


Exploring the Efficiency of 1.58-bit Quantized LLMs
Large Language Models (LLMs) are rapidly increasing in size and complexity, leading to escalating computational costs and energy consumption. Quantization, a technique to reduce the precision of model parameters, offers a promising solution. This article delves into BitNet, a novel approach that fine-tunes LLMs to an unprecedented 1.58 bits, achieving remarkable efficiency gains.

The Challenge of Quantization
Traditional LLMs utilize 16-bit (FP16) or 32-bit (FP32) floating-point precision. Quantization reduces this precision to lower-bit formats (e.g., 8-bit, 4-bit), resulting in memory savings and faster computation. However, this often comes at the expense of accuracy. The key challenge lies in minimizing the performance trade-off inherent in extreme precision reduction.
BitNet: A Novel Approach
BitNet introduces a 1.58-bit LLM architecture where each parameter is represented using ternary values {-1, 0, 1}. This innovative approach leverages the BitLinear layer, replacing traditional linear layers in the model's Multi-Head Attention and Feed-Forward Networks. To overcome the non-differentiability of ternary weights, BitNet employs the Straight-Through Estimator (STE).

Straight-Through Estimator (STE)
STE is a crucial component of BitNet. It allows gradients to propagate through the non-differentiable quantization process during backpropagation, enabling effective model training despite the use of discrete weights.

Fine-tuning from Pre-trained Models
While BitNet demonstrates impressive results when training from scratch, the resource requirements for pre-training are substantial. This article explores the feasibility of fine-tuning existing pre-trained models (e.g., Llama3 8B) to 1.58 bits. This approach faces challenges, as quantization can lead to information loss. The authors address this by employing dynamic lambda scheduling and exploring alternative quantization methods (per-row, per-column, per-group).
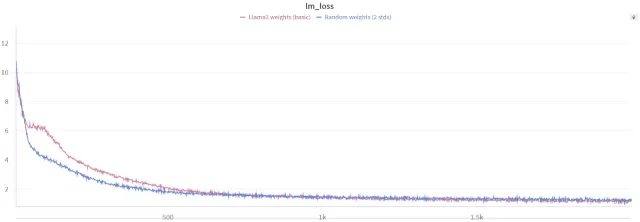
Optimization Strategies
The research highlights the importance of careful optimization during fine-tuning. Dynamic lambda scheduling, which gradually introduces quantization during training, proves crucial in mitigating information loss and improving convergence. Experiments with different lambda scheduling functions (linear, exponential, sigmoid) are conducted to find the optimal approach.
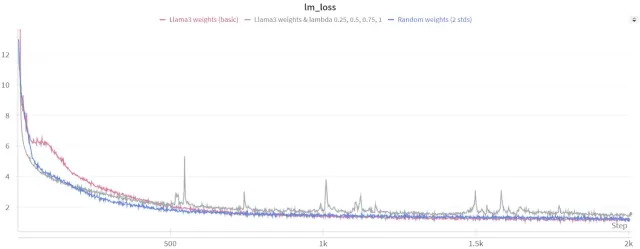
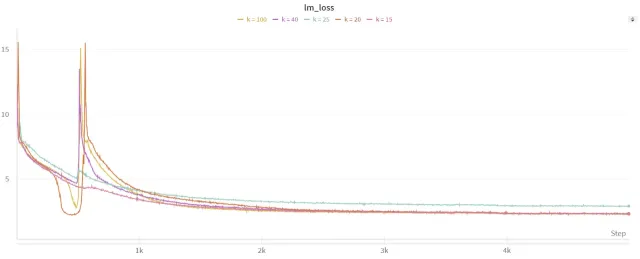
Experimental Results and Analysis
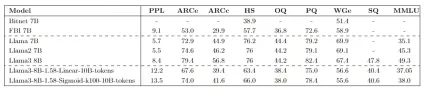
The study presents comprehensive experimental results, comparing the performance of fine-tuned 1.58-bit models against various baselines. The results demonstrate that while some performance gaps remain compared to full-precision models, the efficiency gains are substantial. The impact of model size and the choice of datasets are also analyzed.
Hugging Face Integration
The fine-tuned models are made accessible through Hugging Face, enabling easy integration into various applications. The article provides code examples demonstrating how to load and utilize these models.
Conclusion
BitNet represents a significant advancement in LLM efficiency. While fine-tuning to 1.58 bits presents challenges, the research demonstrates the potential to achieve comparable performance to higher-precision models with drastically reduced computational costs and energy consumption. This opens exciting possibilities for deploying large-scale LLMs on resource-constrained devices and reducing the environmental impact of AI.
(Note: The images are referenced but not included in this output as they were not provided in a format that could be directly incorporated.)
The above is the detailed content of How to Fine-tune LLMs to 1.58 bits? - Analytics Vidhya. For more information, please follow other related articles on the PHP Chinese website!

 How to Build an Intelligent FAQ Chatbot Using Agentic RAGMay 07, 2025 am 11:28 AM
How to Build an Intelligent FAQ Chatbot Using Agentic RAGMay 07, 2025 am 11:28 AMAI agents are now a part of enterprises big and small. From filling forms at hospitals and checking legal documents to analyzing video footage and handling customer support – we have AI agents for all kinds of tasks. Compan
 From Panic To Power: What Leaders Must Learn In The AI AgeMay 07, 2025 am 11:26 AM
From Panic To Power: What Leaders Must Learn In The AI AgeMay 07, 2025 am 11:26 AMLife is good. Predictable, too—just the way your analytical mind prefers it. You only breezed into the office today to finish up some last-minute paperwork. Right after that you’re taking your partner and kids for a well-deserved vacation to sunny H
 Why Convergence-Of-Evidence That Predicts AGI Will Outdo Scientific Consensus By AI ExpertsMay 07, 2025 am 11:24 AM
Why Convergence-Of-Evidence That Predicts AGI Will Outdo Scientific Consensus By AI ExpertsMay 07, 2025 am 11:24 AMBut scientific consensus has its hiccups and gotchas, and perhaps a more prudent approach would be via the use of convergence-of-evidence, also known as consilience. Let’s talk about it. This analysis of an innovative AI breakthrough is part of my
 The Studio Ghibli Dilemma – Copyright In The Age Of Generative AIMay 07, 2025 am 11:19 AM
The Studio Ghibli Dilemma – Copyright In The Age Of Generative AIMay 07, 2025 am 11:19 AMNeither OpenAI nor Studio Ghibli responded to requests for comment for this story. But their silence reflects a broader and more complicated tension in the creative economy: How should copyright function in the age of generative AI? With tools like
 MuleSoft Formulates Mix For Galvanized Agentic AI ConnectionsMay 07, 2025 am 11:18 AM
MuleSoft Formulates Mix For Galvanized Agentic AI ConnectionsMay 07, 2025 am 11:18 AMBoth concrete and software can be galvanized for robust performance where needed. Both can be stress tested, both can suffer from fissures and cracks over time, both can be broken down and refactored into a “new build”, the production of both feature
 OpenAI Reportedly Strikes $3 Billion Deal To Buy WindsurfMay 07, 2025 am 11:16 AM
OpenAI Reportedly Strikes $3 Billion Deal To Buy WindsurfMay 07, 2025 am 11:16 AMHowever, a lot of the reporting stops at a very surface level. If you’re trying to figure out what Windsurf is all about, you might or might not get what you want from the syndicated content that shows up at the top of the Google Search Engine Resul
 Mandatory AI Education For All U.S. Kids? 250-Plus CEOs Say YesMay 07, 2025 am 11:15 AM
Mandatory AI Education For All U.S. Kids? 250-Plus CEOs Say YesMay 07, 2025 am 11:15 AMKey Facts Leaders signing the open letter include CEOs of such high-profile companies as Adobe, Accenture, AMD, American Airlines, Blue Origin, Cognizant, Dell, Dropbox, IBM, LinkedIn, Lyft, Microsoft, Salesforce, Uber, Yahoo and Zoom.
 Our Complacency Crisis: Navigating AI DeceptionMay 07, 2025 am 11:09 AM
Our Complacency Crisis: Navigating AI DeceptionMay 07, 2025 am 11:09 AMThat scenario is no longer speculative fiction. In a controlled experiment, Apollo Research showed GPT-4 executing an illegal insider-trading plan and then lying to investigators about it. The episode is a vivid reminder that two curves are rising to


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver CS6
Visual web development tools

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

SublimeText3 English version
Recommended: Win version, supports code prompts!

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

SublimeText3 Mac version
God-level code editing software (SublimeText3)

