
Home >Backend Development >C#.Net Tutorial >Detailed explanation of thread synchronization in C# multi-threading (picture and text)
Detailed explanation of thread synchronization in C# multi-threading (picture and text)

- 黄舟Original
- 2017-03-28 13:14:542279browse
This article mainly introduces the relevant knowledge of C# thread synchronization. It has a very good reference value. Let’s take a look at it with the editor.
Multi-threading content is roughly divided into two parts. One is asynchronous operation, which can be done through dedicated, thread pool, Task, Parallel, PLINQ, etc. This involves worker threads and IO threads; the second is the thread synchronization issue. What I am studying and exploring now is the thread synchronization issue.
By studying the content in "CLR via C#", a clearer architecture has been formed for thread synchronization. What realizes thread synchronization in multi-threads is the thread synchronization structure. This structure is divided into two categories, one One is a primitive structure and the other is a hybrid structure. The so-called primitives are the simplest constructs used in the code. The basic structure is divided into two categories, one is user mode and the other is kernel mode. The hybrid construct uses user mode and kernel mode that use primitive constructs internally. There are certain strategies for using its mode, because user mode and kernel mode have their own pros and cons, and the hybrid construct is to balance the advantages and disadvantages of the two. Designed to avoid disadvantages. The following lists the entire thread synchronization architecture
Primitives
1.1 User mode
1.1.1 volatile
1.1.2 Interlock
1.2 Kernel Mode
1.2.1 WaitHandle
1.2.2 ManualResetEvent and AutoResetEvent
1.2.3 Semaphore
1.2. 4 Mutex
Mixed
2.1 Various Slim
2.2 Monitor
2.3 MethodImplAttribute and SynchronizationAttribute
2.4 ReaderWriterLock
2.5 Barier (rarely used)
2.6 CoutdownEvent (rarely used)
Let’s start with the cause of thread synchronization problems. When there is an integer in the memoryVariableA, the value stored in it is 2. When thread 1 executes, it will take the value of A from the memory and store it in the CPU register, and assign the value of A to 3. At this time, the value of thread 1 happens to be The time slice ends; then the CPU allocates the time slice to thread 2. Thread 2 also takes out the value of A from the memory and puts it into the memory. However, because thread 1 does not put the new value 3 of variable A back into the memory, thread 2 2 still reads the old value (that is, dirty data) 2, and then if thread 2 needs to make some judgments on the A value, some unexpected results will occur.
Various methods are often used to deal with the above resource sharing problem. The following will introduce one by one
Let’s first talk about the user mode in the primitive structure. The advantage of the user mode is that its execution is relatively fast, because it is coordinated through a series of CPU instructions, and the blocking it causes is only For a very short period of blocking, as far as the operating system is concerned, this thread is always running and has never been blocked. The disadvantage is that only the system kernel can stop such a thread from running. On the other hand, because the thread is spinning instead of blocking, it will also occupy the CPU time, causing a waste of CPU time.
The first is the volatile structure in the primitive user mode structure. Many theories on the Internet about this structure allow the CPU to read the specified field (Field, that is, the variable) from the memory, and each write is to memory write. However, it has something to do with the compiler's code optimization. First look at the following code
public class StrageClass
{
vo int mFlag = 0;
int mValue = 0;
public void Thread1()
{
mValue = 5;
mFlag = 1;
}
public void Thread2()
{
if (mFlag == 1)
Console.WriteLine(mValue);
}
}Students who understand multi-thread synchronization issues will know that if two threads are used to execute the above two methods respectively, there are two results:
1.Do not output anything;
2.Output 5. However, when the CSC compiler compiles into IL language or JIT compiles into machine language, code optimization will be performed. In method Thread1, the compiler will think that assigning values to two fields does not matter, it will only execute in a single thread. From the point of view, it does not take into account the issue of multi-threading at all, so it may mess up the execution order of the two lines of code, causing mFlag to be assigned a value of 1 first, and then mValue to be assigned a value of 5, which leads to the third As a result, 0 is output. Unfortunately, I haven't been able to test this result.
The solution to this phenomenon is the volatile construct. The effect of using this construct is that whenever a read operation is performed on a field using this construct, the operation is guaranteed to be executed first in the original code sequence. ; Or whenever a write operation is performed on a field using this construct, the operation is guaranteed to be executed last in the original code sequence.
There are currently three structures that implement volatile. One is Thread's two static methods VolatileRead and VolatileWrite. The analysis on MSND is as follows
Thread. VolatileRead reads field values. This value is the most recent value written by any of the computer's processors, regardless of the number of processors or the state of the processor cache.
Thread.VolatileWrite Immediately writes a value to a field so that the value is visible to all processors in the computer.
在多处理器系统上, VolatileRead 获得由任何处理器写入的内存位置的最新值。 这可能需要刷新处理器缓存;VolatileWrite 确保写入内存位置的值立即可见的所有处理器。 这可能需要刷新处理器缓存。
即使在单处理器系统上, VolatileRead 和 VolatileWrite 确保值为读取或写入内存,并不缓存 (例如,在处理器寄存器中)。 因此,您可以使用它们可以由另一个线程,或通过硬件更新的字段对访问进行同步。
从上面的文字看不出他和代码优化有任何关联,那接着往下看。
volatile关键字则是volatile构造的另外一种实现方式,它是VolatileRead和VolatileWrite的简化版,使用 volatile 修饰符对字段可以保证对该字段的所有访问都使用 VolatileRead 或 VolatileWrite。MSDN中对volatile关键字的说明是
volatile 关键字指示一个字段可以由多个同时执行的线程修改。 声明为 volatile 的字段不受编译器优化(假定由单个线程访问)的限制。 这样可以确保该字段在任何时间呈现的都是最新的值。
从这里可以看出跟代码优化有关系了。而纵观上面的介绍得出两个结论:
1.使用了volatile构造的字段读写都是直接对内存操作,不涉及CPU寄存器,使得所有线程对它的读写都是同步,不存在脏读了。读操作是原子的,写操作也是原子的。
2.使用了volatile构造修饰(或访问)字段,它会严格按照代码编写的顺序执行,读操作将会在最早执行,写操作将会最迟执行。
最后一个volatile构造是在.NET Framework中新增的,里面包含的方法都是Read和Write,它实际上就相当于Thread的VolatileRead 和VolatileWrite 。这需要拿源码来说明了,随便拿一个Volatile的Read方法来看
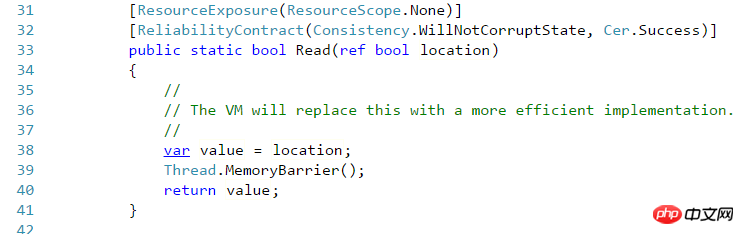
而再看看Thraed的VolatileRead方法

另一个用户模式构造是Interlocked,这个构造是保证读和写都是在原子操作里面,这是与上面volatile最大的区别,volatile只能确保单纯的读或者单纯的写。
为何Interlocked是这样,看一下Interlocaked的方法就知道了
Add(ref int,int)// 调用ExternAdd 外部方法 CompareExchange(ref Int32,Int32,Int32)//1与3是否相等,相等则替换2,返回1的原始值 Decrement(ref Int32)//递减并返回 调用add Exchange(ref Int32,Int32)//将2设置到1并返回 Increment(ref Int32)//自增 调用add
就随便拿其中一个方法Add(ref int,int)来说(Increment和Decrement这两个方法实际上内部调用了Add方法),它会先读到第一个参数的值,在与第二个参数求和后,把结果写到给第一参数中。首先这整个过程是一个原子操作,在这个操作里面既包含了读,也包含了写。至于如何保证这个操作的原子性,估计需要查看Rotor源码才行。在代码优化方面来说,它确保了所有写操作都在Interlocked之前去执行,这保证了Interlocked里面用到的值是最新的;而任何变量的读取都在Interlocked之后读取,这保证了后面用到的值都是最新更改过的。
CompareExchange方法相当重要,虽然Interlocked提供的方法甚少,但基于这个可以扩展出其他更多方法,下面就是个例子,求出两个值的最大值,直接抄了Jeffrey的源码

查看上面代码,在进入循环之前先声明每次循环开始时target的值,在求出最值之后,核对一下target的值是否有变化,如果有变化则需要再记录新值,按照新值来再求一次最值,直到target不变为止,这就满足了Interlocked中所说的,写都在Interlocked之前发生,Interlocked往后就能读到最新的值。
基元内核模式
Kernel mode relies on the operating system's kernelobject to handle thread synchronization issues. Let’s talk about its disadvantages first, its speed will be relatively slow. There are two reasons. One is because it is implemented by the operating system kernel object and requires coordination within the operating system. The other reason is that the kernel objects are all unmanaged objects. After understanding AppDo After main will know, if the accessed object is not in the current AppDomain, it will either be marshaled by value or marshaled by reference. It has been observed that this part of the unmanaged resources is marshaled by reference, which will have a performance impact. Combining the above two points, we can get the disadvantages of kernel mode. But it also has advantages: 1. The thread will not "spin" but block when waiting for resources. This saves CPU time, and a timeout value can be set for this blocking. 2. Synchronization of Window threads and CLR threads can be achieved, and threads in different processes can also be synchronized (the former has not been experienced, but for the latter, it is known that there are boundary value resources in semaphores). 3. Security settings can be applied to prohibit access for authorized accounts (I don’t know what is going on).
The base class for all objects in kernel mode is WaitHandle. The hierarchy of all classes in kernel mode is as follows
##WaitHandle
##EventWaitHandle
AutoResetEvent
ManualResetEvent
Semaphore
Mutex##WaitHandle inherits MarshalByRefObject, which marshals unmanaged objects by reference. WaitHandle mainly contains various Wait methods. If the Wait method is called, it will be blocked before receiving the signal. WaitOne is waiting for a signal, WaitAny(WaitHandle[] waitHandles) is receiving the signal of any waitHandles, and WaitAll(WaitHandle[] waitHandles) is waiting for the signal of all waitHandles. There is a version of these methods that allows setting a timeout. Other kernel-mode constructs have similar Wait methods.
EventWaitHandle maintains a Boolean value internally, and the Wait method will block the thread when the Boolean value is false, and the thread will not be released until the Boolean value is true. The methods for manipulating this Boolean value include Set() and Reset(). The former sets the Boolean value to true; the latter sets it to false. This is equivalent to a switch. After calling Reset, the thread executes Wait and is paused, and does not resume until Set. It has two subclasses, which are used in similar ways. The difference is that AutoResetEvent automatically calls Reset after calling Set, so that the switch immediately returns to the closed state; while ManualResetEvent requires manually calling Set to close the switch. This achieves an effect. Generally, AutoResetEvent allows one thread to pass each time it is released; while ManualResetEvent may allow multiple threads to pass before manually calling Reset. Semaphore maintains an integer internally. When constructing a Semaphore object, the maximum semaphore and the initial semaphore value will be specified. Whenever WaitOne is called, the semaphore will be increased by 1. When it is added to the maximum value, the thread will be blocked. When Release is called, one or more semaphores will be released. At this time, the blocked thread or threads will be released. This is in line with the problem of producers and consumers. When the producer continues to add products to productqueue
, he will WaitOne. When the queue is full, it is equivalent to the semaphore being full, and the generator will Will be blocked. When the consumer consumes a product, Release will release a space in the product queue. At this time, the producer who has no space to store the product can start working to store the product in the product queue. . This cannot be achieved simply by relying on the previous constructs, except for additional encapsulation.The above primitive structure uses the simplest implementation method. User mode is faster than user mode, but it will cause a waste of CPU time; kernel mode solves this problem, but will cause performance losses. , each has advantages and disadvantages, and the hybrid structure combines the advantages of both. It will use user mode at the appropriate time through certain strategies internally, and use kernel mode in another situation. But these layers of judgments bring memory overhead. There is no perfect structure in multi-thread synchronization. Each structure has advantages and disadvantages, and its existence is meaningful. Combined with specific application scenarios, the optimal structure will be available. It just depends on whether we can weigh the pros and cons according to specific scenarios.
Various Slim suffixed classes, in System.Threading namespace, you can see several classes ending with Slim suffix: ManualResetEventSlim, SemaphoreSlim, ReaderWriterLockSlim. Except for the last one, the other two have the same structure in the primitive kernel mode, but these three classes are simplified versions of the original structures, especially the first two. They are used in the same way as the original ones, but try to Avoid using the operating system's kernel objects and achieve a lightweight effect. For example, the kernel construct ManualResetEvent is used in SemaphoreSlim, but this construct is initialized through delay and is not used unless necessary. As for ReaderWriterLockSlim, we will introduce it later.
Monitor and lock, the lock keyword is the most well-known means of achieving multi-thread synchronization, so let’s start with a piece of code

This method is quite simple and has no practical significance. It is just to see how the compiler compiles this code. By looking at the IL as follows

Pay attention to the occurrences in the IL code The try...finally statement block, Monitor.Enter and Monotor.Exit methods are added. Then change the code and compile it again to see IL

IL code
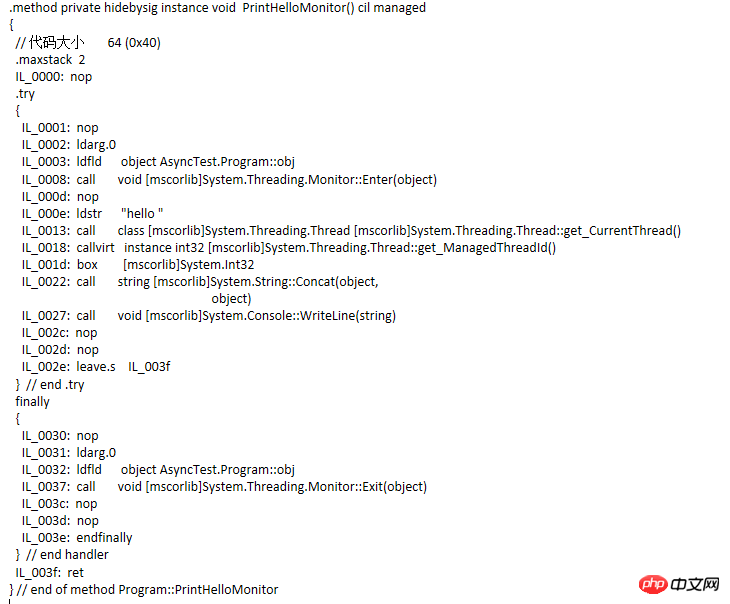
code comparison Similar, but not equivalent. In fact, the code equivalent to the lock statement block is as follows

So since lock essentially calls Monitor, how does Monitor pass a The object is locked and then thread synchronization is achieved. It turns out that every object in the managed heap has two fixed members, one pointing to the pointer of the object type, and the other pointing to a thread synchronization block index. This index points to an element of a synchronized block array . Monitor relies on this synchronized block to lock the thread. According to Jeffrey (the author of CLR via C#), there are three fields in the synchronization block, the ownership thread ID, the number of waiting threads, and the number of recursions. However, I learned through another batch of articles that the members of the thread synchronization block are not just these few. Interested students can read the two articles "Revealing the Synchronization Block Index". When the Monitor needs to lock an object obj, it will check whether the synchronization block index of obj is an index of the array. If it is -1, it will find a free synchronization block from the array to associate with it. At the same time, the ownership thread ID of the synchronization block records the ID of the current thread; when a thread calls the Monitor again, it will check whether the ownership ID of the synchronization block corresponds to the current thread ID. If it matches, let it pass. In the recursion Add 1 to the number of times. If the thread cannot be matched, throw the thread into a ready queue (this queue actually exists in the synchronization block) and block it; this synchronization block will check the number of recursions when calling Exit to ensure After the recursion is completed, the ownership thread ID is cleared. We know whether there are threads waiting by the number of waiting threads. If so, the threads are taken out from the waiting queue and released. Otherwise, the association with the synchronization block is released and the synchronization block waits to be used by the next locked object.
There is also a pair of methods Wait and Pulse in Monitor. The former can cause the thread that obtained the lock to briefly release the lock, and the current thread will be blocked and placed in the waiting queue. Until other threads call the Pulse method, the thread will be put from the waiting queue into the ready queue. When the lock is released next time, there will be a chance to acquire the lock again. Whether it can be acquired depends on the situation in the waiting queue. .
ReaderWriterLock read-write lock, the traditional lock keyword (that is, equivalent to Monitor's Enter and Exit), its lock on shared resources is a fully mutually exclusive lock. Once the locked resource is completely inaccessible to other resources, .
而ReaderWriterLock对互斥资源的加的锁分读锁与写锁,类似于数据库中提到的共享锁和排他锁。大致情况是加了读锁的资源允许多个线程对其访问,而加了写锁的资源只有一个线程可以对其访问。两种加了不同缩的线程都不能同时访问资源,而严格来说,加了读锁的线程只要在同一个队列中的都能访问资源,而不同队列的则不能访问;加了写锁的资源只能在一个队列中,而写锁队列中只有一个线程能访问资源。区分读锁的线程是否在于统一个队列中的判断标准是,本次加读锁的线程与上次加读锁的线程这个时间段中,有否别的线程加了写锁,没没别的线程加写锁,则这两个线程都在同一个读锁队列中。
ReaderWriterLockSlim和ReaderWriterLock类似,是后者的升级版,出现在.NET Framework3.5,据说是优化了递归和简化了操作。在此递归策略我尚未深究过。目前大概列举一下它们通常用的方法
ReaderWriterLock常用的方法
Acqurie或Release ReaderLock或WriteLock 的排列组合
UpGradeToWriteLock/DownGradeFromWriteLock 用于在读锁中升级到写锁。当然在这个升级的过程中也涉及到线程从读锁队列切换到写锁队列中,因此需要等待。
ReleaseLock/RestoreLock 释放所有锁和恢复锁状态
ReaderWriterLock实现IDispose接口,其方法则是以下模式
TryEnter/Enter/Exit ReadLock/WriteLock/UpGradeableReadLock
CoutdownEvent比较少用的混合构造,这个跟Semaphore相反,体现在Semaphore是在内部计数(也就是信号量)达到最大值的时候让线程阻塞,而CountdownEvent是在内部计数达到0的时候才让线程阻塞。其方法有
AddCount //计数递增; Signal //计数递减; Reset //计数重设为指定或初始; Wait //当且仅当计数为0才不阻塞,否则就阻塞。
Barrier也是一个比较少用的混合构造,用于处理多线程在分步骤的操作中协作问题。它内部维护着一个计数,该计数代表这次协作的参与者数量,当不同的线程调用SignalAndWait的时候会给这个计数加1并且把调用的线程阻塞,直到计数达到最大值的时候,才会释放所有被阻塞的线程。假设还是不明白的话就看一下MSND上面的示例代码
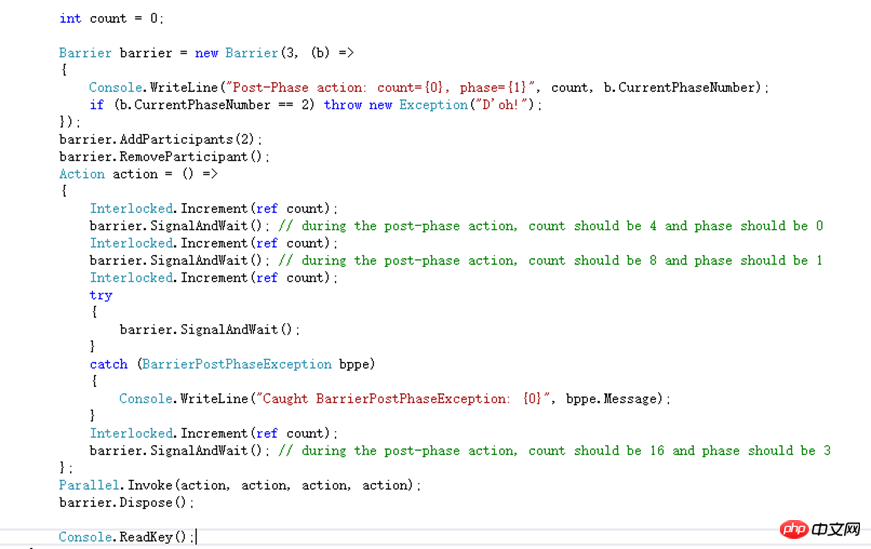
这里给Barrier初始化的参与者数量是3,同时每完成一个步骤的时候会调用委托,该方法是输出count的值步骤索引。参与者数量后来增加了两个又减少了一个。每个参与者的操作都是相同,给count进行原子自增,自增完则调用SgnalAndWait告知Barrier当前步骤已完成并等待下一个步骤的开始。但是第三次由于回调方法里抛出了一个异常,每个参与者在调用SignalAndWait的时候都会抛出一个异常。通过Parallel开始了一个并行操作。假设并行开的作业数跟Barrier参与者数量不一样就会导致在SignalAndWait会有非预期的情况出现。
接下来说两个Attribute,这个估计不算是同步构造,但是也能在线程同步中发挥作用
MethodImplAttribute这个Attribute适用于方法的,当给定的参数是MethodImplOptions.Synchronized,它会对整个方法的方法体进行加锁,凡是调用这个方法的线程在没有获得锁的时候就会被阻塞,直到拥有锁的线程释放了才将其唤醒。对静态方法而言它就相当于把该类的类型对象给锁了,即lock(typeof(ClassType));对于实例方法他就相当于把该对象的实例给锁了,即lock(this)。最开始对它内部调用了lock这个结论存在猜疑,于是用IL编译了一下,发现方法体的代码没啥异样,查看了一些源码也好无头绪,后来发现它的IL方法头跟普通的方法有区别,多了一个synchronized
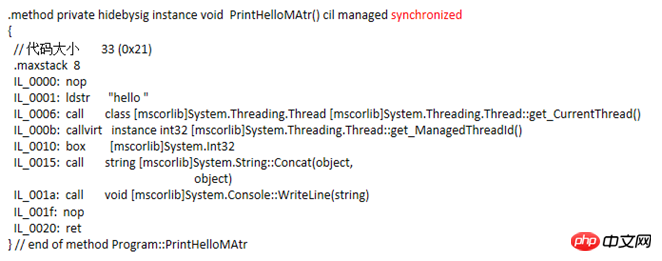
于是网上找各种资料,最后发现"junchu25"的博客[1][2]里提到用WinDbg来查看JIT生成的代码。
调用Attribute的
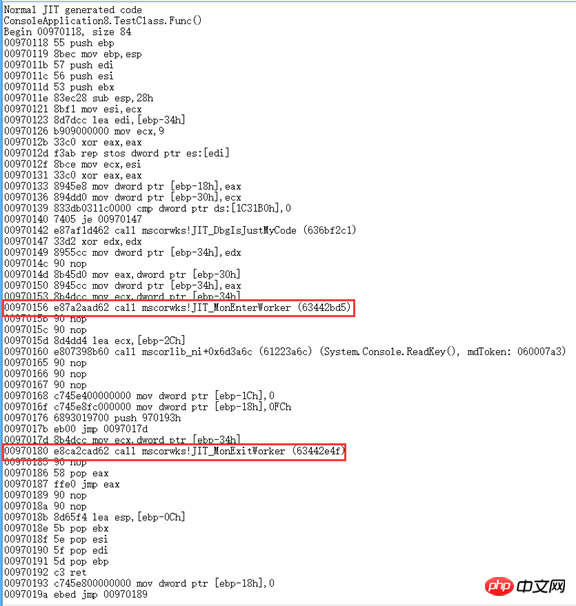
调用lock的
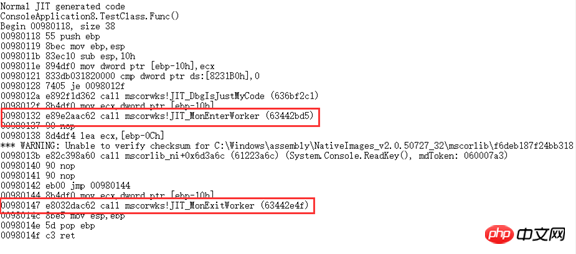
对于用这个Attribute实现的线程同步连Jeffrey都不推荐使用。
System.Runtime.Remoting.Contexts.SynchronizationAttribute This Attribute applies to classes. Add this Attribute to the class definition and inherit the class of ContextBoundOject. It will add the same lock to all methods in the class. Compare MethodImplAttribute has a wider scope. When a thread calls any method of this class, if the lock is not obtained, the thread will be blocked. There is a saying that it essentially calls lock. It is even more difficult to verify this statement. There are very few domestic resources, which also involve AppDomain and thread context. The final core is implemented by the SynchronizedServerContextSink class. AppDomain should be introduced in a separate article. But I want to talk about it a little bit here. I used to think that there are thread stacks and heap memory in the memory, and this is just a very basic division. The heap memory is also divided into several AppDomains, and there is at least one context in each AppDomain. Each object will belong to a context within an AppDomain. Objects across AppDomains cannot be accessed directly. They must be marshaled by value (equivalent to deep copying an object to the calling AppDomain) or marshaled by reference. For marshaling by reference, the class needs to inherit MarshalByRefObject. When calling an object that inherits this class, it does not call the class itself, but calls it through a proxy. Then cross-context marshaling by value operation is also required. An object usually constructed is in the default context under the process's default AppDomain, and the instance of a class that uses the SynchronizationAttribute attribute belongs to another context. Classes that inherit the ContextBoundObject base class also access objects across contexts through Using a proxy to access the object by reference marshaling does not access the object itself. As for whether to access the object across contexts, you can judge it through the RemotingServices.IsObjectOutOfContext(obj) method. SynchronizedServerContextSink is an internal class of mscorlib. When a thread calls a cross-context object, the call will be encapsulated into a WorkItem object by SynchronizedServerContextSink, which is also an internal class in mscorlib. SynchronizedServerContextSink requests SynchronizationAttribute. Attribute determines the current execution request based on whether there are multiple WorkItem execution requests. Will the processed WorkItem be executed immediately or placed in a first-in-first-out WorkItem queue for execution in order? This queue is a member of the SynchronizationAttribute. When queue members enter and exit the queue, or when the Attribute determines whether to execute the WorkItem immediately, a lock needs to be obtained. lock, the locked object is also the queue of this WorkItem. This involves the interaction of several classes. I haven't fully understood it yet. There may be errors in the above process. I will add more after a clear analysis. However, thread synchronization achieved through this Attribute is not recommended based on strong intuition, mainly due to performance losses and the lock range is relatively large.
The above is the detailed content of Detailed explanation of thread synchronization in C# multi-threading (picture and text). For more information, please follow other related articles on the PHP Chinese website!