



Large Language Models (LLMs) have proven themselves as a formidable tool, excelling in both interpreting and producing text that mimics human language. Nevertheless, the widespread availability of these models introduces the complex task of accurately assessing their performance.Here, LLM benchmarks take center stage, providing systematic evaluations to measure a model’s skill in tasks like language understanding and advanced reasoning. This article explores their critical role, highlights renowned examples, and examines their limitations, offering a full picture of their impact on language technology.
Benchmarks are essential for evaluating Large Language Models (LLMs), serving as a standard for measuring and comparing performance. They offer a consistent way to assess skills, from basic language comprehension to advanced reasoning and programming.
Table of contents
- What Are LLM Benchmarks?
- What is the Need for LLM Benchmarks?
- Working of LLM Benchmarks
- Reasoning Benchmarks
- ARC: The Abstraction and Reasoning Challenge
- Massive Multi-discipline Multimodal Understanding (MMMU)
- GPQA: A Challenging Benchmark for Advanced Reasoning
- Measuring Massive Multitask Language Understanding (MMLU)
- Coding Benchmarks
- HumanEval: Evaluating Code Generation from Language Models
- SWE-Bench
- SWE-Lancer
- Live Code Bench
- CodeForces
- Tool Use (Agentic) Benchmarks
- TAU-Bench
- Language Understanding and Question Answering Benchmark
- SuperGLUE
- HelloSwag
- Mathematics Benchmarks
- MATH Dataset
- AIME 2025
- Conclusion
What Are LLM Benchmarks?
LLM benchmarks are structured tests designed to evaluate the performance of language models on specific tasks. They help answer critical questions such as:
- Can this LLM effectively handle coding tasks?
- How well does it provide relevant answers in a conversation?
- Is it capable of solving complex reasoning problems?
Key Features of LLM Benchmarks
- Standardized Tests: Each benchmark consists of a set of tasks with known correct answers, allowing for consistent evaluation.
-
Diverse Areas of Assessment: Benchmarks can focus on various skills, including:
- Language comprehension
- Math problem-solving
- Coding abilities
- Conversational quality
- Safety and ethical considerations
What is the Need for LLM Benchmarks?
Standardization and Transparency in Evaluation
- Comparative Consistency: Benchmarks facilitate direct comparisons among LLMs, ensuring evaluations are transparent and reproducible.
- Performance Snapshot: They offer a rapid assessment of a new LLM’s capabilities relative to established models.
Progress Tracking and Refinement
- Monitoring Progress: Benchmarks assist in observing model performance improvements over time, aiding researchers in refining their models.
- Uncovering Limitations: These tools can pinpoint areas where models fall short, guiding future research and development efforts.
Model Selection
- Informed Choices: For practitioners, benchmarks become a crucial reference when choosing models for specific tasks, ensuring well-informed decisions for applications like chatbots or customer support systems.
Working of LLM Benchmarks
Here’s the step-by-step process:
-
Dataset Input and Testing
- Benchmarks provide a variety of tasks for the LLM to complete, such as answering questions or generating code.
- Each benchmark includes a dataset of text inputs and corresponding “ground truth” answers for evaluation.
- Performance Evaluation and Scoring: After completing the tasks, the model’s responses are evaluated using standardized metrics, such as accuracy or BLEU scores, depending on the task type.
- LLM Ranking and Leaderboards: Models are ranked based on their scores, often displayed on leaderboards that aggregate results from multiple benchmarks.
Reasoning Benchmarks
1. ARC: The Abstraction and Reasoning Challenge
The Abstraction and Reasoning Corpus (ARC) benchmarks machine intelligence by drawing inspiration from Raven’s Progressive Matrices. It challenges AI systems to identify the next image in a sequence based on a few examples, promoting few-shot learning that mirrors human cognitive abilities. By emphasizing generalization and leveraging “priors”—intrinsic knowledge about the world—ARC aims to advance AI toward human-like reasoning. The dataset follows a structured curriculum, systematically guiding systems through increasingly complex tasks while measuring performance through prediction accuracy. Despite progress, AI still struggles to reach human-level performance, highlighting the ongoing need for advancements in AI research.

The Abstraction and Reasoning Corpus includes a diverse set of tasks that both humans and artificial intelligence systems can solve. Inspired by Raven’s Progressive Matrices, the task format requires participants to identify the next image in a sequence, testing their cognitive abilities.
2. Massive Multi-discipline Multimodal Understanding (MMMU)
The Massive Multi-discipline Multimodal Understanding and Reasoning (MMMU) benchmark evaluates multimodal models on college-level knowledge and reasoning tasks. It includes 11.5K questions from exams, quizzes, and textbooks across six disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering.
These questions span 30 subjects and 183 subfields, incorporating 30 heterogeneous image types like charts, diagrams, maps, and chemical structures. MMMU focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform expert-level tasks, and aims to measure perception, knowledge, and reasoning skills in Large Multimodal Models (LMMs). Evaluation of current models, including GPT-4V, reveals substantial room for improvement, even with advanced models only achieving around 56% accuracy. A more robust version of the benchmark, MMMU-Pro, has been introduced for enhanced evaluation.

Sampled MMMU examples from each discipline. The questions and images need expert-level knowledge to understand and reason.
3. GPQA: A Challenging Benchmark for Advanced Reasoning
GPQA is a dataset of 448 multiple-choice questions in biology, physics, and chemistry, designed to challenge experts and advanced AI. Domain experts with PhDs create and validate the questions to ensure high quality and difficulty. Experts achieve 65% accuracy (74% with retrospectively identified mistakes), while non-experts with PhDs in other fields score only 34%, despite unrestricted internet access, proving the questions are “Google-proof.” Leading AI models like GPT-4 reach just 39% accuracy. GPQA supports research on scalable oversight for AI surpassing human abilities, helping humans extract truthful information even on topics beyond their expertise.

Initially, a question is crafted, and then an expert in the same domain provides their answer and feedback, which may include suggested revisions to the question. Subsequently, the question writer revises the question based on the expert’s feedback. This revised question is then sent to another expert in the same domain and three non-expert validators with expertise in other fields. We consider expert validators’ agreement (*) when they either answer correctly initially or, after seeing the correct answer, they provide a clear explanation of their initial mistake or demonstrate a thorough understanding of the question writer’s explanation.
4. Measuring Massive Multitask Language Understanding (MMLU)
The Massive Multitask Language Understanding (MMLU) benchmark, designed to measure a text model’s knowledge acquired during pretraining. MMLU evaluates models on 57 diverse tasks, including elementary mathematics, US history, computer science, law, and more. It’s formatted as multiple-choice questions, making evaluation straightforward.
The benchmark aims to be a more comprehensive and challenging test of language understanding than previous benchmarks, requiring a combination of knowledge and reasoning. The paper presents results for several models, showing that even large pretrained models struggle on MMLU, suggesting significant room for improvement in language understanding capabilities. Furthermore, the paper explores the impact of scale and fine-tuning on MMLU performance.

This task requires understanding detailed and dissonant scenarios, applying appropriate
legal precedents, and choosing the correct explanation. The green checkmark is the ground truth.
Coding Benchmarks
5. HumanEval: Evaluating Code Generation from Language Models
HumanEval is a benchmark designed to evaluate the functional correctness of code generated by language models. It consists of 164 programming problems with a function signature, docstring, and several unit tests. These problems assess skills in language understanding, reasoning, algorithms, and simple mathematics. Unlike previous benchmarks that relied on syntactic similarity, HumanEval evaluates whether the generated code actually passes the provided unit tests, thus measuring functional correctness. The benchmark highlights the gap between current language models and human-level code generation, revealing that even large models struggle to produce correct code consistently. It serves as a challenging and practical test for assessing the capabilities of code-generating language models.

Below are three illustrative problems from the HumanEval dataset, accompanied by the probabilities that a single sample from Codex-12B passes unit tests: 0.9, 0.17, and 0.005. The prompt presented to the model is displayed on a white background, while a successful model-generated completion is highlighted on a yellow background. Although it doesn’t guarantee problem novelty, all problems were meticulously crafted by hand and not programmatically copied from existing sources, ensuring a unique and challenging dataset.
6. SWE-Bench
SWE-bench is a benchmark designed to evaluate large language models (LLMs) on their ability to resolve real-world software issues found on GitHub. It consists of 2,294 software engineering problems sourced from real GitHub issues and corresponding pull requests across 12 popular Python repositories. The task involves providing a language model with a codebase and an issue description, challenging it to generate a patch that resolves the issue. The model’s proposed solution is then evaluated against the repository’s testing framework. SWE-bench focuses on assessing an entire “agent” system, which includes the AI model and the surrounding software scaffolding responsible for generating prompts, parsing output, and managing the interaction loop2. A human-validated subset called SWE-bench Verified consisting of 500 samples ensures the tasks are solvable and provides a clearer measure of coding agents’ performance
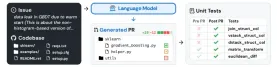
SWE-bench sources task instances from real-world Python repositories by connecting GitHub issues to merge pull request solutions that resolve related tests. Provided with the issue text and a codebase snapshot, models generate a patch that is evaluated against real tests
7. SWE-Lancer
SWE-Lancer is a benchmark developed to evaluate the capabilities of frontier language models (LLMs) in completing real-world freelance software engineering tasks sourced from Upwork, with a total value of $1 million. It includes over 1,400 tasks that range from simple bug fixes, valued at $50, to complex feature implementations worth up to $32,000. The benchmark assesses two types of tasks: Individual Contributor (IC) tasks, where models generate code patches verified through end-to-end tests by professional engineers, and SWE Manager tasks, where models select the best implementation proposals from multiple options. The findings indicate that even advanced models struggle to solve most tasks, highlighting the gap between current AI capabilities and real-world software engineering needs. By linking model performance to monetary value, SWE-Lancer aims to foster research into the economic implications of AI in software development.

The evaluation process for IC SWE tasks involves a rigorous assessment where the model’s performance is thoroughly tested. The model is presented with a set of tasks, and it must generate solutions that satisfy all applicable tests to earn the payout. This evaluation flow ensures that the model’s output is not only correct but also comprehensive, meeting the high standards required for real-world software engineering tasks.
8. Live Code Bench
LiveCodeBench is a novel benchmark designed to offer a holistic and contamination-free evaluation of Large Language Models (LLMs) on code-related tasks by addressing the limitations of existing benchmarks. It uses problems sourced from weekly coding contests on platforms like LeetCode, AtCoder, and CodeForces, tagged with release dates to prevent contamination, and evaluates LLMs on self-repair, code execution, and test output prediction, in addition to code generation. With over 500 coding problems published between May 2023 and May 2024, LiveCodeBench features high-quality problems and tests, balanced problem difficulty, and has revealed potential overfitting to HumanEval among some models, highlighting the varying strengths of different models across diverse coding tasks.

LiveCodeBench offers a comprehensive evaluation approach by presenting various coding scenarios. Coding is a complex task, and we propose assessing Large Language Models (LLMs) through a suite of evaluation setups that capture a range of coding-related skills. Beyond the typical code generation setting, we introduce three additional scenarios: self-repair, code execution, and a novel test output prediction task.
9. CodeForces
CodeForces is a novel benchmark designed to evaluate the competition-level code generation abilities of Large Language Models (LLMs) by directly interfacing with the CodeForces platform. This approach ensures accurate evaluation through access to hidden test cases, support for special judges, and a consistent execution environment. CodeForces introduces a standardized Elo rating system, aligned with CodeForces’ own rating system but with reduced variance, allowing for direct comparison between LLMs and human competitors. Evaluation of 33 LLMs revealed significant performance differences, with OpenAI’s o1-mini achieving the highest Elo rating of 1578, placing it in the top 90th percentile of human participants. The benchmark reveals the progress made by advanced models and the considerable room for improvement in most current LLMs’ competitive programming capabilities. The CodeForces benchmark and its Elo calculation logic are publicly available.

CodeForces presents a wide range of programming challenges, and each problem is carefully structured to include essential components. These components typically include: 1) a descriptive title, 2) a time limit for the solution, 3) a memory limit for the program, 4) a detailed problem description, 5) the input format, 6) the expected output format, 7) test case examples to guide the programmer, and 8) an optional note providing additional context or hints. One such problem, titled “CodeForces Problem E,” can be accessed at the URL: https://codeforces.com/contest/2034/problem/E. This problem is carefully crafted to test a programmer’s skills in a competitive coding environment, challenging them to create efficient and effective solutions within the given time and memory constraints.
Tool Use (Agentic) Benchmarks
10. TAU-Bench
τ-bench actively evaluates language agents on their ability to interact with (simulated) human users and programmatic APIs while adhering to domain-specific policies. Unlike existing benchmarks that often feature simplified instruction-following setups, τ-bench emulates dynamic conversations between a user (simulated by language models) and a language agent equipped with domain-specific API tools and policy guidelines. This benchmark employs a modular framework that includes realistic databases and APIs, domain-specific policy documents, and instructions for diverse user scenarios with corresponding ground truth annotations. A key feature of τ-bench is its evaluation process, which compares the database state at the end of a conversation with the annotated goal state, allowing for an objective measurement of the agent’s decision-making.
The benchmark also introduces a new metric, pass^k, to evaluate the reliability of agent behavior over multiple trials, highlighting the need for agents that can act consistently and follow rules reliably in real-world applications. Initial experiments show that even state-of-the-art function calling agents struggle with complex reasoning, policy adherence, and handling compound requests.

τ-bench is an innovative benchmark where an agent engages with database API tools and an LM-simulated user to accomplish tasks. It evaluates the agent’s capability to gather and convey pertinent information to and from users through multiple interactions, while also testing its ability to solve intricate issues in real-time, ensuring adherence to guidelines outlined in a domain-specific policy document. In the τ-airline task, the agent must reject a user’s request to change a basic economy flight based on domain policies and then propose an alternative solution—canceling and rebooking. This task requires the agent to apply zero-shot reasoning in a complex environment that involves databases, rules, and user intents.
Language Understanding and Question Answering Benchmark
11. SuperGLUE
SuperGLUE assesses the capabilities of Natural Language Understanding (NLU) models through an advanced benchmark, offering a more demanding evaluation than its predecessor, GLUE. While retaining two of GLUE’s most challenging tasks, SuperGLUE introduces new and more intricate tasks that require deeper reasoning, commonsense knowledge, and contextual understanding. It expands beyond GLUE’s sentence and sentence-pair classifications to include tasks like question answering and coreference resolution. SuperGLUE designers create tasks that college-educated English speakers can manage, but these tasks still exceed the capabilities of current state-of-the-art systems. This benchmark provides comprehensive human baselines for comparison and offers a toolkit for model evaluation. SuperGLUE aims to measure and drive progress towards developing general-purpose language understanding technologies.

The development set of SuperGLUE tasks offers a diverse range of examples, each presented in a unique format. These examples typically include bold text to indicate the specific format for each task. The model input integrates the italicized text to provide essential context or information. It specially marks the underlined text within the input, often highlighting a specific focus or requirement. Lastly, it uses the monospaced font to represent the anticipated output, showcasing the expected response or solution.
12. HelloSwag
HellaSwag is a benchmark dataset for evaluating commonsense natural language inference (NLI). It challenges machines to complete sentences based on given contexts. Developed by Zellers et al., it contains 70,000 problems. Humans achieve over 95% accuracy, while top models score below 50%. The dataset uses Adversarial Filtering (AF) to generate misleading yet plausible incorrect answers, making it harder for models to find the right completion. This highlights the limitations of deep learning models like BERT in commonsense reasoning. HellaSwag emphasizes the need for evolving benchmarks that keep AI systems challenged in understanding human-like scenarios.

Models like BERT often struggle to complete sentences in HellaSwag, even when they come from the same distribution as the training data. The incorrect endings, though contextually relevant, fail to meet human standards of correctness and plausibility. For example, in a WikiHow passage, option A advises drivers to stop at a red light for only two seconds, which is clearly wrong and impractical.
Mathematics Benchmarks
13. MATH Dataset
The MATH dataset, introduced in the article, contains 12,500 challenging mathematics competition problems. It evaluates the problem-solving abilities of machine learning models. These problems come from competitions like AMC 10, AMC 12, and AIME, covering various difficulty levels and subjects such as pre-algebra, algebra, number theory, and geometry. Unlike typical math problems solvable with known formulas, MATH problems require problem-solving techniques and heuristics. Each problem includes a step-by-step solution, helping models learn to generate answer derivations and explanations for more interpretable outputs.

This example includes diverse mathematical problems with generated solutions and corresponding ground truth solutions. The most recent AIME, held on February 6th, quickly gained interest in the math community. People shared problems and solutions on YouTube, online forums, and blogs soon after the exam. This rapid discussion highlights the community’s enthusiasm for these challenges. For example, the first problem’s generated solution is correct and clearly explained, showing a successful model output. In contrast, the second problem, involving combinatorics and a figure, challenges the model, leading to an incorrect solution.
14. AIME 2025
The American Invitational Mathematics Examination (AIME) is a prestigious math competition and the second stage in selecting the U.S. team for the International Mathematics Olympiad. Most participants are high school students, but some talented middle schoolers qualify each year. The Mathematical Association of America conducts this exam.
The math community quickly took interest in the recent AIME on February 6th, sharing and discussing problems and solutions across YouTube, forums, and blogs soon after the exam. This rapid analysis reflects the community’s enthusiasm for these challenging competitions.

This image denotes an example problem and solution from the AIME 2025 paper. This benchmark focuses on the mathematical reasoning capabilities of an LLM.
Conclusion
Developers create and train new models almost every day on large datasets, equipping them with various capabilities. LLM benchmarks play a vital role in comparing these models by answering essential questions, such as which model is best for writing code, which one excels in reasoning, and which one handles NLP tasks most effectively. Therefore, evaluating models on these benchmarks becomes a mandatory step. As we rapidly progress toward AGI, researchers are also creating new benchmarks to keep up with advancements.
The above is the detailed content of 14 Popular LLM Benchmarks to Know in 2025. For more information, please follow other related articles on the PHP Chinese website!

![Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]](https://img.php.cn/upload/article/001/242/473/174717025174979.jpg?x-oss-process=image/resize,p_40) Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]May 14, 2025 am 05:04 AM
Can't use ChatGPT! Explaining the causes and solutions that can be tested immediately [Latest 2025]May 14, 2025 am 05:04 AMChatGPT is not accessible? This article provides a variety of practical solutions! Many users may encounter problems such as inaccessibility or slow response when using ChatGPT on a daily basis. This article will guide you to solve these problems step by step based on different situations. Causes of ChatGPT's inaccessibility and preliminary troubleshooting First, we need to determine whether the problem lies in the OpenAI server side, or the user's own network or device problems. Please follow the steps below to troubleshoot: Step 1: Check the official status of OpenAI Visit the OpenAI Status page (status.openai.com) to see if the ChatGPT service is running normally. If a red or yellow alarm is displayed, it means Open
 Calculating The Risk Of ASI Starts With Human MindsMay 14, 2025 am 05:02 AM
Calculating The Risk Of ASI Starts With Human MindsMay 14, 2025 am 05:02 AMOn 10 May 2025, MIT physicist Max Tegmark told The Guardian that AI labs should emulate Oppenheimer’s Trinity-test calculus before releasing Artificial Super-Intelligence. “My assessment is that the 'Compton constant', the probability that a race to
 An easy-to-understand explanation of how to write and compose lyrics and recommended tools in ChatGPTMay 14, 2025 am 05:01 AM
An easy-to-understand explanation of how to write and compose lyrics and recommended tools in ChatGPTMay 14, 2025 am 05:01 AMAI music creation technology is changing with each passing day. This article will use AI models such as ChatGPT as an example to explain in detail how to use AI to assist music creation, and explain it with actual cases. We will introduce how to create music through SunoAI, AI jukebox on Hugging Face, and Python's Music21 library. Through these technologies, everyone can easily create original music. However, it should be noted that the copyright issue of AI-generated content cannot be ignored, and you must be cautious when using it. Let’s explore the infinite possibilities of AI in the music field together! OpenAI's latest AI agent "OpenAI Deep Research" introduces: [ChatGPT]Ope
 What is ChatGPT-4? A thorough explanation of what you can do, the pricing, and the differences from GPT-3.5!May 14, 2025 am 05:00 AM
What is ChatGPT-4? A thorough explanation of what you can do, the pricing, and the differences from GPT-3.5!May 14, 2025 am 05:00 AMThe emergence of ChatGPT-4 has greatly expanded the possibility of AI applications. Compared with GPT-3.5, ChatGPT-4 has significantly improved. It has powerful context comprehension capabilities and can also recognize and generate images. It is a universal AI assistant. It has shown great potential in many fields such as improving business efficiency and assisting creation. However, at the same time, we must also pay attention to the precautions in its use. This article will explain the characteristics of ChatGPT-4 in detail and introduce effective usage methods for different scenarios. The article contains skills to make full use of the latest AI technologies, please refer to it. OpenAI's latest AI agent, please click the link below for details of "OpenAI Deep Research"
 Explaining how to use the ChatGPT app! Japanese support and voice conversation functionMay 14, 2025 am 04:59 AM
Explaining how to use the ChatGPT app! Japanese support and voice conversation functionMay 14, 2025 am 04:59 AMChatGPT App: Unleash your creativity with the AI assistant! Beginner's Guide The ChatGPT app is an innovative AI assistant that handles a wide range of tasks, including writing, translation, and question answering. It is a tool with endless possibilities that is useful for creative activities and information gathering. In this article, we will explain in an easy-to-understand way for beginners, from how to install the ChatGPT smartphone app, to the features unique to apps such as voice input functions and plugins, as well as the points to keep in mind when using the app. We'll also be taking a closer look at plugin restrictions and device-to-device configuration synchronization
 How do I use the Chinese version of ChatGPT? Explanation of registration procedures and feesMay 14, 2025 am 04:56 AM
How do I use the Chinese version of ChatGPT? Explanation of registration procedures and feesMay 14, 2025 am 04:56 AMChatGPT Chinese version: Unlock new experience of Chinese AI dialogue ChatGPT is popular all over the world, did you know it also offers a Chinese version? This powerful AI tool not only supports daily conversations, but also handles professional content and is compatible with Simplified and Traditional Chinese. Whether it is a user in China or a friend who is learning Chinese, you can benefit from it. This article will introduce in detail how to use ChatGPT Chinese version, including account settings, Chinese prompt word input, filter use, and selection of different packages, and analyze potential risks and response strategies. In addition, we will also compare ChatGPT Chinese version with other Chinese AI tools to help you better understand its advantages and application scenarios. OpenAI's latest AI intelligence
 5 AI Agent Myths You Need To Stop Believing NowMay 14, 2025 am 04:54 AM
5 AI Agent Myths You Need To Stop Believing NowMay 14, 2025 am 04:54 AMThese can be thought of as the next leap forward in the field of generative AI, which gave us ChatGPT and other large-language-model chatbots. Rather than simply answering questions or generating information, they can take action on our behalf, inter
 An easy-to-understand explanation of the illegality of creating and managing multiple accounts using ChatGPTMay 14, 2025 am 04:50 AM
An easy-to-understand explanation of the illegality of creating and managing multiple accounts using ChatGPTMay 14, 2025 am 04:50 AMEfficient multiple account management techniques using ChatGPT | A thorough explanation of how to use business and private life! ChatGPT is used in a variety of situations, but some people may be worried about managing multiple accounts. This article will explain in detail how to create multiple accounts for ChatGPT, what to do when using it, and how to operate it safely and efficiently. We also cover important points such as the difference in business and private use, and complying with OpenAI's terms of use, and provide a guide to help you safely utilize multiple accounts. OpenAI


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Dreamweaver Mac version
Visual web development tools

SublimeText3 Chinese version
Chinese version, very easy to use

SublimeText3 Linux new version
SublimeText3 Linux latest version

SublimeText3 Mac version
God-level code editing software (SublimeText3)

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

