



A practical guide to building a data engineering ETL pipeline. This guide provides a hands-on approach to understanding and implementing data engineering fundamentals, covering storage, processing, automation, and monitoring.
What is Data Engineering?
Data engineering focuses on organizing, processing, and automating data workflows to transform raw data into valuable insights for analysis and decision-making. This guide covers:
- Data Storage: Defining where and how data is stored.
- Data Processing: Techniques for cleaning and transforming raw data.
- Workflow Automation: Implementing seamless and efficient workflow execution.
- System Monitoring: Ensuring the reliability and smooth operation of the entire data pipeline.
Let's explore each stage!
Setting Up Your Development Environment
Before we begin, ensure you have the following:
-
Environment Setup:
- A Unix-based system (macOS) or Windows Subsystem for Linux (WSL).
- Python 3.11 (or later) installed.
- PostgreSQL database installed and running locally.
-
Prerequisites:
- Basic command-line proficiency.
- Fundamental Python programming knowledge.
- Administrative privileges for software installation and configuration.
-
Architectural Overview:


The diagram illustrates the interaction between the pipeline components. This modular design leverages the strengths of each tool: Airflow for workflow orchestration, Spark for distributed data processing, and PostgreSQL for structured data storage.
-
Installing Necessary Tools:
- PostgreSQL:
brew update brew install postgresql
- PySpark:
brew install apache-spark
- Airflow:
python -m venv airflow_env source airflow_env/bin/activate # macOS/Linux pip install "apache-airflow[postgres]==" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.10.4/constraints-3.11.txt" airflow db migrate
- PostgreSQL:
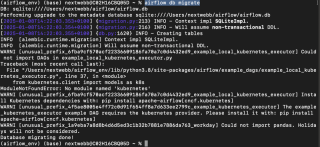
With the environment prepared, let's delve into each component.
1. Data Storage: Databases and File Systems
Data storage is the foundation of any data engineering pipeline. We'll consider two primary categories:
-
Databases: Efficiently organized data storage with features like search, replication, and indexing. Examples include:
- SQL Databases: For structured data (e.g., PostgreSQL, MySQL).
- NoSQL Databases: For schema-less data (e.g., MongoDB, Redis).
- File Systems: Suitable for unstructured data, offering fewer features than databases.
Setting Up PostgreSQL
- Start the PostgreSQL Service:
brew update brew install postgresql

- Create a Database, Connect, and Create a Table:
brew install apache-spark
- Insert Sample Data:
python -m venv airflow_env source airflow_env/bin/activate # macOS/Linux pip install "apache-airflow[postgres]==" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.10.4/constraints-3.11.txt" airflow db migrate
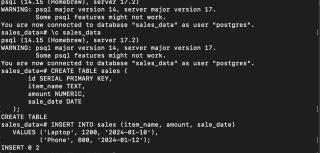
Your data is now securely stored in PostgreSQL.
2. Data Processing: PySpark and Distributed Computing
Data processing frameworks transform raw data into actionable insights. Apache Spark, with its distributed computing capabilities, is a popular choice.
-
Processing Modes:
- Batch Processing: Processes data in fixed-size batches.
- Stream Processing: Processes data in real-time.
- Common Tools: Apache Spark, Flink, Kafka, Hive.
Processing Data with PySpark
- Install Java and PySpark:
brew services start postgresql
- Load Data from a CSV File:
Create a sales.csv file with the following data:
CREATE DATABASE sales_data;
\c sales_data
CREATE TABLE sales (
id SERIAL PRIMARY KEY,
item_name TEXT,
amount NUMERIC,
sale_date DATE
);
Use the following Python script to load and process the data:
INSERT INTO sales (item_name, amount, sale_date)
VALUES ('Laptop', 1200, '2024-01-10'),
('Phone', 800, '2024-01-12');

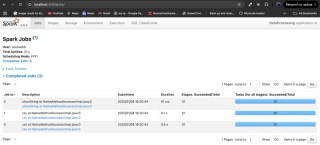
- Filter High-Value Sales:
brew install openjdk@11 && brew install apache-spark


-
Setup Postgres DB driver: Download the PostgreSQL JDBC driver if needed and update the path in the script below.
-
Save Processed Data to PostgreSQL:
brew update brew install postgresql


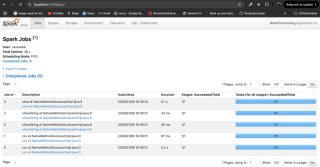
Data processing with Spark is complete.
3. Workflow Automation: Airflow
Automation streamlines workflow management using scheduling and dependency definition. Tools like Airflow, Oozie, and Luigi facilitate this.
Automating ETL with Airflow
- Initialize Airflow:
brew install apache-spark


- Create a Workflow (DAG):
python -m venv airflow_env source airflow_env/bin/activate # macOS/Linux pip install "apache-airflow[postgres]==" --constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.10.4/constraints-3.11.txt" airflow db migrate
This DAG runs daily, executes the PySpark script, and includes a verification step. Email alerts are sent on failure.
-
Monitor the Workflow: Place the DAG file in Airflow's
dags/directory, restart Airflow services, and monitor via the Airflow UI athttp://localhost:8080.
4. System Monitoring
Monitoring ensures pipeline reliability. Airflow's alerting, or integration with tools like Grafana and Prometheus, are effective monitoring strategies. Use the Airflow UI to check task statuses and logs.
Conclusion
You've learned to set up data storage, process data using PySpark, automate workflows with Airflow, and monitor your system. Data engineering is a crucial field, and this guide provides a strong foundation for further exploration. Remember to consult the provided references for more in-depth information.
The above is the detailed content of Data Engineering Foundations: A Hands-On Guide. For more information, please follow other related articles on the PHP Chinese website!

 What are the alternatives to concatenate two lists in Python?May 09, 2025 am 12:16 AM
What are the alternatives to concatenate two lists in Python?May 09, 2025 am 12:16 AMThere are many methods to connect two lists in Python: 1. Use operators, which are simple but inefficient in large lists; 2. Use extend method, which is efficient but will modify the original list; 3. Use the = operator, which is both efficient and readable; 4. Use itertools.chain function, which is memory efficient but requires additional import; 5. Use list parsing, which is elegant but may be too complex. The selection method should be based on the code context and requirements.
 Python: Efficient Ways to Merge Two ListsMay 09, 2025 am 12:15 AM
Python: Efficient Ways to Merge Two ListsMay 09, 2025 am 12:15 AMThere are many ways to merge Python lists: 1. Use operators, which are simple but not memory efficient for large lists; 2. Use extend method, which is efficient but will modify the original list; 3. Use itertools.chain, which is suitable for large data sets; 4. Use * operator, merge small to medium-sized lists in one line of code; 5. Use numpy.concatenate, which is suitable for large data sets and scenarios with high performance requirements; 6. Use append method, which is suitable for small lists but is inefficient. When selecting a method, you need to consider the list size and application scenarios.
 Compiled vs Interpreted Languages: pros and consMay 09, 2025 am 12:06 AM
Compiled vs Interpreted Languages: pros and consMay 09, 2025 am 12:06 AMCompiledlanguagesofferspeedandsecurity,whileinterpretedlanguagesprovideeaseofuseandportability.1)CompiledlanguageslikeC arefasterandsecurebuthavelongerdevelopmentcyclesandplatformdependency.2)InterpretedlanguageslikePythonareeasiertouseandmoreportab
 Python: For and While Loops, the most complete guideMay 09, 2025 am 12:05 AM
Python: For and While Loops, the most complete guideMay 09, 2025 am 12:05 AMIn Python, a for loop is used to traverse iterable objects, and a while loop is used to perform operations repeatedly when the condition is satisfied. 1) For loop example: traverse the list and print the elements. 2) While loop example: guess the number game until you guess it right. Mastering cycle principles and optimization techniques can improve code efficiency and reliability.
 Python concatenate lists into a stringMay 09, 2025 am 12:02 AM
Python concatenate lists into a stringMay 09, 2025 am 12:02 AMTo concatenate a list into a string, using the join() method in Python is the best choice. 1) Use the join() method to concatenate the list elements into a string, such as ''.join(my_list). 2) For a list containing numbers, convert map(str, numbers) into a string before concatenating. 3) You can use generator expressions for complex formatting, such as ','.join(f'({fruit})'forfruitinfruits). 4) When processing mixed data types, use map(str, mixed_list) to ensure that all elements can be converted into strings. 5) For large lists, use ''.join(large_li
 Python's Hybrid Approach: Compilation and Interpretation CombinedMay 08, 2025 am 12:16 AM
Python's Hybrid Approach: Compilation and Interpretation CombinedMay 08, 2025 am 12:16 AMPythonusesahybridapproach,combiningcompilationtobytecodeandinterpretation.1)Codeiscompiledtoplatform-independentbytecode.2)BytecodeisinterpretedbythePythonVirtualMachine,enhancingefficiencyandportability.
 Learn the Differences Between Python's 'for' and 'while' LoopsMay 08, 2025 am 12:11 AM
Learn the Differences Between Python's 'for' and 'while' LoopsMay 08, 2025 am 12:11 AMThekeydifferencesbetweenPython's"for"and"while"loopsare:1)"For"loopsareidealforiteratingoversequencesorknowniterations,while2)"while"loopsarebetterforcontinuinguntilaconditionismetwithoutpredefinediterations.Un
 Python concatenate lists with duplicatesMay 08, 2025 am 12:09 AM
Python concatenate lists with duplicatesMay 08, 2025 am 12:09 AMIn Python, you can connect lists and manage duplicate elements through a variety of methods: 1) Use operators or extend() to retain all duplicate elements; 2) Convert to sets and then return to lists to remove all duplicate elements, but the original order will be lost; 3) Use loops or list comprehensions to combine sets to remove duplicate elements and maintain the original order.


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

MantisBT
Mantis is an easy-to-deploy web-based defect tracking tool designed to aid in product defect tracking. It requires PHP, MySQL and a web server. Check out our demo and hosting services.

Atom editor mac version download
The most popular open source editor

MinGW - Minimalist GNU for Windows
This project is in the process of being migrated to osdn.net/projects/mingw, you can continue to follow us there. MinGW: A native Windows port of the GNU Compiler Collection (GCC), freely distributable import libraries and header files for building native Windows applications; includes extensions to the MSVC runtime to support C99 functionality. All MinGW software can run on 64-bit Windows platforms.

Dreamweaver Mac version
Visual web development tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

