


|
Using php to read the file 3.txt, but there is a garbled problem. D:/3.txt is a utf-8 file. Code:
There is a BOM problem. In order to mark this text as UTF text, Microsoft added three bytes, which are: ord($charset[1]) == 239 && ord($charset[2]) == 187 && ord($charset[3]) == 191 The above code is the php code to delete the BOM. When intercepting, you can start intercepting from the fourth position. If you intercept from the first, second, or third digit, garbled characters may appear. In UTF-8 encoding, a Chinese character may be represented by three bytes. If there are Chinese characters, do not use ANSI encoding, otherwise garbled characters will appear when reading. ANSI encoding (from the encyclopedia) Unicode and ansi are both representations of character codes. In order for the computer to support more languages, 2 bytes in the range of 0x80~0xFF are usually used to represent 1 character. For example: the Chinese character '中' is stored in the two bytes [0xD6,0xD0] in the Chinese operating system. Different countries and regions have formulated different standards, resulting in their own encoding standards such as GB2312, BIG5, and JIS. These various Chinese character extended encodings that use 2 bytes to represent a character are called ANSI encodings. Under Simplified Chinese systems, ANSI encoding represents GB2312 encoding, and under Japanese operating systems, ANSI encoding represents JIS encoding. Different ANSI codes are incompatible with each other. When information is exchanged internationally, text belonging to two languages cannot be stored in the same ANSI coded text. If it is English or symbols, then the encoding is 1 byte, and the highest bit is 0. If it is Chinese, the highest bit must be 1, and the size is 2 bytes. From this point of view, if there is Japanese or Korean in the text file that stores ANSI in our Chinese computer, it may cause encoding conflicts. That is to say, we cannot use ANSI encoding to store Chinese, Japanese and Korean in Notepad. mixed text. The notepad in the computer is developed for the Chinese version of the system. If you want it to be universal, you have to store the txt file into a Unicode format text file. Therefore, if you want to do international things, it is more convenient to use Unicode. In fact, most of today's operating systems are encoded in Unicode. If we use ansi encoding, we still have to convert it to Unicode during internal processing of the system, which in turn results in low code efficiency. It’s more convenient to use Unicode! php garbled problem Code:
There is a garbled problem. Add header("Content-type: text/html;charset=utf-8"); and that's it. Used to set the html encoding format to utf-8 To solve garbled characters, look at three places: 1. Database encoding 2. Page encoding 3. Connection encoding If these three places are consistent, there will be no garbled code problem. |

 Working with Flash Session Data in LaravelMar 12, 2025 pm 05:08 PM
Working with Flash Session Data in LaravelMar 12, 2025 pm 05:08 PMLaravel simplifies handling temporary session data using its intuitive flash methods. This is perfect for displaying brief messages, alerts, or notifications within your application. Data persists only for the subsequent request by default: $request-
 cURL in PHP: How to Use the PHP cURL Extension in REST APIsMar 14, 2025 am 11:42 AM
cURL in PHP: How to Use the PHP cURL Extension in REST APIsMar 14, 2025 am 11:42 AMThe PHP Client URL (cURL) extension is a powerful tool for developers, enabling seamless interaction with remote servers and REST APIs. By leveraging libcurl, a well-respected multi-protocol file transfer library, PHP cURL facilitates efficient execution of various network protocols, including HTTP, HTTPS, and FTP. This extension offers granular control over HTTP requests, supports multiple concurrent operations, and provides built-in security features.
 Simplified HTTP Response Mocking in Laravel TestsMar 12, 2025 pm 05:09 PM
Simplified HTTP Response Mocking in Laravel TestsMar 12, 2025 pm 05:09 PMLaravel provides concise HTTP response simulation syntax, simplifying HTTP interaction testing. This approach significantly reduces code redundancy while making your test simulation more intuitive. The basic implementation provides a variety of response type shortcuts: use Illuminate\Support\Facades\Http; Http::fake([ 'google.com' => 'Hello World', 'github.com' => ['foo' => 'bar'], 'forge.laravel.com' =>
 12 Best PHP Chat Scripts on CodeCanyonMar 13, 2025 pm 12:08 PM
12 Best PHP Chat Scripts on CodeCanyonMar 13, 2025 pm 12:08 PMDo you want to provide real-time, instant solutions to your customers' most pressing problems? Live chat lets you have real-time conversations with customers and resolve their problems instantly. It allows you to provide faster service to your custom
 Explain the concept of late static binding in PHP.Mar 21, 2025 pm 01:33 PM
Explain the concept of late static binding in PHP.Mar 21, 2025 pm 01:33 PMArticle discusses late static binding (LSB) in PHP, introduced in PHP 5.3, allowing runtime resolution of static method calls for more flexible inheritance.Main issue: LSB vs. traditional polymorphism; LSB's practical applications and potential perfo
 PHP Logging: Best Practices for PHP Log AnalysisMar 10, 2025 pm 02:32 PM
PHP Logging: Best Practices for PHP Log AnalysisMar 10, 2025 pm 02:32 PMPHP logging is essential for monitoring and debugging web applications, as well as capturing critical events, errors, and runtime behavior. It provides valuable insights into system performance, helps identify issues, and supports faster troubleshoot
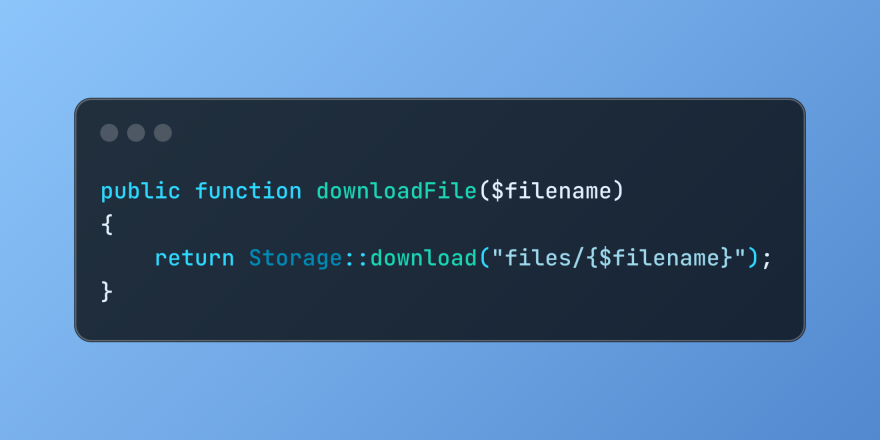 Discover File Downloads in Laravel with Storage::downloadMar 06, 2025 am 02:22 AM
Discover File Downloads in Laravel with Storage::downloadMar 06, 2025 am 02:22 AMThe Storage::download method of the Laravel framework provides a concise API for safely handling file downloads while managing abstractions of file storage. Here is an example of using Storage::download() in the example controller:
 How to Register and Use Laravel Service ProvidersMar 07, 2025 am 01:18 AM
How to Register and Use Laravel Service ProvidersMar 07, 2025 am 01:18 AMLaravel's service container and service providers are fundamental to its architecture. This article explores service containers, details service provider creation, registration, and demonstrates practical usage with examples. We'll begin with an ove


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Dreamweaver Mac version
Visual web development tools

SublimeText3 Chinese version
Chinese version, very easy to use

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

