
Home >Backend Development >Python Tutorial >Python--Introduction to the BeautifulSoup library
Python--Introduction to the BeautifulSoup library

- 零下一度Original
- 2017-06-23 11:14:513159browse
Beautiful Soup parses anything you give it, and does the tree traversal stuff for you.
BeautifulSoup library is a functional library for parsing, traversing, and maintaining "tag trees" (traversal, It refers to visiting each node in the tree once and only once along a certain search route).
We often call the BeautifulSoup library bs4. To import the library: from bs4 import BeautifulSoup. Among them, import BeautifulSoup mainly uses the BeautifulSoup class in bs4.
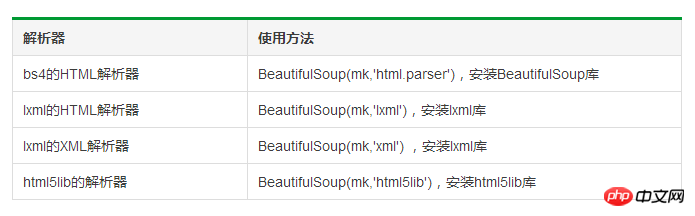
bs4 library parser
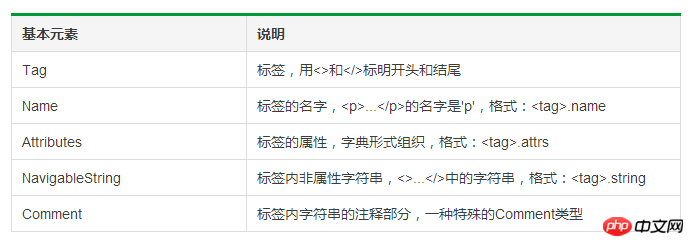
##Basic elements of the BeautifulSoup class
1 import requests 2 from bs4 import BeautifulSoup 3 4 res = requests.get('') 5 soup = BeautifulSoup(res.text,'lxml') 6 print(soup.a) 7 # 任何存在于HTML语法中的标签都可以用soup.<tag>访问获得,当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个。 8 9 print(soup.a.name)10 # 每个<tag>都有自己的名字,可以通过<tag>.name获取,字符串类型11 12 print(soup.a.attrs)13 print(soup.a.attrs['class'])14 # 一个<tag>可能有一个或多个属性,是字典类型15 16 print(soup.a.string)17 # <tag>.string可以取到标签内非属性字符串18 19 soup1 = BeautifulSoup('<p><!--这里是注释--></p>','lxml')20 print(soup1.p.string)21 print(type(soup1.p.string))22 # comment是一种特殊类型,也可以通过<tag>.string取到
Run result:
a
## {'href': '', 'class': ['no- login']} ['no-login']Login
Here are the comments
HTML content traversal of bs4 libraryThe basic structure of HTML
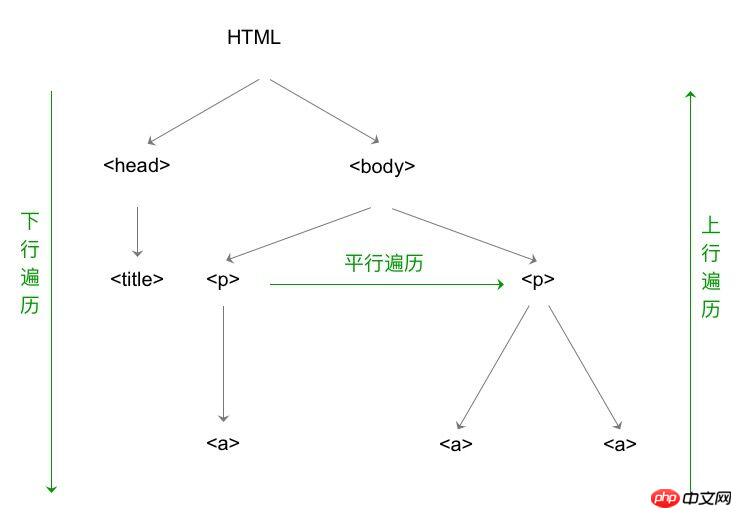
Downward traversal of the tag tree
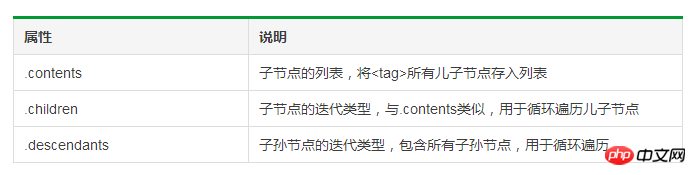 Among them, BeautifulSoup Type is the root node of the tag tree.
Among them, BeautifulSoup Type is the root node of the tag tree.
1 # 遍历儿子节点2 for child in soup.body.children:3 print(child.name)4 5 # 遍历子孙节点6 for child in soup.body.descendants:7 print(child.name)
Upward traversal of the tag tree
##
1 # 遍历所有先辈节点时,包括soup本身,所以要if...else...判断2 for parent in soup.a.parents:3 if parent is None:4 print(parent)5 else:6 print(parent.name)

div
div
body
html
[document]
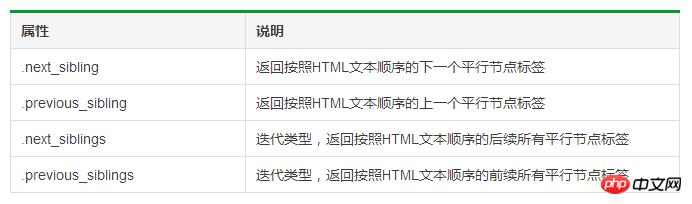
Parallel traversal of tag tree
1 # 遍历后续节点2 for sibling in soup.a.next_sibling:3 print(sibling)4 5 # 遍历前续节点6 for sibling in soup.a.previous_sibling:7 print(sibling)
 prettify() method of bs4 library
prettify() method of bs4 libraryprettify( ) method can standardize the code format, represented by soup.prettify(). In PyCharm, use print(soup.prettify()) to output.
Operating environment: Mac, Python 3.6, PyCharm 2016.2
Reference: Chinese University MOOC course "Python Web Crawler and Information Extraction"
The above is the detailed content of Python--Introduction to the BeautifulSoup library. For more information, please follow other related articles on the PHP Chinese website!