


下面小编就为大家带来一篇dom4j操作xml的demo(分享)。小编觉得挺不错的,现在就分享给大家,也给大家做个参考。一起跟随小编过来看看吧
废话不多说,直接上代码
package com.cn.shop.util;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStreamWriter;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.DocumentException;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
/**
*
* @author NH
*
*/
public class XmlUtils {
public static Document getDocument() {
// 1.读取xml文件获取document对象
SAXReader reader = new SAXReader();
Document document = null;
try {
document = reader.read("D:\\itext\\27663.xml");
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 2.通过解析xml的文本
/*
* String xmlFilePath = "D:\\itext\\27663.xml"; try { document =
* DocumentHelper.parseText(xmlFilePath); } catch (DocumentException e)
* { // TODO Auto-generated catch block e.printStackTrace(); } // 3.通过
* Document document = DocumentHelper.createDocument(); Element root =
* document.addElement("csdn");
*/
return document;
}
public static void anaXml() throws Exception {
// 读取xml的文本内容来创建document对象
SAXReader reader = new SAXReader();
try {
Document document = reader.read("D:\\itext\\27663.xml");
Element root = document.getRootElement();
System.out.println(root.getName());
getElement(root);
/* elementMethod(root); */
/*
* // 获取一个节点 Element element = root.element("title");
*
*
* //获取element的id属性节点对象 Attribute attr = element.attribute("id");
* //删除属性 element.remove(attr);
*
* // 添加新属性 element.addAttribute("author", "作者");
*
* // 添加新的节点 Element newElement = root.addElement("where"); //
* 设定新节点的值 newElement.setText("北京人民出版社,天津人民大学出版社");
*
* // 获取element中的where元素节点对象 Element author =
* element.element("where"); // 删除元素节点 boolean flag =
* element.remove(author); // 返回true代码删除成功,否则失败
* System.out.println(flag); // 添加CDATA区域
* element.addCDATA("红楼梦,是一部爱情小说."); // 写入到一个新的文件中 writer(document);
*/
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/*
*
* 所有节点内容
*/
public static void getElement(Element root) {
// 获取当前节点的所有属性节点
List<Attribute> as = root.attributes();
for (Attribute a : as) {
System.out.println("当前属性节点的名称:" + a.getName());
/*
* System.out.println("当前属性节点的内容:" + a.getText());
*
* System.out.println("当前属性节点的值:" + a.getValue());
*/
}
if (!root.getTextTrim().equals("")) {
System.out.println("文本内容::::" + root.getText());
}
Iterator<Element> el = root.elementIterator();
while (el.hasNext()) {
// 获取某个子节点对象
Element e = el.next();
// 对子节点进行遍历
getElement(e);
}
}
/**
* 介绍Element中的element方法和elements方法的使用
*
* @param node
*/
public static void elementMethod(Element node) {
// 获取node节点中,子节点的元素名称为西游记的元素节点。
Element e = node.element("info");
// 获取西游记元素节点中,子节点为chapter的元素节点(可以看到只能获取第一个作者元素节点)
Element author = e.element("classification");
System.out.println(e.getName() + "----" + author.getText());
// 获取西游记这个元素节点 中,所有子节点名称为classification元素的节点 。
List<Element> authors = e.elements("classification");
for (Element aut : authors) {
System.out.println(aut.getText());
}
// 获取西游记这个元素节点 所有元素的子节点。
List<Element> elements = e.elements();
for (Element el : elements) {
System.out.println(el.getText());
}
}
/**
* 把document对象写入新的文件
*
* @param document
* @throws Exception
*/
public static void writer(Document document) throws Exception {
// 紧凑的格式
// OutputFormat format = OutputFormat.createCompactFormat();
// 排版缩进的格式
OutputFormat format = OutputFormat.createPrettyPrint();
// 设置编码
format.setEncoding("UTF-8");
// 创建XMLWriter对象,指定了写出文件及编码格式
/*
* XMLWriter writer = new XMLWriter(new OutputStreamWriter(new
* FileOutputStream(new File("src//a.xml")), "UTF-8"), format);
*/
File file = new File("c://index//大主宰.xml");
FileOutputStream fos = new FileOutputStream(file);
OutputStreamWriter osw = new OutputStreamWriter(fos, "UTF-8");
XMLWriter writer = new XMLWriter(osw);
// 写入
writer.write(document);
// 立即写入
writer.flush();
// 关闭操作
writer.close();
}
// 以下的代码为字符串与xml互转实例
public void test() throws Exception {
// 创建saxreader对象
SAXReader reader = new SAXReader();
// 读取一个文件,把这个文件转换成Document对象
Document document = reader.read(new File("src//c.xml"));
// 获取根元素
Element root = document.getRootElement();
// 把文档转换字符串
String docXmlText = document.asXML();
System.out.println(docXmlText);
System.out.println("---------------------------");
// csdn元素标签根转换的内容
String rootXmlText = root.asXML();
System.out.println(rootXmlText);
System.out.println("---------------------------");
// 获取java元素标签 内的内容
Element e = root.element("java");
System.out.println(e.asXML());
}
/**
* 创建一个document对象 往document对象中添加节点元素 转存为xml文件
*
* @throws Exception
*/
public void test2() throws Exception {
Document document = DocumentHelper.createDocument();// 创建根节点
Element root = document.addElement("csdn");
Element java = root.addElement("java");
java.setText("java班");
Element ios = root.addElement("ios");
ios.setText("ios班");
writer(document);
}
/**
* 把一个文本字符串转换Document对象
*
* @throws Exception
*/
public void test1() throws Exception {
String text = "<csdn><java>Java班</java><net>Net班</net></csdn>";
Document document = DocumentHelper.parseText(text);
Element e = document.getRootElement();
System.out.println(e.getName());
writer(document);
}
/**
* 把document对象写入新的文件
*
* @param document
* @throws Exception
*/
public void writer1(Document document) throws Exception {
// 紧凑的格式
// OutputFormat format = OutputFormat.createCompactFormat();
// 排版缩进的格式
OutputFormat format = OutputFormat.createPrettyPrint();
// 设置编码
format.setEncoding("UTF-8");
// 创建XMLWriter对象,指定了写出文件及编码格式
// XMLWriter writer = new XMLWriter(new FileWriter(new
// File("src//a.xml")),format);
XMLWriter writer = new XMLWriter(new OutputStreamWriter(new FileOutputStream(new File("src//c.xml")), "UTF-8"),
format);
// 写入
writer.write(document);
// 立即写入
writer.flush();
// 关闭操作
writer.close();
}
public static void main(String[] args) {
try {
anaXml();
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}【相关推荐】
3. java操作(DOM、SAX、JDOM、DOM4J)xml方式的四种比较与详解
The above is the detailed content of Detailed explanation of dom4j operation xml file example code. For more information, please follow other related articles on the PHP Chinese website!

 如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM
如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM如何用PHP和XML实现网站的分页和导航导言:在开发一个网站时,分页和导航功能是很常见的需求。本文将介绍如何使用PHP和XML来实现网站的分页和导航功能。我们会先讨论分页的实现,然后再介绍导航的实现。一、分页的实现准备工作在开始实现分页之前,需要准备一个XML文件,用来存储网站的内容。XML文件的结构如下:<articles><art
 XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM
XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM一、XML外部实体注入XML外部实体注入漏洞也就是我们常说的XXE漏洞。XML作为一种使用较为广泛的数据传输格式,很多应用程序都包含有处理xml数据的代码,默认情况下,许多过时的或配置不当的XML处理器都会对外部实体进行引用。如果攻击者可以上传XML文档或者在XML文档中添加恶意内容,通过易受攻击的代码、依赖项或集成,就能够攻击包含缺陷的XML处理器。XXE漏洞的出现和开发语言无关,只要是应用程序中对xml数据做了解析,而这些数据又受用户控制,那么应用程序都可能受到XXE攻击。本篇文章以java
 php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM
php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM当我们处理数据时经常会遇到将XML格式转换为JSON格式的需求。PHP有许多内置函数可以帮助我们执行这个操作。在本文中,我们将讨论将XML格式转换为JSON格式的不同方法。
 Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PM
Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PMPythonxmltodict对xml的操作xmltodict是另一个简易的库,它致力于将XML变得像JSON.下面是一个简单的示例XML文件:elementsmoreelementselementaswell这是第三方包,在处理前先用pip来安装pipinstallxmltodict可以像下面这样访问里面的元素,属性及值:importxmltodictwithopen("test.xml")asfd:#将XML文件装载到dict里面doc=xmltodict.parse(f
 xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PM
xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PMxml中node和element的区别是:Element是元素,是一个小范围的定义,是数据的组成部分之一,必须是包含完整信息的结点才是元素;而Node是节点,是相对于TREE数据结构而言的,一个结点不一定是一个元素,一个元素一定是一个结点。
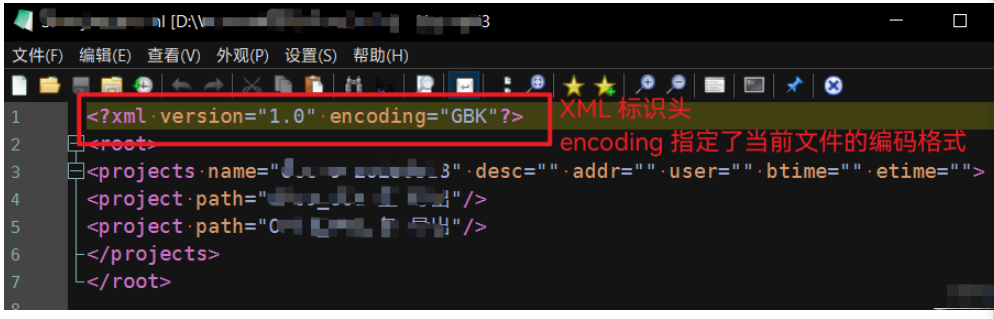 Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM
Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM1.在Python中XML文件的编码问题1.Python使用的xml.etree.ElementTree库只支持解析和生成标准的UTF-8格式的编码2.常见GBK或GB2312等中文编码的XML文件,用以在老旧系统中保证XML对中文字符的记录能力3.XML文件开头有标识头,标识头指定了程序处理XML时应该使用的编码4.要修改编码,不仅要修改文件整体的编码,还要将标识头中encoding部分的值修改2.处理PythonXML文件的思路1.读取&解码:使用二进制模式读取XML文件,将文件变为
 使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM
使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM使用nmap-converter将nmap扫描结果XML转化为XLS实战1、前言作为网络安全从业人员,有时候需要使用端口扫描利器nmap进行大批量端口扫描,但Nmap的输出结果为.nmap、.xml和.gnmap三种格式,还有夹杂很多不需要的信息,处理起来十分不方便,而将输出结果转换为Excel表格,方面处理后期输出。因此,有技术大牛分享了将nmap报告转换为XLS的Python脚本。2、nmap-converter1)项目地址:https://github.com/mrschyte/nmap-
 深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PM
深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PMScrapy是一款强大的Python爬虫框架,可以帮助我们快速、灵活地获取互联网上的数据。在实际爬取过程中,我们会经常遇到HTML、XML、JSON等各种数据格式。在这篇文章中,我们将介绍如何使用Scrapy分别爬取这三种数据格式的方法。一、爬取HTML数据创建Scrapy项目首先,我们需要创建一个Scrapy项目。打开命令行,输入以下命令:scrapys


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

SublimeText3 English version
Recommended: Win version, supports code prompts!

SublimeText3 Mac version
God-level code editing software (SublimeText3)

