



在数据库里面
database
A
表有1张
a
里面数据为
firstname lastname
A a
这样表里面有百万级的数据。
于是问题就来了
/*前面的$name已经是我已经定义了的*/
$result= "SELECT lastname FROM a WHERE firstname='".$name."'";
$sql_name=mysql_query($result);
$name=mysql_fetch_array($sql_title);
$subject =$name[0];
?>
于是问题就来了
服务器一处理同时500个并发数据库就挂了。
有啥好办法解决吗?
回复讨论(解决方案)
很遗憾,这是你的硬件和操作系统不支持你那么高的并发。
仅从 php 角度是不能改变现状的
对于你的代码:
在 php 层面没有任何优化的余地
在 mysql 层面,也只是对 firstname 列做索引而已
很遗憾,这是你的硬件和操作系统不支持你那么高的并发。
仅从 php 角度是不能改变现状的
对于你的代码:
在 php 层面没有任何优化的余地
在 mysql 层面,也只是对 firstname 列做索引而已
其实还是可以的,从代码层次我发现了一个问题
$subject =$name[0];
这里只取了1行。
因此来说。$result= "SELECT lastname FROM a WHERE firstname='".$name."'";
可以修改为$result= "SELECT lastname FROM a WHERE firstname='".$name."' limit 0,1";
查询速度优化了不少。继续想办法,我相信肯定可以处理
$result= "SELECT lastname FROM a WHERE firstname='".$name."'";
和
$result= "SELECT lastname FROM a WHERE firstname='".$name."' limit 0,1";
意义是不同的!
前者表示可能取出多行
后者表示无论多少行都只取遇到的第一行
如果为了所谓的速度,连本意都扭曲了。那“优化”有什么意义?
通过横向或纵向分表,或者通过多数据库分压的方式。
我表示分库分表吧。。。
md5(firstname+lastname),散列到不同的数据库表中。
上面说的有问题,针对你的where语句猜测,分库分表的依赖应该是md5(firstname),不好意思
$result= "SELECT lastname FROM a WHERE firstname='".$name."'";
和
$result= "SELECT lastname FROM a WHERE firstname='".$name."' limit 0,1";
意义是不同的!
前者表示可能取出多行
后者表示无论多少行都只取遇到的第一行
如果为了所谓的速度,连本意都扭曲了。那“优化”有什么意义?
上面说的有问题,针对你的where语句猜测,分库分表的依赖应该是md5(firstname),不好意思
恩可能你还没明白。建立索引吧。然后分库分表
有个类似股票期货的高并发撮合系统,有人能做吗?
请联系我 13816210664

 Working with Flash Session Data in LaravelMar 12, 2025 pm 05:08 PM
Working with Flash Session Data in LaravelMar 12, 2025 pm 05:08 PMLaravel simplifies handling temporary session data using its intuitive flash methods. This is perfect for displaying brief messages, alerts, or notifications within your application. Data persists only for the subsequent request by default: $request-
 cURL in PHP: How to Use the PHP cURL Extension in REST APIsMar 14, 2025 am 11:42 AM
cURL in PHP: How to Use the PHP cURL Extension in REST APIsMar 14, 2025 am 11:42 AMThe PHP Client URL (cURL) extension is a powerful tool for developers, enabling seamless interaction with remote servers and REST APIs. By leveraging libcurl, a well-respected multi-protocol file transfer library, PHP cURL facilitates efficient execution of various network protocols, including HTTP, HTTPS, and FTP. This extension offers granular control over HTTP requests, supports multiple concurrent operations, and provides built-in security features.
 Simplified HTTP Response Mocking in Laravel TestsMar 12, 2025 pm 05:09 PM
Simplified HTTP Response Mocking in Laravel TestsMar 12, 2025 pm 05:09 PMLaravel provides concise HTTP response simulation syntax, simplifying HTTP interaction testing. This approach significantly reduces code redundancy while making your test simulation more intuitive. The basic implementation provides a variety of response type shortcuts: use Illuminate\Support\Facades\Http; Http::fake([ 'google.com' => 'Hello World', 'github.com' => ['foo' => 'bar'], 'forge.laravel.com' =>
 12 Best PHP Chat Scripts on CodeCanyonMar 13, 2025 pm 12:08 PM
12 Best PHP Chat Scripts on CodeCanyonMar 13, 2025 pm 12:08 PMDo you want to provide real-time, instant solutions to your customers' most pressing problems? Live chat lets you have real-time conversations with customers and resolve their problems instantly. It allows you to provide faster service to your custom
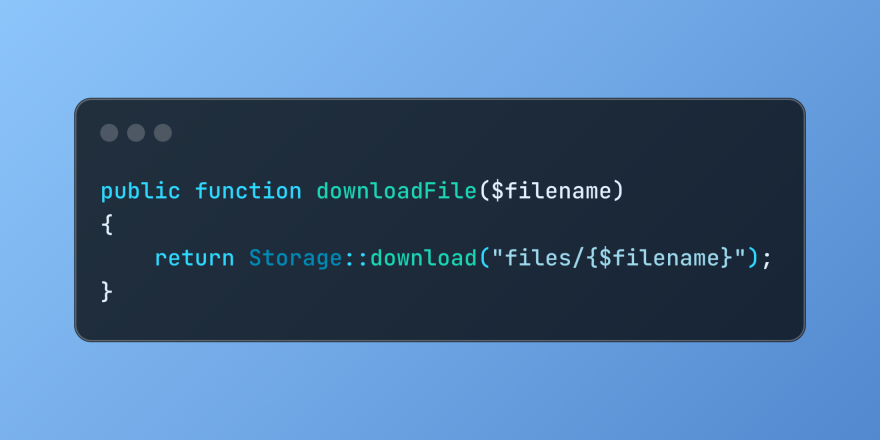 Discover File Downloads in Laravel with Storage::downloadMar 06, 2025 am 02:22 AM
Discover File Downloads in Laravel with Storage::downloadMar 06, 2025 am 02:22 AMThe Storage::download method of the Laravel framework provides a concise API for safely handling file downloads while managing abstractions of file storage. Here is an example of using Storage::download() in the example controller:
 Explain the concept of late static binding in PHP.Mar 21, 2025 pm 01:33 PM
Explain the concept of late static binding in PHP.Mar 21, 2025 pm 01:33 PMArticle discusses late static binding (LSB) in PHP, introduced in PHP 5.3, allowing runtime resolution of static method calls for more flexible inheritance.Main issue: LSB vs. traditional polymorphism; LSB's practical applications and potential perfo
 PHP Logging: Best Practices for PHP Log AnalysisMar 10, 2025 pm 02:32 PM
PHP Logging: Best Practices for PHP Log AnalysisMar 10, 2025 pm 02:32 PMPHP logging is essential for monitoring and debugging web applications, as well as capturing critical events, errors, and runtime behavior. It provides valuable insights into system performance, helps identify issues, and supports faster troubleshoot
 How to Register and Use Laravel Service ProvidersMar 07, 2025 am 01:18 AM
How to Register and Use Laravel Service ProvidersMar 07, 2025 am 01:18 AMLaravel's service container and service providers are fundamental to its architecture. This article explores service containers, details service provider creation, registration, and demonstrates practical usage with examples. We'll begin with an ove


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

SublimeText3 Linux new version
SublimeText3 Linux latest version

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

WebStorm Mac version
Useful JavaScript development tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

