



1813. Sentence Similarity III
Difficulty: Medium
Topics: Array, Two Pointers, String
You are given two strings sentence1 and sentence2, each representing a sentence composed of words. A sentence is a list of words that are separated by a single space with no leading or trailing spaces. Each word consists of only uppercase and lowercase English characters.
Two sentences s1 and s2 are considered similar if it is possible to insert an arbitrary sentence (possibly empty) inside one of these sentences such that the two sentences become equal. Note that the inserted sentence must be separated from existing words by spaces.
For example,
- s1 = "Hello Jane" and s2 = "Hello my name is Jane" can be made equal by inserting "my name is" between "Hello" and "Jane" in s1.
- s1 = "Frog cool" and s2 = "Frogs are cool" are not similar, since although there is a sentence "s are" inserted into s1, it is not separated from "Frog" by a space.
Given two sentences sentence1 and sentence2, return true if sentence1 and sentence2 are similar. Otherwise, return false.
Example 1:
- Input: sentence1 = "My name is Haley", sentence2 = "My Haley"
- Output: true
- Explanation: sentence2 can be turned to sentence1 by inserting "name is" between "My" and "Haley".
Example 2:
- Input: sentence1 = "of", sentence2 = "A lot of words"
- Output: false
- Explanation: No single sentence can be inserted inside one of the sentences to make it equal to the other.
Example 3:
- Input: sentence1 = "Eating right now", sentence2 = "Eating"
- Output: true
- Explanation: sentence2 can be turned to sentence1 by inserting "right now" at the end of the sentence.
Constraints:
- 1
- sentence1 and sentence2 consist of lowercase and uppercase English letters and spaces.
- The words in sentence1 and sentence2 are separated by a single space.
Hint:
- One way to look at it is to find one sentence as a concatenation of a prefix and suffix from the other sentence.
- Get the longest common prefix between them and the longest common suffix.
Solution:
We can approach it by comparing the longest common prefix and suffix of both sentences. If the words in the remaining part of one sentence are completely contained within the other sentence (possibly empty), then the sentences can be considered similar.
Steps:
- Split both sentences into arrays of words.
- Use two pointers to compare the longest common prefix from the start of both arrays.
- Use another two pointers to compare the longest common suffix from the end of both arrays.
- After comparing the common prefix and suffix, if the remaining words in one of the sentences form an empty array (meaning they have all been matched), then the sentences are considered similar.
Let's implement this solution in PHP: 1813. Sentence Similarity III
<p><?php <br> /**</p>
- @param String $sentence1
- @param String $sentence2
- @return Boolean
/
function areSentencesSimilar($sentence1, $sentence2) {
...
...
...
/*
- go to ./solution.php */ }
// Test examples
$sentence1 = "My name is Haley";
$sentence2 = "My Haley";
echo areSentencesSimilar($sentence1, $sentence2) ? 'true' : 'false'; // Output: true
$sentence1 = "of";
$sentence2 = "A lot of words";
echo areSentencesSimilar($sentence1, $sentence2) ? 'true' : 'false'; // Output: false
$sentence1 = "Eating right now";
$sentence2 = "Eating";
echo areSentencesSimilar($sentence1, $sentence2) ? 'true' : 'false'; // Output: true
?>
Explanation:
- Splitting sentences into words: We use explode() to split the sentence strings into arrays of words.
- Common prefix comparison: We iterate over both arrays from the start and compare corresponding words. The loop continues as long as the words match.
- Common suffix comparison: We compare the words from the end of both arrays, again using a loop to check for matching words.
- Final check: After processing the common prefix and suffix, we check if the number of words that have been matched (prefix suffix) covers all the words in the shorter sentence. If so, the sentences can be considered similar.
Time Complexity:
- The time complexity is O(n m), where n and m are the lengths of sentence1 and sentence2 respectively. This is because we process the words in both sentences only once while checking the common prefix and suffix.
This solution should work efficiently given the constraints.
Contact Links
Wenn Sie diese Serie hilfreich fanden, denken Sie bitte darüber nach, dem Repository einen Stern auf GitHub zu geben oder den Beitrag in Ihren bevorzugten sozialen Netzwerken zu teilen? Ihre Unterstützung würde mir sehr viel bedeuten!
Wenn Sie weitere hilfreiche Inhalte wie diesen wünschen, folgen Sie mir gerne:
- GitHub
The above is the detailed content of Sentence Similarity III. For more information, please follow other related articles on the PHP Chinese website!

 Working with Flash Session Data in LaravelMar 12, 2025 pm 05:08 PM
Working with Flash Session Data in LaravelMar 12, 2025 pm 05:08 PMLaravel simplifies handling temporary session data using its intuitive flash methods. This is perfect for displaying brief messages, alerts, or notifications within your application. Data persists only for the subsequent request by default: $request-
 cURL in PHP: How to Use the PHP cURL Extension in REST APIsMar 14, 2025 am 11:42 AM
cURL in PHP: How to Use the PHP cURL Extension in REST APIsMar 14, 2025 am 11:42 AMThe PHP Client URL (cURL) extension is a powerful tool for developers, enabling seamless interaction with remote servers and REST APIs. By leveraging libcurl, a well-respected multi-protocol file transfer library, PHP cURL facilitates efficient execution of various network protocols, including HTTP, HTTPS, and FTP. This extension offers granular control over HTTP requests, supports multiple concurrent operations, and provides built-in security features.
 Simplified HTTP Response Mocking in Laravel TestsMar 12, 2025 pm 05:09 PM
Simplified HTTP Response Mocking in Laravel TestsMar 12, 2025 pm 05:09 PMLaravel provides concise HTTP response simulation syntax, simplifying HTTP interaction testing. This approach significantly reduces code redundancy while making your test simulation more intuitive. The basic implementation provides a variety of response type shortcuts: use Illuminate\Support\Facades\Http; Http::fake([ 'google.com' => 'Hello World', 'github.com' => ['foo' => 'bar'], 'forge.laravel.com' =>
 12 Best PHP Chat Scripts on CodeCanyonMar 13, 2025 pm 12:08 PM
12 Best PHP Chat Scripts on CodeCanyonMar 13, 2025 pm 12:08 PMDo you want to provide real-time, instant solutions to your customers' most pressing problems? Live chat lets you have real-time conversations with customers and resolve their problems instantly. It allows you to provide faster service to your custom
 Explain the concept of late static binding in PHP.Mar 21, 2025 pm 01:33 PM
Explain the concept of late static binding in PHP.Mar 21, 2025 pm 01:33 PMArticle discusses late static binding (LSB) in PHP, introduced in PHP 5.3, allowing runtime resolution of static method calls for more flexible inheritance.Main issue: LSB vs. traditional polymorphism; LSB's practical applications and potential perfo
 PHP Logging: Best Practices for PHP Log AnalysisMar 10, 2025 pm 02:32 PM
PHP Logging: Best Practices for PHP Log AnalysisMar 10, 2025 pm 02:32 PMPHP logging is essential for monitoring and debugging web applications, as well as capturing critical events, errors, and runtime behavior. It provides valuable insights into system performance, helps identify issues, and supports faster troubleshoot
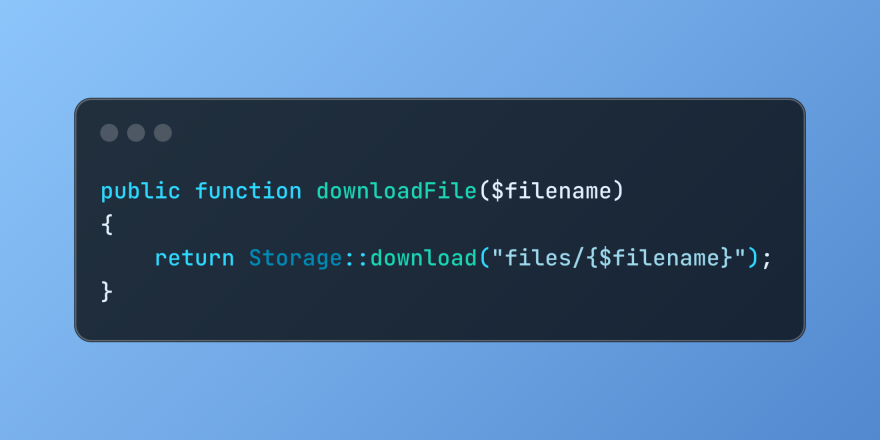 Discover File Downloads in Laravel with Storage::downloadMar 06, 2025 am 02:22 AM
Discover File Downloads in Laravel with Storage::downloadMar 06, 2025 am 02:22 AMThe Storage::download method of the Laravel framework provides a concise API for safely handling file downloads while managing abstractions of file storage. Here is an example of using Storage::download() in the example controller:
 Global View Data Management in LaravelMar 06, 2025 am 02:42 AM
Global View Data Management in LaravelMar 06, 2025 am 02:42 AMLaravel's View::share method offers a streamlined approach to making data accessible across all your application's views. This is particularly useful for managing global settings, user preferences, or recurring UI components. In Laravel development,


Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

EditPlus Chinese cracked version
Small size, syntax highlighting, does not support code prompt function

Dreamweaver CS6
Visual web development tools

WebStorm Mac version
Useful JavaScript development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)

DVWA
Damn Vulnerable Web App (DVWA) is a PHP/MySQL web application that is very vulnerable. Its main goals are to be an aid for security professionals to test their skills and tools in a legal environment, to help web developers better understand the process of securing web applications, and to help teachers/students teach/learn in a classroom environment Web application security. The goal of DVWA is to practice some of the most common web vulnerabilities through a simple and straightforward interface, with varying degrees of difficulty. Please note that this software

