

 DatabaseMysql TutorialThe difference between the index implementation methods of MyISAM and InnoDB storage engines
DatabaseMysql TutorialThe difference between the index implementation methods of MyISAM and InnoDB storage engines1. MyISAM index implementation:
1) Primary key index:
MyISAM engine uses B+Tree as the index structure, and the data field of the leaf node stores The address of the data record. The following figure is the schematic diagram of MyISAM primary key index:

2) Secondary index (Secondary key)
In MyISAM, there is no structural difference between the primary index and the secondary index (Secondary key). The primary index requires the key to be unique, while the key of the secondary index can be repeated.
If we create an auxiliary index on Col2, the structure of this index is as shown below:

MyISAM is to first search the index according to the B+Tree search algorithm. If the specified Key exists, the value of its data field is taken out, and then the value of the data field is used as the address to read the corresponding data record. .
MyISAM's indexing method is also called "non-clustered". The reason why it is called so is to distinguish it from InnoDB's clustered index.
2. InnoDB index implementation
1) Primary key index:
MyISAM index file and data file are separated, and the index file only saves the address of the data record. In InnoDB, the table data file itself is an index structure organized by B+Tree, and the leaf node data field of this tree saves complete data records. The key of this index is the primary key of the data table, so the InnoDB table data file itself is the primary index.
##
(Figure inndb primary key index) is a schematic diagram of the InnoDB primary index (also a data file). You can see that the leaf nodes contain complete data records. This kind of index is called clustered index. Because InnoDB's data files themselves are aggregated by primary key, InnoDB requires that the table must have a primary key (MyISAM may not have one). If it is not explicitly specified, the MySQL system will automatically select a column that can uniquely identify the data record as the primary key. If it does not exist, For this type of column, MySQL automatically generates an implicit field as the primary key for the InnoDB table. The length of this field is 6 bytes and the type is long.
2). InnoDB’s auxiliary index
All auxiliary indexes in InnoDB refer to the primary key as the data field. For example, the following figure shows an auxiliary index defined on Col3:

## The InnoDB table is built based on a clustered index. Therefore, InnoDB's index can provide a very fast primary key lookup performance. However, its auxiliary index (Secondary Index, that is, non-primary key index) will also contain the primary key column, so if the primary key is defined relatively large, other indexes will also be large. If you want to define many indexes on the table, try to define the primary key as small as possible. InnoDB does not compress indexes.
The ASCII code of the text character is used as the comparison criterion.This implementation of clustered index makes searching by primary key very efficient, but auxiliary index search requires retrieving the index twice: first, retrieve the auxiliary index to obtain the primary key, and then use the primary key to retrieve the records in the primary index.
The index implementation methods of different storage engines are very helpful for the correct use and optimization of indexes. For example, after knowing the index implementation of InnoDB, it is easy to understand why it is not recommended to use overly long fields as primary keys. , because all secondary indexes refer to the primary index, a primary index that is too long will make the secondary index too large. For another example, using non-monotonic fields as primary keys is not a good idea in InnoDB because the InnoDB data file itself is a B+Tree. Non-monotonic primary keys will cause the data file to maintain the characteristics of the B+Tree when inserting new records. Frequent split adjustments are very inefficient, and using auto-increment fields as primary keys is a good choice.The difference between InnoDB index and MyISAM index :
First, the difference between the main index, the InnoDB data file itself is the index file . The index and data of MyISAM are separated. The second is the difference between auxiliary indexes: InnoDB's auxiliary index data field stores the value of the corresponding record's primary key instead of the address. There is not much difference between MyISAM's secondary index and the primary index.MySql index algorithm principle analysis (easy to understand, only talking about B-tree)

The above is the detailed content of The difference between the index implementation methods of MyISAM and InnoDB storage engines. For more information, please follow other related articles on the PHP Chinese website!

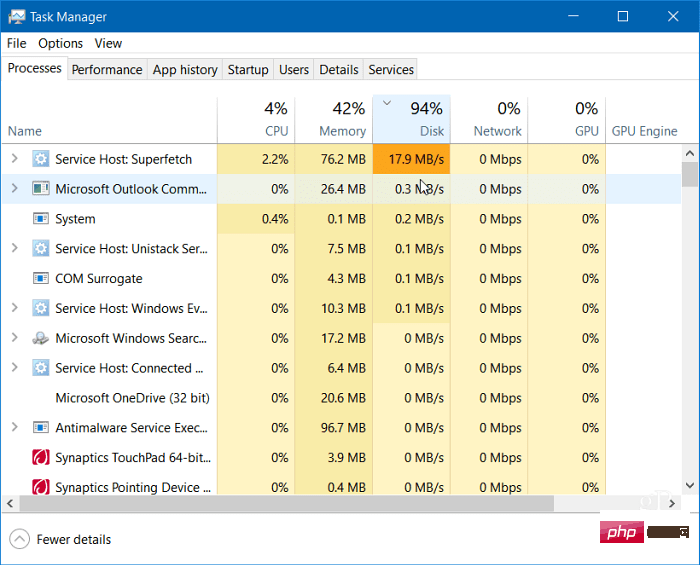 如何在 Windows 11 上修复 100% 的磁盘使用率Apr 20, 2023 pm 12:58 PM
如何在 Windows 11 上修复 100% 的磁盘使用率Apr 20, 2023 pm 12:58 PM如何在Window11上修复100%的磁盘使用率查找导致100%磁盘使用的有问题的应用程序或服务的直接方法是使用任务管理器。要打开任务管理器,请右键单击开始菜单并选择任务管理器。单击磁盘列标题,查看占用最多资源的内容。从那里开始,您将很好地了解从哪里开始。但是,问题可能比仅仅关闭应用程序或禁用服务更严重。继续阅读以查找问题的更多潜在原因以及如何解决这些问题。禁用SuperfetchSuperfetch功能(在Windows11中也称为SysMain)有助于通过访问预取文件来减少启动时
 如何在 Windows 11 中隐藏文件和文件夹并从搜索中移除?Apr 26, 2023 pm 11:07 PM
如何在 Windows 11 中隐藏文件和文件夹并从搜索中移除?Apr 26, 2023 pm 11:07 PM<h2>如何在Windows11上从搜索中隐藏文件和文件夹</h2><p>我们首先要看的是自定义Windows搜索文件的位置。通过跳过这些特定位置,您应该可以更快地看到结果,同时还可以隐藏您想要保护的任何文件。</p><p>如果要从Windows11上的搜索中排除文件和文件夹,请使用以下步骤:</p><ol&
 以下是6种修复Windows 11搜索栏不可用的方法。May 08, 2023 pm 10:25 PM
以下是6种修复Windows 11搜索栏不可用的方法。May 08, 2023 pm 10:25 PM如果您的搜索栏在Windows11中不起作用,有几种快速方法可以立即启动并运行!任何微软操作系统有时都可能遇到故障,最新的操作系统不能免除该规则。此外,正如Reddit上的用户u/zebra_head1所指出的那样,同样的错误出现在Windows11的22H2Build22621.1413上。用户抱怨切换任务栏搜索框的选项随机消失。因此,您必须为任何情况做好准备。为什么我无法在计算机上的搜索栏中键入内容?无法在计算机上键入可归因于不同的因素和过程。以下是您应该注意的一些事项:Ctfmon.
 mysql innodb是什么Apr 14, 2023 am 10:19 AM
mysql innodb是什么Apr 14, 2023 am 10:19 AMInnoDB是MySQL的数据库引擎之一,现为MySQL的默认存储引擎,为MySQL AB发布binary的标准之一;InnoDB采用双轨制授权,一个是GPL授权,另一个是专有软件授权。InnoDB是事务型数据库的首选引擎,支持事务安全表(ACID);InnoDB支持行级锁,行级锁可以最大程度的支持并发,行级锁是由存储引擎层实现的。
 MySQL如何从二进制内容看InnoDB行格式Jun 03, 2023 am 09:55 AM
MySQL如何从二进制内容看InnoDB行格式Jun 03, 2023 am 09:55 AMInnoDB是一个将表中的数据存储到磁盘上的存储引擎,所以即使关机后重启我们的数据还是存在的。而真正处理数据的过程是发生在内存中的,所以需要把磁盘中的数据加载到内存中,如果是处理写入或修改请求的话,还需要把内存中的内容刷新到磁盘上。而我们知道读写磁盘的速度非常慢,和内存读写差了几个数量级,所以当我们想从表中获取某些记录时,InnoDB存储引擎需要一条一条的把记录从磁盘上读出来么?InnoDB采取的方式是:将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB中页的大小一般为16
 Windows 11 Outlook 搜索不工作:6 个修复方法Apr 22, 2023 pm 09:46 PM
Windows 11 Outlook 搜索不工作:6 个修复方法Apr 22, 2023 pm 09:46 PM在Outlook中运行搜索和索引疑难解答您可以开始的更直接的修复之一是运行搜索和索引疑难解答。要在Windows11上运行疑难解答,请执行以下操作:单击开始按钮或按Windows键并从菜单中选择设置。当设置打开时,选择系统>疑难解答>其他疑难解答。在右侧向下滚动,找到SearchandIndexing,然后单击Run按钮。选择Outlook搜索不返回结果并继续屏幕上的说明。当您运行它时,疑难解答程序将自动识别并修复问题。运行疑难解答后,打开Outlook并查看搜索是否正常。如
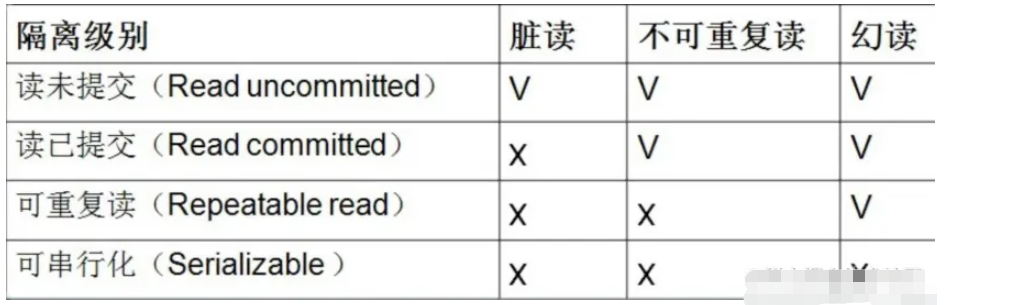 Mysql中的innoDB怎么解决幻读May 27, 2023 pm 03:34 PM
Mysql中的innoDB怎么解决幻读May 27, 2023 pm 03:34 PM1.Mysql的事务隔离级别这四种隔离级别,当存在多个事务并发冲突的时候,可能会出现脏读,不可重复读,幻读的一些问题,而innoDB在可重复读隔离级别模式下解决了幻读的一个问题,2.什么是幻读幻读是指在同一个事务中,前后两次查询相同范围的时候得到的结果不一致如图,第一个事务里面,我们执行一个范围查询,这个时候满足条件的数据只有一条,而在第二个事务里面,它插入一行数据并且进行了提交,接着第一个事务再去查询的时候,得到的结果比第一次查询的结果多出来一条数据,注意第一个事务的第一次和第二次查询,都在同
 mysql innodb异常怎么处理Apr 17, 2023 pm 09:01 PM
mysql innodb异常怎么处理Apr 17, 2023 pm 09:01 PM一、回退重新装mysql为避免再从其他地方导入这个数据的麻烦,先对当前库的数据库文件做了个备份(/var/lib/mysql/位置)。接下来将Perconaserver5.7包进行了卸载,重新安装原先老的5.1.71的包,启动mysql服务,提示Unknown/unsupportedtabletype:innodb,无法正常启动。11050912:04:27InnoDB:Initializingbufferpool,size=384.0M11050912:04:27InnoDB:Complete


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

Dreamweaver Mac version
Visual web development tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

