



在本文中,以'哈'来解释作示例解释所有的问题,“哈”的各种编码如下:
1. UNICODE (UTF8-16),C854;
2. UTF-8,E59388;
3. GBK,B9FE。
一、python中的str和unicode
一直以来,python中的中文编码就是一个极为头大的问题,经常抛出编码转换的异常,python中的str和unicode到底是一个什么东西呢?
在python中提到unicode,一般指的是unicode对象,例如'哈哈'的unicode对象为
u'\u54c8\u54c8'
而str,是一个字节数组,这个字节数组表示的是对unicode对象编码(可以是utf-8、gbk、cp936、GB2312)后的存储的格式。这里它仅仅是一个字节流,没有其它的含义,如果你想使这个字节流显示的内容有意义,就必须用正确的编码格式,解码显示。
例如: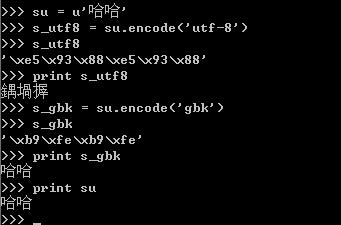
对于unicode对象哈哈进行编码,编码成一个utf-8编码的str-s_utf8,s_utf8就是是一个字节数组,存放的就是'\xe5\x93\x88\xe5\x93\x88',但是这仅仅是一个字节数组,如果你想将它通过print语句输出成哈哈,那你就失望了,为什么呢?
因为print语句它的实现是将要输出的内容传送了操作系统,操作系统会根据系统的编码对输入的字节流进行编码,这就解释了为什么utf-8格式的字符串“哈哈”,输出的是“鍝堝搱”,因为 '\xe5\x93\x88\xe5\x93\x88'用GB2312去解释,其显示的出来就是“鍝堝搱”。这里再强调一下,str记录的是字节数组,只是某种编码的存储格式,至于输出到文件或是打印出来是什么格式,完全取决于其解码的编码将它解码成什么样子。
这里再对print进行一点补充说明:当将一个unicode对象传给print时,在内部会将该unicode对象进行一次转换,转换成本地的默认编码(这仅是个人猜测)
二、str和unicode对象的转换
str和unicode对象的转换,通过encode和decode实现,具体使用如下:
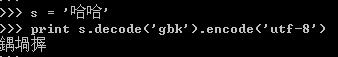
将GBK'哈哈'转换成unicode,然后再转换成UTF8
三、Setdefaultencoding
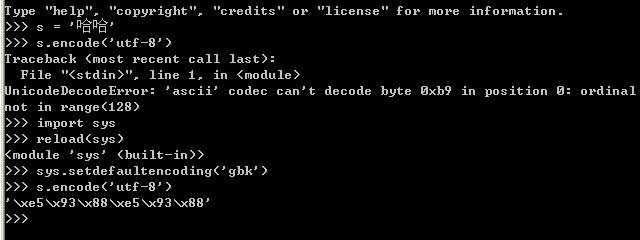
如上图的演示代码所示:
当把s(gbk字符串)直接编码成utf-8的时候,将抛出异常,但是通过调用如下代码:
import sys
reload(sys)
sys.setdefaultencoding('gbk')
后就可以转换成功,为什么呢?在python中str和unicode在编码和解码过程中,如果将一个str直接编码成另一种编码,会先把str解码成unicode,采用的编码为默认编码,一般默认编码是anscii,所以在上面示例代码中第一次转换的时候会出错,当设定当前默认编码为'gbk'后,就不会出错了。
至于reload(sys)是因为Python2.5 初始化后会删除 sys.setdefaultencoding 这个方法,我们需要重新载入。
四、操作不同文件的编码格式的文件
建立一个文件test.txt,文件格式用ANSI,内容为:
abc中文
用python来读取
# coding=gbk
print open("Test.txt").read()
结果:abc中文
把文件格式改成UTF-8:
结果:abc涓枃
显然,这里需要解码:
# coding=gbk
import codecs
print open("Test.txt").read().decode("utf-8")
结果:abc中文
上面的test.txt我是用Editplus来编辑的,但当我用Windows自带的记事本编辑并存成UTF-8格式时,
运行时报错:
Traceback (most recent call last):
File "ChineseTest.py", line 3, in
print open("Test.txt").read().decode("utf-8")
UnicodeEncodeError: 'gbk' codec can't encode character u'\ufeff' in position 0: illegal multibyte sequence
原来,某些软件,如notepad,在保存一个以UTF-8编码的文件时,会在文件开始的地方插入三个不可见的字符(0xEF 0xBB 0xBF,即BOM)。
因此我们在读取时需要自己去掉这些字符,python中的codecs module定义了这个常量:
# coding=gbk
import codecs
data = open("Test.txt").read()
if data[:3] == codecs.BOM_UTF8:
data = data[3:]
print data.decode("utf-8")
结果:abc中文
五、文件的编码格式和编码声明的作用
源文件的编码格式对字符串的声明有什么作用呢?这个问题困扰一直困扰了我好久,现在终于有点眉目了,文件的编码格式决定了在该源文件中声明的字符串的编码格式,例如:
str = '哈哈'
print repr(str)
a.如果文件格式为utf-8,则str的值为:'\xe5\x93\x88\xe5\x93\x88'(哈哈的utf-8编码)
b.如果文件格式为gbk,则str的值为:'\xb9\xfe\xb9\xfe'(哈哈的gbk编码)
在第一节已经说过,python中的字符串,只是一个字节数组,所以当把a情况的str输出到gbk编码的控制台时,就将显示为乱码:鍝堝搱;而当把b情况下的str输出utf-8编码的控制台时,也将显示乱码的问题,是什么也没有,也许'\xb9\xfe\xb9\xfe'用utf-8解码显示,就是空白吧。>_
说完文件格式,现在来谈谈编码声明的作用吧,每个文件在最上面的地方,都会用# coding=gbk 类似的语句声明一下编码,但是这个声明到底有什么用呢?到止前为止,我觉得它的作用也就是三个:
#coding:gbk
ss = u'哈哈'
print repr(ss)
print 'ss:%s' % ss
将这个些代码保存成一个utf-8文本,运行,你认为会输出什么呢?大家第一感觉肯定输出的肯定是:
u'\u54c8\u54c8'
ss:哈哈
但是实际上输出是:
u'\u935d\u581d\u6431'
ss:鍝堝搱
为什么会这样,这时候,就是编码声明在作怪了,在运行ss = u'哈哈'的时候,整个过程可以分为以下几步:
1) 获取'哈哈'的编码:由文件编码格式确定,为'\xe5\x93\x88\xe5\x93\x88'(哈哈的utf-8编码形式)
2) 转成 unicode编码的时候,在这个转换的过程中,对于'\xe5\x93\x88\xe5\x93\x88'的解码,不是用utf-8解码,而是用声明编码处指定的编码GBK,将'\xe5\x93\x88\xe5\x93\x88'按GBK解码,得到就是''鍝堝搱'',这三个字的unicode编码就是u'\u935d\u581d\u6431',至止可以解释为什么print repr(ss)输出的是u'\u935d\u581d\u6431' 了。
好了,这里有点绕,我们来分析下一个示例:
#-*- coding:utf-8 -*-
ss = u'哈哈'
print repr(ss)
print 'ss:%s' % ss
将这个示例这次保存成GBK编码形式,运行结果,竟然是:
UnicodeDecodeError: 'utf8' codec can't decode byte 0xb9 in position 0: unexpected code byte
这里为什么会有utf8解码错误呢?想想上个示例也明白了,转换第一步,因为文件编码是GBK,得到的是'哈哈'编码是GBK的编码'\xb9\xfe\xb9\xfe',当进行第二步,转换成 unicode的时候,会用UTF8对'\xb9\xfe\xb9\xfe'进行解码,而大家查utf-8的编码表会发现,utf8编码表(关于UTF- 8解释可参见字符编码笔记:ASCII、UTF-8、UNICODE)中根本不存在,所以会报上述错误。

 What are the alternatives to concatenate two lists in Python?May 09, 2025 am 12:16 AM
What are the alternatives to concatenate two lists in Python?May 09, 2025 am 12:16 AMThere are many methods to connect two lists in Python: 1. Use operators, which are simple but inefficient in large lists; 2. Use extend method, which is efficient but will modify the original list; 3. Use the = operator, which is both efficient and readable; 4. Use itertools.chain function, which is memory efficient but requires additional import; 5. Use list parsing, which is elegant but may be too complex. The selection method should be based on the code context and requirements.
 Python: Efficient Ways to Merge Two ListsMay 09, 2025 am 12:15 AM
Python: Efficient Ways to Merge Two ListsMay 09, 2025 am 12:15 AMThere are many ways to merge Python lists: 1. Use operators, which are simple but not memory efficient for large lists; 2. Use extend method, which is efficient but will modify the original list; 3. Use itertools.chain, which is suitable for large data sets; 4. Use * operator, merge small to medium-sized lists in one line of code; 5. Use numpy.concatenate, which is suitable for large data sets and scenarios with high performance requirements; 6. Use append method, which is suitable for small lists but is inefficient. When selecting a method, you need to consider the list size and application scenarios.
 Compiled vs Interpreted Languages: pros and consMay 09, 2025 am 12:06 AM
Compiled vs Interpreted Languages: pros and consMay 09, 2025 am 12:06 AMCompiledlanguagesofferspeedandsecurity,whileinterpretedlanguagesprovideeaseofuseandportability.1)CompiledlanguageslikeC arefasterandsecurebuthavelongerdevelopmentcyclesandplatformdependency.2)InterpretedlanguageslikePythonareeasiertouseandmoreportab
 Python: For and While Loops, the most complete guideMay 09, 2025 am 12:05 AM
Python: For and While Loops, the most complete guideMay 09, 2025 am 12:05 AMIn Python, a for loop is used to traverse iterable objects, and a while loop is used to perform operations repeatedly when the condition is satisfied. 1) For loop example: traverse the list and print the elements. 2) While loop example: guess the number game until you guess it right. Mastering cycle principles and optimization techniques can improve code efficiency and reliability.
 Python concatenate lists into a stringMay 09, 2025 am 12:02 AM
Python concatenate lists into a stringMay 09, 2025 am 12:02 AMTo concatenate a list into a string, using the join() method in Python is the best choice. 1) Use the join() method to concatenate the list elements into a string, such as ''.join(my_list). 2) For a list containing numbers, convert map(str, numbers) into a string before concatenating. 3) You can use generator expressions for complex formatting, such as ','.join(f'({fruit})'forfruitinfruits). 4) When processing mixed data types, use map(str, mixed_list) to ensure that all elements can be converted into strings. 5) For large lists, use ''.join(large_li
 Python's Hybrid Approach: Compilation and Interpretation CombinedMay 08, 2025 am 12:16 AM
Python's Hybrid Approach: Compilation and Interpretation CombinedMay 08, 2025 am 12:16 AMPythonusesahybridapproach,combiningcompilationtobytecodeandinterpretation.1)Codeiscompiledtoplatform-independentbytecode.2)BytecodeisinterpretedbythePythonVirtualMachine,enhancingefficiencyandportability.
 Learn the Differences Between Python's 'for' and 'while' LoopsMay 08, 2025 am 12:11 AM
Learn the Differences Between Python's 'for' and 'while' LoopsMay 08, 2025 am 12:11 AMThekeydifferencesbetweenPython's"for"and"while"loopsare:1)"For"loopsareidealforiteratingoversequencesorknowniterations,while2)"while"loopsarebetterforcontinuinguntilaconditionismetwithoutpredefinediterations.Un
 Python concatenate lists with duplicatesMay 08, 2025 am 12:09 AM
Python concatenate lists with duplicatesMay 08, 2025 am 12:09 AMIn Python, you can connect lists and manage duplicate elements through a variety of methods: 1) Use operators or extend() to retain all duplicate elements; 2) Convert to sets and then return to lists to remove all duplicate elements, but the original order will be lost; 3) Use loops or list comprehensions to combine sets to remove duplicate elements and maintain the original order.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

SublimeText3 Linux new version
SublimeText3 Linux latest version

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 English version
Recommended: Win version, supports code prompts!

Dreamweaver Mac version
Visual web development tools

