
Home >Backend Development >Python Tutorial >Taking the example of grabbing Taobao comments to explain how Python crawls data dynamically generated by ajax (classic)
Taking the example of grabbing Taobao comments to explain how Python crawls data dynamically generated by ajax (classic)

- 不言Original
- 2018-04-18 11:14:434115browse
When learning python, you will definitely encounter the situation where the website content is json data generated through ajax dynamic request and asynchronous refresh, and the previous method of crawling static web content through python is not possible, so this This article will describe how to crawl data dynamically generated by ajax in python.
When learning python, you will definitely encounter the situation where the website content is json data generated through ajax dynamic request and asynchronous refresh, and the previous method of crawling static web content through python is not possible. , so this article will describe how to crawl data dynamically generated by ajax in python.
As for the way to read static web content, those who are interested can check the content of this article.
Here we take crawling Taobao comments as an example to explain how to do it.
This is mainly divided into four steps:
When getting Taobao comments, ajax requests the link (url)
2 Get the json data returned by the ajax request
3 Use python to parse the json data
Four Save the parsed results
Step 1:
When getting Taobao comments, ajax Request link (url) Here I use Chrome browser to complete. Open the Taobao link and search for a product in the search box, such as "shoes". Here we select the first product.

Then jump to a new web page. Here, since we need to crawl user reviews, we click Accumulated Ratings.

Then we can see the user's evaluation of the product. At this time, we right-click on the web page to select the review element (or directly use F12 to open it) and select Network options, as shown in the picture:
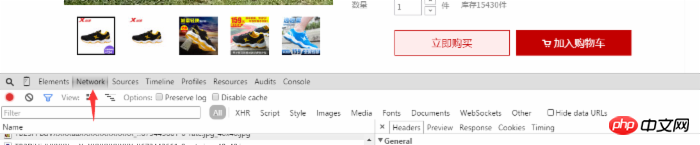
In the user comments, we scroll to the bottom and click on the next page or the second page. We see several dynamically added pages in the Network. item, we select the item starting with list_detail_rate.htm?itemId=35648967399.

Then click this option, we can see the information about the link in the right option box, we want to copy the link content in the Request URL.

We enter the url link we just obtained in the address bar of the browser. After opening it, we will find that the page returns the data we need, but it looks very messy. Because this is json data.

2 Get the json data returned by the ajax request
Next step, we need to get the url json data in. The python editor I use is pycharm. Let’s take a look at the python code:
# -*- coding: utf-8 -*- import sys reload(sys) sys.setdefaultencoding('utf-8') import requests url='https://rate.tmall.com/list_detail_rate.htm?itemId=35648967399&spuId=226460655&sellerId=1809124267ℴ=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=011UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5OcktyT3ZCf0B9Qn9GeC4%3D%7CU2xMHDJ7G2AHYg8hAS8WKAYmCFQ1Uz9YJlxyJHI%3D%7CVGhXd1llXGVYYVVoV2pVaFFvWGVHe0Z%2FRHFMeUB4QHxCdkh8SXJcCg%3D%3D%7CVWldfS0RMQ47ASEdJwcpSDdNPm4LNBA7RiJLDXIJZBk3YTc%3D%7CVmhIGCUFOBgkGiMXNwswCzALKxcpEikJMwg9HSEfJB8%2FBToPWQ8%3D%7CV29PHzEfP29VbFZ2SnBKdiAAPR0zHT0BOQI8A1UD%7CWGFBET8RMQszDy8QLxUuDjIJNQA1YzU%3D%7CWWBAED4QMAU%2BASEYLBksDDAEOgA1YzU%3D%7CWmJCEjwSMmJXb1d3T3JMc1NmWGJAeFhmW2JCfEZmWGw6GicHKQcnGCUdIBpMGg%3D%3D%7CW2JfYkJ%2FX2BAfEV5WWdfZUV8XGBUdEBgVXVJciQ%3D&isg=82B6A3A1ED52A6996BCA2111C9DAAEE6&_ksTS=1440490222698_2142&callback=jsonp2143' #这里的url比较长 content=requests.get(url).content
print content #The printed content is what we previously obtained from the web page json data. Include user comments.
The content here is the json data we need. The next step is to parse these json data.
Three uses python to parse json data
# -*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import requests
import json
import re
url='https://rate.tmall.com/list_detail_rate.htm?itemId=35648967399&spuId=226460655&sellerId=1809124267ℴ=3¤tPage=1&append=0&content=1&tagId=&posi=&picture=&ua=011UW5TcyMNYQwiAiwQRHhBfEF8QXtHcklnMWc%3D%7CUm5OcktyT3ZCf0B9Qn9GeC4%3D%7CU2xMHDJ7G2AHYg8hAS8WKAYmCFQ1Uz9YJlxyJHI%3D%7CVGhXd1llXGVYYVVoV2pVaFFvWGVHe0Z%2FRHFMeUB4QHxCdkh8SXJcCg%3D%3D%7CVWldfS0RMQ47ASEdJwcpSDdNPm4LNBA7RiJLDXIJZBk3YTc%3D%7CVmhIGCUFOBgkGiMXNwswCzALKxcpEikJMwg9HSEfJB8%2FBToPWQ8%3D%7CV29PHzEfP29VbFZ2SnBKdiAAPR0zHT0BOQI8A1UD%7CWGFBET8RMQszDy8QLxUuDjIJNQA1YzU%3D%7CWWBAED4QMAU%2BASEYLBksDDAEOgA1YzU%3D%7CWmJCEjwSMmJXb1d3T3JMc1NmWGJAeFhmW2JCfEZmWGw6GicHKQcnGCUdIBpMGg%3D%3D%7CW2JfYkJ%2FX2BAfEV5WWdfZUV8XGBUdEBgVXVJciQ%3D&isg=82B6A3A1ED52A6996BCA2111C9DAAEE6&_ksTS=1440490222698_2142&callback=jsonp2143'
cont=requests.get(url).content
rex=re.compile(r'\w+[(]{1}(.*)[)]{1}')
content=rex.findall(cont)[0]
con=json.loads(content,"gbk")
count=len(con['rateDetail']['rateList'])
for i in xrange(count):
print con['rateDetail']['rateList'][i]['appendComment']['content']

Analysis:
Here you need to import the required package, re is the package required for regular expressions, and to parse json data you need to import json
cont=requests.get(url).content #Get JSON data in the web page
rex=re.compile(r'\w [(]{1}(.*)[)]{1}') #Regular expression removes the redundant part of the cont data, The data becomes real json format data {"a":"b","c":"d"}
con=json.loads(content,"gbk") Use json's loads function to The content content is converted into a data format that can be processed by the json library function. "gbk" is the encoding method of the data. Since the win system defaults to gbk
count=len(con['rateDetail']['rateList']) #Get the number of user comments (here is only for the current page)
for i in xrange(count):
print con['rateDetail']['rateList'][i][ 'appendComment']
#Loop through the user's comments and output (you can also save the data according to your needs, you can check the fourth part)
The difficulty here is to find the user in the messy json data Comment path
4 Save the parsed results
Here the user can save the user's comment information locally, such as saving it in csv format.
The above is the entire article, I hope you all like it.
The above is the detailed content of Taking the example of grabbing Taobao comments to explain how Python crawls data dynamically generated by ajax (classic). For more information, please follow other related articles on the PHP Chinese website!