



As a data professional, you deal with immense amounts of data from a variety of sources. This can make data management and analysis a challenge. Luckily, two AWS services can help: AWS Glue and Amazon Athena.
When you integrate these services, you unlock the full potential of data discovery, cataloging, and querying within the AWS ecosystem. Let’s take a look at how they can streamline your data analytics workflow.

What is AWS Glue?
AWS Glue is a serverless managed service that allows you to discover, prepare, move, and integrate data from multiple sources. As a data integration service, AWS Glue gives you the power to manage data in a centralized location without having to manage infrastructure.
What is AWS Glue crawler?
Glue crawlers are automated data discovery tools that scan a data source to classify, group, and catalog the data within it automatically. It then creates new or updates existing tables in your AWS Glue Data Catalog.
What is the Glue Data Catalog?
The AWS Glue Data Catalog is an index of your data’s location, schema, and runtime metrics. You need this information to create and monitor your extract, transform, and load (ETL) jobs.
Why use Amazon Athena and AWS Glue?
Now that we’ve covered the basics of Amazon Athena, AWS Glue, and AWS Glue crawlers, let’s talk about them in a little more depth.
4 main Amazon Athena use cases
Amazon Athena provides a simplified, flexible way to analyze petabytes of data right where they live. For example, Athena can analyze data or build applications from an Amazon Simple Storage Service (S3) data lake and 30 data sources, including on-premises data sources or other cloud systems using SQL or Python.
There are four main Amazon Athena use cases:
Run queries on S3, on-premises data centers, or on other clouds
Prepare data for machine learning models
Use machine learning models in SQL queries or Python to simplify complex tasks, such as anomaly detection, customer cohort analysis, and sales predictions
Perform multicloud analytics (like querying data in Azure Synapse Analytics and then visualizing the results with Amazon QuickSight)
3 key AWS Glue use cases
Now that we’ve covered Amazon Athena, let's talk about AWS Glue. You can do a few different things with AWS Glue.
First, you can use AWS Glue data integration engines, which allow you to get data from a few different sources. This includes Amazon S3, Amazon DynamoDB, and Amazon RDS, as well as databases running on Amazon EC2 (which integrates with AWS Glue studio) and AWS Glue for Ray, Python Shell, and Apache Spark.
Once the data is interfaced and filtered so it can interact with places to load or create data, this list expands to include data from places like Amazon Redshift, data lakes, and data warehouses.
You can also use AWS Glue to run your ETL jobs. These jobs allow you to segregate customer data, protect customer data in transit and at rest, and access customer data only as needed in response to customer requests. When provisioning an ETL job, all you need to do is provide input data sources and output data targets in your virtual private cloud.
The final way you can use AWS Glue is through a data catalog to quickly discover and search multiple AWS datasets without moving the data. Once the data is cataloged, it’s immediately available for search and query using Amazon Athena, Amazon EMR, and Amazon Redshift Spectrums.
Getting started with AWS Glue: How to get data from AWS Glue to Amazon Athena
So, how can you get data from AWS Glue into Amazon Athena? Follow these steps:
Start by uploading data to a data source. The most popular option is an S3 bucket, but DynamoDB tables and Amazon RedShift are also options.
Select your data source and create a classifier if necessary. A classifier reads the data and generates a schema if it recognizes the format. You can create custom classifiers to see different data types.
Create a crawler.
Set up a name for the crawler, then choose your data sources and add any custom classifiers to make sure AWS Glue recognizes the data correctly.
Set up an Identity and Access Management (IAM) role to make sure the crawler can run the processes correctly.
Create a database that will hold the data set. Set when and how often the crawler works to keep your data fresh and up to date.
Run the crawler. This process can take a while depending on how big the dataset is. Once the crawler has successfully run, you’ll see changes to tables in the database.
Now that you’ve completed this process, you can jump over to Amazon Athena and run the queries you need to filter the data and get the results you’re looking for.
The above is the detailed content of How to use AWS Glue crawlers with Amazon Athena. For more information, please follow other related articles on the PHP Chinese website!

 SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询Aug 26, 2022 pm 02:07 PM
SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询Aug 26, 2022 pm 02:07 PM本篇文章给大家带来了关于SQL的相关知识,其中主要介绍了SQL Server使用CROSS APPLY与OUTER APPLY实现连接查询的方法,文中通过示例代码介绍的非常详细,下面一起来看一下,希望对大家有帮助。
 SQL Server解析/操作Json格式字段数据的方法实例Aug 29, 2022 pm 12:00 PM
SQL Server解析/操作Json格式字段数据的方法实例Aug 29, 2022 pm 12:00 PM本篇文章给大家带来了关于SQL server的相关知识,其中主要介绍了SQL SERVER没有自带的解析json函数,需要自建一个函数(表值函数),下面介绍关于SQL Server解析/操作Json格式字段数据的相关资料,希望对大家有帮助。
 聊聊优化sql中order By语句的方法Sep 27, 2022 pm 01:45 PM
聊聊优化sql中order By语句的方法Sep 27, 2022 pm 01:45 PM如何优化sql中的orderBy语句?下面本篇文章给大家介绍一下优化sql中orderBy语句的方法,具有很好的参考价值,希望对大家有所帮助。
 Monaco Editor如何实现SQL和Java代码提示?May 07, 2023 pm 10:13 PM
Monaco Editor如何实现SQL和Java代码提示?May 07, 2023 pm 10:13 PMmonacoeditor创建//创建和设置值if(!this.monacoEditor){this.monacoEditor=monaco.editor.create(this._node,{value:value||code,language:language,...options});this.monacoEditor.onDidChangeModelContent(e=>{constvalue=this.monacoEditor.getValue();//使value和其值保持一致i
 一文搞懂SQL中的开窗函数Sep 02, 2022 pm 04:55 PM
一文搞懂SQL中的开窗函数Sep 02, 2022 pm 04:55 PM本篇文章给大家带来了关于SQL server的相关知识,开窗函数也叫分析函数有两类,一类是聚合开窗函数,一类是排序开窗函数,下面这篇文章主要给大家介绍了关于SQL中开窗函数的相关资料,文中通过实例代码介绍的非常详细,需要的朋友可以参考下。
 如何使用exp进行SQL报错注入May 12, 2023 am 10:16 AM
如何使用exp进行SQL报错注入May 12, 2023 am 10:16 AM0x01前言概述小编又在MySQL中发现了一个Double型数据溢出。当我们拿到MySQL里的函数时,小编比较感兴趣的是其中的数学函数,它们也应该包含一些数据类型来保存数值。所以小编就跑去测试看哪些函数会出现溢出错误。然后小编发现,当传递一个大于709的值时,函数exp()就会引起一个溢出错误。mysql>selectexp(709);+-----------------------+|exp(709)|+-----------------------+|8.218407461554972
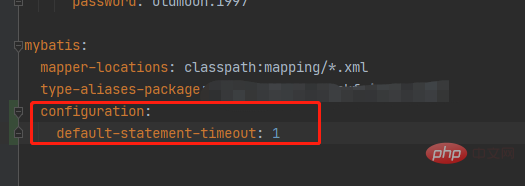 springboot配置mybatis的sql执行超时时间怎么解决May 15, 2023 pm 06:10 PM
springboot配置mybatis的sql执行超时时间怎么解决May 15, 2023 pm 06:10 PM当某些sql因为不知名原因堵塞时,为了不影响后台服务运行,想要给sql增加执行时间限制,超时后就抛异常,保证后台线程不会因为sql堵塞而堵塞。一、yml全局配置单数据源可以,多数据源时会失效二、java配置类配置成功抛出超时异常。importcom.alibaba.druid.pool.DruidDataSource;importcom.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceBuilder;importorg.apache.
 Monaco Editor怎么实现SQL和Java代码提示May 11, 2023 pm 05:31 PM
Monaco Editor怎么实现SQL和Java代码提示May 11, 2023 pm 05:31 PMmonacoeditor创建//创建和设置值if(!this.monacoEditor){this.monacoEditor=monaco.editor.create(this._node,{value:value||code,language:language,...options});this.monacoEditor.onDidChangeModelContent(e=>{constvalue=this.monacoEditor.getValue();//使value和其值保持一致i


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Zend Studio 13.0.1
Powerful PHP integrated development environment

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Dreamweaver Mac version
Visual web development tools

Atom editor mac version download
The most popular open source editor

mPDF
mPDF is a PHP library that can generate PDF files from UTF-8 encoded HTML. The original author, Ian Back, wrote mPDF to output PDF files "on the fly" from his website and handle different languages. It is slower than original scripts like HTML2FPDF and produces larger files when using Unicode fonts, but supports CSS styles etc. and has a lot of enhancements. Supports almost all languages, including RTL (Arabic and Hebrew) and CJK (Chinese, Japanese and Korean). Supports nested block-level elements (such as P, DIV),

