
Home >Backend Development >Python Tutorial >用python + hadoop streaming 分布式编程(一) -- 原理介绍,样例程序与本地调试
用python + hadoop streaming 分布式编程(一) -- 原理介绍,样例程序与本地调试

- WBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOYWBOriginal
- 2016-06-16 08:43:141201browse
MapReduce与HDFS简介
什么是Hadoop?
Google为自己的业务需要提出了编程模型MapReduce和分布式文件系统Google File System,并发布了相关论文(可在Google Research的网站上获得: GFS 、 MapReduce)。 Doug Cutting和Mike Cafarella在开发搜索引擎Nutch时对这两篇论文做了自己的实现,即同名的MapReduce和HDFS,合起来就是Hadoop。
MapReduce的Data flow如下图,原始数据经过mapper处理,再进行partition和sort,到达reducer,输出最后结果。
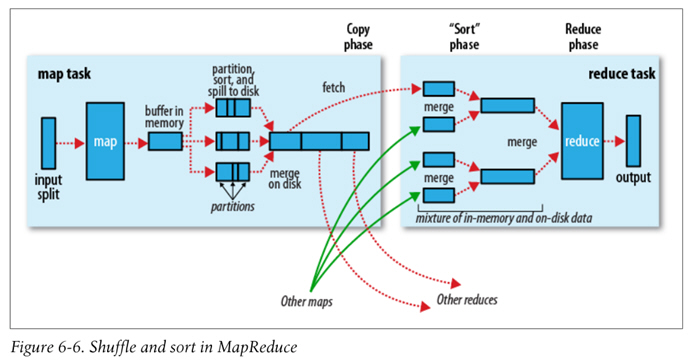
图片来自Hadoop: The Definitive Guide
Hadoop Streaming原理
Hadoop本身是用Java开发的,程序也需要用Java编写,但是通过Hadoop Streaming,我们可以使用任意语言来编写程序,让Hadoop运行。
Hadoop Streaming的相关源代码可以在Hadoop的Github repo 查看。简单来说,就是通过将用其他语言编写的mapper和reducer通过参数传给一个事先写好的Java程序(Hadoop自带的*-streaming.jar),这个Java程序会负责创建MR作业,另开一个进程来运行mapper,将得到的输入通过stdin传给它,再将mapper处理后输出到stdout的数据交给Hadoop,partition和sort之后,再另开进程运行reducer,同样地通过stdin/stdout得到最终结果。因此,我们只需要在其他语言编写的程序里,通过stdin接收数据,再将处理过的数据输出到stdout,Hadoop streaming就能通过这个Java的wrapper帮我们解决中间繁琐的步骤,运行分布式程序。
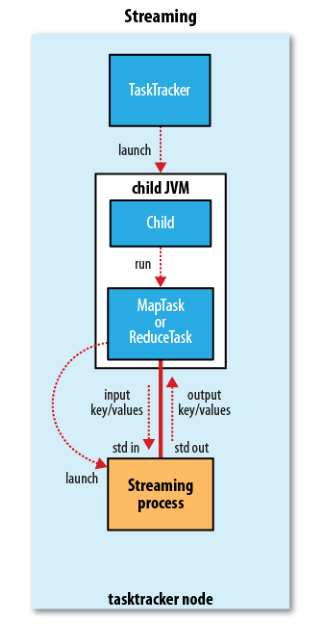
图片来自Hadoop: The Definitive Guide
原理上只要是能够处理stdio的语言都能用来写mapper和reducer,也可以指定mapper或reducer为Linux下的程序(如awk、grep、cat)或者按照一定格式写好的java class。因此,mapper和reducer也不必是同一类的程序。
Hadoop Streaming的优缺点
优点
可以使用自己喜欢的语言来编写MapReduce程序(换句话说,不必写Java XD)
不需要像写Java的MR程序那样import一大堆库,在代码里做一大堆配置,很多东西都抽象到了stdio上,代码量显著减少
因为没有库的依赖,调试方便,并且可以脱离Hadoop先在本地用管道模拟调试
缺点
只能通过命令行参数来控制MapReduce框架,不像Java的程序那样可以在代码里使用API,控制力比较弱,有些东西鞭长莫及
因为中间隔着一层处理,效率会比较慢
所以Hadoop Streaming比较适合做一些简单的任务,比如用python写只有一两百行的脚本。如果项目比较复杂,或者需要进行比较细致的优化,使用Streaming就容易出现一些束手束脚的地方。
用python编写简单的Hadoop Streaming程序
这里提供两个例子:
Michael Noll的word count程序
Hadoop: The Definitive Guide里的例程
使用python编写Hadoop Streaming程序有几点需要注意:
在能使用iterator的情况下,尽量使用iterator,避免将stdin的输入大量储存在内存里,否则会严重降低性能
streaming不会帮你分割key和value传进来,传进来的只是一个个字符串而已,需要你自己在代码里手动调用split()
从stdin得到的每一行数据末尾似乎会有\n,保险起见一般都需要使用rstrip()来去掉
在想获得K-V list而不是一个个处理key-value pair时,可以使用groupby配合itemgetter将key相同的k-v pair组成一个个group,得到类似Java编写的reduce可以直接获取一个Text类型的key和一个iterable作为value的效果。注意itemgetter的效率比lambda表达式要高,所以如果需求不是很复杂的话,尽量用itemgetter比较好。
我在编写Hadoop Streaming程序时的基本模版是
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
Some description here...
"""
import sys
from operator import itemgetter
from itertools import groupby
def read_input(file):
"""Read input and split."""
for line in file:
yield line.rstrip().split('\t')
def main():
data = read_input(sys.stdin)
for key, kviter in groupby(data, itemgetter(0)):
# some code here..
if __name__ == "__main__":
main()
如果对输入输出格式有不同于默认的控制,主要会在read_input()里调整。
本地调试
本地调试用于Hadoop Streaming的python程序的基本模式是:
$ cat <input path> | python <path to mapper script> | sort -t $'\t' -k1,1 | python <path to reducer script> > <output path>
或者如果不想用多余的cat,也可以用
$ python <path to mapper script> < <input path> | sort -t $'\t' -k1,1 | python <path to reducer script> > <output path>
这里有几点需要注意:
Hadoop默认按照tab来分割key和value,以第一个分割出的部分为key,按key进行排序,因此这里使用
sort -t $'\t' -k1,1
来模拟。如果你有其他需求,在交给Hadoop Streaming执行时可以通过命令行参数调,本地调试也可以进行相应的调整,主要是调整sort的参数。因此为了能够熟练进行本地调试,建议先掌握sort命令的用法。
如果你在python脚本里加上了shebang,并且为它们添加了执行权限,也可以用类似于
./mapper.py
来代替
python mapper.py