


看书上提到的,记下来,加深一下印象。
一、mybatis处理CLOB/BLOB列的类型处理,例如:
CREATE TABLE USER_PICS (
ID INT(11) NOT NULL AUTO_INCREMENT,
NAME VARCHAR(50) DEFAULT NULL,
PIC BLOB,
BIO LONGTEXT,
PRIMARY KEY (ID)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=LATIN1;默认情况下,mybatis会将CLOB类型的列映射到java.lang.String类型上,而把BLOB类型的列映射到byte[]类型上
public class UserPic{
private int id;
private String name;
private byte[] pic;
private String bio;
//setters & getters
}创建mapper文件代码如下
<insert id="insertUserPic" parameterType="UserPic">
INSERT INTO USER_PICS(NAME, PIC,BIO)
VALUES(#{name},#{pic},#{bio})
</insert>
<select id="getUserPic" parameterType="int" resultType="UserPic">
SELECT * FROM USER_PICS WHERE ID=#{id}
</select>下列的insertUserPic()展示了如何将数据插入到 CLOB/BLOB 类型的列上:
public void insertUserPic(){
byte[] pic = null;
try{
File file = new File("C:\\Images\\UserImg.jpg");
InputStream is = new FileInputStream(file);
pic = new byte[is.available()];
is.read(pic);
is.close();
}catch (FileNotFoundException e){
e.printStackTrace();
}catch (IOException e){
e.printStackTrace();
}
String name = "UserName";
String bio = "put some lenghty bio here";
UserPic userPic = new UserPic(0, name, pic , bio);
SqlSession sqlSession = MyBatisUtil.openSession();
try{
UserPicMapper mapper =
sqlSession.getMapper(UserPicMapper.class);
mapper.insertUserPic(userPic);
sqlSession.commit();
}
finally{
sqlSession.close();
}
}下面的 getUserPic()方法展示了怎样将 CLOB 类型数据读取到 String 类型,BLOB 类型数据读取成 byte[]属性:
public void getUserPic(){
UserPic userPic = null;
SqlSession sqlSession = MyBatisUtil.openSession();
try{
UserPicMapper mapper =
sqlSession.getMapper(UserPicMapper.class);
userPic = mapper.getUserPic(1);
}finally{
sqlSession.close();
}
byte[] pic = userPic.getPic();
try{
OutputStream os = new FileOutputStream(new
File("C:\\Images\\UserImage_FromDB.jpg"));
os.write(pic);
os.close();
}catch (FileNotFoundException e){
e.printStackTrace();
}catch (IOException e){
e.printStackTrace();
}
}二、使用RowBound来进行分页处理
mybatis可以使用RowBound来进行分页处理,RowBound有两个参数,offset和limit。offset标识开始的位置,limit标识要取的记录的数目,例如:
<select id="findAllStudents" resultMap="StudentResult">
select * from Students
</select>然后,你可以加载如下加载第一页数据(前 25 条) :
int offset =0 , limit =25; RowBounds rowBounds = new RowBounds(offset, limit); List<Student> = studentMapper.getStudents(rowBounds);
个人感觉这个对象可能比较适用于使用反向工程生成的代码,进行单表查询的时候使用,与mybatis的分页插件pageHelper比较像,不知道是不是,大牛有知道的帮忙解释一下。
三、mybatis-3.2.2 并不支持使用 resultMap 配置将查询的结果集映射成一个属性为key,而另外属性为 value 的 HashMap。sqlSession.selectMap()则可以返回 以给定列为 key,记录对象为 value 的 map。我们不能将其配置成使用其中一个属性作为 key,而另外的属性作为 value。
四、缓存
mybatis对通过映射的select语句加载查询结果提供了内建的缓存支持。
默认情况下,开启一级缓存,即:如果你使用同一个sqlSession接口对象条用了同一个select语句,则直接从缓存中返回结构,不会再次查询数据库。
二级缓存,默认是关闭的,你可以通过在mapper映射文件中加入下面这一行来实现。
一个缓存的配置和缓存实例被绑定到映射器配置文件所在的名空间 (namespace)上,所以在相同名空间内的所有语
句被绑定到一个 cache 中。
<cache eviction="FIFO" flushInterval="60000" size="512" readOnly="true"/>
<!--
一、eviction:定义缓存的移除机制,主要包括
1、LUR(Least Recently used最近最少使用)
2、FIFO(first in first out,先进先出)
3、SOFT(software reference,软引用(不清楚什么玩意))
4、WEAK(weak reference,弱引用,不知道什么鬼)
二、flushInterval:缓存刷新间隔,以毫秒计。默认情况下不设置。所以不使用刷新间隔,缓存 cache 只
有调用语句的时候刷新。
三、size:此表示缓存 cache 中能容纳的最大元素数。默认值是 1024,你可以设置成任意的正整数。
四、readOnly:一个只读的缓存 cache 会对所有的调用者返回被缓存对象的同一个实例(实际返回的是被返回对
象的一份引用)。一个读/写缓存 cache 将会返回被返回对象的一分拷贝(通过序列化) 。默认情况下设
置为 false。可能的值有 false 和 true。
-->mybatis-config.xml中配置的
<settings>
<!-- 该配置影响的所有映射器中配置的缓存的全局开关。-->
<setting name="cacheEnable" value="true"/>
</settings>
 Java之Mybatis的二级缓存怎么使用May 24, 2023 pm 06:16 PM
Java之Mybatis的二级缓存怎么使用May 24, 2023 pm 06:16 PM缓存的概述和分类概述缓存就是一块内存空间.保存临时数据为什么使用缓存将数据源(数据库或者文件)中的数据读取出来存放到缓存中,再次获取的时候,直接从缓存中获取,可以减少和数据库交互的次数,这样可以提升程序的性能!缓存的适用情况适用于缓存的:经常查询但不经常修改的(eg:省市,类别数据),数据的正确与否对最终结果影响不大的不适用缓存的:经常改变的数据,敏感数据(例如:股市的牌价,银行的汇率,银行卡里面的钱)等等MyBatis缓存类别一级缓存:它是sqlSession对象的缓存,自带的(不需要配置)不
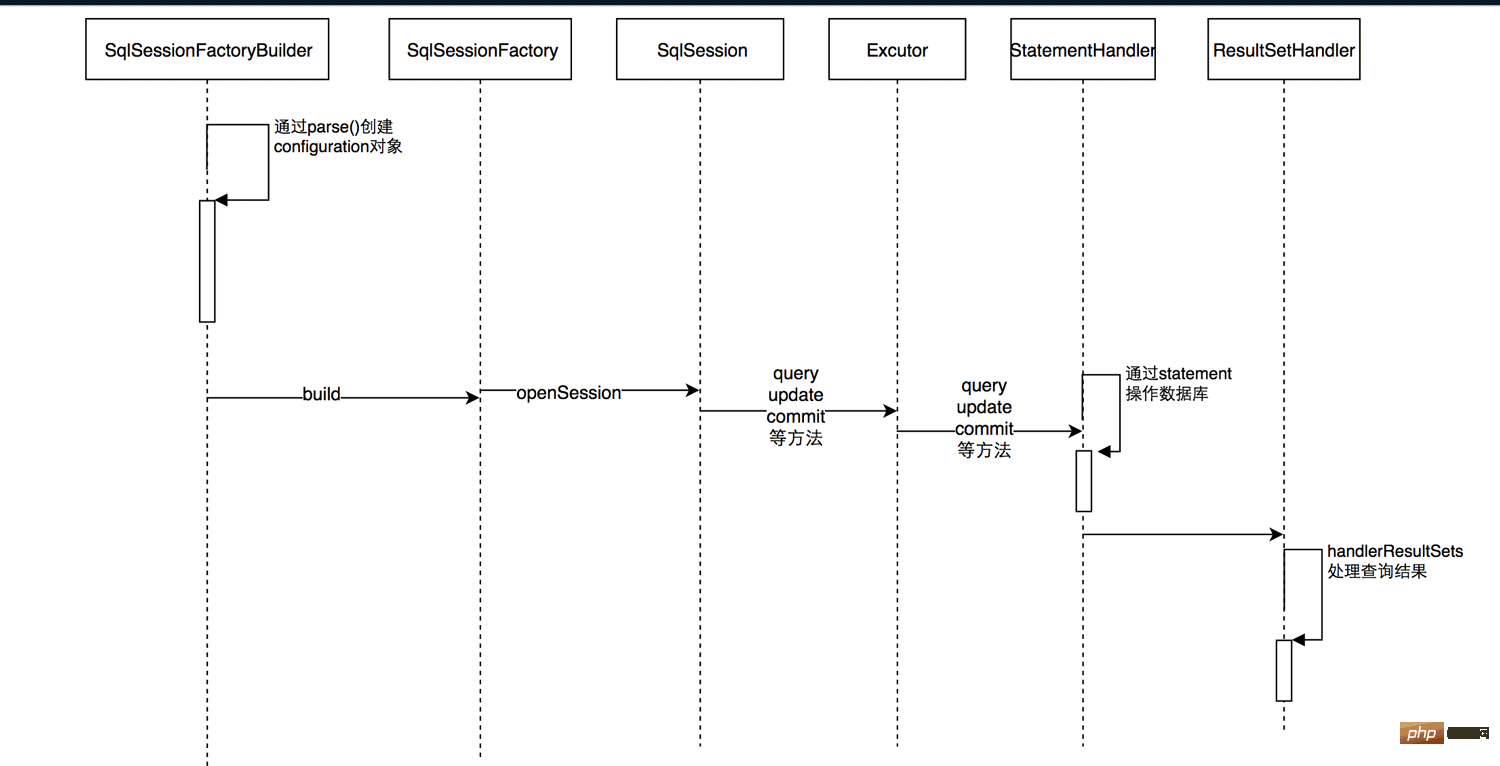 怎么使用springboot+mybatis拦截器实现水平分表May 14, 2023 pm 06:43 PM
怎么使用springboot+mybatis拦截器实现水平分表May 14, 2023 pm 06:43 PMMyBatis允许使用插件来拦截的方法Executor(update,query,flushStatements,commit,rollback,getTransaction,close,isClosed)ParameterHandler(getParameterObject,setParameters)ResultSetHandler(handleResultSets,handleOutputParameters)StatementHandler(prepare,parameterize,ba
 mybatis分页的几种方式Jan 04, 2023 pm 04:23 PM
mybatis分页的几种方式Jan 04, 2023 pm 04:23 PMmybatis分页的方式:1、借助数组进行分页,首先查询出全部数据,然后再list中截取需要的部分。2、借助Sql语句进行分页,在sql语句后面添加limit分页语句即可。3、利用拦截器分页,通过拦截器给sql语句末尾加上limit语句来分页查询。4、利用RowBounds实现分页,需要一次获取所有符合条件的数据,然后在内存中对大数据进行操作即可实现分页效果。
 springboot怎么整合mybatis分页拦截器May 13, 2023 pm 04:31 PM
springboot怎么整合mybatis分页拦截器May 13, 2023 pm 04:31 PM简介今天开发时想将自己写好的代码拿来优化,因为不想在开发服弄,怕搞坏了到时候GIT到生产服一大堆问题,然后把它分离到我轮子(工具)项目上,最后运行后发现我获取List的时候很卡至少10秒,我惊了平时也就我的正常版本是800ms左右(不要看它很久,因为数据量很大,也很正常。),前提是我也知道很慢,就等的确需要优化时,我在放出我优化的plus版本,回到10秒哪里,最开始我刚刚接到这个app项目时,在我用PageHelper.startPage(page,num);(分页),还没等查到的数据封装(Pa
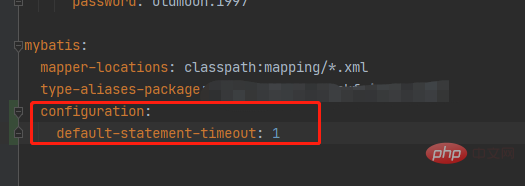 springboot配置mybatis的sql执行超时时间怎么解决May 15, 2023 pm 06:10 PM
springboot配置mybatis的sql执行超时时间怎么解决May 15, 2023 pm 06:10 PM当某些sql因为不知名原因堵塞时,为了不影响后台服务运行,想要给sql增加执行时间限制,超时后就抛异常,保证后台线程不会因为sql堵塞而堵塞。一、yml全局配置单数据源可以,多数据源时会失效二、java配置类配置成功抛出超时异常。importcom.alibaba.druid.pool.DruidDataSource;importcom.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;importorg.apache.
 mybatis怎么调用mysql存储过程并获取返回值May 27, 2023 am 09:01 AM
mybatis怎么调用mysql存储过程并获取返回值May 27, 2023 am 09:01 AMmybatis调用mysql存储过程并获取返回值1、mysql创建存储过程#结束符号默认;,delimiter$$语句表示结束符号变更为$$delimiter$$CREATEPROCEDURE`demo`(INinStrVARCHAR(100),outourStrVARCHAR(4000))BEGINSETourStr='01';if(inStr=='02')thensetourStr='02';en
 怎么用springboot+mybatis plus实现树形结构查询May 21, 2023 pm 05:01 PM
怎么用springboot+mybatis plus实现树形结构查询May 21, 2023 pm 05:01 PM背景实际开发过程中经常需要查询节点树,根据指定节点获取子节点列表,以下记录了获取节点树的操作,以备不时之需。使用场景可以用于系统部门组织机构、商品分类、城市关系等带有层级关系的数据结构;设计思路递归模型即根节点、枝干节点、叶子节点,数据模型如下:idcodenameparent_code110000电脑0220000手机0310001联想笔记本10000410002惠普笔记本1000051000101联想拯救者1000161000102联想小新系列10001实现代码表结构CREATETABLE`
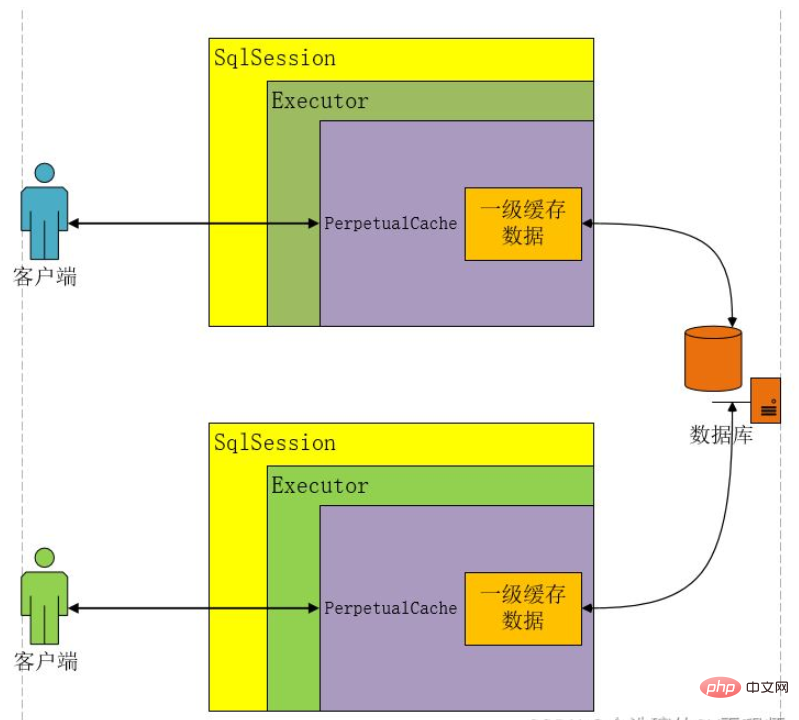 Java Mybatis一级缓存和二级缓存是什么Apr 25, 2023 pm 02:10 PM
Java Mybatis一级缓存和二级缓存是什么Apr 25, 2023 pm 02:10 PM一、什么是缓存缓存是内存当中一块存储数据的区域,目的是提高查询效率。MyBatis会将查询结果存储在缓存当中,当下次执行相同的SQL时不访问数据库,而是直接从缓存中获取结果,从而减少服务器的压力。什么是缓存?存在于内存中的一块数据。缓存有什么作用?减少程序和数据库的交互,提高查询效率,降低服务器和数据库的压力。什么样的数据使用缓存?经常查询但不常改变的,改变后对结果影响不大的数据。MyBatis缓存分为哪几类?一级缓存和二级缓存如何判断两次Sql是相同的?查询的Sql语句相同传递的参数值相同对结


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

WebStorm Mac version
Useful JavaScript development tools

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

