



DeepSeek: A Deep Dive into Reinforcement Learning for LLMs
DeepSeek's recent success, achieving impressive performance at lower costs, highlights the importance of Large Language Model (LLM) training methods. This article focuses on the Reinforcement Learning (RL) aspect, exploring TRPO, PPO, and the newer GRPO algorithms. We'll minimize complex math to make it accessible, assuming basic familiarity with machine learning, deep learning, and LLMs.
Three Pillars of LLM Training
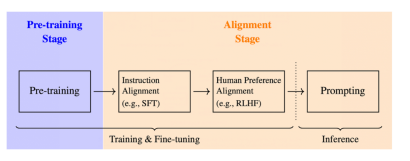
LLM training typically involves three key phases:
- Pre-training: The model learns to predict the next token in a sequence from preceding tokens using a massive dataset.
- Supervised Fine-Tuning (SFT): Targeted data refines the model, aligning it with specific instructions.
- Reinforcement Learning (RLHF): This stage, the focus of this article, further refines responses to better match human preferences through direct feedback.
Reinforcement Learning Fundamentals

Reinforcement learning involves an agent interacting with an environment. The agent exists in a specific state, taking actions to transition to new states. Each action results in a reward from the environment, guiding the agent's future actions. Think of a robot navigating a maze: its position is the state, movements are actions, and reaching the exit provides a positive reward.
RL in LLMs: A Detailed Look
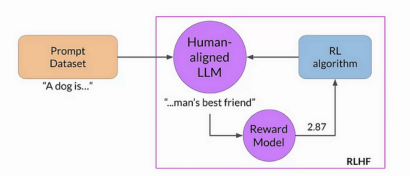
In LLM training, the components are:
- Agent: The LLM itself.
- Environment: External factors like user prompts, feedback systems, and contextual information.
- Actions: The tokens the LLM generates in response to a query.
- State: The current query and the generated tokens (partial response).
- Rewards: Usually determined by a separate reward model trained on human-annotated data, ranking responses to assign scores. Higher-quality responses receive higher rewards. Simpler, rule-based rewards are possible in specific cases, such as DeepSeekMath.
The policy determines which action to take. For an LLM, it's a probability distribution over possible tokens, used to sample the next token. RL training adjusts the policy's parameters (model weights) to favor higher-reward tokens. The policy is often represented as:
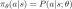
The core of RL is finding the optimal policy. Unlike supervised learning, we use rewards to guide policy adjustments.
TRPO (Trust Region Policy Optimization)

TRPO uses an advantage function, analogous to the loss function in supervised learning, but derived from rewards:
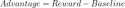
TRPO maximizes a surrogate objective, constrained to prevent large policy deviations from the previous iteration, ensuring stability:

PPO (Proximal Policy Optimization)
PPO, now preferred for LLMs like ChatGPT and Gemini, simplifies TRPO by using a clipped surrogate objective, implicitly limiting policy updates and improving computational efficiency. The PPO objective function is:
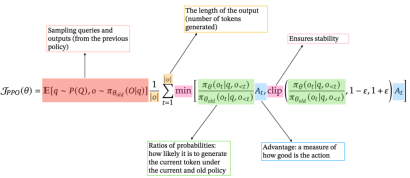
GRPO (Group Relative Policy Optimization)
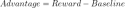
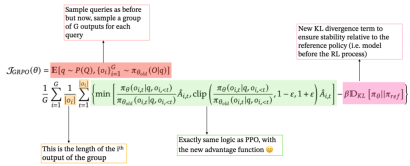
GRPO streamlines training by eliminating the separate value model. For each query, it generates a group of responses and calculates the advantage as a z-score based on their rewards:

This simplifies the process and is well-suited for LLMs' ability to generate multiple responses. GRPO also incorporates a KL divergence term, comparing the current policy to a reference policy. The final GRPO formulation is:
Conclusion
Reinforcement learning, particularly PPO and the newer GRPO, is crucial for modern LLM training. Each method builds upon RL fundamentals, offering different approaches to balance stability, efficiency, and human alignment. DeepSeek's success leverages these advancements, along with other innovations. Reinforcement learning is poised to play an increasingly dominant role in advancing LLM capabilities.
References: (The references remain the same, just reformatted for better readability)
- [1] "Foundations of Large Language Models", 2025. https://www.php.cn/link/fbf8ca43dcc014c2c94549d6b8ca0375
- [2] "Reinforcement Learning." Enaris. Available at: https://www.php.cn/link/20e169b48c8f869887e2bbe1c5c3ea65
- [3] Y. Gokhale. "Introduction to LLMs and the Generative AI Part 5: RLHF," Medium, 2023. Available at: https://www.php.cn/link/b24b1810f41d38b55728a9f56b043d35
- [4] L. Weng. "An Overview of Reinforcement Learning," 2018. Available at: https://www.php.cn/link/fc42bad715bcb9767ddd95a239552434
- [5] "DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning", 2025. https://www.php.cn/link/d0ae1e3078807c85d78d64f4ded5cdcb
- [6] "DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models", 2025. https://www.php.cn/link/f8b18593cdbb1ce289330560a44e33aa
- [7] "Trust Region Policy Optimization", 2017. https://www.php.cn/link/77a44d5cfb595b3545d61aa742268c9b
The above is the detailed content of Training Large Language Models: From TRPO to GRPO. For more information, please follow other related articles on the PHP Chinese website!

 Personal Hacking Will Be A Pretty Fierce BearMay 11, 2025 am 11:09 AM
Personal Hacking Will Be A Pretty Fierce BearMay 11, 2025 am 11:09 AMCyberattacks are evolving. Gone are the days of generic phishing emails. The future of cybercrime is hyper-personalized, leveraging readily available online data and AI to craft highly targeted attacks. Imagine a scammer who knows your job, your f
 Pope Leo XIV Reveals How AI Influenced His Name ChoiceMay 11, 2025 am 11:07 AM
Pope Leo XIV Reveals How AI Influenced His Name ChoiceMay 11, 2025 am 11:07 AMIn his inaugural address to the College of Cardinals, Chicago-born Robert Francis Prevost, the newly elected Pope Leo XIV, discussed the influence of his namesake, Pope Leo XIII, whose papacy (1878-1903) coincided with the dawn of the automobile and
 FastAPI-MCP Tutorial for Beginners and Experts - Analytics VidhyaMay 11, 2025 am 10:56 AM
FastAPI-MCP Tutorial for Beginners and Experts - Analytics VidhyaMay 11, 2025 am 10:56 AMThis tutorial demonstrates how to integrate your Large Language Model (LLM) with external tools using the Model Context Protocol (MCP) and FastAPI. We'll build a simple web application using FastAPI and convert it into an MCP server, enabling your L
 Dia-1.6B TTS : Best Text-to-Dialogue Generation Model - Analytics VidhyaMay 11, 2025 am 10:27 AM
Dia-1.6B TTS : Best Text-to-Dialogue Generation Model - Analytics VidhyaMay 11, 2025 am 10:27 AMExplore Dia-1.6B: A groundbreaking text-to-speech model developed by two undergraduates with zero funding! This 1.6 billion parameter model generates remarkably realistic speech, including nonverbal cues like laughter and sneezes. This article guide
 3 Ways AI Can Make Mentorship More Meaningful Than EverMay 10, 2025 am 11:17 AM
3 Ways AI Can Make Mentorship More Meaningful Than EverMay 10, 2025 am 11:17 AMI wholeheartedly agree. My success is inextricably linked to the guidance of my mentors. Their insights, particularly regarding business management, formed the bedrock of my beliefs and practices. This experience underscores my commitment to mentor
 AI Unearths New Potential In The Mining IndustryMay 10, 2025 am 11:16 AM
AI Unearths New Potential In The Mining IndustryMay 10, 2025 am 11:16 AMAI Enhanced Mining Equipment The mining operation environment is harsh and dangerous. Artificial intelligence systems help improve overall efficiency and security by removing humans from the most dangerous environments and enhancing human capabilities. Artificial intelligence is increasingly used to power autonomous trucks, drills and loaders used in mining operations. These AI-powered vehicles can operate accurately in hazardous environments, thereby increasing safety and productivity. Some companies have developed autonomous mining vehicles for large-scale mining operations. Equipment operating in challenging environments requires ongoing maintenance. However, maintenance can keep critical devices offline and consume resources. More precise maintenance means increased uptime for expensive and necessary equipment and significant cost savings. AI-driven
 Why AI Agents Will Trigger The Biggest Workplace Revolution In 25 YearsMay 10, 2025 am 11:15 AM
Why AI Agents Will Trigger The Biggest Workplace Revolution In 25 YearsMay 10, 2025 am 11:15 AMMarc Benioff, Salesforce CEO, predicts a monumental workplace revolution driven by AI agents, a transformation already underway within Salesforce and its client base. He envisions a shift from traditional markets to a vastly larger market focused on
 AI HR Is Going To Rock Our Worlds As AI Adoption SoarsMay 10, 2025 am 11:14 AM
AI HR Is Going To Rock Our Worlds As AI Adoption SoarsMay 10, 2025 am 11:14 AMThe Rise of AI in HR: Navigating a Workforce with Robot Colleagues The integration of AI into human resources (HR) is no longer a futuristic concept; it's rapidly becoming the new reality. This shift impacts both HR professionals and employees, dem


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

SublimeText3 Linux new version
SublimeText3 Linux latest version

WebStorm Mac version
Useful JavaScript development tools

