
Home >Backend Development >C++ >CS- Week 5
CS- Week 5

- Susan SarandonOriginal
- 2024-12-28 11:38:24959browse
Data structures
Information structures are forms of organizing information in memory. There are many ways to organize data in memory.
Abstract data structures are structures that we conceptually imagine. Familiarity with these abstract structures makes it easier to implement data structures in practice in the future.
Stack and Queue
Queue is a form of abstract data structures.
The Queue data structure works according to the FIFO (First In First Out, "the first added element comes out first") rule.
It can be imagined as an example of people standing in line at an attraction: the first person in line gets in first, and the last one gets in last.
Queues:
- Enqueue: add a new element to the end of the queue.
- Dequeue: remove an element from the beginning of the queue.
Stack data structure works according to LIFO (Last In First Out, "the last added element comes out first") rule.
For example, stacking plates in the kitchen: the last plate is taken first.
Stack has the following operations:
- Push: put a new element on the stack.
- Pop: remove an element from the stack.
Array
Array is a method of sequentially storing data in memory. An array can be visualized as:

Memory may contain other values stored by other programs, functions, and variables, as well as redundant values that were previously used and are no longer in use:

If we want to add a new element - 4 - to the array, we need to allocate new memory and move the old array into it. This new memory may be full of garbage values:


The disadvantage of this approach is that the entire array needs to be copied every time a new element is added.
What if we put 4 somewhere else in memory? Then, by definition, this is no longer an array, because 4 is not contiguous with array elements in memory.
Sometimes, programmers allocate more memory than necessary (eg 300 for 30 elements). But this is bad design because it wastes system resources and in most cases the extra memory is unnecessary. Therefore, it is important to allocate memory according to the specific need.
Linked List
Linked List is one of the most powerful data structures in the C programming language. They allow combining values located in different memory regions into a single list. It also allows us to dynamically expand or shrink the list as we wish.

Each node stores two values:
- value;
- is a pointer that holds the memory address of the next node. And the last node contains NULL to indicate that there is no other element after it.

We save the address of the first element of the linked list to a pointer (pointer).

In the C programming language, we can write node as:
typedef struct node
{
int number;
struct node *next;
}
node;
Let's look at the process of creating Linked list:
- We declare node *list:

- allocate memory for node:
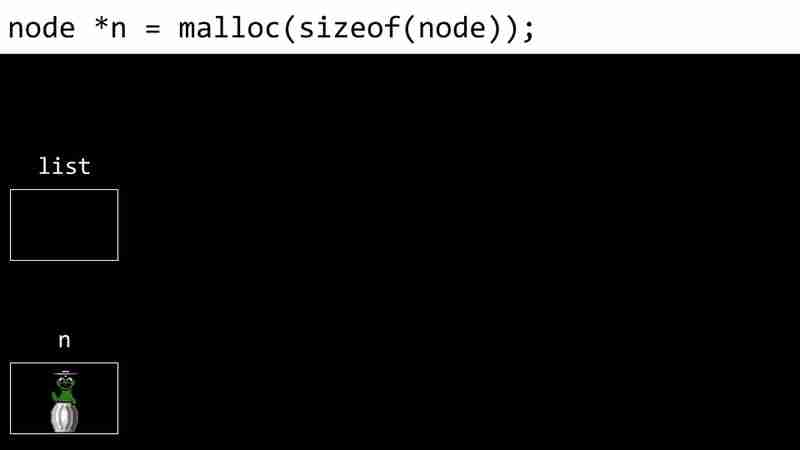
- enter the value of node: n->number = 1:

- We set the next index of the node to NULL: n->next = NULL:

- let's equal the list to:

- In the same order, we create a new node with a value of 2:

- In order to connect both nodes, we set n's next index to list:

- And finally, we set the list to n. Now we have a linked list consisting of two elements:

In the C programming language, we can write the code of this process as follows:
typedef struct node
{
int number;
struct node *next;
}
node;
There are several drawbacks when working with a linked list:
- More memory: for each element, it is necessary to store not only the value of the element itself, but also a pointer to the next element.
- Calling elements by index: in arrays we can call a certain element by index, but in linked list it is impossible. To find the position of a particular element, it is necessary to go through all the elements in sequence, starting with the first element.
Tree
Binary Search Tree (BST) is an information structure that allows efficient storage, search and retrieval of data.
Let us be given a sequence of sorted numbers:

We place the element in the center at the top, values smaller than the element in the center to the left, and larger values to the right:

We connect each element to each other using pointers:

The following code shows how to implement BST:
#include <cs50.h>
#include <stdio.h>
#include <stdlib.h>
typedef struct node
{
int number;
struct node *next;
}
node;
int main(int argc, char *argv[])
{
// Linked list'ni e'lon qilamiz
node *list = NULL;
// Har bir buyruq qatori argumenti uchun
for (int i = 1; i < argc; i++)
{
// Argumentni butun songa o‘tkazamiz
int number = atoi(argv[i]);
// Yangi element uchun xotira ajratamiz
node *n = malloc(sizeof(node));
if (n == NULL)
{
return 1;
}
n->number = number;
n->next = NULL;
// Linked list'ning boshiga node'ni qo‘shamiz
n->next = list;
list = n;
}
// Linked list elementlarini ekranga chiqaramiz
node *ptr = list;
while (ptr != NULL)
{
printf("%i\n", ptr->number);
ptr = ptr->next;
}
// Xotirani bo‘shatamiz
ptr = list;
while (ptr != NULL)
{
node *next = ptr->next;
free(ptr);
ptr = next;
}
}
We allocate memory for each node and its value is stored in number, so each node has left and right indicators. The print_tree function prints each node in sequential recursion from left to right. The free_tree function recursively frees all nodes of the data structure from memory.
Advantages ofBST:
- Dynamism: we can efficiently add or remove elements.
- Search Efficiency: The time taken to search for a given element in BST is O(log n), since half of the tree is excluded from the search in each search.
BST:
- If the balance of the tree is broken (for example, if all elements are placed in a row), the search efficiency drops to O(n).
- Requires to store both left and right pointers for each node, which increases memory consumption on the computer.
Dictionary
Dictionary is like a dictionary book, it contains a word and its definition, its elements key (key) and value has (value).
If we queryDictionary for an element, it returns the element to us in O(1) time. Dictionaries can provide exactly this speed through hashing.
Hashing is the process of converting the data in the input array into a sequence of bits using a special algorithm.
A hash function is an algorithm that generates a string of fixed length bits from a string of arbitrary length.
Hash table is a great combination of arrays and linked lists. We can imagine it as follows:

Collision (Collisions) is when two different inputs produce one hash value. In the image above, the elements that collide are connected as a linked list. By improving the hash function, the probability of collision can be reduced.
A simple example of a hash function is:
typedef struct node
{
int number;
struct node *next;
}
node;
This article uses CS50x 2024 source.
The above is the detailed content of CS- Week 5. For more information, please follow other related articles on the PHP Chinese website!
Related articles
See more- C++ compilation error: A header file is referenced multiple times, how to solve it?
- C++ compilation error: wrong function parameters, how to fix it?
- C++ error: The constructor must be declared in the public area, how to deal with it?
- Process management and thread synchronization in C++
- How to deal with data splitting problems in C++ development