



载自:http://lelong.iteye.com/blog/538645
在这篇文章中主要讲解php_curl库的知识,并教你如何更好的使用php_curl。
简介
你可能在你的编写PHP脚本代码中会遇到这样的问题:怎么样才能从其他站点获取内容呢?这里有几个解决方式;最简单的就是在php中使用fopen()函数,但是fopen函数没有足够的参数来使用,比如当你想构建一个“网络爬虫”,想定义爬虫的客户端描述(IE,firefox),通过不同的请求方式来获取内容,比如POST,GET;等等这些需求是不可能用fopen() 函数实现的。
为了解决我们上面提出的问题,我们可以使用PHP的扩展库-Curl,这个扩展库通常是默认在安装包中的,你可以它来获取其他站点的内容,也可以来干别的。
备注:这两段代码需要php_curl扩展库的支持,查看phpinfo(),如果curl support enabled则表示支持curl库。
1、Windows下的PHP开启curl库支持:
打开php.ini,将extension=php_curl.dll前的;号去掉。
2、Linux下的PHP开启curl库支持:
编译PHP时在./configure后加上 ?with-curl
在这篇文章中,我们一起来看看如何使用curl库,并看看它的其他用处,但是接下来,我们要从最基本的用法开始
基本用法:
第一步,我们通过函数curl_init()创建一个新的curl会话,代码如下:
// create a new curl resource
$ch = curl_init();
?>
我们已经成功创建了一个curl会话,如果需要获取一个URL的内容,那么接下的一步,传递一个URL给curl_setopt()函数,代码:
// set URL and other appropriate options
curl_setopt($ch, CURLOPT_URL, “http://www.google.com/”);
?>
做完上一步工作,curl的准备工作做完了,curl将会获取URL站点的内容,并打印出来。代码:
// grab URL and pass it to the browser
curl_exec($ch);
?>
最后,关闭当前的curl会话
//close curl resource, and free up system resources
curl_close($ch);
?>
下面我们来看看完成的实例代码:
// create a new curl resource
$ch = curl_init();
// set URL and other appropriate options
curl_setopt($ch, CURLOPT_URL, “http://www.google.nl/”);
// grab URL and pass it to the browser
curl_exec($ch);
// close curl resource, and free up system resources
curl_close($ch);
?>
(查看在线demo )
我们刚刚把另外一个站点的内容,获取过来以后自动输出到浏览器,我们有没有其他的方式组织获取的信息,然后控制其输出的内容呢?完全没有问题,在curl_setopt()函数的参数中,如果希望获得内容但不输出,使用CURLOPT_RETURNTRANSFER 参数,并设为非0值/true!,完整代码请看:
// create a new curl resource
$ch = curl_init();
// set URL and other appropriate options
curl_setopt($ch, CURLOPT_URL, “http://www.google.nl/”);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// grab URL, and return output
$output = curl_exec($ch);
// close curl resource, and free up system resources
curl_close($ch);
// Replace ‘Google’ with ‘PHPit’
$output = str_replace(’Google’, ‘PHPit’, $output);
// Print output
echo $output;
?>
(查看在线demo )
在上面的2个实例中,你可能注意到通过设置函数curl_setopt() 的不同参数,可以获得不同结果,这正是curl强大的原因,下面我们来看看这些参数的含义。
CURL的相关选项:
如果你看过php手册中的curl_setopt()函数,你可以注意到了,它下面长长的参数列表,我们不可能一一介绍,更多的内容请查看PHP手册,这里只介绍常用的和有的一些参数。
第一个很有意思的参数是 CURLOPT_FOLLOWLOCATION ,当你把这个参数设置为true时,curl会根据任何重定向命令更深层次的获取转向路径,举个例子:当你尝试获取一个PHP的页面,然后这个PHP的页面中有一段跳转代码 ,curl将从http://new_url获取内容,而不是返回跳转代码。完整的代码如下:
// create a new curl resource
$ch = curl_init();
// set URL and other appropriate options
curl_setopt($ch, CURLOPT_URL, “http://www.google.com/”);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
// grab URL, and print
curl_exec($ch);
?>
(查看在线demo ),
如果Google发送一个转向请求,上面的例子将根据跳转的网址继续获取内容,和这个参数有关的两个选项是CURLOPT_MAXREDIRS 和CURLOPT_AUTOREFERER .
参数CURLOPT_MAXREDIRS 选项允许你定义跳转请求的最大次数,超过了这个次数将不再获取其内容。如果CURLOPT_AUTOREFERER 设置为true时,curl会自动添加Referer header在每一个跳转链接,可能它不是很重要,但是在一定的案例中却非常的有用。
下一步介绍的参数是CURLOPT_POST ,这是一个非常有用的功能,因为它可以让您这样做POST请求,而不是GET请求,这实际上意味着你可以提交
其他形式的页面,无须其实在表单中填入。下面的例子表明我的意思:
// create a new curl resource
$ch = curl_init();
// set URL and other appropriate options
curl_setopt($ch, CURLOPT_URL,”http://projects/phpit/content/using%20curl%20php/demos/handle_form.php”);
// Do a POST
$data = array(’name’ => ‘Dennis’, ’surname’ => ‘Pallett’);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
// grab URL, and print
curl_exec($ch);
?>
(View Live Demo )
And the handle_form.php file:
echo ‘
Form variables I received:
’;echo ‘
’;<br>print_r ($_POST);<br>echo ‘’;
?>
正如你可以看到,这使得它真的很容易提交形式,这是一个伟大的方式来测试您的所有形式,而不以填补他们在所有的时间。
参数CURLOPT_CONNECTTIMEOUT 通常用来设置curl尝试请求链接的时间,这是一个非常重要的选项,如果你把这段时间设置的太短了,可能会导致curl请求失败。
但是如果你把它设置的时间太长了,可能PHP脚本将死掉。和这个参数相关的一个选项是 CURLOPT_TIMEOUT ,这是用来设置curl允许执行的时间需求。如果您设置这一个很小的值,它可能会导下载的网页上是不完整的,因为他们需要一段时间才能下载。
最后一个选项是 CURLOPT_USERAGENT,它允许你自定义请求是的客户端名称,比如webspilder或是IE6.0.示例代码如下:
// create a new curl resource
$ch = curl_init();
// set URL and other appropriate options
curl_setopt($ch, CURLOPT_URL, “http://www.useragent.org/”);
curl_setopt($ch, CURLOPT_USERAGENT, ‘My custom web spider/0.1′);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
// grab URL, and print
curl_exec($ch);
?>
(View Live Demo)
现在我们把最有意思的一个参数都介绍过了,下面我们来介绍一个curl_getinfo() 函数,看看它能为我们做些什么。
获取页面的信息:
函数curl_getinfo()可以使得我们获取接受页面各种信息,你能编辑这些信息通过设定选项的第二个参数,你也可以传递一个数组的形式。就像下面的例子:
// create a new curl resource
$ch = curl_init();
// set URL and other appropriate options
curl_setopt($ch, CURLOPT_URL, “http://www.google.com”);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FILETIME, true);
// grab URL
$output = curl_exec($ch);
// Print info
echo ‘
’;<br>print_r (curl_getinfo($ch));<br>echo ‘’;
?>
(View Live Demo )
大部分返回的信息是请求本身的,像:这个请求花的时间,返回的头文件信息,当然也有一些页面的信息,像页面内容的大小,最后修改的时间。
那些全是关于curl_getinfo()函数的,现在让我们看看它的实际用途。
实际用途:
curl库的第一用途可以查看一个URL页面是否存在,我们可以通过查看这个URL的请求返回的代码来判断比如404代表这个页面不存在,我们来看一些例子:
// create a new curl resource
$ch = curl_init();
// set URL and other appropriate options
curl_setopt($ch, CURLOPT_URL, “http://www.google.com/does/not/exist”);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// grab URL
$output = curl_exec($ch);
// Get response code
$response_code = curl_getinfo($ch, CURLINFO_HTTP_CODE);
// Not found?
if ($response_code == ‘404′) {
echo ‘Page doesn\’t exist’;
} else {
echo $output;
}
?>
(View Live Demo )
其他的用户可能是创建一个自动检查器,验证每个请求的页面是否存在。
我们可以用curl库来写和google类似的网页蜘蛛(web spider),或是其他的网页蜘蛛。这篇文章不是关于如何写一个网页蜘蛛的,因此所以我们没有讲任何关于网页蜘蛛的细节问题,但是以后在PHPit 将会介绍用 curl来构造一个web spider.
结论:
在这篇文章我已经表明,如何使用php中的curl库和其大部分的选项。
为最基本的任务,只想获得一个网页,你可能不会需要CURL库,但是,一旦你想要做任何事情稍微先进的,您可能会想要使用curl库。
在近未来,我会告诉您究竟如何建立自己的网络蜘蛛,类似Google的网络蜘蛛,敬请期待,以phpit。

 Working with Flash Session Data in LaravelMar 12, 2025 pm 05:08 PM
Working with Flash Session Data in LaravelMar 12, 2025 pm 05:08 PMLaravel simplifies handling temporary session data using its intuitive flash methods. This is perfect for displaying brief messages, alerts, or notifications within your application. Data persists only for the subsequent request by default: $request-
 cURL in PHP: How to Use the PHP cURL Extension in REST APIsMar 14, 2025 am 11:42 AM
cURL in PHP: How to Use the PHP cURL Extension in REST APIsMar 14, 2025 am 11:42 AMThe PHP Client URL (cURL) extension is a powerful tool for developers, enabling seamless interaction with remote servers and REST APIs. By leveraging libcurl, a well-respected multi-protocol file transfer library, PHP cURL facilitates efficient execution of various network protocols, including HTTP, HTTPS, and FTP. This extension offers granular control over HTTP requests, supports multiple concurrent operations, and provides built-in security features.
 Simplified HTTP Response Mocking in Laravel TestsMar 12, 2025 pm 05:09 PM
Simplified HTTP Response Mocking in Laravel TestsMar 12, 2025 pm 05:09 PMLaravel provides concise HTTP response simulation syntax, simplifying HTTP interaction testing. This approach significantly reduces code redundancy while making your test simulation more intuitive. The basic implementation provides a variety of response type shortcuts: use Illuminate\Support\Facades\Http; Http::fake([ 'google.com' => 'Hello World', 'github.com' => ['foo' => 'bar'], 'forge.laravel.com' =>
 12 Best PHP Chat Scripts on CodeCanyonMar 13, 2025 pm 12:08 PM
12 Best PHP Chat Scripts on CodeCanyonMar 13, 2025 pm 12:08 PMDo you want to provide real-time, instant solutions to your customers' most pressing problems? Live chat lets you have real-time conversations with customers and resolve their problems instantly. It allows you to provide faster service to your custom
 Explain the concept of late static binding in PHP.Mar 21, 2025 pm 01:33 PM
Explain the concept of late static binding in PHP.Mar 21, 2025 pm 01:33 PMArticle discusses late static binding (LSB) in PHP, introduced in PHP 5.3, allowing runtime resolution of static method calls for more flexible inheritance.Main issue: LSB vs. traditional polymorphism; LSB's practical applications and potential perfo
 PHP Logging: Best Practices for PHP Log AnalysisMar 10, 2025 pm 02:32 PM
PHP Logging: Best Practices for PHP Log AnalysisMar 10, 2025 pm 02:32 PMPHP logging is essential for monitoring and debugging web applications, as well as capturing critical events, errors, and runtime behavior. It provides valuable insights into system performance, helps identify issues, and supports faster troubleshoot
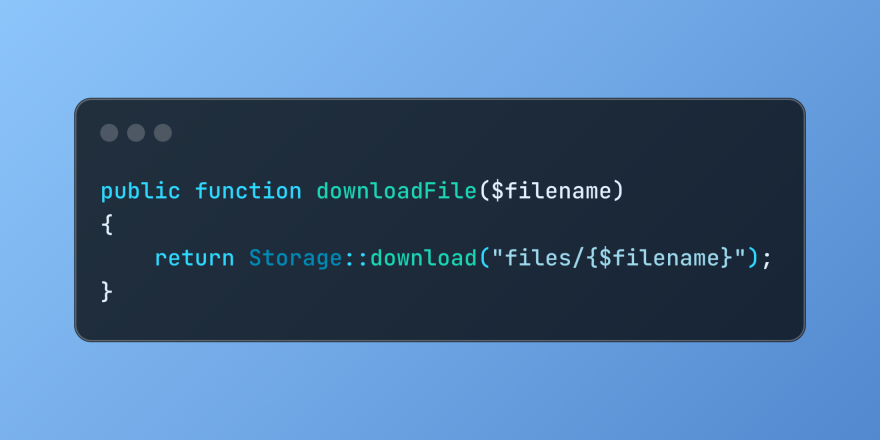 Discover File Downloads in Laravel with Storage::downloadMar 06, 2025 am 02:22 AM
Discover File Downloads in Laravel with Storage::downloadMar 06, 2025 am 02:22 AMThe Storage::download method of the Laravel framework provides a concise API for safely handling file downloads while managing abstractions of file storage. Here is an example of using Storage::download() in the example controller:
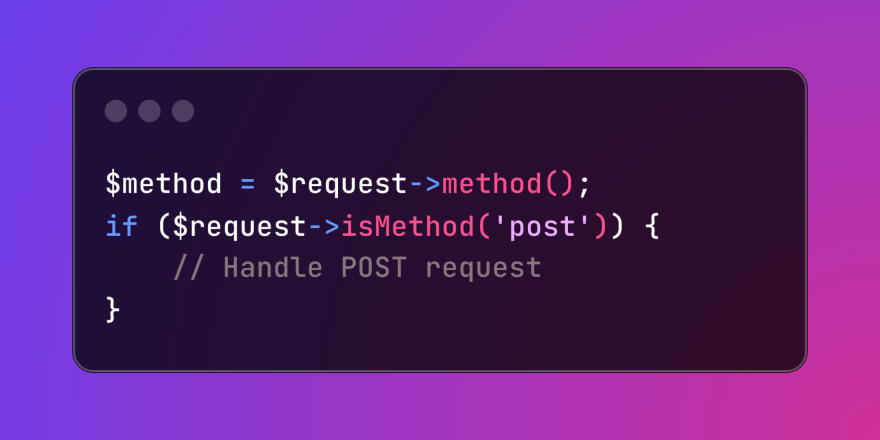 HTTP Method Verification in LaravelMar 05, 2025 pm 04:14 PM
HTTP Method Verification in LaravelMar 05, 2025 pm 04:14 PMLaravel simplifies HTTP verb handling in incoming requests, streamlining diverse operation management within your applications. The method() and isMethod() methods efficiently identify and validate request types. This feature is crucial for building


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

SublimeText3 Mac version
God-level code editing software (SublimeText3)

Zend Studio 13.0.1
Powerful PHP integrated development environment

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

