



MHA故障切换和在线切换的代码解析
前段时间我的同事沈龙星整理了一下MHA故障切换和在线切换的代码流程,在征得其同意后,在此转发。以下是正文
本文是以MySQL5.5为基础的,因此没有涉及到gtid相关内容。MHA的主从切换过程分为failover和rotate两种,前者适用于原Master down的情况,后者是在在线切换的情况下使用。下面分别讲解failover的处理流程
- MHA::MasterFailover::main()
- ->do_master_failover
- Phase 1: Configuration Check Phase
- -> check_settings:
- check_node_version:查看MHA的版本信息
- connect_all_and_read_server_status:确认各个node的MySQL实例是否可以连接
- get_dead_servers/get_alive_servers/get_alive_slaves:double check各个node的死活状态
- start_sql_threads_if:查看Slave_SQL_Running是否为Yes,若不是则启动SQL thread
- Phase 2: Dead Master Shutdown Phase:对于我们来说,唯一的作用就是stop IO thread
- -> force_shutdown($dead_master):
- stop_io_thread:所有slave的IO thread stop掉(将stop掉master)
- force_shutdown_internal(实际上就是执行配置文件中的master_ip_failover_script/shutdown_script,若无则不执行):
- master_ip_failover_script:如果设置了VIP,则首先切换VIP
- shutdown_script:如果设置了shutdown脚本,则执行
- Phase 3: Master Recovery Phase
- -> Phase 3.1: Getting Latest Slaves Phase(取得latest slave)
- read_slave_status:取得各个slave的binlog file/position
- check_slave_status:调用"SHOW SLAVE STATUS"来取得slave的如下信息:
- Slave_IO_State, Master_Host,
- Master_Port, Master_User,
- Slave_IO_Running, Slave_SQL_Running,
- Master_Log_File, Read_Master_Log_Pos,
- Relay_Master_Log_File, Last_Errno,
- Last_Error, Exec_Master_Log_Pos,
- Relay_Log_File, Relay_Log_Pos,
- Seconds_Behind_Master, Retrieved_Gtid_Set,
- Executed_Gtid_Set, Auto_Position
- Replicate_Do_DB, Replicate_Ignore_DB, Replicate_Do_Table,
- Replicate_Ignore_Table, Replicate_Wild_Do_Table,
- Replicate_Wild_Ignore_Table
- identify_latest_slaves:
- 通过比较各个slave中的Master_Log_File/Read_Master_Log_Pos,来找到latest的slave
- identify_oldest_slaves:
- 通过比较各个slave中的Master_Log_File/Read_Master_Log_Pos,来找到oldest的slave
- -> Phase 3.2: Saving Dead Master's Binlog Phase:
- save_master_binlog:
- 如果dead master可以ssh连接,则走如下分支:
- save_master_binlog_internal:(使用node节点的save_binary_logs脚本在dead master上做拷贝)
- save_binary_logs --command=save --start_file=mysql-bin.000281 --start_pos=107 --binlog_dir=/opt/mysql/data/binlog --output_file=/opt/mha/log/saved_master_binlog_from_10.27.177.245_3306_20160108211857.binlog --handle_raw_binlog=1 --disable_log_bin=0 --manager_version=0.55
- generate_diff_binary_log:
- concat_all_binlogs_from:
- dump_binlog:就是将binlog文件dump到target文件中,用的就是binmode read
- dump_binlog_header_fde:从0读到position-1
- dump_binlog_from_pos:从position开始,dump binlog file到target file
- file_copy:
- 文件拷贝,是将上述生成的binlog文件拷贝到manage节点的manager_workdir目录下
- 如果dead master无法ssh登录,则master上未同步到slave的txn丢失
- -> Phase 3.3: Determining New Master Phase
- find_latest_base_slave:
- find_latest_base_slave_internal:
- pos_cmp( $oldest_mlf, $oldest_mlp, $latest_mlf, $latest_mlp )
- 判断latest/oldest slave的binlog位置是不是相同,若相同则不需要同步relay log
- apply_diff_relay_logs --command=find --latest
- 查看latest slave中是否有oldest缺少的relay log,若无则继续,否则failover失败
- 查找的方法很简单,就是逆序的读latest slave的relay log文件,一直找到file/position为止
- select_new_master:选出新的master节点
- If preferred node is specified, one of active preferred nodes will be new master.
- If the latest server behinds too much (i.e. stopping sql thread for online backups),
- we should not use it as a new master, we should fetch relay log there. Even though preferred
- master is configured, it does not become a master if it's far behind.
- get_candidate_masters:
- 就是配置文件中配置了candidate_master>0的节点
- get_bad_candidate_masters:
- # The following servers can not be master:
- # - dead servers
- # - Set no_master in conf files (i.e. DR servers)
- # - log_bin is disabled
- # - Major version is not the oldest
- # - too much replication delay(slave与master的binlog position差距大于100000000)
- Searching from candidate_master slaves which have received the latest relay log events
- if NOT FOUND:
- Searching from all candidate_master slaves
- if NOT FOUND:
- Searching from all slaves which have received the latest relay log events
- if NOT FOUND:
- Searching from all slaves
- -> Phase 3.4: New Master Diff Log Generation Phase
- recover_relay_logs:
- 判断new master是不是latest slave,若不是则使用apply_diff_relay_logs --命令生成差分log,
- 并发送到新new master
- recover_master_internal:
- 将3.2中生成的daed master上的binlog发送到new master
- -> Phase 3.5: Master Log Apply Phase
- recover_slave:
- apply_diff:
- 0. wait_until_relay_log_applied,等待new master将relaylog执行完
- 1. 判断Exec_Master_Log_Pos == Read_Master_Log_Pos,
- 如果不相等则使用save_binary_logs --command=save生成差分log
- 2. 调用apply_diff_relay_logs命令,让new master进行recover.其中:
- 2.1 recover的log分为三部分:
- exec_diff:Exec_Master_Log_Pos和Read_Master_Log_Pos的差分
- read_diff:new master与lastest slave的relay log的差分
- binlog_diff:lastest slave与daed master之间的binlog差分
- 实际上apply_diff_relay_logs就是调用mysqlbinlog command进行recover
- //如果设置了vip,则需要调用master_ip_failover_script进行vip的failover
- Phase 4: Slaves Recovery Phase
- -> Phase 4.1: Starting Parallel Slave Diff Log Generation Phase
- 生成Slave与New Slave之间的差异日志,并将该日志拷贝到各Slave的工作目录下。
- -> Phase 4.2: Starting Parallel Slave Log Apply Phase
- recover_slave:
- 对各个slave进行恢复,同Phase3.5
- change_master_and_start_slave:
- 通过CHANGE MASTER TO命令将这些Slave指向新的New Master,最后开始复制(start slave)
- Phase 5: New master cleanup phase
- reset_slave_on_new_master
- 清理New Master其实就是重置slave info,即取消原来的Slave信息。至此整个Master故障切换过程完成
rotate的处理过程
- MHA::MasterRotate::main()
-> do_master_online_switch:
Phase 1: Configuration Check Phase
-> identify_orig_master
connect_all_and_read_server_status:
connect_check:首先进行connect check,确保各个server的MySQL服务都正常
connect_and_get_status:获取MySQL实例的server_id/mysql_version/log_bin..等信息
这一步还有一个重要的作用,是获取当前的master节点。通过执行show slave status,
如果输出为空,说明当前节点是master节点。
validate_current_master:取得master节点的信息,并判断配置的正确性
check是否有server down,若有则退出rotate
check master alive or not,若dead则退出rotate
check_repl_priv:
查看用户是否有replication的权限
获取monitor_advisory_lock,以保证当前没有其他的monitor进程在master上运行
执行:SELECT GET_LOCK('MHA_Master_High_Availability_Monitor', ?) AS Value
获取failover_advisory_lock,以保证当前没有其他的failover进程在slave上运行
执行:SELECT GET_LOCK('MHA_Master_High_Availability_Failover', ?) AS Value
check_replication_health:
执行:SHOW SLAVE STATUS来判断如下状态:current_slave_position/has_replication_problem
其中,has_replication_problem具体check如下内容:IO线程/SQL线程/Seconds_Behind_Master(1s)
get_running_update_threads:
使用show processlist来查询当前有没有执行update的线程存在,若有则退出switch
-> identify_new_master
set_latest_slaves:当前的slave节点都是latest slave
select_new_master:选出新的master节点
If preferred node is specified, one of active preferred nodes will be new master.
If the latest server behinds too much (i.e. stopping sql thread for online backups),
we should not use it as a new master, we should fetch relay log there. Even though preferred
master is configured, it does not become a master if it's far behind.
get_candidate_masters:
就是配置文件中配置了candidate_master>0的节点
get_bad_candidate_masters:
# The following servers can not be master:
# - dead servers
# - Set no_master in conf files (i.e. DR servers)
# - log_bin is disabled
# - Major version is not the oldest
# - too much replication delay(slave与master的binlog position差距大于100000000)
Searching from candidate_master slaves which have received the latest relay log events
if NOT FOUND:
Searching from all candidate_master slaves
if NOT FOUND:
Searching from all slaves which have received the latest relay log events
if NOT FOUND:
Searching from all slaves
Phase 2: Rejecting updates Phase
reject_update:lock table来reject write binlog
如果MHA的配置文件中设置了"master_ip_online_change_script"参数,则执行该脚本来disable writes on the current master
该脚本在使用了vip的时候才需要设置
reconnect:确保当前与master的连接正常
lock_all_tables:执行FLUSH TABLES WITH READ LOCK,来lock table
check_binlog_stop:连续两次show master status,来判断写binlog是否已经停止
read_slave_status:
get_alive_slaves:
check_slave_status:调用"SHOW SLAVE STATUS"来取得slave的如下信息:
Slave_IO_State, Master_Host,
Master_Port, Master_User,
Slave_IO_Running, Slave_SQL_Running,
Master_Log_File, Read_Master_Log_Pos,
Relay_Master_Log_File, Last_Errno,
Last_Error, Exec_Master_Log_Pos,
Relay_Log_File, Relay_Log_Pos,
Seconds_Behind_Master, Retrieved_Gtid_Set,
Executed_Gtid_Set, Auto_Position
Replicate_Do_DB, Replicate_Ignore_DB, Replicate_Do_Table,
Replicate_Ignore_Table, Replicate_Wild_Do_Table,
Replicate_Wild_Ignore_Table
switch_master:
switch_master_internal:
master_pos_wait:调用select master_pos_wait函数,等待主从同步完成
get_new_master_binlog_position:执行'show master status'
Allow write access on the new master:
调用master_ip_online_change_script --command=start ...,将vip指向new master
disable_read_only:
在新master上执行:SET GLOBAL read_only=0
switch_slaves:
switch_slaves_internal:
change_master_and_start_slave
change_master:
start_slave:
unlock_tables:在orig master上执行unlock table
Phase 5: New master cleanup phase
reset_slave_on_new_master
release_failover_advisory_lock

 如何在 iPhone 和 Android 上关闭蓝色警报Feb 29, 2024 pm 10:10 PM
如何在 iPhone 和 Android 上关闭蓝色警报Feb 29, 2024 pm 10:10 PM根据美国司法部的解释,蓝色警报旨在提供关于可能对执法人员构成直接和紧急威胁的个人的重要信息。这种警报的目的是及时通知公众,并让他们了解与这些罪犯相关的潜在危险。通过这种主动的方式,蓝色警报有助于增强社区的安全意识,促使人们采取必要的预防措施以保护自己和周围的人。这种警报系统的建立旨在提高对潜在威胁的警觉性,并加强执法机构与公众之间的沟通,以共尽管这些紧急通知对我们社会至关重要,但有时可能会对日常生活造成干扰,尤其是在午夜或重要活动时收到通知时。为了确保安全,我们建议您保持这些通知功能开启,但如果
 在Android中实现轮询的方法是什么?Sep 21, 2023 pm 08:33 PM
在Android中实现轮询的方法是什么?Sep 21, 2023 pm 08:33 PMAndroid中的轮询是一项关键技术,它允许应用程序定期从服务器或数据源检索和更新信息。通过实施轮询,开发人员可以确保实时数据同步并向用户提供最新的内容。它涉及定期向服务器或数据源发送请求并获取最新信息。Android提供了定时器、线程、后台服务等多种机制来高效地完成轮询。这使开发人员能够设计与远程数据源保持同步的响应式动态应用程序。本文探讨了如何在Android中实现轮询。它涵盖了实现此功能所涉及的关键注意事项和步骤。轮询定期检查更新并从服务器或源检索数据的过程在Android中称为轮询。通过
 如何在Android中实现按下返回键再次退出的功能?Aug 30, 2023 am 08:05 AM
如何在Android中实现按下返回键再次退出的功能?Aug 30, 2023 am 08:05 AM为了提升用户体验并防止数据或进度丢失,Android应用程序开发者必须避免意外退出。他们可以通过加入“再次按返回退出”功能来实现这一点,该功能要求用户在特定时间内连续按两次返回按钮才能退出应用程序。这种实现显著提升了用户参与度和满意度,确保他们不会意外丢失任何重要信息Thisguideexaminesthepracticalstepstoadd"PressBackAgaintoExit"capabilityinAndroid.Itpresentsasystematicguid
 Android逆向中smali复杂类实例分析May 12, 2023 pm 04:22 PM
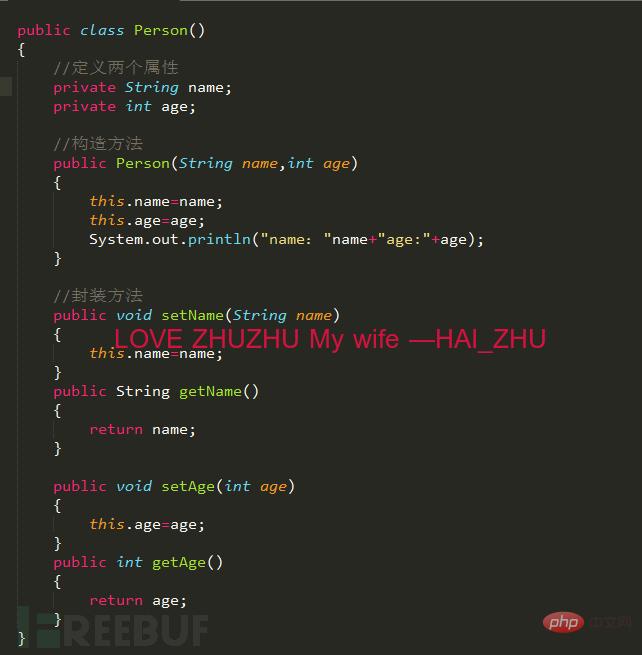
Android逆向中smali复杂类实例分析May 12, 2023 pm 04:22 PM1.java复杂类如果有什么地方不懂,请看:JAVA总纲或者构造方法这里贴代码,很简单没有难度。2.smali代码我们要把java代码转为smali代码,可以参考java转smali我们还是分模块来看。2.1第一个模块——信息模块这个模块就是基本信息,说明了类名等,知道就好对分析帮助不大。2.2第二个模块——构造方法我们来一句一句解析,如果有之前解析重复的地方就不再重复了。但是会提供链接。.methodpublicconstructor(Ljava/lang/String;I)V这一句话分为.m
 如何在2023年将 WhatsApp 从安卓迁移到 iPhone 15?Sep 22, 2023 pm 02:37 PM
如何在2023年将 WhatsApp 从安卓迁移到 iPhone 15?Sep 22, 2023 pm 02:37 PM如何将WhatsApp聊天从Android转移到iPhone?你已经拿到了新的iPhone15,并且你正在从Android跳跃?如果是这种情况,您可能还对将WhatsApp从Android转移到iPhone感到好奇。但是,老实说,这有点棘手,因为Android和iPhone的操作系统不兼容。但不要失去希望。这不是什么不可能完成的任务。让我们在本文中讨论几种将WhatsApp从Android转移到iPhone15的方法。因此,坚持到最后以彻底学习解决方案。如何在不删除数据的情况下将WhatsApp
 同样基于linux为什么安卓效率低Mar 15, 2023 pm 07:16 PM
同样基于linux为什么安卓效率低Mar 15, 2023 pm 07:16 PM原因:1、安卓系统上设置了一个JAVA虚拟机来支持Java应用程序的运行,而这种虚拟机对硬件的消耗是非常大的;2、手机生产厂商对安卓系统的定制与开发,增加了安卓系统的负担,拖慢其运行速度影响其流畅性;3、应用软件太臃肿,同质化严重,在一定程度上拖慢安卓手机的运行速度。
 Android中动态导出dex文件的方法是什么May 30, 2023 pm 04:52 PM
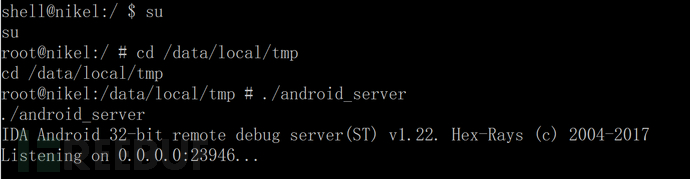
Android中动态导出dex文件的方法是什么May 30, 2023 pm 04:52 PM1.启动ida端口监听1.1启动Android_server服务1.2端口转发1.3软件进入调试模式2.ida下断2.1attach附加进程2.2断三项2.3选择进程2.4打开Modules搜索artPS:小知识Android4.4版本之前系统函数在libdvm.soAndroid5.0之后系统函数在libart.so2.5打开Openmemory()函数在libart.so中搜索Openmemory函数并且跟进去。PS:小知识一般来说,系统dex都会在这个函数中进行加载,但是会出现一个问题,后
 Android APP测试流程和常见问题是什么May 13, 2023 pm 09:58 PM
Android APP测试流程和常见问题是什么May 13, 2023 pm 09:58 PM1.自动化测试自动化测试主要包括几个部分,UI功能的自动化测试、接口的自动化测试、其他专项的自动化测试。1.1UI功能自动化测试UI功能的自动化测试,也就是大家常说的自动化测试,主要是基于UI界面进行的自动化测试,通过脚本实现UI功能的点击,替代人工进行自动化测试。这个测试的优势在于对高度重复的界面特性功能测试的测试人力进行有效的释放,利用脚本的执行,实现功能的快速高效回归。但这种测试的不足之处也是显而易见的,主要包括维护成本高,易发生误判,兼容性不足等。因为是基于界面操作,界面的稳定程度便成了


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SublimeText3 Linux new version
SublimeText3 Linux latest version

Notepad++7.3.1
Easy-to-use and free code editor

Atom editor mac version download
The most popular open source editor

WebStorm Mac version
Useful JavaScript development tools

ZendStudio 13.5.1 Mac
Powerful PHP integrated development environment

