

 Operation and MaintenanceLinux Operation and MaintenanceA detailed introduction to memory management in Linux
Operation and MaintenanceLinux Operation and MaintenanceA detailed introduction to memory management in LinuxI read "In-depth Understanding of the Linux Kernel" some time ago and spent a lot of time on the memory management part, but there are still many questions that are not very clear. I recently spent some time reviewing it and recorded myself here. understanding and some views and knowledge on memory management in Linux.
I prefer to understand the development process of a technology itself. In short, it is how this technology developed, what technologies existed before this technology, what are the characteristics of these technologies, and why are they currently used? It has been replaced by new technology, and the current technology has solved the problems of the previous technology. Once we understand these, we can have a clearer grasp of a certain technology. Some materials directly introduce the meaning and principles of a certain concept without mentioning the development process and the principles behind it, as if the technology fell from the sky. At this point, let’s talk about today’s topic based on the development history of memory management.
First of all, I must explain that the topic of this article is segmentation and paging technology in Linux memory management.
Let’s take a look back at history. In early computers, programs ran directly on physical memory. In other words, all the programs access during running are physical addresses. If this system only runs one program, then as long as the memory required by this program does not exceed the physical memory of the machine, there will be no problem, and we do not need to consider the troublesome memory management. Anyway, it is just your program, that's it. Save some money, it's up to you whether you eat enough or not. However, today's systems all support multi-tasking and multi-processing, so the utilization of the CPU and other hardware will be higher. At this time, we must consider how to allocate the limited physical memory in the system to multiple programs in a timely and effective manner. , this matter itself is called memory management.
Let’s give an example of memory allocation management in an early computer system to facilitate everyone’s understanding.
We have three programs, Program 1, 2, and 3. Program 1 requires 10M memory during running, Program 2 requires 100M memory during running, and Program 3 requires 20M memory during running. If the system needs to run programs A and B at the same time, the early memory management process is probably like this, allocating the first 10M of physical memory to A, and the next 10M-110M to B. This method of memory management is relatively straightforward. Okay, let's assume that we want program C to run at this time, and assume that the memory of our system is only 128M. Obviously, according to this method, program C cannot run due to insufficient memory. Everyone knows that you can use virtual memory technology. When the memory space is not enough, you can swap data that is not used by the program to disk space, which has achieved the purpose of expanding the memory space. Let's take a look at some of the more obvious problems with this memory management method. As mentioned at the beginning of the article, to have a deep understanding of a technology it is best to understand its development history.
1. The process address space cannot be isolated
Since the program directly accesses physical memory, the memory space used by the program is not isolated at this time. For example, as mentioned above, the address space of A is in the range of 0-10M, but if there is a piece of code in A that operates data in the address space of 10M-128M, then program B and program C are likely to will crash (every program can take the entire address space of the system). In this way, many malicious programs or Trojan horse programs can easily break other programs, and the security of the system cannot be guaranteed, which is intolerable to users.
2. Memory usage is inefficient
As mentioned above, if we want to let programs A, B, and C run at the same time, then the only way is to use virtual memory technology to combine some Data that is not temporarily used by the program is written to the disk, and is read back from the disk to the memory when needed. Here, program C needs to run, so swapping A to the disk is obviously not possible, because the program requires a continuous address space. Program C requires 20M of memory, and A only has 10M of space, so program B needs to be swapped to the disk. , and B is fully 100M. We can see that in order to run program C, we need to write 100M of data from memory to disk, and then read it from disk to memory when program B needs to run. We know that IO operations are time-consuming. So the efficiency of this process will be very low.
3. The address where the program runs cannot be determined
Every time the program needs to be run, it needs to allocate a large enough free area in the memory. The problem is that this free location cannot Sure, this will bring about some relocation problems. The relocation problem must be the addresses of variables and functions referenced in the program. If you don't understand, you can check the compilation information.
Memory management is nothing more than finding ways to solve the above three problems, how to isolate the address space of the process, how to improve the efficiency of memory usage, and how to solve the relocation problem when the program is running?
Here is a quote from the computer industry that cannot be verified: "Any problem in a computer system can be solved by introducing an intermediate layer."
The current memory management method introduces the concept of virtual memory between the program and physical memory. Virtual memory is located between the program and the internal memory. The program can only see virtual memory and can no longer directly access physical memory. Each program has its own independent process address space, thus achieving process isolation. The process address space here refers to the virtual address. As the name suggests, since it is a virtual address, it is virtual and not a real address space.
Since we have added a virtual address between the program and the physical address space, we need to solve how to map from the virtual address to the physical address, because the program must eventually run in physical memory, mainly segmented and paging two technologies.
Segmentation: This method is one of the first methods people used. The basic idea is to map the virtual space of the memory address space required by the program to a certain physical address space.
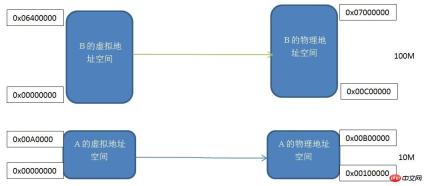
Segment mapping mechanism
Each program has its own virtual independent process address space. You can see the virtual addresses of programs A and B. The spaces all start from 0x00000000. We map two virtual address spaces of the same size to the actual physical address space one by one, that is, each byte in the virtual address space corresponds to each byte in the actual address space. This mapping process is set by software. mechanism, the actual conversion is done by hardware.
This segmented mechanism solves the three problems mentioned at the beginning of the article: process address space isolation and program address relocation. Program A and Program B have their own independent virtual address spaces, and the virtual address spaces are mapped to non-overlapping physical address spaces. If the address that Program A accesses the virtual address space is not in the range of 0x00000000-0x00A00000, then the kernel will Deny this request, so it solves the problem of isolating the address space. Our application A only needs to care about its virtual address space 0x00000000-0x00A00000, and we do not need to care about which physical address it is mapped to, so the program will always place variables and code according to this virtual address space without relocation.
Regardless, the segmentation mechanism solves the above two problems, which is a great progress, but it is still powerless to solve the problem of memory efficiency. Because this memory mapping mechanism is still based on the program, when the memory is insufficient, the entire program still needs to be swapped to the disk, so the memory usage efficiency is still very low. So, what is considered efficient memory usage? In fact, according to the local operation principle of the program, during a certain period of time during the running of a program, only a small part of the data will be frequently used. So we need a more fine-grained memory partitioning and mapping method. At this time, will you think of the Buddy algorithm and slab memory allocation mechanism in Linux, haha. Another way to convert virtual addresses into physical addresses is the paging mechanism.
Paging mechanism:
The paging mechanism is to divide the memory address space into several small fixed-size pages. The size of each page is determined by the memory, just like the ext file system in Linux Dividing the disk into several Blocks is done to improve memory and disk utilization respectively. Imagine the following, if the disk space is divided into N equal parts, the size of each part (one Block) is 1M, and if the file I want to store on the disk is 1K bytes, then the remaining 999 bytes are wasted. Therefore, a more fine-grained disk partitioning method is needed. We can set the Block to be smaller. This is of course based on the size of the stored files. It seems a bit off topic. I just want to say that the paging mechanism in memory is different from ext. The disk partitioning mechanism in file systems is very similar.
The general page size in Linux is 4KB. We divide the address space of the process by pages, load commonly used data and code pages into the memory, and save the less commonly used code and data in the disk. We still Let’s take an example to illustrate, as shown below:
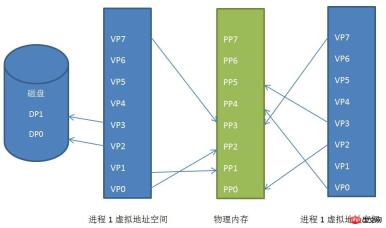
Page mapping relationship between process virtual address space, physical address space and disk
We can see The virtual address spaces of process 1 and process 2 are mapped into discontinuous physical address spaces (this is of great significance, if one day we do not have enough continuous physical address space, but there are many discontinuous address spaces, if there is no such technology , our program cannot run), even they share a part of the physical address space, which is shared memory.
The virtual pages VP2 and VP3 of process 1 are swapped to the disk. When the program needs these two pages, the Linux kernel will generate a page fault exception, and then the exception management program will read it into the memory.
This is the principle of the paging mechanism. Of course, the implementation of the paging mechanism in Linux is still relatively complicated. It is implemented through several levels of paging mechanisms such as the global directory, the upper-level directory, the page intermediate directory, and the page table. Yes, but the basic working principle will not change.
The implementation of the paging mechanism requires hardware implementation. The name of this hardware is MMU (Memory Management Unit). It is specifically responsible for converting from virtual addresses to physical addresses, that is, finding physical pages from virtual pages.
The above is the detailed content of A detailed introduction to memory management in Linux. For more information, please follow other related articles on the PHP Chinese website!

 The 5 Core Components of the Linux Operating SystemMay 08, 2025 am 12:08 AM
The 5 Core Components of the Linux Operating SystemMay 08, 2025 am 12:08 AMThe five core components of the Linux operating system are: 1. Kernel, 2. System libraries, 3. System tools, 4. System services, 5. File system. These components work together to ensure the stable and efficient operation of the system, and together form a powerful and flexible operating system.
 The 5 Essential Elements of Linux: ExplainedMay 07, 2025 am 12:14 AM
The 5 Essential Elements of Linux: ExplainedMay 07, 2025 am 12:14 AMThe five core elements of Linux are: 1. Kernel, 2. Command line interface, 3. File system, 4. Package management, 5. Community and open source. Together, these elements define the nature and functionality of Linux.
 Linux Operations: Security and User ManagementMay 06, 2025 am 12:04 AM
Linux Operations: Security and User ManagementMay 06, 2025 am 12:04 AMLinux user management and security can be achieved through the following steps: 1. Create users and groups, using commands such as sudouseradd-m-gdevelopers-s/bin/bashjohn. 2. Bulkly create users and set password policies, using the for loop and chpasswd commands. 3. Check and fix common errors, home directory and shell settings. 4. Implement best practices such as strong cryptographic policies, regular audits and the principle of minimum authority. 5. Optimize performance, use sudo and adjust PAM module configuration. Through these methods, users can be effectively managed and system security can be improved.
 Linux Operations: File System, Processes, and MoreMay 05, 2025 am 12:16 AM
Linux Operations: File System, Processes, and MoreMay 05, 2025 am 12:16 AMThe core operations of Linux file system and process management include file system management and process control. 1) File system operations include creating, deleting, copying and moving files or directories, using commands such as mkdir, rmdir, cp and mv. 2) Process management involves starting, monitoring and killing processes, using commands such as ./my_script.sh&, top and kill.
 Linux Operations: Shell Scripting and AutomationMay 04, 2025 am 12:15 AM
Linux Operations: Shell Scripting and AutomationMay 04, 2025 am 12:15 AMShell scripts are powerful tools for automated execution of commands in Linux systems. 1) The shell script executes commands line by line through the interpreter to process variable substitution and conditional judgment. 2) The basic usage includes backup operations, such as using the tar command to back up the directory. 3) Advanced usage involves the use of functions and case statements to manage services. 4) Debugging skills include using set-x to enable debugging mode and set-e to exit when the command fails. 5) Performance optimization is recommended to avoid subshells, use arrays and optimization loops.
 Linux Operations: Understanding the Core FunctionalityMay 03, 2025 am 12:09 AM
Linux Operations: Understanding the Core FunctionalityMay 03, 2025 am 12:09 AMLinux is a Unix-based multi-user, multi-tasking operating system that emphasizes simplicity, modularity and openness. Its core functions include: file system: organized in a tree structure, supports multiple file systems such as ext4, XFS, Btrfs, and use df-T to view file system types. Process management: View the process through the ps command, manage the process using PID, involving priority settings and signal processing. Network configuration: Flexible setting of IP addresses and managing network services, and use sudoipaddradd to configure IP. These features are applied in real-life operations through basic commands and advanced script automation, improving efficiency and reducing errors.
 Linux: Entering and Exiting Maintenance ModeMay 02, 2025 am 12:01 AM
Linux: Entering and Exiting Maintenance ModeMay 02, 2025 am 12:01 AMThe methods to enter Linux maintenance mode include: 1. Edit the GRUB configuration file, add "single" or "1" parameters and update the GRUB configuration; 2. Edit the startup parameters in the GRUB menu, add "single" or "1". Exit maintenance mode only requires restarting the system. With these steps, you can quickly enter maintenance mode when needed and exit safely, ensuring system stability and security.
 Understanding Linux: The Core Components DefinedMay 01, 2025 am 12:19 AM
Understanding Linux: The Core Components DefinedMay 01, 2025 am 12:19 AMThe core components of Linux include kernel, shell, file system, process management and memory management. 1) Kernel management system resources, 2) shell provides user interaction interface, 3) file system supports multiple formats, 4) Process management is implemented through system calls such as fork, and 5) memory management uses virtual memory technology.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

SublimeText3 Chinese version
Chinese version, very easy to use

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Atom editor mac version download
The most popular open source editor

