
Home >Backend Development >PHP Tutorial >Methods for simulating HTTP requests to realize automatic web page operation and data collection (Collection)
Methods for simulating HTTP requests to realize automatic web page operation and data collection (Collection)

- PHPzOriginal
- 2018-05-24 11:03:244499browse
The following editor will bring you an article on how to simulate HTTP requests to realize automatic operation and data collection of web pages. The editor thinks it is quite good, so I will share it with you now and give it as a reference for everyone. Let’s follow the editor to take a look.
Preface
Web pages can be divided into information provision and business operation categories. Information provision such as news, stocks Quotes and other websites. Business operations such as online business hall, OA and so on. Of course, there are many websites that have both properties at the same time. Websites such as Weibo, Douban, and Taobao not only provide information but also implement certain businesses.
Ordinary Internet access methods are generally manual operations (this does not require explanation: D). But sometimes manual operations may not be enough, such as crawling a large amount of data on the Internet, monitoring changes in a page in real time, batch operations (such as batch posting on Weibo, batch Taobao shopping), brushing orders, etc. Due to the large amount of operations and the repetitive operations, manual operations are inefficient and error-prone. At this time, you can use software to automatically operate.
I have developed a number of such software, including web crawlers and automatic batch operation businesses. One of the core functions used is to simulate HTTP requests. Of course, the HTTPS protocol is sometimes used, and the website generally needs to be logged in before further operations can be performed. The most important point is to understand the business process of the website, that is, to know when and how to submit to which page in order to achieve a certain operation. What data? Finally, to extract the data or know the results of the operation, you also need to parse the HTML. This article will explain them one by one.
This article uses C# language to display the code. Of course, it can also be implemented in other languages. The principle is the same. Take logging into JD.com as an example.
Simulating HTTP requests
C# To simulate HTTP requests, you need to use the following classes:
•WebRequest
##•HttpWebRequest
•HttpWebResponse
•Stream
First create a request object (HttpWebRequest), set the relevant Headers information and then send the request (if it is POST, also write the form data to the network stream), if the target address is accessible, a response object (HttpWebResponse) will be obtained, and the return result can be read from the network stream of the corresponding object.The sample code is as follows:
String contentType = "application/x-www-form-urlencoded";
String accept = "image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/x-shockwave-flash, application/x-silverlight, application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, application/x-ms-application, application/x-ms-xbap, application/vnd.ms-xpsdocument, application/xaml+xml, application/x-silverlight-2-b1, */*";
String userAgent = "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.116 Safari/537.36";
public String Get(String url, String encode = DEFAULT_ENCODE)
{
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
InitHttpWebRequestHeaders(request);
request.Method = "GET";
var html = ReadHtml(request, encode);
return html;
}
public String Post(String url, String param, String encode = DEFAULT_ENCODE)
{
Encoding encoding = System.Text.Encoding.UTF8;
byte[] data = encoding.GetBytes(param);
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
InitHttpWebRequestHeaders(request);
request.Method = "POST";
request.ContentLength = data.Length;
var outstream = request.GetRequestStream();
outstream.Write(data, 0, data.Length);
var html = ReadHtml(request, encode);
return html;
}
private void InitHttpWebRequestHeaders(HttpWebRequest request)
{
request.ContentType = contentType;
request.Accept = accept;
request.UserAgent = userAgent;
}
private String ReadHtml(HttpWebRequest request, String encode)
{
HttpWebResponse response = request.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.GetEncoding(encode));
String content = reader.ReadToEnd();
reader.Close();
stream.Close();
return content;
}It can be seen that most of the codes of the Get and Post methods are similar, so the codes are encapsulated. Extracted the same code as a new function.
HTTPS request
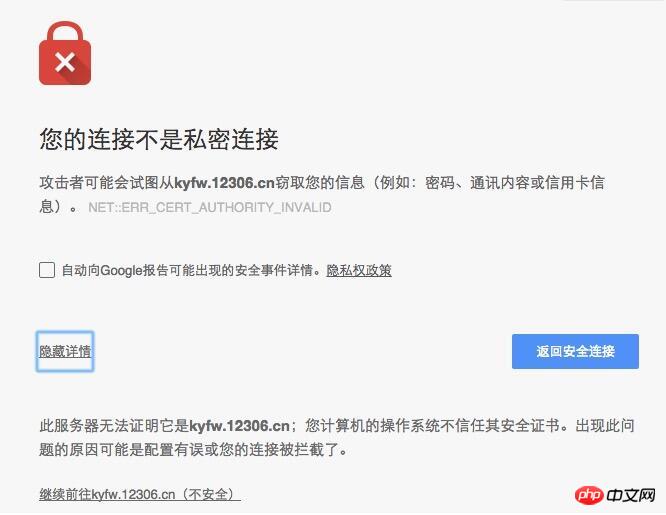
When the website uses https protocol, the following error may occur in the above code:The underlying connection was closed: Could not establish trust relationship forReason It is a certificate error. When you open it with a browser, the following page will appear:
private HttpWebRequest CreateHttpWebRequest(String url)
{
HttpWebRequest request;
if (IsHttpsProtocol(url))
{
ServicePointManager.ServerCertificateValidationCallback = new RemoteCertificateValidationCallback(CheckValidationResult);
request = WebRequest.Create(url) as HttpWebRequest;
request.ProtocolVersion = HttpVersion.Version10;
}
else
{
request = WebRequest.Create(url) as HttpWebRequest;
}
return request;
}
private HttpWebRequest CreateHttpWebRequest(String url)
{
HttpWebRequest request;
if (IsHttpsProtocol(url))
{
ServicePointManager.ServerCertificateValidationCallback = new RemoteCertificateValidationCallback(CheckValidationResult);
request = WebRequest.Create(url) as HttpWebRequest;
request.ProtocolVersion = HttpVersion.Version10;
}
else
{
request = WebRequest.Create(url) as HttpWebRequest;
}
return request;
}In this way, you can access the https website normally. Record Cookies to achieve identity authenticationSome websites require logging in to perform the next step. For example, shopping on JD.com requires logging in first. The website server uses sessions to record client users. Each session corresponds to a user, and the previous code will re-establish a session every time it creates a request. Even if the login is successful, the login will be invalid because a new connection is created during the next step. At this time, you have to find a way to make the server think that this series of requests come from the same session. The client only has Cookies. In order to let the server know which session the client corresponds to during the next request, there will be a record of the session ID in the Cookies. Therefore, as long as the cookies are the same, it is the same user to the server. You need to use CookieContainer at this time. As the name suggests, this is a Cookies container. HttpWebRequest has a CookieContainer property. As long as the cookies for each request are recorded in CookieContainer, the CookieContainer attribute of HttpWebRequest is set on the next request. Since the cookies are the same, it is the same user to the server. public String Get(String url, String encode = DEFAULT_ENCODE)
{
HttpWebRequest request = WebRequest.Create(url) as HttpWebRequest;
InitHttpWebRequestHeaders(request);
request.Method = "GET";
request.CookieContainer = cookieContainer;
HttpWebResponse response = request.GetResponse() as HttpWebResponse;
foreach (Cookie c in response.Cookies)
{
cookieContainer.Add(c);
}
}
Analysis and debugging website
The above has achieved the simulation of HTTP requests. Of course, the most important thing is the analysis station. The usual situation is that there is no documentation, no website developer can be found, and exploration starts from a black box. There are many analysis tools. It is recommended to use the Chrome+ plug-in Advanced Rest Client. Chrome's developer tools allow us to know what operations and requests are made in the background when opening a web page. Advanced Rest Client can simulate sending requests.For example, when logging in to JD.com, the following data will be submitted:
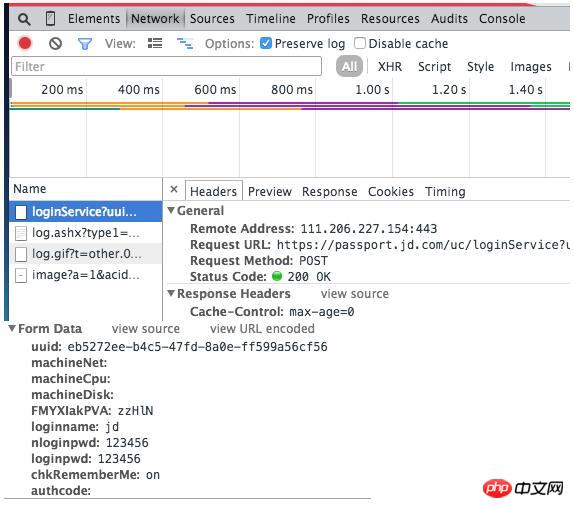
We can also see that Jingdong’s password is actually transmitted in clear text, which is very worrying about security!
You can also see the returned data:

The returned data is JSON data, but\u8d26What are these? In fact, this is Unicode encoding. You can use the Unicode encoding conversion tool to convert it into readable text. For example, the result returned this time is: the account name and password do not match, please re-enter.
Parsing HTML
The data obtained by HTTP request is generally in HTML format, and sometimes it may be Json or XML. Parsing is required to extract useful data. The components that parse HTML are:
•HTML Parser. Available on multiple platforms such as Java/C#/Python. Haven't used it for a long time.
•HtmlAgilityPack. By parsing HMTL via XPath. Used all the time. For XPath tutorials, you can see W3School's XPath tutorials.
Conclusion
This article introduces the skills required to develop simulated automatic web page operations, from simulating HTTP/HTTPS requests, to cookies, and analyzing websites , parse HTML. The code is intended to illustrate usage and is not complete code and may not be run directly.
The above is the detailed content of Methods for simulating HTTP requests to realize automatic web page operation and data collection (Collection). For more information, please follow other related articles on the PHP Chinese website!