
Home >Backend Development >Python Tutorial >What is a crawler? What is the basic process of crawler?
What is a crawler? What is the basic process of crawler?

- 零下一度Original
- 2017-07-23 13:41:0337011browse
A web crawler is a program, mainly used for search engines. It reads all the content and links of a website, builds relevant full-text indexes into the database, and then jumps to another website. It looks like A big spider.
When people search for keywords on the Internet (such as Google), they are actually comparing the content in the database to find those that match the user. The quality of the web crawler program determines the ability of the search engine , for example, Google’s search engine is obviously better than Baidu, because its web crawler program is efficient and its programming structure is good.
1. What is a crawler
First of all, let’s briefly understand the crawler. That is a process of requesting a website and extracting the data you need. As for how to climb and how to climb, it will be the content of learning later, so there is no need to go into it for now. Through our program, we can send requests to the server on our behalf, and then download large amounts of data in batches.
2. The basic process of the crawler
Initiate a request: initiate a request request to the server through the url, Requests can contain additional header information.
Get the response content: If the server responds normally, we will receive a response. The response is the content of the web page we requested, which may include HTML. Json string or binary data (video, picture), etc.
Parse content: If it is HTML code, it can be parsed using a web page parser. If it is Json data, it can be converted into a Json object for parsing. If Is binary data, it can be saved to a file for further processing.
Save data: You can save it to a local file or to a database (MySQL, Redis, Mongodb, etc.)
3. What does the request contain?
When we send a request to the server through the browser When requesting, what information does this request contain? We can explain it through Chrome's developer tools (if you don't know how to use it, read the notes in this article).
Request method: The most commonly used request methods include get request and post request. The most common post request in development is to submit it through a form. From the user's perspective, the most common one is login verification. When you need to enter some information to log in, this request is a post request.
url Uniform Resource Locator: A URL, a picture, a video, etc. can all be defined using URL. When we request a web page, we can view the network tag. The first one is usually a document, which means that this document is an HTML code that is not rendered with external images, css, js, etc. Below this document we will see To a series of jpg, js, etc., this is a request initiated by the browser again and again based on the html code, and the requested address is the url address of the image, js, etc. in the html document
request headers: Request headers, including the request type of this request, cookie information, browser type, etc. This request header is still useful when we crawl web pages. The server will review the information by parsing the request header to determine whether the request is a legitimate request. So when we make a request through a program that disguises the browser, we can set the request header information.
Request body: The post request will package the user information in form-data for submission, so compared to the get request, the content of the Headers tag of the post request There will be an additional information package called Form Data. The get request can be simply understood as an ordinary search carriage return, and the information will be added at the end of the url at ? intervals.
4. What does the response contain
##Response status: The status code can be seen through General in Headers. 200 indicates success, 301 jump, 404 web page not found, 502 server error, etc.
#Response header: includes content type, cookie information, etc.
Response body: The purpose of the request is to get the response body, including html code, Json and binary data.
5. Simple request demonstration
Perform web page requests through Python's request library :

The output result is the web page code that has not yet been rendered, that is, the content of the request body. You can view the response header information:
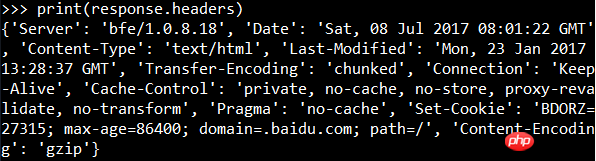
View status code:

You can also add the request header to the request information:
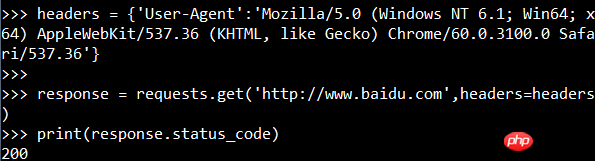
Grab the picture (Baidu logo):

6. How to solve JavaScript rendering problems
Use Selenium webdriver

Enter print(driver.page_source) and you can see that this time the code is the code after rendering.
【Remarks】Using chrome browser
##F12 to open the developer tools
 ##
##
Network tag
##
The above is the detailed content of What is a crawler? What is the basic process of crawler?. For more information, please follow other related articles on the PHP Chinese website!