容 2f1bd8167d633807671a2ebd53e0748c run元素的子节点,定义了一张图片 c21d2efe537efcf091b2cd661d85da6e drawing子节点,具体应用没有研究 b497ea7e5ff41fded60ec12afe67378a 定义了图片内容 f1f3cff7c99aac51f998ac1409da3381 graphic文档的子节点,定义了图片内容的索引.
Specifically speaking, if you use java, then XWPF parsing the docx document is to parse the xml document, obtain all the nodes and convert them into more useful attributes to provide API for use. In java Zhongpoi can get the resources corresponding to the picture based on this name, and the key to getting the location of the picture is here.
But unfortunately, I am using php~~~so we need to manually obtain the image through the relevant interface of php.
Let me talk about it The specific idea: Obtain the xml node of the docx document through PHP's built-in DOMDocument interface, traverse the xml node to find the node element that saves the image, and traverse down the image node Get the value of the r:embed index. Because the docx document is in a compressed package format, the docx document is traversed through the PHP built-in interface ZipArchive interface (essentially traversing the .zip compressed package), the corresponding image is found through the index, converted into binary data, and spliced The img tag displays image data in base64 format.
Convert to xml:
private $rels_xml;
private $doc_xml;
private function readZipPart($filename) {
$zip = new ZipArchive();
$_xml = 'word/document.xml';
$_xml_rels = 'word/_rels/document.xml.rels';
if (true === $zip->open($filename)) {
if (($index = $zip->locateName($_xml)) !== false) {
$xml = $zip->getFromIndex($index);
}
$zip->close();
} else die('non zip file');
if (true === $zip->open($filename)) {
if (($index = $zip->locateName($_xml_rels)) !== false) {
$xml_rels = $zip->getFromIndex($index);
}
$zip->close();
} else die('non zip file');
$this->doc_xml = new DOMDocument();
$this->doc_xml->encoding = mb_detect_encoding($xml);
$this->doc_xml->preserveWhiteSpace = false;
$this->doc_xml->formatOutput = true;
$this->doc_xml->loadXML($xml);
$this->doc_xml->saveXML();
$this->rels_xml = new DOMDocument();
$this->rels_xml->encoding = mb_detect_encoding($xml);
$this->rels_xml->preserveWhiteSpace = false;
$this->rels_xml->formatOutput = true;
$this->rels_xml->loadXML($xml_rels);
$this->rels_xml->saveXML();
}
Determine whether it is a picture node:
if($paragraph->name === 'w:drawing') {
(strstr($ts,'…封…') != false || strstr($ts,'…线…') != false) ? $t .= '' : $t .= $this->analysisDrawing($paragraph);
}
Get the picture index:
private function analysisDrawing(&$drawingXml) {
while($drawingXml->read()) {
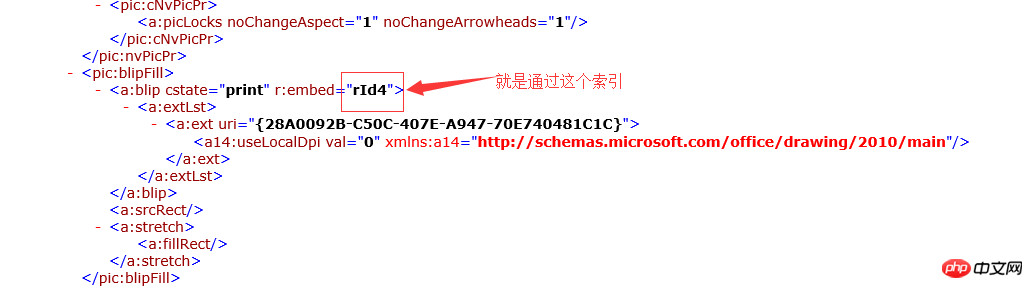
if ($drawingXml->nodeType == XMLREADER::ELEMENT && $drawingXml->name === 'a:blip') {
$rId = $drawingXml->getAttribute('r:embed');
$rIdIndex = substr($rId,3);
return $this->checkImageFormating($rIdIndex);
}
}
}
Display the picture file in the compressed package:
private function checkImageFormating($rIdIndex) {
$imgname = 'word/media/image'.($rIdIndex-8);
$zipfileName = __DIR__.DIRECTORY_SEPARATOR.'b'.DIRECTORY_SEPARATOR.'test.docx';
$zip=zip_open($zipfileName);
while($zip_entry = zip_read($zip)) {//读依次读取包中的文件
$file_name=zip_entry_name($zip_entry);//获取zip中的文件名
if(strstr($file_name,$imgname) != '' ) {
$a = ($rIdIndex-8 b13a7ec521d12190d2804798bdb3ee93', $ext, base64_encode($content));//利用base64_encode函数转换读取到的二进制数据并输入输出到页面中
}
zip_entry_close($zip_entry); //关闭zip中打开的项目
}
}
zip_close($zip);//关闭zip文件
}
以上就是本文的全部内容,希望对大家的学习有所帮助,更多相关内容请关注PHP中文网!
相关推荐:
The above is the detailed content of How to use php to get the parsing of images in documents. For more information, please follow other related articles on the PHP Chinese website!