



VisionAgent: Revolutionizing Computer Vision Application Development
Computer vision is transforming industries like healthcare, manufacturing, and retail. However, building vision-based solutions is often complex and time-consuming. LandingAI, led by Andrew Ng, introduces VisionAgent, a generative Visual AI application builder designed to simplify the entire process – from creation and iteration to deployment.
VisionAgent's Agentic Object Detection eliminates the need for lengthy data labeling and model training, surpassing traditional object detection methods. Its text prompt-based detection allows for rapid prototyping and deployment, utilizing advanced reasoning for high-quality results and versatile complex object recognition.
Key features include:
- Text prompt-based detection: No data labeling or model training required.
- Advanced reasoning: Ensures accurate, high-quality outputs.
- Versatile recognition: Handles complex objects and scenarios effectively.
VisionAgent surpasses simple code generation; it acts as an AI-powered assistant, guiding developers through planning, tool selection, code generation, and deployment. This AI assistance allows developers to iterate in minutes, not weeks.
Table of Contents
- VisionAgent Ecosystem
- Benchmark Evaluation
- VisionAgent in Action
-
- Prompt: "Detect vegetables in and around the basket"
-
- Prompt: "Identify red car in the video"
- Conclusion
VisionAgent Ecosystem

VisionAgent comprises three core components for a streamlined development experience:
- VisionAgent Web App
- VisionAgent Library
- VisionAgent Tools Library
Understanding their interaction is crucial for maximizing VisionAgent's potential.
1. VisionAgent Web App
The VisionAgent Web App is a user-friendly, hosted platform for prototyping, refining, and deploying vision applications without extensive setup. Its intuitive web interface allows users to:
- Easily upload and process data.
- Generate and test computer vision code.
- Visualize and adjust results.
- Deploy solutions as cloud endpoints or Streamlit apps.
This low-code approach is ideal for experimenting with AI-powered vision applications without complex local development environments.
2. VisionAgent Library

The VisionAgent Library forms the framework's core, providing essential functionalities for creating and deploying AI-driven vision applications programmatically. Key features include:
- Agent-based planning: Generates multiple solutions and automatically selects the optimal one.
- Tool selection and execution: Dynamically chooses appropriate tools for various vision tasks.
- Code generation and evaluation: Produces efficient Python-based implementations.
- Built-in vision model support: Utilizes diverse computer vision models for object detection, image classification, and segmentation.
- Local and cloud integration: Enables local execution or utilizes LandingAI's cloud-hosted models for scalability.
A Streamlit-powered chat app provides a more intuitive interaction for users preferring a chat interface.
3. VisionAgent Tools Library

The VisionAgent Tools Library offers a collection of pre-built, Python-based tools for specific computer vision tasks:
- Object Detection: Identifies and locates objects in images or videos.
- Image Classification: Categorizes images based on trained AI models.
- QR Code Reading: Extracts information from QR codes.
- Item Counting: Counts objects for inventory or tracking.
These tools interact with various vision models via a dynamic model registry, allowing seamless model switching. Developers can also register custom tools. Note that deployment services are not included in the tools library.
Benchmark Evaluation

1. Models & Approaches
- Landing AI (Agentic Object Detection): Agentic category.
- Microsoft Florence-2: Open Set Object Detection.
- Google OWLv2: Open Set Object Detection.
- Alibaba Qwen2.5-VL-7B-Instruct: Large Multimodal Model (LMM).
2. Evaluation Metrics
Models were assessed using:
- Recall: Measures the model's ability to identify all relevant objects.
- Precision: Measures the accuracy of detections (fewer false positives).
- F1 Score: A balanced measure of precision and recall.
3. Performance Comparison
| Model | Recall | Precision | F1 Score | ||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Landing AI | 77.0% | 82.6% |
|
||||||||||||||||||||
| Microsoft Florence-2 | 43.4% | 36.6% | 39.7% | ||||||||||||||||||||
| Google OWLv2 | 81.0% | 29.5% | 43.2% | ||||||||||||||||||||
| Alibaba Qwen2.5-VL-7B-Instruct | 26.0% | 54.0% | 35.1% |
4. Key Findings
Landing AI's Agentic Object Detection achieved the highest F1 score, indicating the best balance of precision and recall. Other models showed trade-offs between recall and precision.
VisionAgent in Action
VisionAgent uses a structured workflow:
-
Upload the image or video.
-
Provide a text prompt (e.g., "detect people with glasses").
-
VisionAgent analyzes the input.
-
Receive the detection results.
-
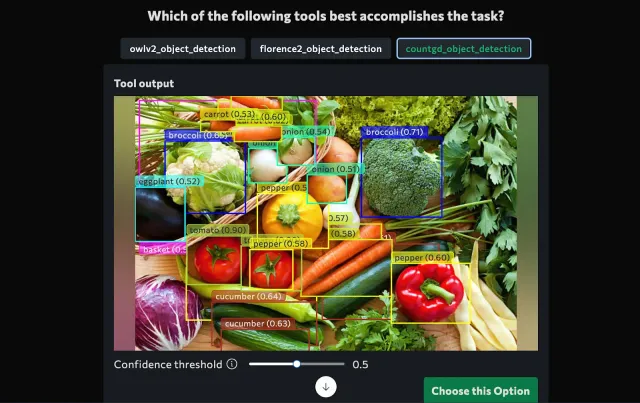
Prompt: "Detect vegetables in and around the basket"
Step 1: Interaction
The user initiates the request using natural language. VisionAgent confirms understanding.
Input Image

Interaction Example
"I'll generate code to detect vegetables inside and outside the basket using object detection."
Step 2: Planning
VisionAgent determines the best approach:
- Understand image content using Visual Question Answering (VQA).
- Generate suggestions for the detection method.
- Select appropriate tools (object detection, color-based classification).
Step 3: Execution
The plan is executed using the VisionAgent Library and Tools Library.
Observation and Output
VisionAgent provides structured results:
- Detected vegetables categorized by location (inside/outside basket).
- Bounding box coordinates for each vegetable.
- A deployable AI model.
Output Examples


-
Prompt: "Identify red car in the video"
This example follows a similar process, using video frames, VQA, and suggestions to identify and track the red car. The output would show the tracked car throughout the video. (Output image examples omitted for brevity, but would be similar in style to the vegetable detection output).
Conclusion
VisionAgent streamlines AI-driven vision application development, automating tedious tasks and providing ready-to-use tools. Its speed, flexibility, and scalability benefit AI researchers, developers, and businesses. Future advancements will likely incorporate more powerful models and broader application support.
The above is the detailed content of Andrew Ng's VisionAgent: Streamlining Vision AI Solutions. For more information, please follow other related articles on the PHP Chinese website!

 California Taps AI To Fast-Track Wildfire Recovery PermitsMay 04, 2025 am 11:10 AM
California Taps AI To Fast-Track Wildfire Recovery PermitsMay 04, 2025 am 11:10 AMAI Streamlines Wildfire Recovery Permitting Australian tech firm Archistar's AI software, utilizing machine learning and computer vision, automates the assessment of building plans for compliance with local regulations. This pre-validation significan
 What The US Can Learn From Estonia's AI-Powered Digital GovernmentMay 04, 2025 am 11:09 AM
What The US Can Learn From Estonia's AI-Powered Digital GovernmentMay 04, 2025 am 11:09 AMEstonia's Digital Government: A Model for the US? The US struggles with bureaucratic inefficiencies, but Estonia offers a compelling alternative. This small nation boasts a nearly 100% digitized, citizen-centric government powered by AI. This isn't
 Wedding Planning Via Generative AIMay 04, 2025 am 11:08 AM
Wedding Planning Via Generative AIMay 04, 2025 am 11:08 AMPlanning a wedding is a monumental task, often overwhelming even the most organized couples. This article, part of an ongoing Forbes series on AI's impact (see link here), explores how generative AI can revolutionize wedding planning. The Wedding Pl
 What Are Digital Defense AI Agents?May 04, 2025 am 11:07 AM
What Are Digital Defense AI Agents?May 04, 2025 am 11:07 AMBusinesses increasingly leverage AI agents for sales, while governments utilize them for various established tasks. However, consumer advocates highlight the need for individuals to possess their own AI agents as a defense against the often-targeted
 A Business Leader's Guide To Generative Engine Optimization (GEO)May 03, 2025 am 11:14 AM
A Business Leader's Guide To Generative Engine Optimization (GEO)May 03, 2025 am 11:14 AMGoogle is leading this shift. Its "AI Overviews" feature already serves more than one billion users, providing complete answers before anyone clicks a link.[^2] Other players are also gaining ground fast. ChatGPT, Microsoft Copilot, and Pe
 This Startup Is Using AI Agents To Fight Malicious Ads And Impersonator AccountsMay 03, 2025 am 11:13 AM
This Startup Is Using AI Agents To Fight Malicious Ads And Impersonator AccountsMay 03, 2025 am 11:13 AMIn 2022, he founded social engineering defense startup Doppel to do just that. And as cybercriminals harness ever more advanced AI models to turbocharge their attacks, Doppel’s AI systems have helped businesses combat them at scale— more quickly and
 How World Models Are Radically Reshaping The Future Of Generative AI And LLMsMay 03, 2025 am 11:12 AM
How World Models Are Radically Reshaping The Future Of Generative AI And LLMsMay 03, 2025 am 11:12 AMVoila, via interacting with suitable world models, generative AI and LLMs can be substantively boosted. Let’s talk about it. This analysis of an innovative AI breakthrough is part of my ongoing Forbes column coverage on the latest in AI, including
 May Day 2050: What Have We Left To Celebrate?May 03, 2025 am 11:11 AM
May Day 2050: What Have We Left To Celebrate?May 03, 2025 am 11:11 AMLabor Day 2050. Parks across the nation fill with families enjoying traditional barbecues while nostalgic parades wind through city streets. Yet the celebration now carries a museum-like quality — historical reenactment rather than commemoration of c


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 Linux new version
SublimeText3 Linux latest version

Dreamweaver CS6
Visual web development tools

Dreamweaver Mac version
Visual web development tools

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

