

FIFO
The simplest caching algorithm is to set the cache upper limit. When the cache upper limit is reached, it will be eliminated according to the first-in, first-out strategy, and then new ones will be added. k-v.
Uses a object as cache, and an array matches the order in which records are added to the object to determine whether the upper limit is reached. If the upper limit is reached, the first item in the array is taken. An element key, corresponding to Delete the key value in the object.
/**
* FIFO队列算法实现缓存
* 需要一个对象和一个数组作为辅助
* 数组记录进入顺序
*/
class FifoCache{
constructor(limit){
this.limit = limit || 10
this.map = {}
this.keys = []
}
set(key,value){
let map = this.map
let keys = this.keys
if (!Object.prototype.hasOwnProperty.call(map,key)) {
if (keys.length === this.limit) {
delete map[keys.shift()]//先进先出,删除队列第一个元素
}
keys.push(key)
}
map[key] = value//无论存在与否都对map中的key赋值
}
get(key){
return this.map[key]
}
}
module.exports = FifoCache
LRU
LRU (Least recently used, least recently used) algorithm. The point of view of this algorithm is that the data that has been accessed recently has a greater probability of being accessed in the future. When the cache is full, the least interested data will be eliminated first.
Algorithm implementation idea: Based on the data structure of a double linked list, when it is not full, the new k-v is placed at the head of the linked list, and the k-v is moved every time the k-v in the cache is obtained. When the cache is full, the ones at the end will be eliminated first.
The characteristics of a doubly linked list are head and tail pointers. Each node has prev (predecessor) and next (successor) pointers pointing to its previous and next nodes respectively.
Key point: Pay attention to the order issue during the insertion process of the double linked list. The pointer must be processed first while keeping the linked list continuous, and finally the original pointer points to the newly inserted element. In the implementation of the code Please pay attention to the order I explained in Notes!
class LruCache {
constructor(limit) {
this.limit = limit || 10
//head 指针指向表头元素,即为最常用的元素
this.head = this.tail = undefined
this.map = {}
this.size = 0
}
get(key, IfreturnNode) {
let node = this.map[key]
// 如果查找不到含有`key`这个属性的缓存对象
if (node === undefined) return
// 如果查找到的缓存对象已经是 tail (最近使用过的)
if (node === this.head) { //判断该节点是不是是第一个节点
// 是的话,皆大欢喜,不用移动元素,直接返回
return returnnode ?
node :
node.value
}
// 不是头结点,铁定要移动元素了
if (node.prev) { //首先要判断该节点是不是有前驱
if (node === this.tail) { //有前驱,若是尾节点的话多一步,让尾指针指向当前节点的前驱
this.tail = node.prev
}
//把当前节点的后继交接给当前节点的前驱去指向。
node.prev.next = node.next
}
if (node.next) { //判断该节点是不是有后继
//有后继的话直接让后继的前驱指向当前节点的前驱
node.next.prev = node.prev
//整个一个过程就是把当前节点拿出来,并且保证链表不断,下面开始移动当前节点了
}
node.prev = undefined //移动到最前面,所以没了前驱
node.next = this.head //注意!!! 这里要先把之前的排头给接到手!!!!让当前节点的后继指向原排头
if (this.head) {
this.head.prev = node //让之前的排头的前驱指向现在的节点
}
this.head = node //完成了交接,才能执行此步!不然就找不到之前的排头啦!
return IfreturnNode ?
node :
node.value
}
set(key, value) {
// 之前的算法可以直接存k-v但是现在要把简单的 k-v 封装成一个满足双链表的节点
//1.查看是否已经有了该节点
let node = this.get(key, true)
if (!node) {
if (this.size === this.limit) { //判断缓存是否达到上限
//达到了,要删最后一个节点了。
if (this.tail) {
this.tail = this.tail.prev
this.tail.prev.next = undefined
//平滑断链之后,销毁当前节点
this.tail.prev = this.tail.next = undefined
this.map[this.tail.key] = undefined
//当前缓存内存释放一个槽位
this.size--
}
node = {
key: key
}
this.map[key] = node
if(this.head){//判断缓存里面是不是有节点
this.head.prev = node
node.next = this.head
}else{
//缓存里没有值,皆大欢喜,直接让head指向新节点就行了
this.head = node
this.tail = node
}
this.size++//减少一个缓存槽位
}
}
//节点存不存在都要给他重新赋值啊
node.value = value
}
}
module.exports = LruCache
The specific idea is that if the node you want to get is not the head node (that is, it is already the most recently used node, and there is no need to move the node position), you must first perform a smooth link breaking operation and handle the pointer pointed to. Relationship, take out the node that needs to be moved to the front, and perform the insertion operation into the linked list.
I believe you have mastered the method after reading the case in this article. For more exciting information, please pay attention to other related articles on the php Chinese website!
Recommended reading:
What are the steps for query dynamic parameter passing in vue-router
The local development environment cannot be used How to handle IP access
The above is the detailed content of FIFO/LRU implements caching algorithm. For more information, please follow other related articles on the PHP Chinese website!

 特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM
特斯拉自动驾驶算法和模型解读Apr 11, 2023 pm 12:04 PM特斯拉是一个典型的AI公司,过去一年训练了75000个神经网络,意味着每8分钟就要出一个新的模型,共有281个模型用到了特斯拉的车上。接下来我们分几个方面来解读特斯拉FSD的算法和模型进展。01 感知 Occupancy Network特斯拉今年在感知方面的一个重点技术是Occupancy Network (占据网络)。研究机器人技术的同学肯定对occupancy grid不会陌生,occupancy表示空间中每个3D体素(voxel)是否被占据,可以是0/1二元表示,也可以是[0, 1]之间的
 基于因果森林算法的决策定位应用Apr 08, 2023 am 11:21 AM
基于因果森林算法的决策定位应用Apr 08, 2023 am 11:21 AM译者 | 朱先忠审校 | 孙淑娟在我之前的博客中,我们已经了解了如何使用因果树来评估政策的异质处理效应。如果你还没有阅读过,我建议你在阅读本文前先读一遍,因为我们在本文中认为你已经了解了此文中的部分与本文相关的内容。为什么是异质处理效应(HTE:heterogenous treatment effects)呢?首先,对异质处理效应的估计允许我们根据它们的预期结果(疾病、公司收入、客户满意度等)选择提供处理(药物、广告、产品等)的用户(患者、用户、客户等)。换句话说,估计HTE有助于我
 Mango:基于Python环境的贝叶斯优化新方法Apr 08, 2023 pm 12:44 PM
Mango:基于Python环境的贝叶斯优化新方法Apr 08, 2023 pm 12:44 PM译者 | 朱先忠审校 | 孙淑娟引言模型超参数(或模型设置)的优化可能是训练机器学习算法中最重要的一步,因为它可以找到最小化模型损失函数的最佳参数。这一步对于构建不易过拟合的泛化模型也是必不可少的。优化模型超参数的最著名技术是穷举网格搜索和随机网格搜索。在第一种方法中,搜索空间被定义为跨越每个模型超参数的域的网格。通过在网格的每个点上训练模型来获得最优超参数。尽管网格搜索非常容易实现,但它在计算上变得昂贵,尤其是当要优化的变量数量很大时。另一方面,随机网格搜索是一种更快的优化方法,可以提供更好的
 因果推断主要技术思想与方法总结Apr 12, 2023 am 08:10 AM
因果推断主要技术思想与方法总结Apr 12, 2023 am 08:10 AM导读:因果推断是数据科学的一个重要分支,在互联网和工业界的产品迭代、算法和激励策略的评估中都扮演者重要的角色,结合数据、实验或者统计计量模型来计算新的改变带来的收益,是决策制定的基础。然而,因果推断并不是一件简单的事情。首先,在日常生活中,人们常常把相关和因果混为一谈。相关往往代表着两个变量具有同时增长或者降低的趋势,但是因果意味着我们想要知道对一个变量施加改变的时候会发生什么样的结果,或者说我们期望得到反事实的结果,如果过去做了不一样的动作,未来是否会发生改变?然而难点在于,反事实的数据往往是
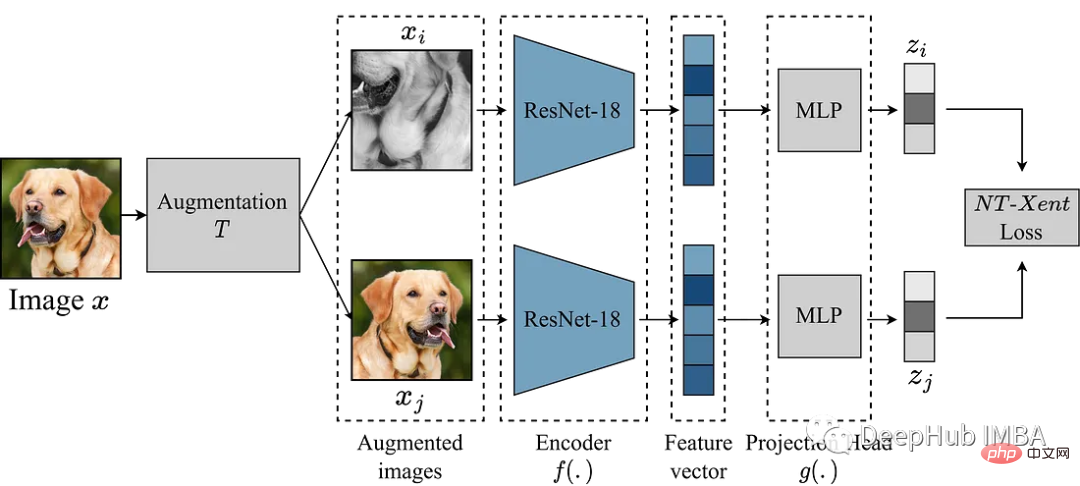 使用Pytorch实现对比学习SimCLR 进行自监督预训练Apr 10, 2023 pm 02:11 PM
使用Pytorch实现对比学习SimCLR 进行自监督预训练Apr 10, 2023 pm 02:11 PMSimCLR(Simple Framework for Contrastive Learning of Representations)是一种学习图像表示的自监督技术。 与传统的监督学习方法不同,SimCLR 不依赖标记数据来学习有用的表示。 它利用对比学习框架来学习一组有用的特征,这些特征可以从未标记的图像中捕获高级语义信息。SimCLR 已被证明在各种图像分类基准上优于最先进的无监督学习方法。 并且它学习到的表示可以很容易地转移到下游任务,例如对象检测、语义分割和小样本学习,只需在较小的标记
 盒马供应链算法实战Apr 10, 2023 pm 09:11 PM
盒马供应链算法实战Apr 10, 2023 pm 09:11 PM一、盒马供应链介绍1、盒马商业模式盒马是一个技术创新的公司,更是一个消费驱动的公司,回归消费者价值:买的到、买的好、买的方便、买的放心、买的开心。盒马包含盒马鲜生、X 会员店、盒马超云、盒马邻里等多种业务模式,其中最核心的商业模式是线上线下一体化,最快 30 分钟到家的 O2O(即盒马鲜生)模式。2、盒马经营品类介绍盒马精选全球品质商品,追求极致新鲜;结合品类特点和消费者购物体验预期,为不同品类选择最为高效的经营模式。盒马生鲜的销售占比达 60%~70%,是最核心的品类,该品类的特点是用户预期时
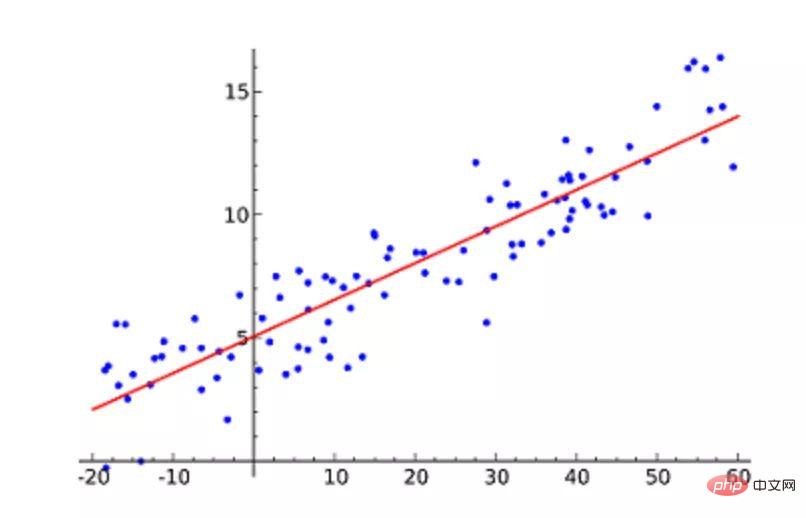 机器学习必知必会十大算法!Apr 12, 2023 am 09:34 AM
机器学习必知必会十大算法!Apr 12, 2023 am 09:34 AM1.线性回归线性回归(Linear Regression)可能是最流行的机器学习算法。线性回归就是要找一条直线,并且让这条直线尽可能地拟合散点图中的数据点。它试图通过将直线方程与该数据拟合来表示自变量(x 值)和数值结果(y 值)。然后就可以用这条线来预测未来的值!这种算法最常用的技术是最小二乘法(Least of squares)。这个方法计算出最佳拟合线,以使得与直线上每个数据点的垂直距离最小。总距离是所有数据点的垂直距离(绿线)的平方和。其思想是通过最小化这个平方误差或距离来拟合模型。例如
 人类反超 AI:DeepMind 用 AI 打破矩阵乘法计算速度 50 年记录一周后,数学家再次刷新Apr 11, 2023 pm 01:16 PM
人类反超 AI:DeepMind 用 AI 打破矩阵乘法计算速度 50 年记录一周后,数学家再次刷新Apr 11, 2023 pm 01:16 PM10 月 5 日,AlphaTensor 横空出世,DeepMind 宣布其解决了数学领域 50 年来一个悬而未决的数学算法问题,即矩阵乘法。AlphaTensor 成为首个用于为矩阵乘法等数学问题发现新颖、高效且可证明正确的算法的 AI 系统。论文《Discovering faster matrix multiplication algorithms with reinforcement learning》也登上了 Nature 封面。然而,AlphaTensor 的记录仅保持了一周,便被人类


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

SublimeText3 Linux new version
SublimeText3 Linux latest version

Notepad++7.3.1
Easy-to-use and free code editor

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Zend Studio 13.0.1
Powerful PHP integrated development environment

