
Home >Backend Development >C#.Net Tutorial >Detailed introduction to the past and present life of C# Lambda expression (picture)
Detailed introduction to the past and present life of C# Lambda expression (picture)

- 黄舟Original
- 2017-03-09 15:26:392563browse
Lambda expression
As early as C# 1.0, the concept of delegate type was introduced in C#. By using this type, we can pass functions as parameters. In a sense, a delegate can be understood as a managed, strongly typed function pointer.
Typically, using a delegate to pass a function requires certain steps:
Define a delegate with specified parameter types and return value types.
In a method that needs to receive function parameters, use this delegate type to define the parameter signature of the method.
Creates a delegate instance for the specified passed function.
Maybe this sounds complicated, but essentially it is. Step 3 above is usually not necessary and the C# compiler can handle this, but steps 1 and 2 are still required.
Fortunately, generics were introduced in C# 2.0. Now we can write generic classes, generic methods and most importantly: generic delegates. Still, it wasn't until .NET 3.5 that Microsoft realized that 99% of needs could actually be met with just two generic delegates:
Action: No input parameters, no return value
Action: supports 1-16 input parameters, no return value
Func: supports 1-16 input parameters and has a return value
The Action delegate returns void type, and the Func delegate returns a value of the specified type. By using these two kinds of delegation, step 1 above can be omitted in most cases. But step 2 is still required, but only with Action and Func.
So what if I just want to execute some code? C# 2.0 provides a way to create anonymous functions. Unfortunately, this syntax did not catch on. Here is an example of a simple anonymous function:
Func<double, double> square = delegate(double x)
{
return x * x;
};To improve these syntaxes, Lambda expressions were introduced in the .NET 3.5 framework and C# 3.0.
First, let’s understand the origin of the name of Lambda expression. The name actually comes from the word λ in calculus mathematics, which is a statement of what exactly is needed to express a function. Rather, it describes a system of mathematical logic that expresses calculations through the combination and substitution of variables. So, basically we have 0-n input parameters and a return value. In programming languages, we also provide void support without return values.
Let’s look at some examples of Lambda expressions:
// The compiler cannot resolve this, which makes the usage of var impossible!
// Therefore we need to specify the type.
Action dummyLambda = () =>
{
Console.WriteLine("Hello World from a Lambda expression!");
};
// Can be used as with double y = square(25);
Func<double, double> square = x => x * x;
// Can be used as with double z = product(9, 5);
Func<double, double, double> product = (x, y) => x * y;
// Can be used as with printProduct(9, 5);
Action<double, double> printProduct = (x, y) => { Console.WriteLine(x * y); };
// Can be used as with
// var sum = dotProduct(new double[] { 1, 2, 3 }, new double[] { 4, 5, 6 });
Func<double[], double[], double> dotProduct = (x, y) =>
{
var dim = Math.Min(x.Length, y.Length);
var sum = 0.0;
for (var i = 0; i != dim; i++)
sum += x[i] + y[i];
return sum;
};
// Can be used as with var result = matrixVectorProductAsync(...);
Func<double[,], double[], Task<double[]>> matrixVectorProductAsync =
async (x, y) =>
{
var sum = 0.0;
/* do some stuff using await ... */
return sum;
};From these sentences we can directly understand:
If there is only one input parameter, the parentheses can be omitted.
If there is only one line of statements and you are returning within that statement, the braces can be omitted, and the return keyword can also be omitted.
Lambda expressions can be declared to execute asynchronously by using the async keyword.
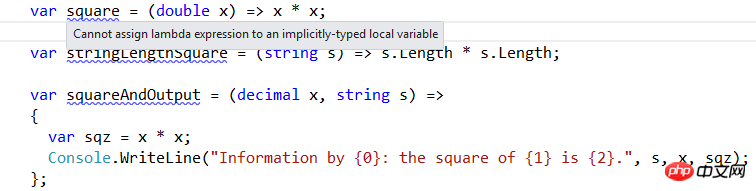
In most cases, the var declaration may not be used, but can be used in some special cases.
When using var, if the compiler cannot infer the delegate type through parameter type and return value type inference, it will throw an error message "Cannot assign lambda expression to an implicitly-typed local variable." Consider the following examples:
Now that we’ve covered most of the basics, there are some particularly cool parts of lambda expressions that we haven’t mentioned yet.
Let’s take a look at this code:
var a = 5; Funcint, int> multiplyWith = x => x * a; var result1 = multiplyWith(10); // 50 a = 10; var result2 = multiplyWith(10); // 100
As you can see, peripheral variables, that is, closures, can be used in Lambda expressions.
static void DoSomeStuff()
{
var coeff = 10;
Funcint, int> compute = x => coeff * x;
Action modifier = () =>
{
coeff = 5;
};
var result1 = DoMoreStuff(compute); // 50
ModifyStuff(modifier);
var result2 = DoMoreStuff(compute); // 25
}
static int DoMoreStuff(Funcint, int> computer)
{
return computer(5);
}
static void ModifyStuff(Action modifier)
{
modifier();
}What's going on here? First we create a local variable and two Lambda expressions. The first lambda expression shows that it can access the local variable in other scopes, which actually shows a powerful ability. This means that we can protect a variable but still access it in other methods, regardless of whether that method is defined in the current class or another class.
The second lambda expression demonstrates the ability to modify peripheral variables within a lambda expression. This means that by passing lambda expressions between functions, we can modify local variables in other scopes in other methods. Therefore, I think closures are a particularly powerful feature, but can sometimes introduce some undesirable results.
var buttons = new Button[10];
for (var i = 0; i < buttons.Length; i++)
{
var button = new Button();
button.Text = (i + 1) + ". Button - Click for Index!";
button.OnClick += (s, e) => { Messagebox.Show(i.ToString()); };
buttons[i] = button;
}
//What happens if we click ANY button?!What is the result of this strange question? Is Button 0 showing 0 and Button 1 showing 1? The answer is: all Buttons display 10!
Because as the for loop traverses, the value of the local variable i has been changed to the length of buttons, 10. A simple solution is something like:
var button = new Button();
var index = i;
button.Text = (i + 1) + ". Button - Click for Index!";
button.OnClick += (s, e) => { Messagebox.Show(index.ToString()); };
buttons[i] = button;Copy the value in variable i by defining variable index.
注:如果你使用 Visual Studio 2012 以上的版本进行测试,因为使用的编译器与 Visual Studio 2010 的不同,此处测试的结果可能不同。可参考:Visual C# Breaking Changes in Visual Studio 2012
表达式树
在使用 Lambda 表达式时,一个重要的问题是目标方法是怎么知道如下这些信息的:
我们传递的变量的名字是什么?
我们使用的表达式体的结构是什么?
在表达式体内我们用了哪些类型?
现在,表达式树帮我们解决了问题。它允许我们深究具体编译器是如何生成的表达式。此外,我们也可以执行给定的函数,就像使用 Func 和 Action 委托一样。其也允许我们在运行时解析 Lambda 表达式。
我们来看一个示例,描述如何使用 Expression 类型:
Expressionint>> expr = model => model.MyProperty; var member = expr.Body as MemberExpression; var propertyName = memberExpression.Member.Name; //only execute if member != null
上面是关于 Expression 用法的一个最简单的示例。其中的原理非常直接:通过形成一个 Expression 类型的对象,编译器会根据表达式树的解析生成元数据信息。解析树中包含了所有相关的信息,例如参数和方法体等。
方法体包含了整个解析树。通过它我们可以访问操作符、操作对象以及完整的语句,最重要的是能访问返回值的名称和类型。当然,返回变量的名称可能为 null。尽管如此,大多数情况下我们仍然对表达式的内容很感兴趣。对于开发人员的益处在于,我们不再会拼错属性的名称,因为每个拼写错误都会导致编译错误。
如果程序员只是想知道调用属性的名称,有一个更简单优雅的办法。通过使用特殊的参数属性 CallerMemberName 可以获取到被调用方法或属性的名称。编译器会自动记录这些名称。所以,如果我们仅是需要获知这些名称,而无需更多的类型信息,则我们可以参考如下的代码写法:
string WhatsMyName([CallerMemberName] string callingName = null)
{
return callingName;
}Lambda 表达式的性能
有一个大问题是:Lambda 表达式到底有多快?当然,我们期待其应该与常规的函数一样快,因为 Lambda 表达式也同样是由编译器生成的。在下一节中,我们会看到为 Lambda 表达式生成的 MSIL 与常规的函数并没有太大的不同。
一个非常有趣的讨论是关于在 Lambda 表达式中的闭包是否要比使用全局变量更快,而其中最有趣的地方就是是否当可用的变量都在本地作用域时是否会有性能影响。
让我们来看一些代码,用于衡量各种性能基准。通过这 4 种不同的基准测试,我们应该有足够的证据来说明常规函数与 Lambda 表达式之间的不同了。
class StandardBenchmark : Benchmark
{
static double[] A;
static double[] B;
public static void Test()
{
var me = new StandardBenchmark();
Init();
for (var i = 0; i 10; i++)
{
var lambda = LambdaBenchmark();
var normal = NormalBenchmark();
me.lambdaResults.Add(lambda);
me.normalResults.Add(normal);
}
me.PrintTable();
}
static void Init()
{
var r = new Random();
A = new double[LENGTH];
B = new double[LENGTH];
for (var i = 0; i )
{
A[i] = r.NextDouble();
B[i] = r.NextDouble();
}
}
static long LambdaBenchmark()
{
Funcdouble> Perform = () =>
{
var sum = 0.0;
for (var i = 0; i )
sum += A[i] * B[i];
return sum;
};
var iterations = new double[100];
var timing = new Stopwatch();
timing.Start();
for (var j = 0; j )
iterations[j] = Perform();
timing.Stop();
Console.WriteLine("Time for Lambda-Benchmark: t {0}ms",
timing.ElapsedMilliseconds);
return timing.ElapsedMilliseconds;
}
static long NormalBenchmark()
{
var iterations = new double[100];
var timing = new Stopwatch();
timing.Start();
for (var j = 0; j )
iterations[j] = NormalPerform();
timing.Stop();
Console.WriteLine("Time for Normal-Benchmark: t {0}ms",
timing.ElapsedMilliseconds);
return timing.ElapsedMilliseconds;
}
static double NormalPerform()
{
var sum = 0.0;
for (var i = 0; i )
sum += A[i] * B[i];
return sum;
}
}当然,利用 Lambda 表达式,我们可以把上面的代码写的更优雅一些,这么写的原因是防止干扰最终的结果。所以我们仅提供了 3 个必要的方法,其中一个负责执行 Lambda 测试,一个负责常规函数测试,第三个方法则是在常规函数。而缺少的第四个方法就是我们的 Lambda 表达式,其已经在第一个方法中内嵌了。使用的计算方法并不重要,我们使用了随机数,进而避免了编译器的优化。最后,我们最感兴趣的就是常规函数与 Lambda 表达式的不同。
在运行这些测试后,我们会发现,在通常情况下 Lambda 表达式不会表现的比常规函数更差。而其中的一个很奇怪的结果就是,Lambda 表达式实际上在某些情况下表现的要比常规方法还要好些。当然,如果是在使用闭包的条件下,结果就不一样了。这个结果告诉我们,使用 Lambda 表达式无需再犹豫。但是我们仍然需要仔细的考虑当我们使用闭包时所丢失的性能。在这种情景下,我们通常会丢失一点性能,但或许仍然还能接受。关于性能丢失的原因将在下一节中揭开。
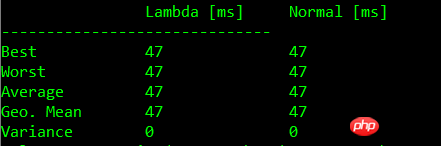
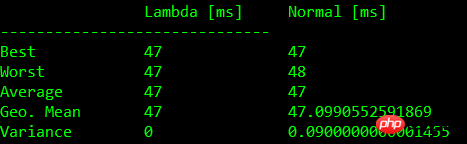
下面的表格中显示了基准测试的结果:
无入参无闭包比较
含入参比较
含闭包比较
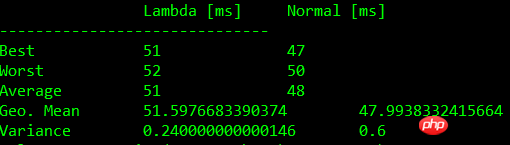
含入参含闭包比较
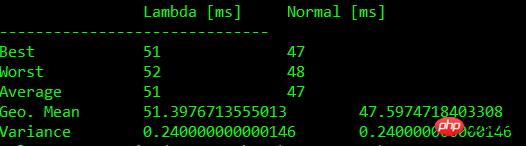
| Test | Lambda [ms] | Normal [ms] |
| 0 | 45+-1 | 46+-1 |
| 1 | 44+-1 | 46+-2 |
| 2 | 49+-3 | 45+-2 |
| 3 | 48+-2 | 45+-2 |
注:测试结果根据机器硬件配置有所不同
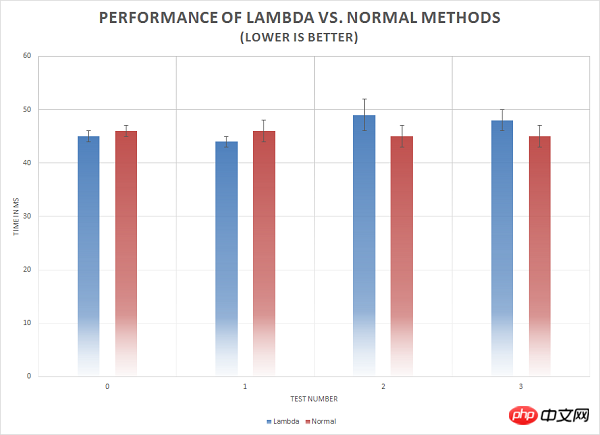
下面的图表中同样展现了测试结果。我们可以看到,常规函数与 Lambda 表达式会有相同的限制。使用 Lambda 表达式并没有显著的性能损失。
MSIL揭秘Lambda表达式
使用著名的工具 LINQPad 我们可以查看 MSIL。
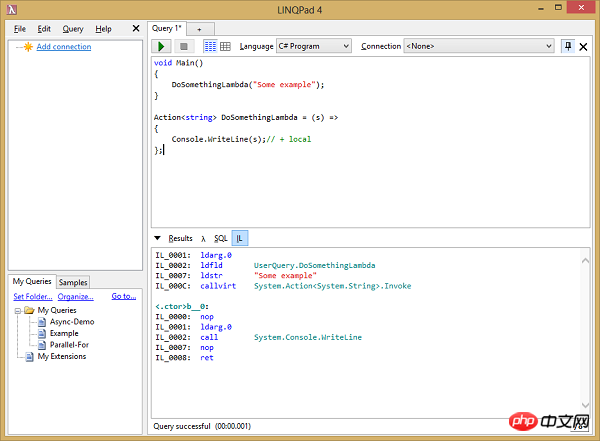
我们来看下第一个示例:
void Main()
{
DoSomethingLambda("some example");
DoSomethingNormal("some example");
}Lambda 表达式:
Actionstring> DoSomethingLambda = (s) =>
{
Console.WriteLine(s);// + local
};相应的方法的代码:
void DoSomethingNormal(string s)
{
Console.WriteLine(s);
}两段代码的 MSIL 代码:
IL_0001: ldarg.0 IL_0002: ldfld UserQuery.DoSomethingLambda IL_0007: ldstr "some example" IL_000C: callvirt System.Action.Invoke IL_0011: nop IL_0012: ldarg.0 IL_0013: ldstr "some example" IL_0018: call UserQuery.DoSomethingNormal DoSomethingNormal: IL_0000: nop IL_0001: ldarg.1 IL_0002: call System.Console.WriteLine IL_0007: nop IL_0008: ret b__0: IL_0000: nop IL_0001: ldarg.0 IL_0002: call System.Console.WriteLine IL_0007: nop IL_0008: ret
此处最大的不同就是函数的命名和用法,而不是声明方式,实际上声明方式是相同的。编译器会在当前类中创建一个新的方法,然后推断该方法的用法。这没什么特别的,只是使用 Lambda 表达式方便了许多。从 MSIL 的角度来看,我们做了相同的事,也就是在当前的对象上调用了一个方法。
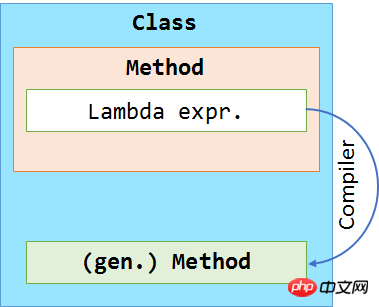
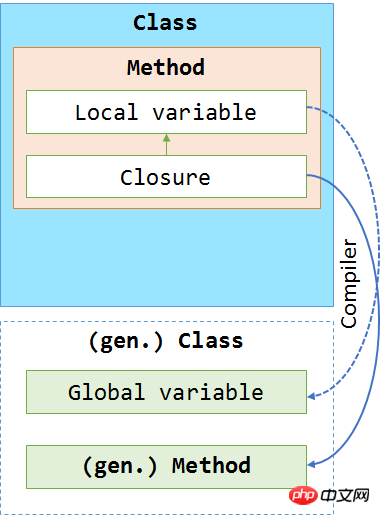
我们可以将这些分析放到一张图中,来展现编译器所做的更改。在下面这张图中我们可以看到编译器将 Lambda 表达式移到了一个单独的方法中。
在第二个示例中,我们将展现 Lambda 表达式真正神奇的地方。在这个例子中,我们使用了一个常规的方法来访问全局变量,然后用一个 Lambda 表达式来捕获局部变量。代码如下:
void Main()
{
int local = 5;
Actionstring> DoSomethingLambda = (s) => {
Console.WriteLine(s + local);
};
global = local;
DoSomethingLambda("Test 1");
DoSomethingNormal("Test 2");
}
int global;
void DoSomethingNormal(string s)
{
Console.WriteLine(s + global);
}目前看来没什么特殊的。关键的问题是:编译器是如何处理 Lambda 表达式的?
IL_0000: newobj UserQuery+c__DisplayClass1..ctor IL_0005: stloc.1 // CS$8__locals2 IL_0006: nop IL_0007: ldloc.1 // CS$8__locals2 IL_0008: ldc.i4.5 IL_0009: stfld UserQuery+c__DisplayClass1.local IL_000E: ldloc.1 // CS$8__locals2 IL_000F: ldftn UserQuery+c__DisplayClass1.b__0 IL_0015: newobj System.Action..ctor IL_001A: stloc.0 // DoSomethingLambda IL_001B: ldarg.0 IL_001C: ldloc.1 // CS$8__locals2 IL_001D: ldfld UserQuery+c__DisplayClass1.local IL_0022: stfld UserQuery.global IL_0027: ldloc.0 // DoSomethingLambda IL_0028: ldstr "Test 1" IL_002D: callvirt System.Action.Invoke IL_0032: nop IL_0033: ldarg.0 IL_0034: ldstr "Test 2" IL_0039: call UserQuery.DoSomethingNormal IL_003E: nop DoSomethingNormal: IL_0000: nop IL_0001: ldarg.1 IL_0002: ldarg.0 IL_0003: ldfld UserQuery.global IL_0008: box System.Int32 IL_000D: call System.String.Concat IL_0012: call System.Console.WriteLine IL_0017: nop IL_0018: ret c__DisplayClass1.b__0: IL_0000: nop IL_0001: ldarg.1 IL_0002: ldarg.0 IL_0003: ldfld UserQuery+c__DisplayClass1.local IL_0008: box System.Int32 IL_000D: call System.String.Concat IL_0012: call System.Console.WriteLine IL_0017: nop IL_0018: ret c__DisplayClass1..ctor: IL_0000: ldarg.0 IL_0001: call System.Object..ctor IL_0006: ret
还是一样,两个函数从调用语句上看是相同的,还是应用了与之前相同的机制。也就是说,编译器为该函数生成了一个名字,并把它替换到代码中。而此处最大的区别在于,编译器同时生成了一个类,而编译器生成的函数就被放到了这个类中。那么,创建这个类的目的是什么呢?它使变量具有了全局作用域范围,而此之前其已被用于捕获变量。通过这种方式,Lambda 表达式有能力访问局部作用域的变量(因为从 MSIL 的观点来看,其仅是类实例中的一个全局变量而已)。
然后,通过这个新生成的类的实例,所有的变量都从这个实例分配和读取。这解决了变量间存在引用的问题(会对类添加一个额外的引用 – 确实是这样)。编译器已经足够的聪明,可以将那些被捕获变量放到这个类中。所以,我们可能会期待使用 Lambda 表达式并不会存在性能问题。然而,这里我们必须提出一个警告,就是这种行为可能会引起内存泄漏,因为对象仍然被 Lambda 表达式引用着。只要这个函数还在,其作用范围仍然有效(之前我们已经了解了这些,但现在我们知道了原因)。
像之前一样,我们把这些分析放入一张图中。从图中我们可以看到,闭包并不是仅有的被移动的方法,被捕获变量也被移动了。所有被移动的对象都会被放入一个编译器生成的类中。最后,我们从一个未知的类实例化了一个对象。
The above is the detailed content of Detailed introduction to the past and present life of C# Lambda expression (picture). For more information, please follow other related articles on the PHP Chinese website!