


DeepSeek's groundbreaking open-source release: FlashMLA, a CUDA kernel accelerating LLMs. This optimized multi-latent attention (MLA) decoding kernel, specifically designed for Hopper GPUs, significantly boosts the speed and efficiency of AI model hosting. Key improvements include BF16 support and a paged KV cache (64-block size), resulting in impressive performance benchmarks.
? Day 1 of #OpenSourceWeek: FlashMLA
DeepSeek proudly unveils FlashMLA, a high-efficiency MLA decoding kernel for Hopper GPUs. Optimized for variable-length sequences and now in production.
✅ BF16 support
✅ Paged KV cache (block size 64)
⚡ 3000 GB/s memory-bound & 580 TFLOPS…— DeepSeek (@deepseek_ai) February 24, 2025
Key Features:
- BF16 Precision: Enables efficient computation while maintaining numerical stability.
- Paged KV Cache (64-block size): Enhances memory efficiency and reduces latency, especially crucial for large models.
These optimizations achieve up to 3000 GB/s memory bandwidth and 580 TFLOPS in computation-bound scenarios on H800 SXM5 GPUs using CUDA 12.6. This dramatically improves AI inference performance. Previously used in DeepSeek Models, FlashMLA now accelerates DeepSeek AI's R1 V3.
Table of Contents:
- What is FlashMLA?
- Understanding Multi-head Latent Attention (MLA)
- Standard Multi-Head Attention Limitations
- MLA's Memory Optimization Strategy
- Key-Value Caching and Autoregressive Decoding
- KV Caching Mechanics
- Addressing Memory Challenges
- FlashMLA's Role in DeepSeek Models
- NVIDIA Hopper Architecture
- Performance Analysis and Implications
- Conclusion
What is FlashMLA?
FlashMLA is a highly optimized MLA decoding kernel built for NVIDIA Hopper GPUs. Its design prioritizes speed and efficiency, reflecting DeepSeek's commitment to scalable AI model acceleration.
Hardware and Software Requirements:
- Hopper architecture GPUs (e.g., H800 SXM5)
- CUDA 12.3
- PyTorch 2.0
Performance Benchmarks:
FlashMLA demonstrates exceptional performance:
- Memory Bandwidth: Up to 3000 GB/s (approaching the H800 SXM5 theoretical peak).
- Computational Throughput: Up to 580 TFLOPS for BF16 matrix multiplication (significantly exceeding the H800's theoretical peak).
This superior performance makes FlashMLA ideal for demanding AI workloads.
Understanding Multi-head Latent Attention (MLA)
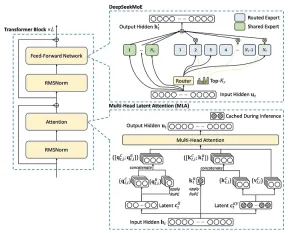
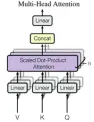
MLA, introduced with DeepSeek-V2, addresses the memory limitations of standard multi-head attention (MHA) by using a low-rank factorized projection matrix. Unlike methods like Group-Query Attention, MLA improves performance while reducing memory overhead.
Standard Multi-Head Attention Limitations:
MHA's KV cache scales linearly with sequence length, creating a memory bottleneck for long sequences. The cache size is calculated as: seq_len * n_h * d_h (where n_h is the number of attention heads and d_h is the head dimension).
MLA's Memory Optimization:
MLA compresses keys and values into a smaller latent vector (c_t), reducing the KV cache size to seq_len * d_c (where d_c is the latent vector dimension). This significantly reduces memory usage (up to 93.3% reduction in DeepSeek-V2).
Key-Value Caching and Autoregressive Decoding
KV caching accelerates autoregressive decoding by reusing previously computed key-value pairs. However, this increases memory usage.
Addressing Memory Challenges:
Techniques like Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) mitigate the memory issues associated with KV caching.
FlashMLA's Role in DeepSeek Models:
FlashMLA powers DeepSeek's R1 and V3 models, enabling efficient large-scale AI applications.
NVIDIA Hopper Architecture
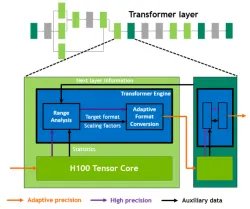
NVIDIA Hopper is a high-performance GPU architecture designed for AI and HPC workloads. Its innovations, such as the Transformer Engine and second-generation MIG, enable exceptional speed and scalability.
Performance Analysis and Implications
FlashMLA achieves 580 TFLOPS for BF16 matrix multiplication, more than double the H800 GPU's theoretical peak. This demonstrates highly efficient utilization of GPU resources.
Conclusion
FlashMLA represents a major advancement in AI inference efficiency, particularly for Hopper GPUs. Its MLA optimization, combined with BF16 support and paged KV caching, delivers remarkable performance improvements. This makes large-scale AI models more accessible and cost-effective, setting a new benchmark for model efficiency.
The above is the detailed content of DeepSeek Launches FlashMLA. For more information, please follow other related articles on the PHP Chinese website!

 California Taps AI To Fast-Track Wildfire Recovery PermitsMay 04, 2025 am 11:10 AM
California Taps AI To Fast-Track Wildfire Recovery PermitsMay 04, 2025 am 11:10 AMAI Streamlines Wildfire Recovery Permitting Australian tech firm Archistar's AI software, utilizing machine learning and computer vision, automates the assessment of building plans for compliance with local regulations. This pre-validation significan
 What The US Can Learn From Estonia's AI-Powered Digital GovernmentMay 04, 2025 am 11:09 AM
What The US Can Learn From Estonia's AI-Powered Digital GovernmentMay 04, 2025 am 11:09 AMEstonia's Digital Government: A Model for the US? The US struggles with bureaucratic inefficiencies, but Estonia offers a compelling alternative. This small nation boasts a nearly 100% digitized, citizen-centric government powered by AI. This isn't
 Wedding Planning Via Generative AIMay 04, 2025 am 11:08 AM
Wedding Planning Via Generative AIMay 04, 2025 am 11:08 AMPlanning a wedding is a monumental task, often overwhelming even the most organized couples. This article, part of an ongoing Forbes series on AI's impact (see link here), explores how generative AI can revolutionize wedding planning. The Wedding Pl
 What Are Digital Defense AI Agents?May 04, 2025 am 11:07 AM
What Are Digital Defense AI Agents?May 04, 2025 am 11:07 AMBusinesses increasingly leverage AI agents for sales, while governments utilize them for various established tasks. However, consumer advocates highlight the need for individuals to possess their own AI agents as a defense against the often-targeted
 A Business Leader's Guide To Generative Engine Optimization (GEO)May 03, 2025 am 11:14 AM
A Business Leader's Guide To Generative Engine Optimization (GEO)May 03, 2025 am 11:14 AMGoogle is leading this shift. Its "AI Overviews" feature already serves more than one billion users, providing complete answers before anyone clicks a link.[^2] Other players are also gaining ground fast. ChatGPT, Microsoft Copilot, and Pe
 This Startup Is Using AI Agents To Fight Malicious Ads And Impersonator AccountsMay 03, 2025 am 11:13 AM
This Startup Is Using AI Agents To Fight Malicious Ads And Impersonator AccountsMay 03, 2025 am 11:13 AMIn 2022, he founded social engineering defense startup Doppel to do just that. And as cybercriminals harness ever more advanced AI models to turbocharge their attacks, Doppel’s AI systems have helped businesses combat them at scale— more quickly and
 How World Models Are Radically Reshaping The Future Of Generative AI And LLMsMay 03, 2025 am 11:12 AM
How World Models Are Radically Reshaping The Future Of Generative AI And LLMsMay 03, 2025 am 11:12 AMVoila, via interacting with suitable world models, generative AI and LLMs can be substantively boosted. Let’s talk about it. This analysis of an innovative AI breakthrough is part of my ongoing Forbes column coverage on the latest in AI, including
 May Day 2050: What Have We Left To Celebrate?May 03, 2025 am 11:11 AM
May Day 2050: What Have We Left To Celebrate?May 03, 2025 am 11:11 AMLabor Day 2050. Parks across the nation fill with families enjoying traditional barbecues while nostalgic parades wind through city streets. Yet the celebration now carries a museum-like quality — historical reenactment rather than commemoration of c


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 Chinese version
Chinese version, very easy to use

WebStorm Mac version
Useful JavaScript development tools

SublimeText3 English version
Recommended: Win version, supports code prompts!

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Linux new version
SublimeText3 Linux latest version

