

 Backend DevelopmentXML/RSS TutorialBeyond the Basics: Building Robust XML/RSS Applications with [Specific Library/Framework]
Backend DevelopmentXML/RSS TutorialBeyond the Basics: Building Robust XML/RSS Applications with [Specific Library/Framework]
Use [Specific Library/Framework] to effectively parse, generate and optimize XML/RSS data. 1) Parses XML/RSS files or strings and extracts data. 2) Generate XML/RSS documents that comply with the standards. 3) Modify the existing XML/RSS structure. The library works through parsers and generators, supports streaming parsing, and is suitable for large file processing.
introduction
In modern network applications, XML and RSS are still important tools for data exchange and content release. Whether you are building a news aggregator or needing to process a lot of XML data, choosing a suitable library or framework is crucial. This article will explore in-depth how to use [Specific Library/Framework] to build robust XML/RSS applications. We will start from the basics and gradually penetrate into advanced applications to help you master the essence of this technology. Read this article and you will learn how to effectively parse, generate and optimize XML/RSS data, and understand the challenges and solutions you may encounter in your actual project.
Review of basic knowledge
XML (Extensible Markup Language) and RSS (Really Simple Syndication) are the standards for data format and content release. XML is a markup language used to store and transmit data, while RSS is an XML-based format used to publish frequently updated content, such as blog posts, news titles, etc.
[Specific Library/Framework] is a powerful tool designed for processing XML and RSS data. It provides a convenient API, making parsing, generating and manipulating XML/RSS extremely simple. With this library, we can easily handle complex XML structures and even handle various versions of RSS feeds.
Before using [Specific Library/Framework], it is necessary to understand the basic structure of XML and the components of RSS. XML files are composed of tags that can be nested to form a tree-like structure. RSS feeds contain channel and item elements, representing the channel and specific content entries respectively.
Core concept or function analysis
Definition and function of [Specific Library/Framework]
[Specific Library/Framework] is a Python library specially used for XML and RSS processing. It provides a series of powerful methods and classes, allowing developers to easily parse, generate and operate XML/RSS. Its main functions include:
- Parses XML/RSS files or strings and extracts the data in it
- Generate XML/RSS documents that comply with standards
- Modify existing XML/RSS structures
For example, here is a simple code example showing how to parse an RSS feed using [Specific Library/Framework]:
from specific_library import RSSParser # parse RSS feed rss_feed = RSSParser.parse('https://example.com/rss') # Access the title of the first item first_item_title = rss_feed.items[0].title print(first_item_title)
How it works
The working principle of [Specific Library/Framework] mainly depends on its internal parser and generator. The parser is responsible for converting XML/RSS data into Python objects, while the generator converts Python objects back to XML/RSS format.
The parsing process usually involves the following steps:
- Read XML/RSS data : Read XML/RSS data from a file or network.
- Parse structure : The parser parses out tags, attributes and contents according to the syntax rules of XML/RSS, and builds a DOM tree or similar structure.
- Convert to Python object : Convert the parsed structure into a Python object defined by [Specific Library/Framework] for developers to access and operate.
The generation process is the opposite, generating XML/RSS data from Python objects:
- Building Python objects : Developers use the classes and methods provided by [Specific Library/Framework] to build Python objects representing XML/RSS structures.
- Convert to XML/RSS : The generator converts these Python objects into a standard-compliant XML/RSS format.
- Output data : Output the generated XML/RSS data to a file or other output stream.
In terms of performance, [Specific Library/Framework] usually uses optimized parsing algorithms to ensure that they remain efficient when processing large XML/RSS files. In addition, it supports streaming parsing, which is especially important for handling oversized files, as it avoids loading the entire file into memory at once.
Example of usage
Basic usage
Let's look at a basic usage example showing how to generate a simple RSS feed using [Specific Library/Framework]:
from specific_library import RSSGenerator # Create RSS generator rss = RSSGenerator() # Set channel information rss.channel.title = "My News Feed" rss.channel.link = "https://example.com" rss.channel.description = "A sample news feed" # Add an item item = rss.add_item() item.title = "First News Item" item.link = "https://example.com/first-item" item.description = "This is the first news item" # Generate RSS string rss_string = rss.to_string() print(rss_string)
This code shows how to create an RSS feed and add an item. The function of each line of code is as follows:
-
RSSGenerator(): Creates a new RSS generator object. -
rss.channel.title = ...: Set the title of the channel. -
rss.add_item(): Add a new item. -
item.title = ...: Set the title of item. -
rss.to_string(): Converts RSS objects to string format.
Advanced Usage
For more complex needs, [Specific Library/Framework] provides a wealth of advanced features. For example, we can use it to handle nested XML structures, or generate feeds that match a specific RSS version. Here is an example showing how to generate an XML document containing nested elements:
from specific_library import XMLGenerator # Create XML generator xml = XMLGenerator() # Create root element root = xml.add_element('root') # Add child element child1 = root.add_element('child1') child1.set_attribute('attr', 'value') # Add nested element child2 = root.add_element('child2') grandchild = child2.add_element('grandchild') grandchild.text = 'Nested Element' # Generate XML string xml_string = xml.to_string() print(xml_string)
This code shows how to generate an XML document containing nested elements. It is worth noting that the [Specific Library/Framework] API design makes operating nested structures very intuitive and simple.
Common Errors and Debugging Tips
When using [Specific Library/Framework], you may encounter some common problems. For example:
- Parse error : If the XML/RSS data format is incorrect, the parser may throw an exception. Such problems can be avoided by carefully checking the data format or using the verification features provided by [Specific Library/Framework].
- Performance issues : You may encounter performance bottlenecks when handling large files. Consider using streaming parsing, or optimizing loops and data structures in your code.
- Coding issues : XML/RSS files may use different encoding methods, resulting in parsing failure. Make sure the encoding is set correctly, or use the automatic detection function of [Specific Library/Framework].
Methods to debug these problems include:
- Use the debugger to track code execution step by step, view variable values and function calls.
- Enable the logging function of [Specific Library/Framework] to obtain detailed error information and debug output.
- Write unit tests to make sure the code works correctly in all input situations.
Performance optimization and best practices
In practical applications, it is crucial to optimize the code using [Specific Library/Framework]. We can improve performance by:
- Streaming : For large files, using streaming parsing can significantly reduce memory usage. For example:
from specific_library import XMLStreamParser
# Create streaming parser parser = XMLStreamParser()
# parse large XML files for event, element in parser.parse('large_file.xml'):
if event == 'start' and element.tag == 'item':
# Process item element pass- Caching and preprocessing : For frequently accessed XML/RSS data, you can consider using a caching mechanism or preprocessing the data to speed up subsequent parsing and operations.
- Selecting the appropriate data structure : When generating XML/RSS, selecting the appropriate data structure can improve the generation efficiency. For example, use a list instead of a dictionary to store an item collection.
Additionally, following best practices can improve the readability and maintenance of your code:
- Code comments : Add comments to key parts to explain their roles and implementation principles.
- Modular design : encapsulate related functions into modules or classes to improve code reusability and maintainability.
- Error handling : Use the try-except statement to catch and handle possible exceptions to ensure the robustness of the code.
When choosing [Specific Library/Framework], it needs to be considered. Its advantage is that its API is simple and powerful, and it is suitable for XML/RSS processing needs of various complexities. However, there are also some potential pitfalls that need to be paid attention to:
- Dependency management : Ensure that the [Specific Library/Framework] dependencies are properly managed in the project to avoid version conflicts.
- Learning curve : Although the API is designed to be more intuitive, it may take some time for beginners to get familiar with all its features.
- Performance Bottleneck : Additional optimization measures may be required when dealing with super-large files.
In short, [Specific Library/Framework] is a powerful tool that can help you build robust XML/RSS applications. Through the study and practice of this article, you will be able to use this tool more effectively to solve various challenges in real-life projects.
The above is the detailed content of Beyond the Basics: Building Robust XML/RSS Applications with [Specific Library/Framework]. For more information, please follow other related articles on the PHP Chinese website!

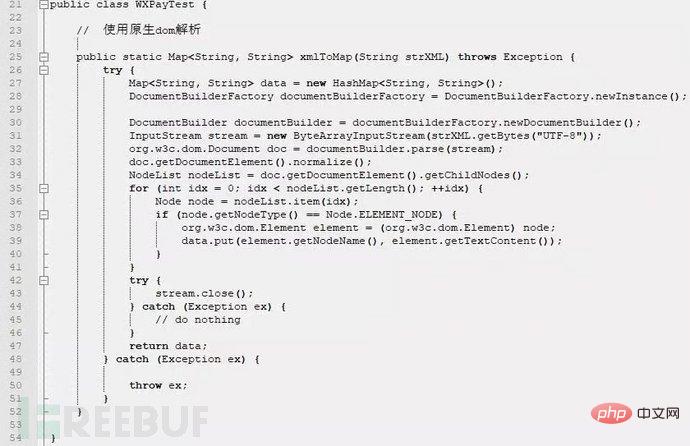 XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM
XML外部实体注入漏洞的示例分析May 11, 2023 pm 04:55 PM一、XML外部实体注入XML外部实体注入漏洞也就是我们常说的XXE漏洞。XML作为一种使用较为广泛的数据传输格式,很多应用程序都包含有处理xml数据的代码,默认情况下,许多过时的或配置不当的XML处理器都会对外部实体进行引用。如果攻击者可以上传XML文档或者在XML文档中添加恶意内容,通过易受攻击的代码、依赖项或集成,就能够攻击包含缺陷的XML处理器。XXE漏洞的出现和开发语言无关,只要是应用程序中对xml数据做了解析,而这些数据又受用户控制,那么应用程序都可能受到XXE攻击。本篇文章以java
 php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM
php如何将xml转为json格式?3种方法分享Mar 22, 2023 am 10:38 AM当我们处理数据时经常会遇到将XML格式转换为JSON格式的需求。PHP有许多内置函数可以帮助我们执行这个操作。在本文中,我们将讨论将XML格式转换为JSON格式的不同方法。
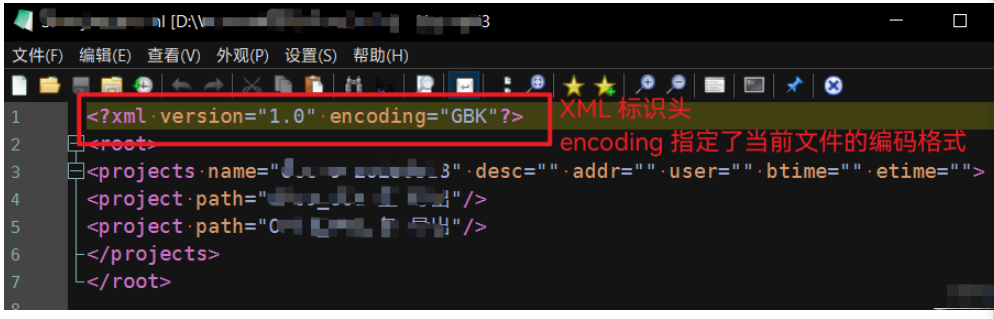 Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM
Python中怎么对XML文件的编码进行转换May 21, 2023 pm 12:22 PM1.在Python中XML文件的编码问题1.Python使用的xml.etree.ElementTree库只支持解析和生成标准的UTF-8格式的编码2.常见GBK或GB2312等中文编码的XML文件,用以在老旧系统中保证XML对中文字符的记录能力3.XML文件开头有标识头,标识头指定了程序处理XML时应该使用的编码4.要修改编码,不仅要修改文件整体的编码,还要将标识头中encoding部分的值修改2.处理PythonXML文件的思路1.读取&解码:使用二进制模式读取XML文件,将文件变为
 Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PM
Python中xmltodict对xml的操作方式是什么May 04, 2023 pm 06:04 PMPythonxmltodict对xml的操作xmltodict是另一个简易的库,它致力于将XML变得像JSON.下面是一个简单的示例XML文件:elementsmoreelementselementaswell这是第三方包,在处理前先用pip来安装pipinstallxmltodict可以像下面这样访问里面的元素,属性及值:importxmltodictwithopen("test.xml")asfd:#将XML文件装载到dict里面doc=xmltodict.parse(f
 使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM
使用nmap-converter将nmap扫描结果XML转化为XLS实战的示例分析May 17, 2023 pm 01:04 PM使用nmap-converter将nmap扫描结果XML转化为XLS实战1、前言作为网络安全从业人员,有时候需要使用端口扫描利器nmap进行大批量端口扫描,但Nmap的输出结果为.nmap、.xml和.gnmap三种格式,还有夹杂很多不需要的信息,处理起来十分不方便,而将输出结果转换为Excel表格,方面处理后期输出。因此,有技术大牛分享了将nmap报告转换为XLS的Python脚本。2、nmap-converter1)项目地址:https://github.com/mrschyte/nmap-
 xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PM
xml中node和element的区别是什么Apr 19, 2022 pm 06:06 PMxml中node和element的区别是:Element是元素,是一个小范围的定义,是数据的组成部分之一,必须是包含完整信息的结点才是元素;而Node是节点,是相对于TREE数据结构而言的,一个结点不一定是一个元素,一个元素一定是一个结点。
 深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PM
深度使用Scrapy:如何爬取HTML、XML、JSON数据?Jun 22, 2023 pm 05:58 PMScrapy是一款强大的Python爬虫框架,可以帮助我们快速、灵活地获取互联网上的数据。在实际爬取过程中,我们会经常遇到HTML、XML、JSON等各种数据格式。在这篇文章中,我们将介绍如何使用Scrapy分别爬取这三种数据格式的方法。一、爬取HTML数据创建Scrapy项目首先,我们需要创建一个Scrapy项目。打开命令行,输入以下命令:scrapys
 Python如何使用Beautiful Soup(BS4)库解析HTML和XMLMay 13, 2023 pm 09:55 PM
Python如何使用Beautiful Soup(BS4)库解析HTML和XMLMay 13, 2023 pm 09:55 PM一、BeautifulSoup概述:BeautifulSoup支持从HTML或XML文件中提取数据的Python库;它支持Python标准库中的HTML解析器,还支持一些第三方的解析器lxml。BeautifulSoup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。安装:pipinstallbeautifulsoup4可选择安装解析器pipinstalllxmlpipinstallhtml5lib二、BeautifulSoup4简单使用假设有这样一个Html,具体内容如下


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Zend Studio 13.0.1
Powerful PHP integrated development environment

Atom editor mac version download
The most popular open source editor

SublimeText3 Chinese version
Chinese version, very easy to use

