
Home >Operation and Maintenance >Linux Operation and Maintenance >linux processes and signals
linux processes and signals
- 巴扎黑Original
- 2017-06-23 13:49:162269browse
Directory of this article:
##9.1 Brief description of the process
9.11 The difference between process and program
9.12 Multitasking and cpu time slices
9.13 Parent-child processes and how to create processes
9.14 Process status
9.15 Example analysis of process status transition process
##9.16 Process Structure and Subshells
9.2 Job task
9.3 The relationship between the terminal and the process
9.4 Signals
##9.41 Signals you need to know
9.42 SIGHUP
##9.43 Zombie Processes and SIGCHLD9.44 Manually send signal (kill command)
9.45 pkill and killall
##9.5 fuser and lsof
9.1 Brief description of process
Process is a very complex concept and involves a lot of content. The content listed in this section has been extremely simplified by me. You should understand it as much as possible. I think these theories are more important than how to use commands to check the status. If you don’t understand these theories, you can check the status information later. Basically, I don’t know what the corresponding status means.
9.1.1 The difference between a process and a program
A program is a binary file that is statically stored on the disk and does not occupy system running resources (cpu /Memory).
9.1.2 Multitasking and CPU time slices
Now all operating systems can run multiple processes "simultaneously", that is, multitasking or It is said to be executed in parallel. But in fact this is a human illusion.
A physical CPU can only run one process at the same time. Only multiple physical CPUs can truly achieve multitasking
However, how the CPU chooses the next process to execute is a very complicated matter. On Linux, determining the next process to run is achieved through the "scheduling class" (scheduler)
. When a program runs is determined by the priority of the process, but be aware that the lower the priority value, the higher the priority and the sooner it will be selected by the scheduling class. In Linux, changing the nice value of a process can affect the priority value of a certain type of process.Some processes are more important and should be completed as soon as possible, while some processes are more minor and completing them earlier or later will not have much impact. Therefore, the operating system must be able to know which processes are more important and which processes are less important. For more important processes, more CPU execution time should be allocated to it so that it can be completed as soon as possible. The figure below is the concept of CPU time slice.

It can be known that all processes have the opportunity to run, but important processes will always get more CPU time. This method is "preemptive multi-process" Task processing": The kernel can force the CPU usage rights to be taken back when the time slice is exhausted, and hand the CPU to the process selected by the scheduling class. In addition, in some cases, it can also directly preempt the currently running process. As time goes by, the time allocated to the process will gradually be consumed. When the allocated time is consumed, the kernel takes back control of the process and lets the next process run. But because the previous process has not been completed, the scheduling class will still select it at some time in the future, so the kernel should save the runtime environment (contents in registers and page tables) when each process is temporarily stopped (the save location is The memory occupied by the kernel), this is called the protection site. The next time the process resumes running, the original runtime environment is loaded onto the CPU. This is called the recovery site, so that the CPU can continue to execute in the original runtime environment.
Reading books say that the Linux scheduler does not select the next process to run based on the elapse of the CPU time slice, but considers the waiting time of the process, that is, how long it has waited in the ready queue, and those who are interested in the time. Processes with the most stringent requirements should be scheduled for execution as early as possible. In addition, important processes will naturally allocate more CPU running time.
After the scheduling class selects the next process to be executed, it must perform underlying task switching, that is, context switching. This process requires close interaction with the CPU process. Process switching should not be too frequent, nor should it be too slow. Switching too frequently will cause the CPU to idle for too long in the protection and recovery scene, which is not productive for humans or processes (because it is not executing programs). Switching too slowly will result in slow process scheduling switching. It is very likely that the next process will have to wait a long time before it is its turn to execute. To put it bluntly, if you issue an ls command, you may have to wait for half a day, which is obviously not allowed. of.
At this point, we know that the unit of measurement of cpu is time, just like the unit of measurement of memory is the size of space. If a process takes up a long time on the CPU, it means that the CPU is running on it for a long time. Note that the percentage value of a CPU is not its work intensity or frequency, but "process occupied cpu time/total cpu time". This measurement concept must not be mistaken.
9.1.3 Parent-child processes and methods of creating processes
A unique process will be assigned to each process based on the UID of the user executing the program and other criteria. PID.
The concept of parent-child process. Simply put, when a program is executed or called in the context of a certain process (parent process), the process triggered by this program is the child process, and the PPID of the process represents the parent of the process. The PID of the process. From this we also know that The child process is always created by the parent process.
In Linux, parent-child processes exist in a tree structure, and multiple child processes created by a parent process are called sibling processes. On CentOS 6, the init process is the parent process of all processes, and on CentOS 7 it is systemd.
There are three ways to create child processes on Linux (an extremely important concept): one is a fork process, one is an exec process, and one is a clone process.
(1).fork is a copy process, which copies a copy of the current process (regardless of the copy-on-write mode) and hands these resources to the child process in an appropriate manner. Therefore, the resources controlled by the child process are the same as those of the parent process, including the contents of the memory, so it also includes environment variables and variables. But the parent and child processes are completely independent. They are two instances of the same program.
(2).exec is to load another application to replace the currently running process, which means loading a new program without creating a new process. exec also has another action. After the process is executed, exit the shell where exec is located. Therefore, in order to ensure process security, if you want to form a new and independent child process, you will first fork a copy of the current process, and then call exec on the forked child process to load a new program to replace the child process. For example, when executing the cp command under bash, a bash will be forked first, and then exec will load the cp program to overwrite the sub-bash process and become the cp process.
(3).clone is used to implement threads. The working principle of clone is the same as that of fork, but the new process cloned is not independent of the parent process. It will only share certain resources with the parent process. When cloning the process, you can specify which resources are to be shared.
Under normal circumstances, sibling processes are independent and invisible to each other, but sometimes through special means, they will achieve inter-process communication. For example, a pipe coordinates the processes on both sides. The processes on both sides belong to the same process group and their PPIDs are the same. The pipe allows them to transfer data in a "pipeline" manner.
A process has an owner, that is, its initiator. If a user is not the process initiator, the parent process initiator, or the root user, then it cannot kill the process. And killing the parent process (non-terminal process) will cause the child process to become an orphan process. The parent process of the orphan process is always init/systemd.
9.1.4 Process status
The process is not always running, at least it is non-running when the CPU is not running on it. A process has several states, and state switching can be achieved between different states. The picture below is a very classic process status description diagram. I personally feel that the picture on the right is easier to understand.
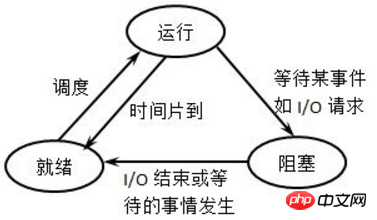
Running state: The process is running, that is, the CPU is on it.
Ready (waiting) state: The process can run and is already in the waiting queue, which means that the scheduling class may select it next time
Sleep (blocked) state: The process is sleeping and cannot run.
The conversion method between each state is: (Maybe it may not be easy to understand, you can combine it with a later example)
(1) New state -> Ready state: When the waiting queue is allowed When a new process is admitted, the kernel moves the new process into the waiting queue.
(2) Ready state -> Running state: The scheduling class selects a process in the waiting queue, and the process enters the running state.
(3) Running state -> Sleep state: The running process cannot execute because it needs to wait for the occurrence of a certain event (such as IO waiting, signal waiting, etc.) and enters the sleep state.
(4) Sleep state -> Ready state: When the event that the process is waiting for occurs, the process is queued from the sleep state to the waiting queue, waiting to be selected for execution next time.
(5) Running state -> Ready state: The executing process is suspended due to the time slice running out; or in the preemptive scheduling mode, the high-priority process forcibly preempts the executing low-priority process level process.
(6) Running state -> Termination state: When a process is completed or some special event occurs, the process will become terminated state. For commands, exit status codes are generally returned.
Note that in the above picture, there is no state switching between "Ready-->Sleep" and "Sleep-->Run". It's easy to understand. For "Ready-->Sleep", the waiting process has already entered the waiting queue, indicating that it can be run, and entering the sleep state means that it is temporarily unrunnable, which is a conflict in itself; for "Sleep-->Run" This also doesn't work because the scheduling class will just pick the next process to run from the waiting queue.
Let’s talk about the running state-->sleep state. From the running state to the sleep state, it is usually to wait for the occurrence of an event, such as waiting for a signal notification or waiting for IO to be completed. Signal notification is easy to understand, but for IO waiting, for the program to run, the CPU must execute the instructions of the program, and data must be input at the same time, which may be variable data, keyboard input data or data in disk files. The latter two types of data Compared to the CPU, they are extremely slow. But no matter what, if the CPU can't get the data at the moment it needs the data, the CPU can only sit idle. This is definitely not the case, because the CPU is an extremely precious resource, so the kernel should let the CPU run and need data. The process temporarily goes to sleep and waits until its data is ready before returning to the waiting queue and waiting to be selected by the scheduling class. This is IO waiting.
In fact, the above picture is missing a special state of the process-zombie state. The zombie process means that the process has been converted to the terminated state. It has completed its mission and disappeared, but the kernel has not had time to delete its entry in the process list, which means that the kernel has not To take care of its aftermath, this creates the illusion that a process is both dead and alive. It is said to be dead because it no longer consumes resources, and it is impossible for the scheduling class to select it and let it run. It is said to be alive because it is There is also a corresponding entry in the process list, which can be captured. The zombie process does not occupy many resources. It only occupies a little memory in the process list. Most zombie processes appear because the process terminates normally (including kill -9), but the parent process does not confirm that the process has terminated, so it is not notified to the kernel, and the kernel does not know that the process has terminated. For a more detailed description of the zombie process, see later.
In addition, sleep state is a very broad concept, divided into interruptible sleep and uninterruptible sleep. Interruptible sleep is a sleep that is allowed to be awakened by receiving external signals and kernel signals. The vast majority of sleep is interruptible sleep. The sleep that can be captured by ps or top is almost always interruptible sleep; uninterruptible sleep can only be controlled by the kernel. Initiate a signal to wake up. The outside world cannot wake up through signals, mainly when interacting with hardware. For example, when catting a file, loading data from the hard disk into the memory must be uninterruptible during the short period of time it interacts with the hardware. Otherwise, it will suddenly be manually awakened by an artificial signal when loading the data, and when it is awakened, it will not be interrupted. The hardware interaction process has not yet been completed, so even if it wakes up, it cannot give the CPU to run, so it is impossible to only display part of the content when catting a file. Moreover, if uninterruptible sleep can be artificially awakened, the more serious consequence will be hardware crash. It can be seen that uninterruptible sleep is to protect certain important processes and to prevent the CPU from being wasted. Generally, uninterruptible sleep is extremely short-lived and extremely difficult to capture non-programmatically.
In fact, as long as the process is found to exist, is not a zombie process, and does not occupy CPU resources, then it is sleeping. Including the pause state and tracking state that appear later in the article, they are also sleep states.
9.1.5 Example analysis of process state transition process
The state transition situation between processes may be very complicated. Here is an example to describe it in as much detail as possible. they.
Take executing the cp command under bash as an example. In the current bash environment, when it is in a runnable state (i.e. ready state), when the cp command is executed, a bash sub-process is first forked, and then the cp program is loaded by exec on the sub-bash. The cp sub-process enters the waiting queue. The command is typed on the command line, so it has a higher priority, and the scheduling class quickly selects it. During the execution of the child process cp, the parent process bash will enter the sleep state (not only because only one process can be executed at a time when there is only one cpu, but also because the process is waiting) and waits to be awakened. At this moment, bash cannot interact with humans. Interaction. When the cp command is executed, it will inform the parent process of its exit status code whether the copy is successful or failed. Then the cp process disappears by itself, and the parent process bash is awakened and enters the waiting queue again, and at this time bash has obtained cp. Exit status code. According to the "signal" of the status code, the parent process bash knows that the child process has terminated, so it notifies the kernel. After receiving the notification, the kernel deletes the cp process entry in the process list. At this point, the entire cp process is completed normally.
If the cp sub-process copies a large file and cannot complete the copy in one cpu time slice, it will enter the waiting queue when one cpu time slice is exhausted.
If the cp sub-process copies a file and there is already a file with the same name at the target location, it will ask by default whether to overwrite it. When asking, it waits for a yes or no signal, so it enters a sleep state (interruptible) Sleep), when typing yes or no signal to cp on the keyboard, cp receives the signal and switches from sleep state to ready state, waiting for the scheduling class to select it to complete the cp process.
When cp copies, it needs to interact with the disk. During the short process of interacting with the hardware, cp will be in uninterruptible sleep.
If the cp process ends, but there is some kind of accident during the ending process, so that the parent process of bash does not know that it has ended (this is impossible in this example), then bash will The kernel will not be notified to recycle the cp entry in the process list, and cp will become a zombie process at this time.
9.1.6 Process structure and subshell
Foreground process: General commands (such as the cp command) will fork the child process for execution. During the execution of the child process, the parent process The process will go to sleep, which is a foreground process. When the foreground process is executed, its parent process sleeps, because there is only one CPU, even if there are multiple CPUs, only one process can be executed due to the execution flow (process waiting). In order to achieve true For multitasking, in-process multithreading should be used to implement multiple execution streams.
Background process: If you add the symbol "&" at the end of the command when executing the command, it will enter the background. Putting the command into the background will immediately return to the parent process and return the jobid and pid of the background process, so the parent process of the background process will not go to sleep. When an error occurs in the background process, or when the execution is completed and the background process terminates, the parent process will receive the signal. Therefore, by adding "&" after the command, and then giving another command to be executed after the "&", can achieve "pseudo-parallel" execution , such as "cp /etc/fstab /tmp & cat /etc/fstab".
bash built-in commands: bash built-in commands are very special. The parent process will not create child processes to execute these commands, but will be executed directly in the current bash process. But if you place the built-in command after the pipe, the built-in command will belong to the same process group as the process on the left side of the pipe, so the child process will still be created.
Having said this, we should explain subshell, this special subprocess.
Generally, the content of the child process that comes out of the fork is the same as the parent process, including variables. For example, the variables of the parent process can also be obtained when executing the cp command. But where is the cp command executed? in a subshell. After executing the cp command and pressing Enter, the current bash process forks out a sub-bash, and then the sub-bash loads the cp program through exec to replace the sub-bash. Please don't get entangled with sub-bash and sub-shell here. If you can't figure out their relationship, just treat them as the same thing.
Can we understand that the running environment of all commands is in a subshell? Obviously, the bash built-in commands mentioned above are not run in a subshell. All other methods are done in subshells, but the methods are different. For the complete subshell, see man bash, where subshells are mentioned in many places. Here are some common ways.
(1). Directly execute the bash command. This is a very coincidental order. The bash command itself is a built-in bash command. Executing the built-in command in the current shell environment will not create a subshell, which means that no independent bash process will appear, and the actual result is that the new bash is a child process. One of the reasons is that executing the bash command will load various environment configuration items. In order to protect the parent bash environment from being overwritten, it should exist as a subshell. Although the content of the bash sub-process from the fork completely inherits the parent shell, due to the reloading of the environment configuration items, the sub-shell does not inherit ordinary variables. To be more precise, it overwrites the variables inherited from the parent shell . You might as well try defining a variable in the /etc/bashrc file, and then export an environment variable with the same name but different value in the parent shell, and then go to the subshell to see what the value of the variable is?
(2). Execute the shell script. Because the first line in the script is always "#!/bin/bash" or directly "bash xyz.sh", this is actually the same thing as executing bash to enter the subshell above. They both use the bash command to enter the subshell. It's just that the execution script has one more action: automatically exit the subshell after the command is executed. Therefore, when the script is executed, the environment variables of the parent shell will not be inherited in the script.
(3). Command substitution for non-built-in commands. When the command contains a command substitution part, this part will be executed first. If this part is not a built-in command, it will be completed in a subshell, and then the execution result will be returned to the current command. Because this subshell is not a subshell entered through the bash command, it will inherit all the variable contents of the parent shell. This also explains that the result of "$$" in "$(echo $$)" is the pid number of the current bash, not the pid number of the subshell, because it is not a subshell entered using the bash command.
There are also two special script calling methods: exec and source.
exec: exec is a loader that replaces the current process, so it does not open a subshell, but directly executes the command or script in the current shell. After executing exec, it directly exits where exec is located. shell. This explains why when executing the cp command under bash, the subshell where cp is located will automatically exit after cp is executed.
source: source is generally used to load environment configuration scripts, and commands cannot be loaded directly. It also does not open a subshell, directly executes the calling script in the current shell and does not exit the current shell after executing the script, so the script will inherit the current existing variables, and the environment variables loaded after the script is executed will be sticky to the current shell. , takes effect in the current shell.
9.2 job task
Most processes can put it into the background. At this time, it is a background task, so it is often called job, each opened shell will maintain a job table, and each job in the background corresponds to a Job item in the job table.
The way to manually run a command or script in the background is to add the "&" symbol after the command line. For example:
[root@server2 ~]# cp /etc/fstab /tmp/ &[1] 8701
After putting a process into the background, it will immediately return to its parent process. Generally, processes that are manually put into the background are done under bash. , so return to the bash environment immediately. While returning the parent process, its jobid and pid will also be returned to the parent process. If you want to quote jobid in the future, you should add a percent sign "%" before jobid, where "%%" represents the current job. For example, "kill -9 %1" means killing the background process with jobid 1. If you do not add a hundred Semicolon, it's over, kill the Init process.
You can view background job information through the jobs command.
jobs [--l:jobs默认不会列出后台工作的PID,加上---s:显示后台工作处于stopped状态的jobs
Tasks placed in the background through "&" will still be running in the background. Of course, for interactive commands such as vim, it will enter a paused running state.
[root@server2 ~]# sleep 10 &[1] 8710[root@server2 ~]# jobs [1]+ Running sleep 10 &
Be sure to note that what you see here is the R status displayed by running and ps or top. They are not always Indicates that it is running, and the process in the waiting queue also belongs to running. They all belong to the task_running identifier.
Another way to manually join the background is to press the CTRL+Z key. This can add the running process to the background, but the process added to the background will be suspended in the background.
[root@server2 ~]# sleep 10^Z [1]+ Stopped sleep 10[root@server2 ~]# jobs [1]+ Stopped sleep 10
From the jobs information, we can also see that there is a "+" sign after each jobid, and there is also a "-", or no sign.
[root@server2 ~]# sleep 30&vim /etc/my.cnf&sleep 50&[1] 8915[2] 8916[3] 8917
[root@server2 ~]# jobs [1] Running sleep 30 &[2]+ Stopped vim /etc/my.cnf [3]- Running sleep 50 &
It is found that the process of vim is followed by a plus sign. "+" indicates the task being executed, which means that the CPU is working on it. body, "-" indicates the next task to be executed selected by the scheduling class, and it will not be marked starting from the third task. It can be analyzed from the status of jobs. The running but not "+" in the background task table indicates that it is in the waiting queue, the running and "+" indicates that it is being executed, and the stopped status indicates that it is in the sleeping state. However, we cannot think that the tasks in the job list will always be in this state, because the time slice assigned to each task is actually very short. After executing the task of this time slice length in a very short time, it will immediately switch to the next task. and execute. However, in the actual process, because the switching speed and the time slice of each task are extremely short, when the task list is small, the displayed order may not change much.
As far as the above example is concerned, the next task to be executed is vim, but it is stopped. Is it because the first process is stopped that other processes will not be executed? That's obviously not the case. In fact, before long, you will find that the other two sleep tasks have been completed, but vim is still in the stop state.
[root@server2 ~]# jobs [1] Done sleep 30[2]+ Stopped vim /etc/my.cnf [3]- Done sleep 50
Through this job example, do you have a deeper understanding of the way the kernel schedules processes?
Back to the topic. Since you can manually put the process into the background, you can definitely bring it back to the foreground. If you move to the foreground to check the execution progress, and want to bring it into the background, there must be a way. You can't use CTRL+Z to add it in a pause mode. Backstage.
The fg and bg commands are the abbreviations of foreground and background respectively, that is, putting them into the foreground and putting them into the background. Strictly speaking, they are put into the foreground and background in a running state, even if the original task is in a stopped state.
The operation method is also very simple. Just add jobid directly after the command (i.e. [fg|bg] [%jobid]). If jobid is not given, the current task will be operated, that is, with " +" task items.
[root@server2 ~]# sleep 20^Z # 按下CTRL+Z进入暂停并放入后台 [3]+ Stopped sleep 20
[root@server2 ~]# jobs [2]- Stopped vim /etc/my.cnf [3]+ Stopped sleep 20 # 此时为stopped状态
[root@server2 ~]# bg %3 # 使用bg或fg可以让暂停状态的进程变会运行态 [3]+ sleep 20 &
[root@server2 ~]# jobs [2]+ Stopped vim /etc/my.cnf [3]- Running sleep 20 & # 已经变成运行态
Use the disown command to directly remove a job from the job table. It is just removing the job table, not ending the task. And after removing the job table, the task will be hung under the init/systemd process, making it independent of the terminal .
disown [-ar] [-h] [%jobid ...] 选项说明:-h:给定该选项,将不从job table中移除job,而是将其设置为不接受shell发送的sighup信号。具体说明见"信号"小节。-a:如果没有给定jobid,该选项表示针对Job table中的所有job进行操作。-r:如果没有给定jobid,该选项严格限定为只对running状态的job进行操作
如果不给定任何选项,该shell中所有的job都会被移除,移除是disown的默认操作,如果也没给定jobid,而且也没给定-a或-r,则表示只针对当前任务即带有"+"号的任务项。
9.3 终端和进程的关系
使用pstree命令查看下当前的进程,不难发现在某个终端执行的进程其父进程或上几个级别的父进程总是会是终端的连接程序。
例如下面筛选出了两个终端下的父子进程关系,第一个行是tty终端(即直接在虚拟机中)中执行的进程情况,第二行和第三行是ssh连接到Linux上执行的进程。
[root@server2 ~]# pstree -c | grep bash|-login---bash---bash---vim|-sshd-+-sshd---bash| `-sshd---bash-+-grep
正常情况下杀死父进程会导致子进程变为孤儿进程,即其PPID改变,但是杀掉终端这种特殊的进程,会导致该终端上的所有进程都被杀掉。这在很多执行长时间任务的时候是很不方便的。比如要下班了,但是你连接的终端上还在执行数据库备份脚本,这可能会花掉很长时间,如果直接退出终端,备份就终止了。所以应该保证一种安全的退出方法。
一般的方法也是最简单的方法是使用nohup命令带上要执行的命令或脚本放入后台,这样任务就脱离了终端的关联。当终端退出时,该任务将自动挂到init(或systemd)进程下执行。如:
shell> nohup tar rf a.tar.gz /tmp/*.txt
另一种方法是使用screen这个工具,该工具可以模拟多个物理终端,虽然模拟后screen进程仍然挂在其所在的终端上的,但同nohup一样,当其所在终端退出后将自动挂到init/systemd进程下继续存在,只要screen进程仍存在,其所模拟的物理终端就会一直存在,这样就保证了模拟终端中的进程继续执行。它的实现方式其实和nohup差不多,只不过它花样更多,管理方式也更多。一般对于简单的后台持续运行进程,使用nohup足以。
另外,可能你已经发现了,很多进程是和终端无关的,也就是不依赖于终端,这类进程一般是内核类进程/线程以及daemon类进程,若它们也依赖于终端,则终端一被终止,这类进程也立即被终止,这是绝对不允许的。
9.4 信号
信号在操作系统中控制着进程的绝大多数动作,信号可以让进程知道某个事件发生了,也指示着进程下一步要做出什么动作。信号的来源可以是硬件信号(如按下键盘或其他硬件故障),也可以是软件信号(如kill信号,还有内核发送的信号)。不过,很多可以感受到的信号都是从进程所在的控制终端发送出去的。
9.4.1 需知道的信号
Linux中支持非常多种信号,它们都以SIG字符串开头,SIG字符串后的才是真正的信号名称,信号还有对应的数值,其实数值才是操作系统真正认识的信号。但由于不少信号在不同架构的计算机上数值不同(例如CTRL+Z发送的SIGSTP信号就有三种值18,20,24),所以在不确定信号数值是否唯一的时候,最好指定其字符名称。
以下是需要了解的信号。
中断进程,可被捕捉和忽略,几乎等同于sigterm,所以也会尽可能的释放执行clean-up,释放资源,保存状态等(CTRL+ 强制杀死进程,该信号不可被捕捉和忽略,进程收到该信号后不会执行任何clean- 杀死(终止)进程,可被捕捉和忽略,几乎等同于sigint信号,会尽可能的释放执行clean-- 该信号是可被忽略的进程停止信号(CTRL+ 发送此信号使得stopped进程进入running,该信号主要用于jobs,例如bg & 用户自定义信号2
只有SIGKILL和SIGSTOP这两个信号是不可被捕捉且不可被忽略的信号,其他所有信号都可以通过trap或其他编程手段捕捉到或忽略掉。
更多更详细的信号理解或说明,可以参考wiki的两篇文章:
jobs控制机制:(Unix)
信号说明:
9.4.2 SIGHUP
(1).当控制终端退出时,会向该终端中的进程发送sighup信号,因此该终端上行的shell进程、其他普通进程以及任务都会收到sighup而导致进程终止。
两种方式可以改变因终端中断发送sighup而导致子进程也被结束的行为:一是使用nohup命令启动进程,它会忽略所有的sighup信号,使得该进程不会随着终端退出而结束;二是使用disown,将任务列表中的任务移除出job table或者直接使用disown -h的功能设置其不接收终端发送的sighup信号。但不管是何种实现方式,终端退出后未被终止的进程将只能挂靠在init/systemd下。
(2).对于daemon类的程序(即服务性进程),这类程序不依赖于终端(它们的父进程都是Init或systemd),它们收到sighup信号时会重读配置文件并重新打开日志文件,使得服务程序可以不用重启就可以加载配置文件。
9.4.3 僵尸进程和SIGCHLD
一个编程完善的程序,在子进程终止、退出的时候,会发送SIGCHLD信号给父进程,父进程收到信号就会通知内核清理该子进程相关信息。
在子进程死亡的那一刹那,子进程的状态就是僵尸进程,但因为发出了SIGCHLD信号给父进程,父进程只要收到该信号,子进程就会被清理也就不再是僵尸进程。所以正常情况下,所有终止的进程都会有一小段时间处于僵尸态(发送SIGCHLD信号到父进程收到该信号之间),只不过这种僵尸进程存在时间极短(倒霉的僵尸),几乎是不可被ps或top这类的程序捕捉到的。
如果在特殊情况下,子进程终止了,但父进程没收到SIGCHLD信号,没收到这信号的原因可能是多种的,不管如何,此时子进程已经成了永存的僵尸,能轻易的被ps或top捕捉到。僵尸不倒霉,人类就要倒霉,但是僵尸爸爸并不知道它儿子已经变成了僵尸,因为有僵尸爸爸的掩护,僵尸道长即内核见不到小僵尸,所以也没法收尸。悲催的是,人类能力不足,直接发送信号(如kill)给僵尸进程是无效的,因为僵尸进程本就是终结了的进程,不占用任何运行资源,也收不到信号,只有内核从进程列表中将僵尸进程表项移除才能收尸。
要解决掉永存的僵尸有几种方法:
(1).杀死僵尸进程的父进程。没有了僵尸爸爸的掩护,小僵尸就暴露给了僵尸道长的直系弟子init/systemd,init/systemd会定期清理它下面的各种僵尸进程。所以这种方法有点不讲道理,僵尸爸爸是正常的啊,不过如果僵尸爸爸下面有很多僵尸儿子,这僵尸爸爸肯定是有问题的,比如编程不完善,杀掉是应该的。
(2).手动发送SIGCHLD信号给僵尸进程的父进程。僵尸道长找不到僵尸,但被僵尸祸害的人类能发现僵尸,所以人类主动通知僵尸爸爸,让僵尸爸爸知道自己的儿子死而不僵,然后通知内核来收尸。
当然,第二种手动发送SIGCHLD信号的方法要求父进程能收到信号,而SIGCHLD信号默认是被忽略的,所以应该显式地在程序中加上获取信号的代码。也就是人类主动通知僵尸爸爸的时候,默认僵尸爸爸是不搭理人类的,所以要强制让僵尸爸爸收到通知。不过一般daemon类的程序在编程上都是很完善的,发送SIGCHLD总是会收到,不用担心。
9.4.4 手动发送信号(kill命令)
使用kill命令可以手动发送信号给指定的进程。
kill [-s signal] pid...kill [-signal] pid...kill -l
使用kill -l可以列出Linux中支持的信号,有64种之多,但绝大多数非编程人员都用不上。
使用-s或-signal都可以发送信号,不给定发送的信号时,默认为TREM信号,即kill -15。
shell> kill -9 pid1 pid2... shell> kill -TREM pid1 pid2... shell> kill -s TREM pid1 pid2...
9.4.5 pkill和killall
这两个命令都可以直接指定进程名来发送信号,不指定信号时,默认信号都是TERM。
(1).pkill
pkill和pgrep命令是同族命令,都是先通过给定的匹配模式搜索到指定的进程,然后发送信号(pkill)或列出匹配的进程(pgrep),pgrep就不介绍了。
pkill能够指定模式匹配,所以可以使用进程名来删除,想要删除指定pid的进程,反而还要使用"-s"选项来指定。默认发送的信号是SIGTERM即数值为15的信号。
pkill [-signal] [-v] [-P ppid,...] [-s pid,...][-U uid,...] [-t term,...] [pattern] 选项说明:-P ppid,... :匹配PPID为指定值的进程-s pid,... :匹配PID为指定值的进程-U uid,... :匹配UID为指定值的进程,可以使用数值UID,也可以使用用户名称-t term,... :匹配给定终端,终端名称不能带上"/dev/"前缀,其实"w"命令获得终端名就满足此处条件了,所以pkill可以直接杀掉整个终端-v :反向匹配-signal :指定发送的信号,可以是数值也可以是字符代表的信号
在CentOS 7上,还有两个好用的新功能选项。
-F, --pidfile file:匹配进程时,读取进程的pid文件从中获取进程的pid值。这样就不用去写获取进程pid命令的匹配模式-L, --logpidfile :如果"-F"选项读取的pid文件未加锁,则pkill或pgrep将匹配失败。
例如踢出终端:
shell> pkill -t pts/0
(2).killall
killall主要用于杀死一批进程,例如杀死整个进程组。其强大之处还体现在可以通过指定文件来搜索哪个进程打开了该文件,然后对该进程发送信号,在这一点上,fuser和lsof命令也一样能实现。
killall [-r,--regexp] [-s,--signal signal] [-u,--user user] [-v,--verbose] [-w,--wait] [-I,--ignore-case] [--] name ... 选项说明:-I :匹配时不区分大小写-r :使用扩展正则表达式进行模式匹配-s, --signal :发送信号的方式可以是-HUP或-SIGHUP,或数值的"-1",或使用"-s"选项指定信号-u, --user :匹配该用户的进程-v, :给出详细信息-w, --wait :等待直到该杀的进程完全死透了才返回。默认killall每秒检查一次该杀的进程是否还存在,只有不存在了才会给出退出状态码。 如果一个进程忽略了发送的信号、信号未产生效果、或者是僵尸进程将永久等待下去
9.5 fuser和lsof
fuser可以查看文件或目录所属进程的pid,即由此知道该文件或目录被哪个进程使用。例如,umount的时候提示the device busy可以判断出来哪个进程在使用。而lsof则反过来,它是通过进程来查看进程打开了哪些文件,但要注意的是,一切皆文件,包括普通文件、目录、链接文件、块设备、字符设备、套接字文件、管道文件,所以lsof出来的结果可能会非常多。
9.5.1 fuser
fuser [-ki] [-signal] file/dir-k:找出文件或目录的pid,并试图kill掉该pid。发送的信号是SIGKILL-i:一般和-k一起使用,指的是在kill掉pid之前询问。-signal:发送信号,如-1 -15,如果不写,默认-9,即kill -9不加选项:直接显示出文件或目录的pid
在不加选项时,显示结果中文件或目录的pid后会带上一个修饰符:
c:在当前目录下
e:可被执行的
f:是一个被开启的文件或目录
F:被打开且正在写入的文件或目录
r:代表root directory
例如:
[root@xuexi ~]# fuser /usr/sbin/crond/usr/sbin/crond: 1425e
表示/usr/sbin/crond被1425这个进程打开了,后面的修饰符e表示该文件是一个可执行文件。
[root@xuexi ~]# ps aux | grep 142[5] root 1425 0.0 0.1 117332 1276 ? Ss Jun10 0:00 crond
9.5.2 lsof
例如:
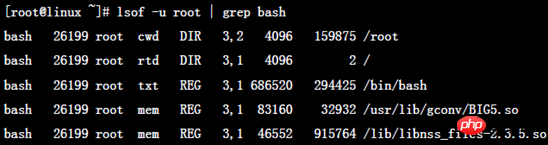
输出信息中各列意义:
COMMAND:进程的名称
PID:进程标识符
USER:进程所有者
FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等
TYPE:文件类型,如DIR、REG等
DEVICE:指定磁盘的名称
SIZE/OFF:文件的大小或文件的偏移量(单位kb)(size and offset)
NODE:索引节点(文件在磁盘上的标识)
NAME:打开文件的确切名称
lsof的各种用法:
lsof /path/to/somefile:显示打开指定文件的所有进程之列表;建议配合grep使用 lsof -c string:显示其COMMAND列中包含指定字符(string)的进程所有打开的文件;可多次使用该选项lsof -p PID:查看该进程打开了哪些文件lsof -U:列出套接字类型的文件。一般和其他条件一起使用。如lsof -u root -a -Ulsof -u uid/name:显示指定用户的进程打开的文件;可使用脱字符"^"取反,如"lsof -u ^root"将显示非root用户打开的所有文件lsof +d /DIR/:显示指定目录下被进程打开的文件 lsof +D /DIR/:基本功能同上,但lsof会对指定目录进行递归查找,注意这个参数要比grep版本慢 lsof -a:按"与"组合多个条件,如lsof -a -c apache -u apache lsof -N:列出所有NFS(网络文件系统)文件 lsof -n:不反解IP至HOSTNAME lsof -i:用以显示符合条件的进程情况lsof -i[46] [protocol][@host][:service|port]46:IPv4或IPv6 protocol:TCP or UDP host:host name或ip地址,表示搜索哪台主机上的进程信息 service:服务名称(可以不只一个) port:端口号 (可以不只一个)
大概"-i"是使用最多的了,而"-i"中使用最多的又是服务名或端口了。
[root@www ~]# lsof -i :22COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME sshd 1390 root 3u IPv4 13050 0t0 TCP *:ssh (LISTEN) sshd 1390 root 4u IPv6 13056 0t0 TCP *:ssh (LISTEN) sshd 36454 root 3r IPv4 94352 0t0 TCP xuexi:ssh->172.16.0.1:50018 (ESTABLISHED)
回到系列文章大纲:
转载请注明出处:
The above is the detailed content of linux processes and signals. For more information, please follow other related articles on the PHP Chinese website!