
 Web Front-endJS TutorialXML processing function js code compatible with IE, FireFox, Chrome and other browsers_javascript skills
Web Front-endJS TutorialXML processing function js code compatible with IE, FireFox, Chrome and other browsers_javascript skills
When writing web pages that process xml, browser compatibility is often a headache. So I encapsulated common xml operations into functions. After a period of improvement, it is now very stable and comfortable to use.
Functions include——
xml_loadFile: xml synchronous/asynchronous loading.
xml_transformNode: xsl transformation.
xml_text: The text of the node.
selectSingleNode: Select a single node based on XPath.
selectNodes: Select multiple nodes based on XPath.
Full code (zyllibjs_xml.js) -
/*
zyllibjs_xml
XML processing
@author zyl910
Note——
1. Chrome cannot read local files due to its security mechanism restrictions.
Reference
~~~~~~~~~
http://www.jinlie.net/?p=302
Chrome browser loads XML document
Update
~ ~~~~~
[2011-11-02]
Definition.
[2011-11-09]
xml_loadFile: Add isError parameter to the callback function.
[2011-11-21]
selectSingleNode
selectNodes
*/
// Load XML file and return XML document node
// return: Return an object on success (synchronous The XML document object is returned in mode, the operation object is returned in asynchronous mode), and null is returned in case of failure.
// xmlUrl: url of xml file.
// funcAsync: callback function. function onload(xmlDoc, isError){ ... }
function xml_loadFile(xmlUrl, funcAsync)
{
var xmlDoc = null;
var isChrome = false;
var asyncIs = (null!=funcAsync); // Whether it is asynchronous loading. When funcAsync is not empty, asynchronous loading is used, otherwise synchronous loading is used.
// Check parameters
if (""==xmlUrl) return null;
if (asyncIs)
{
if ("function"!=typeof(funcAsync)) return null;
}
// Create XML object
try
{
xmlDoc = new ActiveXObject("Microsoft.XMLDOM"); // Support IE
}
catch(ex)
{
}
if (null==xmlDoc)
{
try
{
// Support Firefox, Mozilla, Opera, etc
xmlDoc = document. implementation.createDocument("", "", null); // Create an empty XML document object.
}
catch(ex)
{
}
}
if (null==xmlDoc) return null;
// Load XML document
xmlDoc.async = asyncIs;
if (asyncIs)
{
if(window.ActiveXObject)
{
xmlDoc.onreadystatechange = function(){
if(xmlDoc.readyState == 4)
{
var isError = false;
if (null!=xmlDoc.parseError)
{
isError = (0!=xmlDoc.parseError.errorCode); // 0 successful, not 0 failed.
}
funcAsync(xmlDoc, isError);
}
}
}
else
{
xmlDoc.onload = function(){
funcAsync( xmlDoc, false);
}
}
}
try
{
xmlDoc.load(xmlUrl);
}
catch(ex)
{
// alert(ex.message) // If the browser is Chrome, this exception will be caught: Object # (a Document) has no method "load"
isChrome = true;
xmlDoc = null ;
}
if (isChrome)
{
var xhr = new XMLHttpRequest();
if (asyncIs) // Asynchronous
{
xhr.onreadystatechange = function( ){
if(xhr.readyState == 4)
{
funcAsync(xhr.responseXML, xhr.status != 200);
}
}
xhr.open( "GET", xmlUrl, true);
try // In asynchronous mode, the callback function handles errors.
{
xhr.send(null);
}
catch(ex)
{
funcAsync(null, true);
return null;
}
return xhr; // Note: What is returned is XMLHttpRequest. It is recommended to only use null to test the return value in asynchronous mode.
}
else // Synchronous
{
xhr.open("GET", xmlUrl, false);
xhr.send(null); // In synchronous mode, by the caller Handling exceptions
xmlDoc = xhr.responseXML;
}
}
return xmlDoc;
}
// Use XSLT to convert the XML document into a string.
function xml_transformNode(xmlDoc, xslDoc)
{
if (null==xmlDoc) return "";
if (null==xslDoc) return "";
if (window.ActiveXObject ) // IE
{
return xmlDoc.transformNode(xslDoc);
}
else // FireFox, Chrome
{
//Define XSLTProcesor object
var xsltProcessor= new XSLTProcessor();
xsltProcessor.importStylesheet(xslDoc);
// transformToDocument method
var result=xsltProcessor.transformToDocument(xmlDoc);
var xmls=new XMLSerializer();
var rt = xmls.serializeToString(result);
return rt;
}
}
// Get the text of the node
function xml_text(xmlNode)
{
if (null ==xmlNode) return "";
var rt;
if (window.ActiveXObject) // IE
{
rt = xmlNode.text;
}
else
{
// FireFox, Chrome, ...
rt = xmlNode.textContent;
}
if (null==rt) rt=xmlNode.nodeValue; // XML DOM
return rt;
}
// Add method. In order to be compatible with FireFox and Chrome.
if (!window.ActiveXObject)
{
XMLDocument.prototype.selectSingleNode = Element.prototype.selectSingleNode = function (xpath)
{
var x = this.selectNodes(xpath)
if ( ! x ||
{
var xpe = new XPathEvaluator();
var nsResolver = xpe.createNSResolver( this.ownerDocument == null?this.documentElement : this.ownerDocument.documentElement);
var result = xpe .evaluate(xpath, this , nsResolver, 0 , null );
var found = [];
var res;
while (res = result.iterateNext())
found.push(res );
return found;
}
}
Chrome browser loads XML document
Chrome browser does not support the load method to load XML document. After searching online, I need the following solution:
function loadXMLDoc( xml_name)
{
var xmlDoc;
try
{
xmlDoc = new ActiveXObject("Microsoft.XMLDOM"); // Support IE
}
catch(e)
{
try
{
// Support Firefox, Mozilla, Opera, etc
xmlDoc = document.implementation.createDocument("", "", null) ;// Create an empty XML document object.
}
catch(e)
{
alert(e.message);
}
}
// Load XML document
try
{
xmlDoc.async = false; // Turn off asynchronous loading
xmlDoc.load(xml_name);
}
catch(e)
{
// alert(e.message) if If the browser is Chrome, it will catch this exception: Object # (a Document) has no method "load", so the following implementation supports chrome loading XML documents (just roughly written)
var xhr = new XMLHttpRequest() ;
xhr.open("GET", xml_name, false);
xhr.send(null);
xmlDoc = xhr.responseXML.documentElement;
}
return xmlDoc;
}
BTW, each browser loads the XML string differently.
IE uses the loadXML() method to parse XML strings:
FireFox and others use the DOMParser object to parse XML strings:
var parseXml = new DOMParser();
var doc = parseXml.parseFromString(xml_str,"text/xml");

 如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM
如何用PHP和XML实现网站的分页和导航Jul 28, 2023 pm 12:31 PM如何用PHP和XML实现网站的分页和导航导言:在开发一个网站时,分页和导航功能是很常见的需求。本文将介绍如何使用PHP和XML来实现网站的分页和导航功能。我们会先讨论分页的实现,然后再介绍导航的实现。一、分页的实现准备工作在开始实现分页之前,需要准备一个XML文件,用来存储网站的内容。XML文件的结构如下:<articles><art
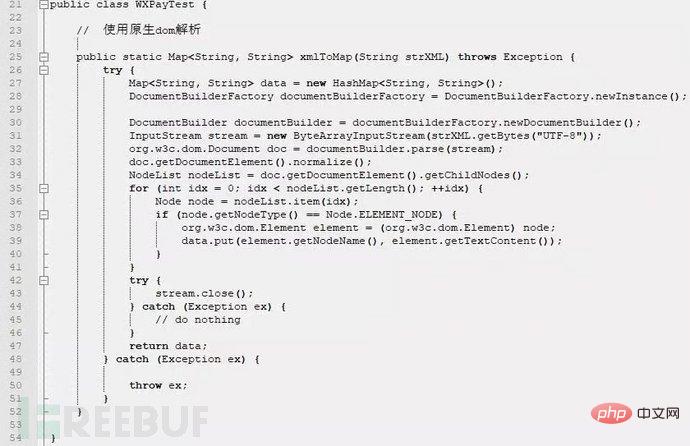 XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM
XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM一、XML外部实体注入XML外部实体注入漏洞也就是我们常说的XXE漏洞。XML作为一种使用较为广泛的数据传输格式,很多应用程序都包含有处理xml数据的代码,默认情况下,许多过时的或配置不当的XML处理器都会对外部实体进行引用。如果攻击者可以上传XML文档或者在XML文档中添加恶意内容,通过易受攻击的代码、依赖项或集成,就能够攻击包含缺陷的XML处理器。XXE漏洞的出现和开发语言无关,只要是应用程序中对xml数据做了解析,而这些数据又受用户控制,那么应用程序都可能受到XXE攻击。本篇文章以java
 php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM
php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM当我们处理数据时经常会遇到将XML格式转换为JSON格式的需求。PHP有许多内置函数可以帮助我们执行这个操作。在本文中,我们将讨论将XML格式转换为JSON格式的不同方法。
 Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PM
Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PMPythonxmltodict对xml的操作xmltodict是另一个简易的库,它致力于将XML变得像JSON.下面是一个简单的示例XML文件:elementsmoreelementselementaswell这是第三方包,在处理前先用pip来安装pipinstallxmltodict可以像下面这样访问里面的元素,属性及值:importxmltodictwithopen("test.xml")asfd:#将XML文件装载到dict里面doc=xmltodict.parse(f
 使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM
使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM使用nmap-converter将nmap扫描结果XML转化为XLS实战1、前言作为网络安全从业人员,有时候需要使用端口扫描利器nmap进行大批量端口扫描,但Nmap的输出结果为.nmap、.xml和.gnmap三种格式,还有夹杂很多不需要的信息,处理起来十分不方便,而将输出结果转换为Excel表格,方面处理后期输出。因此,有技术大牛分享了将nmap报告转换为XLS的Python脚本。2、nmap-converter1)项目地址:https://github.com/mrschyte/nmap-
 xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PM
xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PMxml中node和element的区别是:Element是元素,是一个小范围的定义,是数据的组成部分之一,必须是包含完整信息的结点才是元素;而Node是节点,是相对于TREE数据结构而言的,一个结点不一定是一个元素,一个元素一定是一个结点。
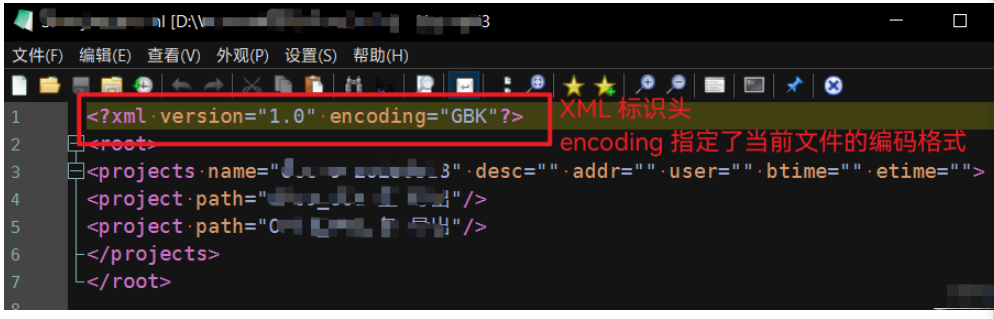 Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM
Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM1.在Python中XML文件的编码问题1.Python使用的xml.etree.ElementTree库只支持解析和生成标准的UTF-8格式的编码2.常见GBK或GB2312等中文编码的XML文件,用以在老旧系统中保证XML对中文字符的记录能力3.XML文件开头有标识头,标识头指定了程序处理XML时应该使用的编码4.要修改编码,不仅要修改文件整体的编码,还要将标识头中encoding部分的值修改2.处理PythonXML文件的思路1.读取&解码:使用二进制模式读取XML文件,将文件变为
 深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PM
深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PMScrapy是一款强大的Python爬虫框架,可以帮助我们快速、灵活地获取互联网上的数据。在实际爬取过程中,我们会经常遇到HTML、XML、JSON等各种数据格式。在这篇文章中,我们将介绍如何使用Scrapy分别爬取这三种数据格式的方法。一、爬取HTML数据创建Scrapy项目首先,我们需要创建一个Scrapy项目。打开命令行,输入以下命令:scrapys


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

SublimeText3 Chinese version
Chinese version, very easy to use

SublimeText3 Linux new version
SublimeText3 Linux latest version

Notepad++7.3.1
Easy-to-use and free code editor

Dreamweaver CS6
Visual web development tools

