


I recently tried to implement a DQN based Chess Agent.
Now, anyone who knows how DQNs and Chess works would tell you that's a dumb idea.
And...it was, but as a beginner I enjoyed it nevertheless. In this article I'll share the insights I learned while working on this.
Understanding the Environment.
Before I started implementing the Agent itself, I had to familiarize myself with the environment I'll be using and make a custom wrapper on top of it so that it can interact with the Agent during training.
-
I used the chess environment from the kaggle_environments library.
from kaggle_environments import make env = make("chess", debug=True)
-
I also used Chessnut, which is a lightweight python library that helps parse and validate chess games.
from Chessnut import Game initial_fen = env.state[0]['observation']['board'] game=Game(env.state[0]['observation']['board'])
In this environment, the state of the board is stored in the FEN format.

It provides a compact way to represent all the pieces on the board and the currently active player. However, since I planned on feeding the input to a neural network, I had to modify the representation of the state.
Converting FEN to Matrix format
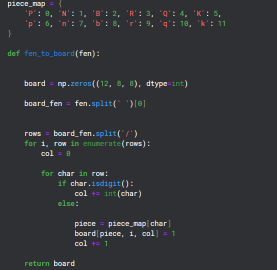
Since there are 12 different types of pieces on a board, I created 12 channels of 8x8 grids to represent the state of each of those types on the board.
Creating a Wrapper for the Environment
class EnvCust:
def __init__(self):
self.env = make("chess", debug=True)
self.game=Game(env.state[0]['observation']['board'])
print(self.env.state[0]['observation']['board'])
self.action_space=game.get_moves();
self.obs_space=(self.env.state[0]['observation']['board'])
def get_action(self):
return Game(self.env.state[0]['observation']['board']).get_moves();
def get_obs_space(self):
return fen_to_board(self.env.state[0]['observation']['board'])
def step(self,action):
reward=0
g=Game(self.env.state[0]['observation']['board']);
if(g.board.get_piece(Game.xy2i(action[2:4]))=='q'):
reward=7
elif g.board.get_piece(Game.xy2i(action[2:4]))=='n' or g.board.get_piece(Game.xy2i(action[2:4]))=='b' or g.board.get_piece(Game.xy2i(action[2:4]))=='r':
reward=4
elif g.board.get_piece(Game.xy2i(action[2:4]))=='P':
reward=2
g=Game(self.env.state[0]['observation']['board']);
g.apply_move(action)
done=False
if(g.status==2):
done=True
reward=10
elif g.status == 1:
done = True
reward = -5
self.env.step([action,'None'])
self.action_space=list(self.get_action())
if(self.action_space==[]):
done=True
else:
self.env.step(['None',random.choice(self.action_space)])
g=Game(self.env.state[0]['observation']['board']);
if g.status==2:
reward=-10
done=True
self.action_space=list(self.get_action())
return self.env.state[0]['observation']['board'],reward,done
The point of this wrapper was to provide a reward policy for the agent and a step function which is used to interact with the environment during training.
Chessnut was useful in getting information like the legal moves possible at current state of the board and also to recognize Checkmates during the game.
I tried to create a reward policy to give positive points for checkmates and taking out enemy pieces while negative points for losing the game.
Creating a Replay Buffer
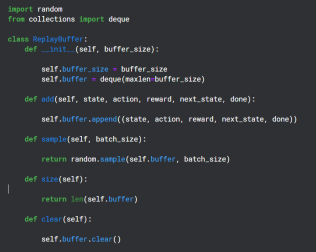
Replay Buffer is used during the training period to save the (state,action,reward,next state) output by the Q-Network and later used randomly for backpropagation of the Target Network
Auxiliary Functions
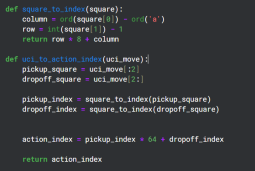

Chessnut returns legal action in UCI format which looks like 'a2a3', however to interact with the Neural Network I converted each action into a distinct index using a basic pattern. There are total 64 Squares, so I decided to have 64*64 unique indexes for each move.
I know that not all of the 64*64 moves would be legal, but I could handle legality using Chessnut and the pattern was simple enough.
Neural Network Structure
from kaggle_environments import make
env = make("chess", debug=True)
This Neural Network uses the Convolutional Layers to take in the 12 channel input and also uses the valid action indexes to filter out the reward output prediction.
Implementing the Agent
from Chessnut import Game initial_fen = env.state[0]['observation']['board'] game=Game(env.state[0]['observation']['board'])
This was obviously a very basic model which had no chance of actually performing well (And it didn't), but it did help me understand how DQNs work a little better.

The above is the detailed content of Building a Chess Agent using DQN. For more information, please follow other related articles on the PHP Chinese website!

 What is Python Switch Statement?Apr 30, 2025 pm 02:08 PM
What is Python Switch Statement?Apr 30, 2025 pm 02:08 PMThe article discusses Python's new "match" statement introduced in version 3.10, which serves as an equivalent to switch statements in other languages. It enhances code readability and offers performance benefits over traditional if-elif-el
 What are Exception Groups in Python?Apr 30, 2025 pm 02:07 PM
What are Exception Groups in Python?Apr 30, 2025 pm 02:07 PMException Groups in Python 3.11 allow handling multiple exceptions simultaneously, improving error management in concurrent scenarios and complex operations.
 What are Function Annotations in Python?Apr 30, 2025 pm 02:06 PM
What are Function Annotations in Python?Apr 30, 2025 pm 02:06 PMFunction annotations in Python add metadata to functions for type checking, documentation, and IDE support. They enhance code readability, maintenance, and are crucial in API development, data science, and library creation.
 What are unit tests in Python?Apr 30, 2025 pm 02:05 PM
What are unit tests in Python?Apr 30, 2025 pm 02:05 PMThe article discusses unit tests in Python, their benefits, and how to write them effectively. It highlights tools like unittest and pytest for testing.
 What are Access Specifiers in Python?Apr 30, 2025 pm 02:03 PM
What are Access Specifiers in Python?Apr 30, 2025 pm 02:03 PMArticle discusses access specifiers in Python, which use naming conventions to indicate visibility of class members, rather than strict enforcement.
 What is __init__() in Python and how does self play a role in it?Apr 30, 2025 pm 02:02 PM
What is __init__() in Python and how does self play a role in it?Apr 30, 2025 pm 02:02 PMArticle discusses Python's \_\_init\_\_() method and self's role in initializing object attributes. Other class methods and inheritance's impact on \_\_init\_\_() are also covered.
 What is the difference between @classmethod, @staticmethod and instance methods in Python?Apr 30, 2025 pm 02:01 PM
What is the difference between @classmethod, @staticmethod and instance methods in Python?Apr 30, 2025 pm 02:01 PMThe article discusses the differences between @classmethod, @staticmethod, and instance methods in Python, detailing their properties, use cases, and benefits. It explains how to choose the right method type based on the required functionality and da
 How do you append elements to a Python array?Apr 30, 2025 am 12:19 AM
How do you append elements to a Python array?Apr 30, 2025 am 12:19 AMInPython,youappendelementstoalistusingtheappend()method.1)Useappend()forsingleelements:my_list.append(4).2)Useextend()or =formultipleelements:my_list.extend(another_list)ormy_list =[4,5,6].3)Useinsert()forspecificpositions:my_list.insert(1,5).Beaware


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

SublimeText3 Chinese version
Chinese version, very easy to use

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Safe Exam Browser
Safe Exam Browser is a secure browser environment for taking online exams securely. This software turns any computer into a secure workstation. It controls access to any utility and prevents students from using unauthorized resources.

WebStorm Mac version
Useful JavaScript development tools

PhpStorm Mac version
The latest (2018.2.1) professional PHP integrated development tool

