

 Web Front-endJS TutorialClean up HTML Content for Retrieval-Augmented Generation with Readability.js
Web Front-endJS TutorialClean up HTML Content for Retrieval-Augmented Generation with Readability.jsClean up HTML Content for Retrieval-Augmented Generation with Readability.js

Web scraping is a common method for gathering content for your retrieval-augmented generation (RAG) application. However, parsing web page content can be challenging.
Mozilla's open-source Readability.js library offers a convenient solution for extracting only the essential parts of a web page. Let's explore its integration into a data ingestion pipeline for a RAG application.
Extracting Unstructured Data from Web Pages
Web pages are rich sources of unstructured data, ideal for RAG applications. However, web pages often contain irrelevant information such as headers, sidebars, and footers. While useful for browsing, this extra content detracts from the page's main subject.
For optimal RAG data, irrelevant content must be removed. While tools like Cheerio can parse HTML based on a site's known structure, this approach is inefficient for scraping diverse website layouts. A robust method is needed to extract only relevant content.
Leveraging Reader View Functionality
Most browsers include a reader view that removes all but the article title and content. The following image illustrates the difference between standard browsing and reader mode applied to a DataStax blog post:

Mozilla provides Readability.js, the library behind Firefox's reader mode, as a standalone open-source module. This allows us to integrate Readability.js into a data pipeline to remove irrelevant content and improve scraping results.
Scraping Data with Node.js and Readability.js
Let's illustrate scraping article content from a previous blog post about creating vector embeddings in Node.js. The following JavaScript code retrieves the page's HTML:
const html = await fetch( "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js" ).then((res) => res.text()); console.log(html);
This includes all HTML, including navigation, footers, and other elements common on websites.
Alternatively, you could use Cheerio to select specific elements:
npm install cheerio
import * as cheerio from "cheerio";
const html = await fetch(
"https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js"
).then((res) => res.text());
const $ = cheerio.load(html);
console.log($("h1").text(), "\n");
console.log($("section#blog-content > div:first-child").text());
This yields the title and article text. However, this approach relies on knowing the HTML structure, which is not always feasible.
A better approach involves installing Readability.js and jsdom:
npm install @mozilla/readability jsdom
Readability.js operates within a browser environment, requiring jsdom to simulate this in Node.js. We can convert the loaded HTML into a document and use Readability.js to parse the content:
import { Readability } from "@mozilla/readability";
import { JSDOM } from "jsdom";
const url = "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js";
const html = await fetch(url).then((res) => res.text());
const doc = new JSDOM(html, { url });
const reader = new Readability(doc.window.document);
const article = reader.parse();
console.log(article);
The article object contains various parsed elements:
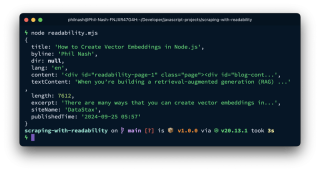
This includes the title, author, excerpt, publication time, and both HTML (content) and plain text (textContent). textContent is ready for chunking, embedding, and storage, while content retains links and images for further processing.
The isProbablyReaderable function helps determine if the document is suitable for Readability.js:
const html = await fetch( "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js" ).then((res) => res.text()); console.log(html);
Unsuitable pages should be flagged for review.
Integrating Readability with LangChain.js
Readability.js integrates seamlessly with LangChain.js. The following example uses LangChain.js to load a page, extract content with MozillaReadabilityTransformer, split text with RecursiveCharacterTextSplitter, create embeddings with OpenAI, and store data in Astra DB.
Required dependencies:
npm install cheerio
You'll need Astra DB credentials ( ASTRA_DB_APPLICATION_TOKEN, ASTRA_DB_API_ENDPOINT) and an OpenAI API key (OPENAI_API_KEY) as environment variables.
Import necessary modules:
import * as cheerio from "cheerio";
const html = await fetch(
"https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js"
).then((res) => res.text());
const $ = cheerio.load(html);
console.log($("h1").text(), "\n");
console.log($("section#blog-content > div:first-child").text());
Initialize components:
npm install @mozilla/readability jsdom
Load, transform, split, embed, and store documents:
import { Readability } from "@mozilla/readability";
import { JSDOM } from "jsdom";
const url = "https://www.datastax.com/blog/how-to-create-vector-embeddings-in-node-js";
const html = await fetch(url).then((res) => res.text());
const doc = new JSDOM(html, { url });
const reader = new Readability(doc.window.document);
const article = reader.parse();
console.log(article);
Improved Web Scraping Accuracy with Readability.js
Readability.js, a robust library powering Firefox's reader mode, efficiently extracts relevant data from web pages, improving RAG data quality. It can be used directly or via LangChain.js's MozillaReadabilityTransformer.
This is just the initial stage of your ingestion pipeline. Chunking, embedding, and Astra DB storage are subsequent steps in building your RAG application.
Do you employ other methods for cleaning web content in your RAG applications? Share your techniques!
The above is the detailed content of Clean up HTML Content for Retrieval-Augmented Generation with Readability.js. For more information, please follow other related articles on the PHP Chinese website!

 JavaScript Comments: A Guide to Using // and /* */May 13, 2025 pm 03:49 PM
JavaScript Comments: A Guide to Using // and /* */May 13, 2025 pm 03:49 PMJavaScriptusestwotypesofcomments:single-line(//)andmulti-line(//).1)Use//forquicknotesorsingle-lineexplanations.2)Use//forlongerexplanationsorcommentingoutblocksofcode.Commentsshouldexplainthe'why',notthe'what',andbeplacedabovetherelevantcodeforclari
 Python vs. JavaScript: A Comparative Analysis for DevelopersMay 09, 2025 am 12:22 AM
Python vs. JavaScript: A Comparative Analysis for DevelopersMay 09, 2025 am 12:22 AMThe main difference between Python and JavaScript is the type system and application scenarios. 1. Python uses dynamic types, suitable for scientific computing and data analysis. 2. JavaScript adopts weak types and is widely used in front-end and full-stack development. The two have their own advantages in asynchronous programming and performance optimization, and should be decided according to project requirements when choosing.
 Python vs. JavaScript: Choosing the Right Tool for the JobMay 08, 2025 am 12:10 AM
Python vs. JavaScript: Choosing the Right Tool for the JobMay 08, 2025 am 12:10 AMWhether to choose Python or JavaScript depends on the project type: 1) Choose Python for data science and automation tasks; 2) Choose JavaScript for front-end and full-stack development. Python is favored for its powerful library in data processing and automation, while JavaScript is indispensable for its advantages in web interaction and full-stack development.
 Python and JavaScript: Understanding the Strengths of EachMay 06, 2025 am 12:15 AM
Python and JavaScript: Understanding the Strengths of EachMay 06, 2025 am 12:15 AMPython and JavaScript each have their own advantages, and the choice depends on project needs and personal preferences. 1. Python is easy to learn, with concise syntax, suitable for data science and back-end development, but has a slow execution speed. 2. JavaScript is everywhere in front-end development and has strong asynchronous programming capabilities. Node.js makes it suitable for full-stack development, but the syntax may be complex and error-prone.
 JavaScript's Core: Is It Built on C or C ?May 05, 2025 am 12:07 AM
JavaScript's Core: Is It Built on C or C ?May 05, 2025 am 12:07 AMJavaScriptisnotbuiltonCorC ;it'saninterpretedlanguagethatrunsonenginesoftenwritteninC .1)JavaScriptwasdesignedasalightweight,interpretedlanguageforwebbrowsers.2)EnginesevolvedfromsimpleinterpreterstoJITcompilers,typicallyinC ,improvingperformance.
 JavaScript Applications: From Front-End to Back-EndMay 04, 2025 am 12:12 AM
JavaScript Applications: From Front-End to Back-EndMay 04, 2025 am 12:12 AMJavaScript can be used for front-end and back-end development. The front-end enhances the user experience through DOM operations, and the back-end handles server tasks through Node.js. 1. Front-end example: Change the content of the web page text. 2. Backend example: Create a Node.js server.
 Python vs. JavaScript: Which Language Should You Learn?May 03, 2025 am 12:10 AM
Python vs. JavaScript: Which Language Should You Learn?May 03, 2025 am 12:10 AMChoosing Python or JavaScript should be based on career development, learning curve and ecosystem: 1) Career development: Python is suitable for data science and back-end development, while JavaScript is suitable for front-end and full-stack development. 2) Learning curve: Python syntax is concise and suitable for beginners; JavaScript syntax is flexible. 3) Ecosystem: Python has rich scientific computing libraries, and JavaScript has a powerful front-end framework.
 JavaScript Frameworks: Powering Modern Web DevelopmentMay 02, 2025 am 12:04 AM
JavaScript Frameworks: Powering Modern Web DevelopmentMay 02, 2025 am 12:04 AMThe power of the JavaScript framework lies in simplifying development, improving user experience and application performance. When choosing a framework, consider: 1. Project size and complexity, 2. Team experience, 3. Ecosystem and community support.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

VSCode Windows 64-bit Download
A free and powerful IDE editor launched by Microsoft

SAP NetWeaver Server Adapter for Eclipse
Integrate Eclipse with SAP NetWeaver application server.

SecLists
SecLists is the ultimate security tester's companion. It is a collection of various types of lists that are frequently used during security assessments, all in one place. SecLists helps make security testing more efficient and productive by conveniently providing all the lists a security tester might need. List types include usernames, passwords, URLs, fuzzing payloads, sensitive data patterns, web shells, and more. The tester can simply pull this repository onto a new test machine and he will have access to every type of list he needs.

Atom editor mac version download
The most popular open source editor

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

